如果需要更好的閱讀體驗,可以在ai studio上fork該項目:使用VisualDL2.0對項目進行可視化調參
調參是深度學習必須要做的事情。數據和模型處理好后,需要進行模型訓練,這個時候就需要進行調參了。一種好的參數配置,可以使得訓練出來的模型在測試集上表現出很好的效果。可是要如何調呢?這里用飛槳(paddlepaddle深度學習框架)
我們通常說的調參是指調整超參數這些,例如:
- 先給他個設置一個不大不小的epoch,和一些其他超參數,例如epoch=10?然后跑一下,每多少iter(batch步數)打印一次loss看看,這其實是很不直觀的,得一條條輸出看過去。
- batch_size給個32?還是64?又或者更大更小?大的batch容易收斂,可是又容易陷入局部最小值(鞍點);小的batch訓練的模型魯棒性好,可是又難收斂!
- 學習率先給個0.01,觀察loss,如果loss上升就說明loss過大,給他減小到0.001?又或者0.005之類。如果loss下降很慢,這個時候是否考慮給他增大學習率呢?學習率衰減使用哪些策略比較好呢?是選擇分段衰減?還是按按步數衰減之類?等等…
- 這些超參數都是需要盡可能的去試,在不同模型和數據上這些參數選擇哪種是比較好的,都是不確定的(也就是所謂煉丹了)。
- 顯而易見調參這項工作是十分的耗費費時間和資源的,如果可以快速找到這些最好的參數,可以節約很多時間和算力資源。這也是本文的主要問題:如何進行高效的調參?這里推薦使用VisualDL工具進行可視化分析
- PaddleSeg是基于PaddlePaddle開發的端到端圖像分割開發套件,覆蓋了DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割網絡。通過模塊化的設計,以配置化方式驅動模型組合,幫助開發者更便捷地完成從訓練到部署的全流程圖像分割應用。
- 本文將使用paddleSeg套件實現一個語義分割項目,并用VisualDL工具對其參數進行可視化分析,以可視化的形式幫助開發者清楚了解這些參數的變化情況。
