目錄
激活函數
1、作用
2、常用激活函數
3、衡量激活函數好壞的標準:
4、不同的激活函數
1)sigmoid
2)tanh函數
?3)RULE函數和leak-relu函數
4)softmax函數
激活函數
1、作用
如果只是線性卷積的話,會導致無法形成復雜的表達空間,因此需要激活函數來進行非線性映射,這樣可以得到更高語義的信息,提升整個神經網絡的表達能力。
2、常用激活函數
sigmoid、tanh、relu、softmax
3、衡量激活函數好壞的標準:
1)是否0-均值輸出:即是否關于零點中心對稱,這樣可以使得收斂加速(不太理解)
2)是否會出現梯度消失現象:梯度消失現象主要是因為在反向傳播時,由于鏈式求導原則,使得梯度從后一層傳到前一層會出現減小的情況,如果網絡深的話,傳播到前面時,梯度變成了0
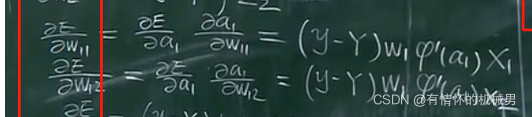
以BP后向傳播為例,在求w11的導數時,若W1求值為[0,1],激活函數φ的導數小于1時會出現梯度消失
3)激活函數表達式是否會很復雜:若計算表達式出現冪運算、指數運算等,一般計算量都很大
4、不同的激活函數
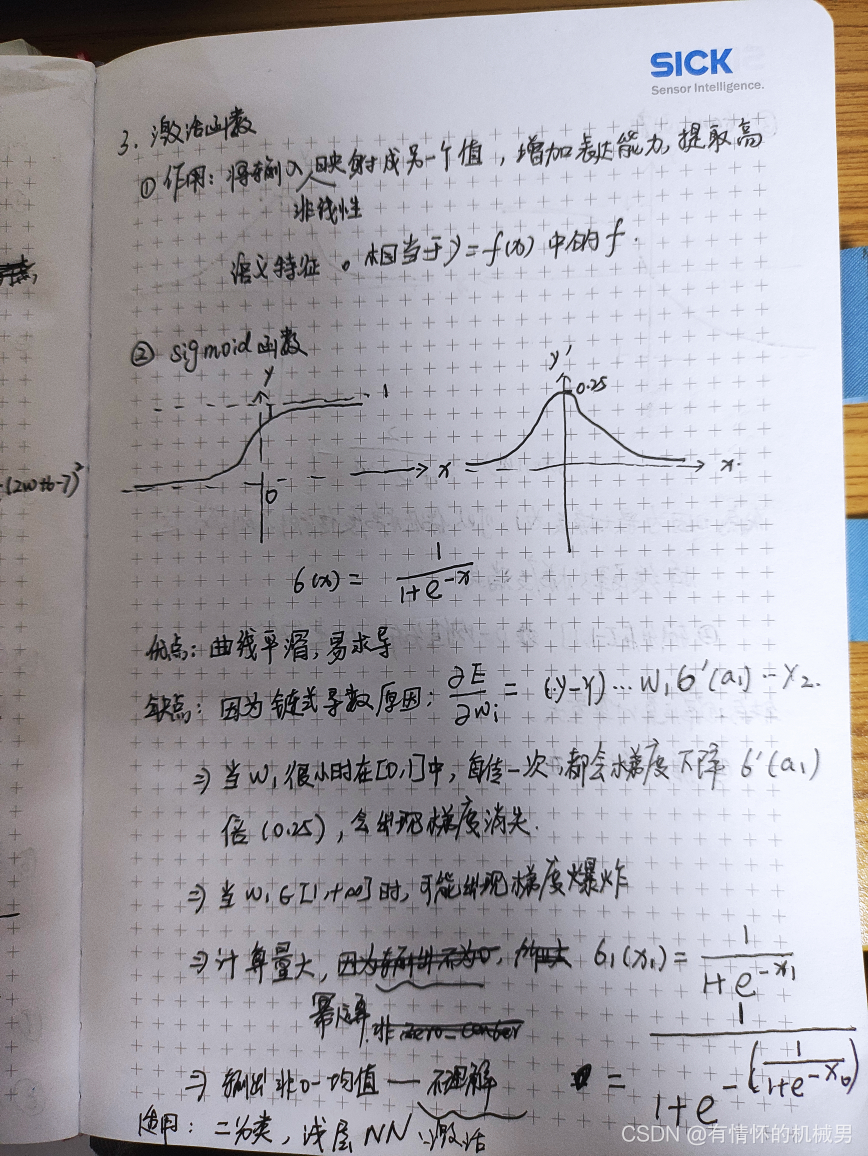
1)sigmoid
sigmoid函數可以作為0-1二分類的分類器,也可以作為層數較少的神經網絡的激活函數
優缺點如下:
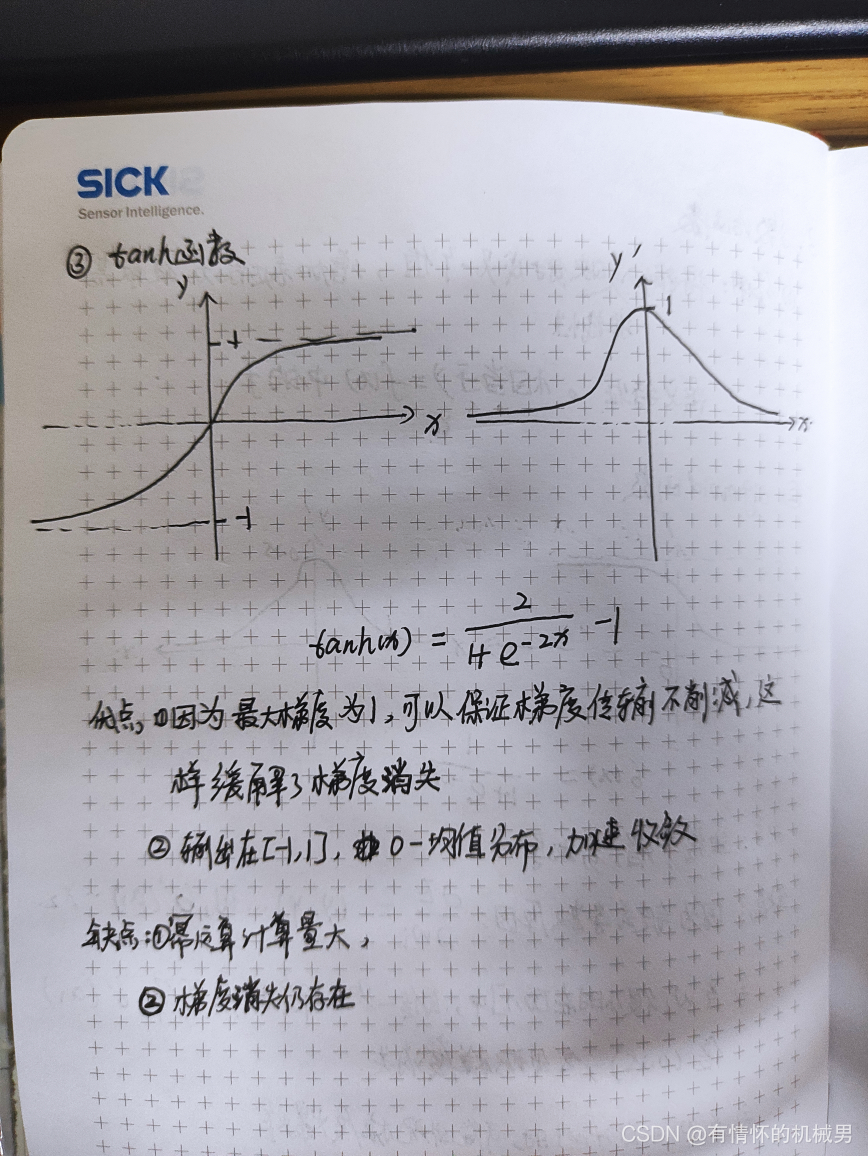
2)tanh函數
tanh函數適用于激活函數,相較于sigmoid函數做到了零均值輸出以及緩解了梯度消失
優缺點如下:
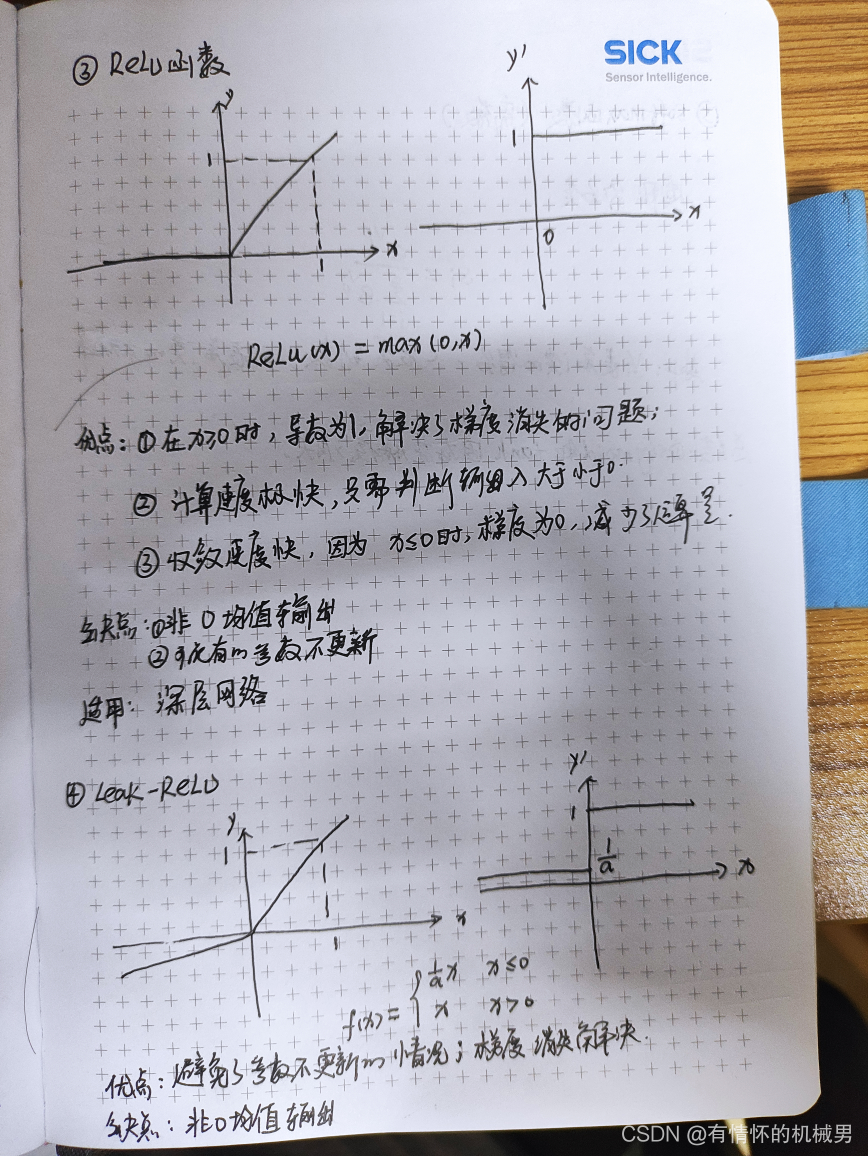
?3)RULE函數和leak-relu函數
RELU函數因為其在正空間為線性的緣故,因此適用于深度很深的神經網絡中,比如VGG16的實現。但是因為其在負空間直接將值置為0,導致導數為0,使得會出現參數不更新的情況,稱之為Dead ReLU Problem,基于此,出現了leak-rule函數,它是給了一個非常小的系數,使得在負空間的導數接近于零而不等于零,優缺點如下:
注意(個人理解):在大量的實驗種,發現relu函數會優于后者,原因可以是relu起到了一定的dropout的作用,可以有效地避免過擬合。因為relU在小于0的時候,梯度是0的,也就是有一部分神經元的參數是不會發生改變,所以這也相當于這部分神經元在訓練的時候被丟棄了,只有一部分神經元參與到了訓練當中。每次迭代都有不一樣的神經元的參數不發生改變,這樣的話就導致了多次訓練得到了不一樣的神經網絡結構,相當于dropout的作用。
區別在于:dropout方法隨即丟棄神經元,隨機性更強,而relu的話因為導數為0這部分主要是集中在負半區,使得每次迭代“丟棄”的神經元種有大部分其實是相同的,因此效果沒有直接用dropout來的好。
4)softmax函數
適用于多分類情景,是一個離散函數,輸入是每一類的得分,輸出是每一類的概率










)

o)

)





)