下載安裝命令## CPU版本安裝命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle## GPU版本安裝命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
項目內容
- 一.對數據進行一些處理以及簡單配置一下paddleSeg中提供的模型的參數
- 二.訓練模型,期間調整一些超參數/參數
- 三.使用VisualDL2.0工具進行可視化
- 四.總結
一.數據和配置準備:
- 數據這里采用第八屆CCF BDCI遙感影像地塊分割的初賽數據集,由于數據比較多,語義分割訓練較慢,我們這邊只是為了觀察vdl的使用。因此,我們就從這14萬張訓練集里劃分出一萬張來作為我們的訓練集。模型使用deeplabv3+exception65(輕量級網絡)
#下載paddleSeg
!git clone https://hub.fastgit.org/PaddlePaddle/PaddleSeg.git
#配置
%cd PaddleSeg
!pip install -r requirements.txt
%cd PaddleSeg/
#下載預訓練模型
!python pretrained_model/download_model.py deeplabv3p_xception65_bn_coco
#將數據集解壓到PaddleSeg路徑下,如果在本地運行,注意更改data/data55400/
!unzip data/data55400/img_train.zip -d PaddleSeg/dataset/rs_data
!unzip data/data55400/lab_train.zip -d PaddleSeg/dataset/rs_data
#為了方便訓練,從14萬張數據集中劃分出1萬張作為數據集,這邊已經劃分好了,如果想用完整數據集,或者進行一些數據增強操作,可以在下面代碼基礎上修改
%cd PaddleSeg/dataset/rs_data
%mkdir new_img
%mkdir new_lab
import os.path
import glob
import cv2
import matplotlib.pyplot as plt # plt 用于顯示圖片
import matplotlib.image as mpimg # mpimg 用于讀取圖片
import numpy as np
from PIL import Image, ImageEnhance, ImageDrawnums_id = 0#計數器
with open("train_list.txt", "w", encoding='utf-8') as f1:#訓練集with open("val_list.txt", "w", encoding='utf-8') as f2:#驗證集with open("test_list.txt", "w", encoding='utf-8') as f3:#測試集for file1 in glob.glob(r'lab_train/*.png'):nums_id += 1#原文件保存路徑path1, pngfile = file1.split()[0], file1.split("/")[1]path2, jpgfile = "img_train", pngfile.split(".")[0] + ".jpg"file2 = os.path.join(path2, jpgfile)#新文件保存路徑new_file1 = os.path.join("new_lab", pngfile)new_file2 = os.path.join("new_img", jpgfile)##遍歷lab_train下的png圖片,復制1萬張到另一個文件夾new_lab下'''img1 = cv2.imread(file1,flags=-1)cv2.imwrite(new_file1, img1)#'''img1 = Image.open(file1)img1.save(new_file1)#保存圖片,用PIL讀取png圖片##對應的img_train目錄下的1萬張jpg圖片,也復制到一個新文件夾new_img下img2 = cv2.imread(file2)cv2.imwrite(new_file2, img2, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])#保存圖片#保存list文件if nums_id <= 900:f1.write(new_file2 + " " + new_file1 + "\n")#生成訓練集列表else:f2.write(new_file2 + " " + new_file1 + "\n")#生成驗證集列表if nums_id > 9980:f3.write(new_file2 + "\n")#生成測試集列表,用于可視化數據,就取最后20張#打印進度if nums_id %100 == 0:print("處理到:",nums_id)if nums_id == 1000:break
%cd ../../
二.開始訓練:打印loss等信息(正常的觀察模型訓練情況的方式)以及保存日志文件(用于VDL可視化顯示訓練情況)
- 訓練過程中,設置參數:–use_vdl(使用vdl) --vdl_log_dir “vis”(指定日志保存的路徑)
#進入到PaddleSeg路徑下,如果在終端運行,需要刪去代碼前面符號。
%cd PaddleSeg
!python pdseg/train.py --cfg ../work/deeplabv3.yaml --use_gpu --use_vdl --do_eval --vdl_log_dir "vis5"
三.使用VDL可視化分析訓練過程的各參數變化情況
1.訓練完后(訓練過程中也可以動態查看),如何使用vdl可視化查看數據變化呢?
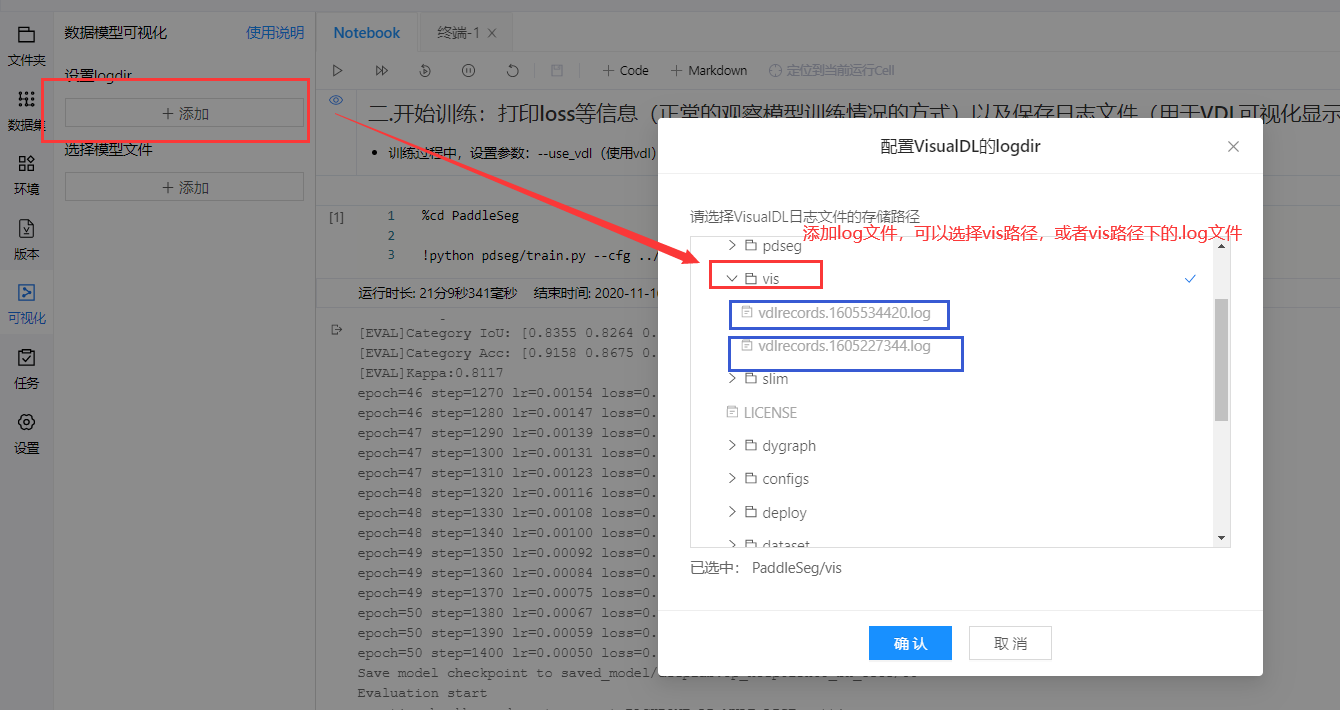
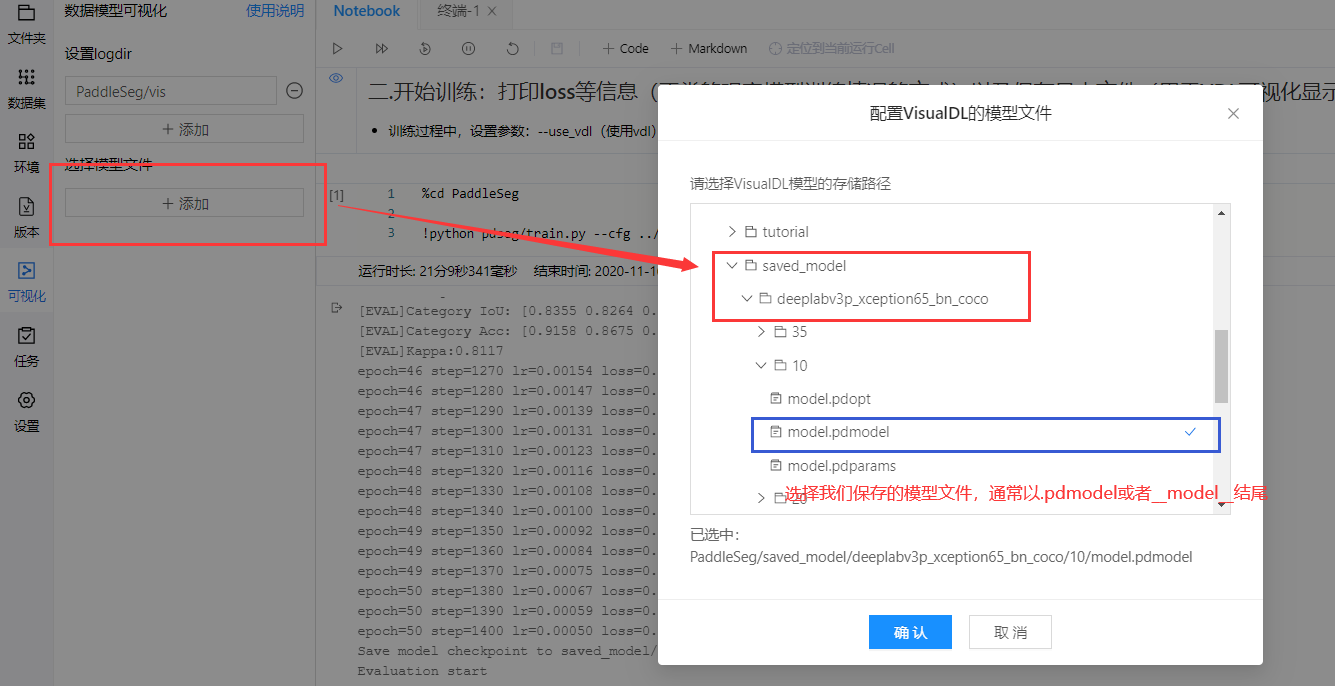
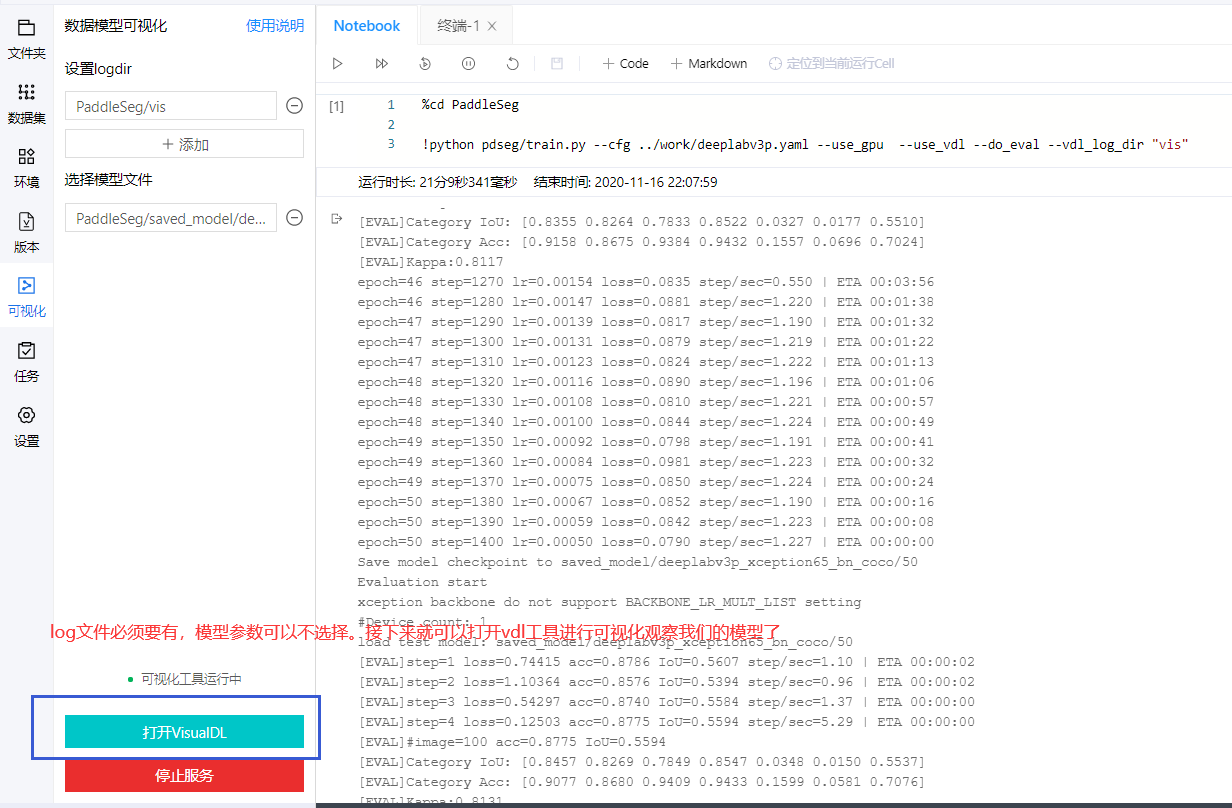
2.完成準備工作后,我們就可以進行可視化了!
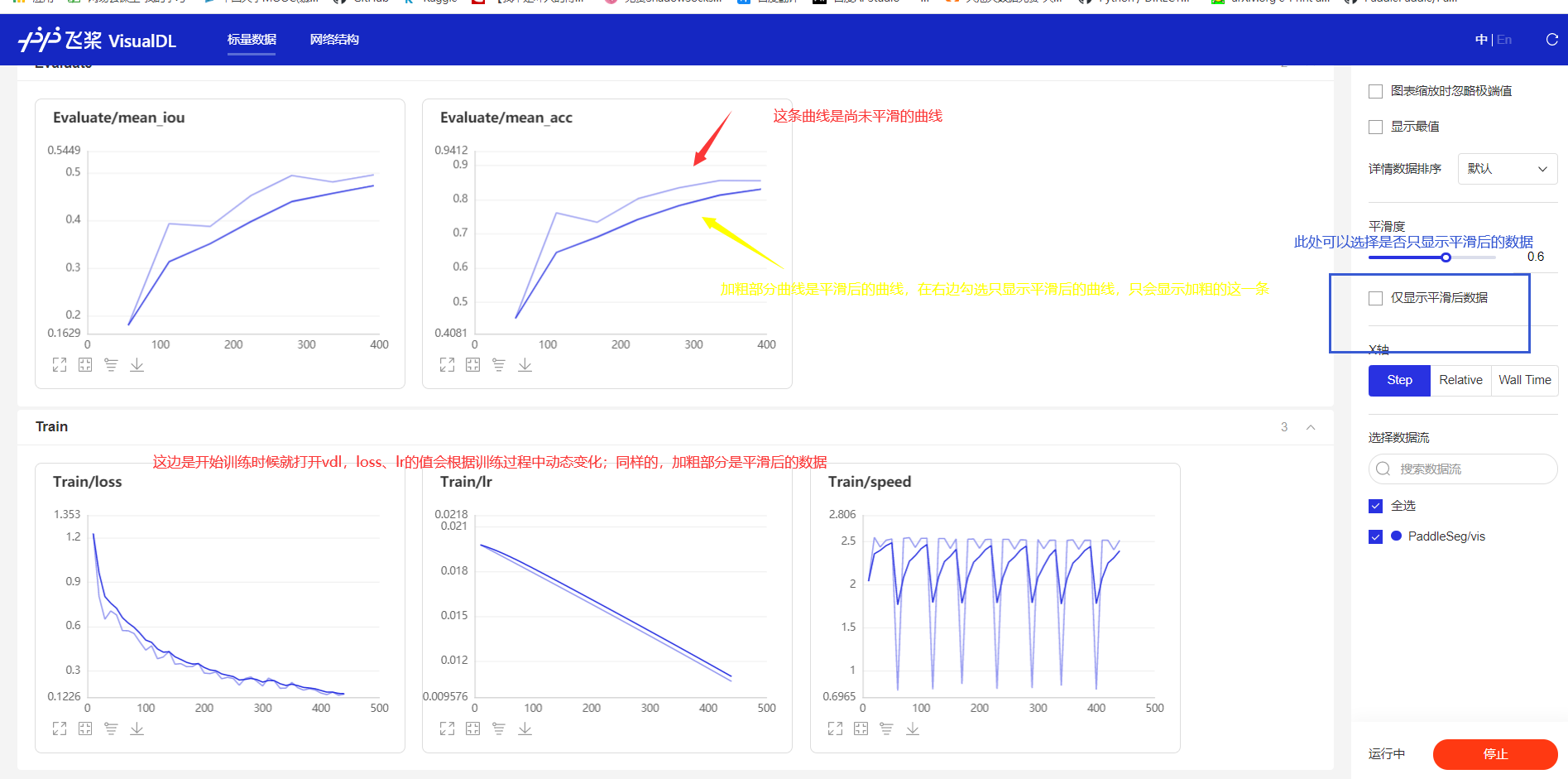
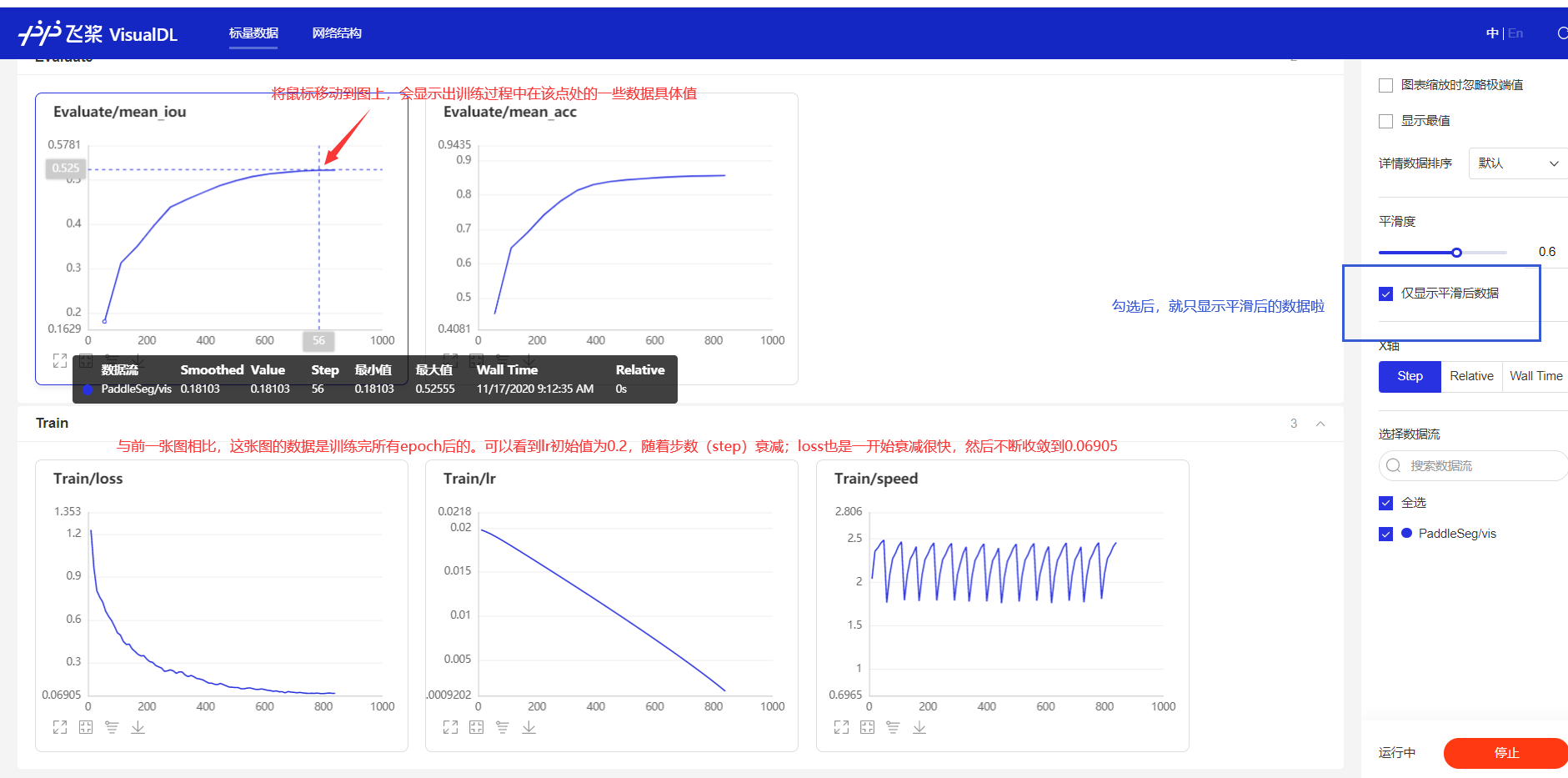
訓練過程中就打開vdl,觀察數據在訓練過程中的動態變化情況
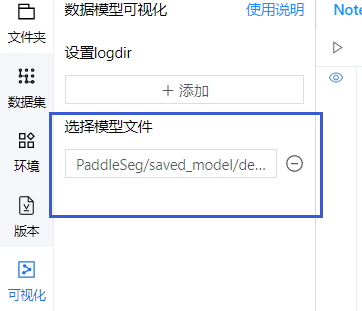
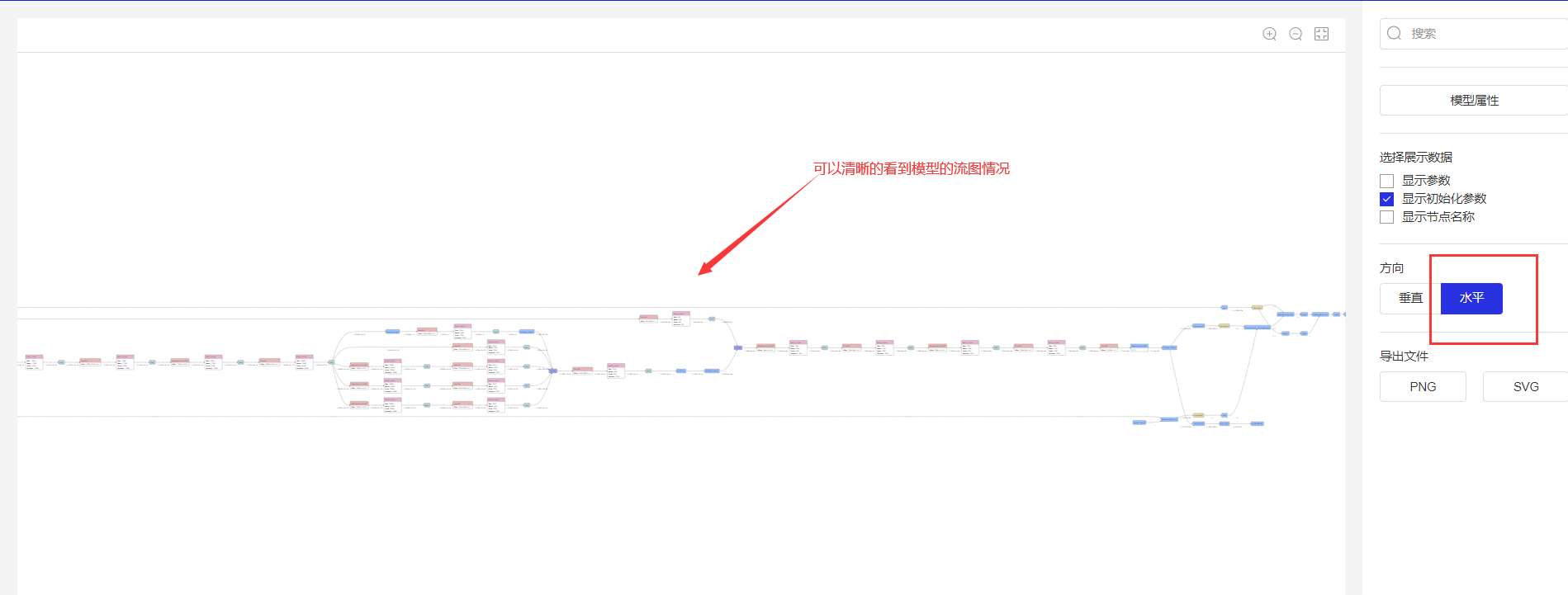
3.查看模型結構:使用deeplabv3p_xception65模型訓練,選擇模型文件,然后打開vdl,就可以查看模型結構了
- 如果想看自己搭的一個模型結構圖,那么也可以不需要自己去辛苦畫了,直接vdl打開,跑一下,就可以顯示出來啦!用處多多,有待挖掘!

4.我們還可以分成多組實驗,觀察不同超參數下,loss等數據的變化情況,在一張圖上展示出來
- 從最簡單的來:學習率
- vis1:lr1=0.01
- vis2:lr2=0.02
- vis3:lr3=0.05
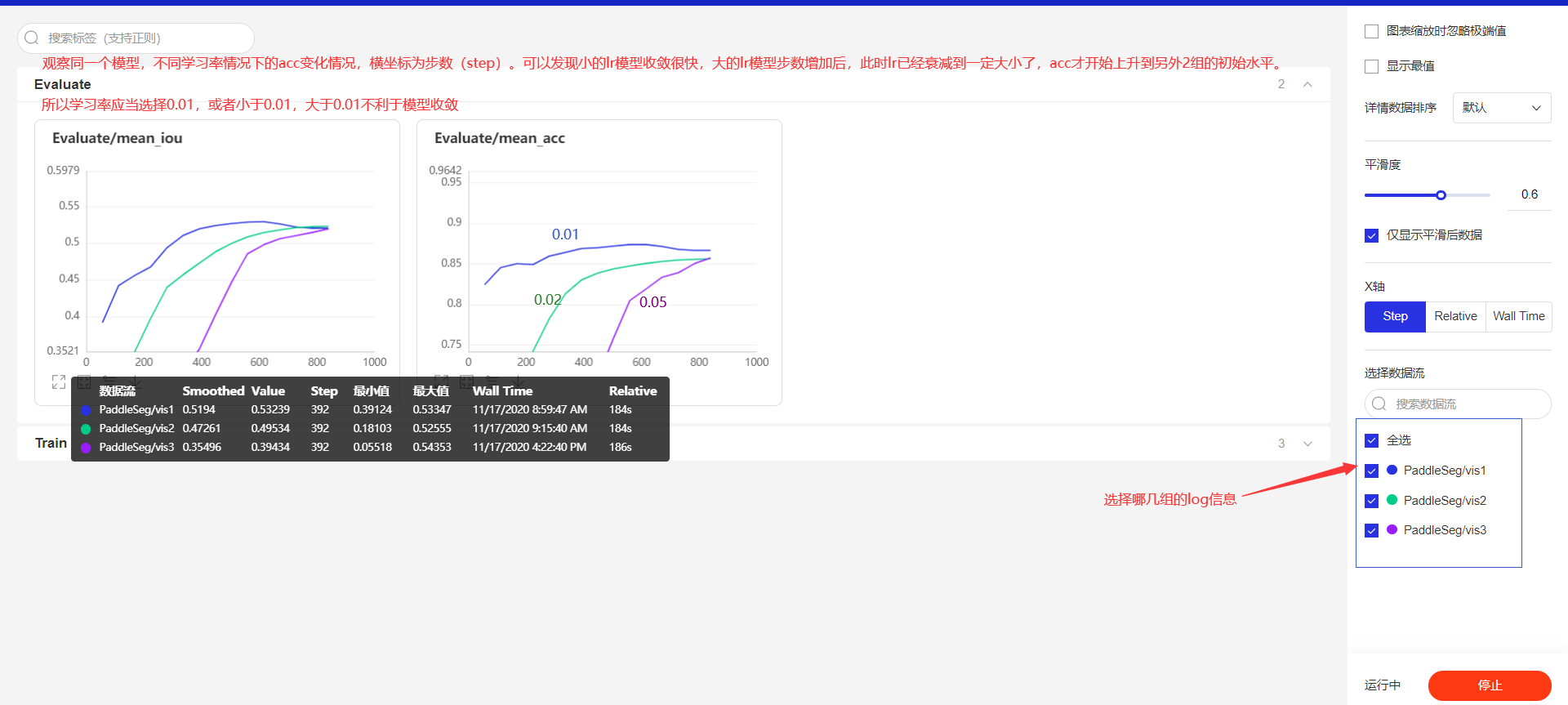
- lr1、lr2、lr3在步數(橫坐標)為280的時候,miou分別為0.49357,0.43952,0.2408,可以幫助我們分析學習率衰減情況對miou提升的影響。對于某一階段的miou如果是單純看打印信息,是基本上都是沒顯示的,使用vdl后可以看任意階段的數值變化。Relative是訓練到該位置的時間,通過這個參數可以查看訓練多少步數,需要多長時間,調參時候可以先跑幾個epoch,就可以較為準確的算出一個訓練一個epoch要多長時間,方便我們調整總epoch數的設置。

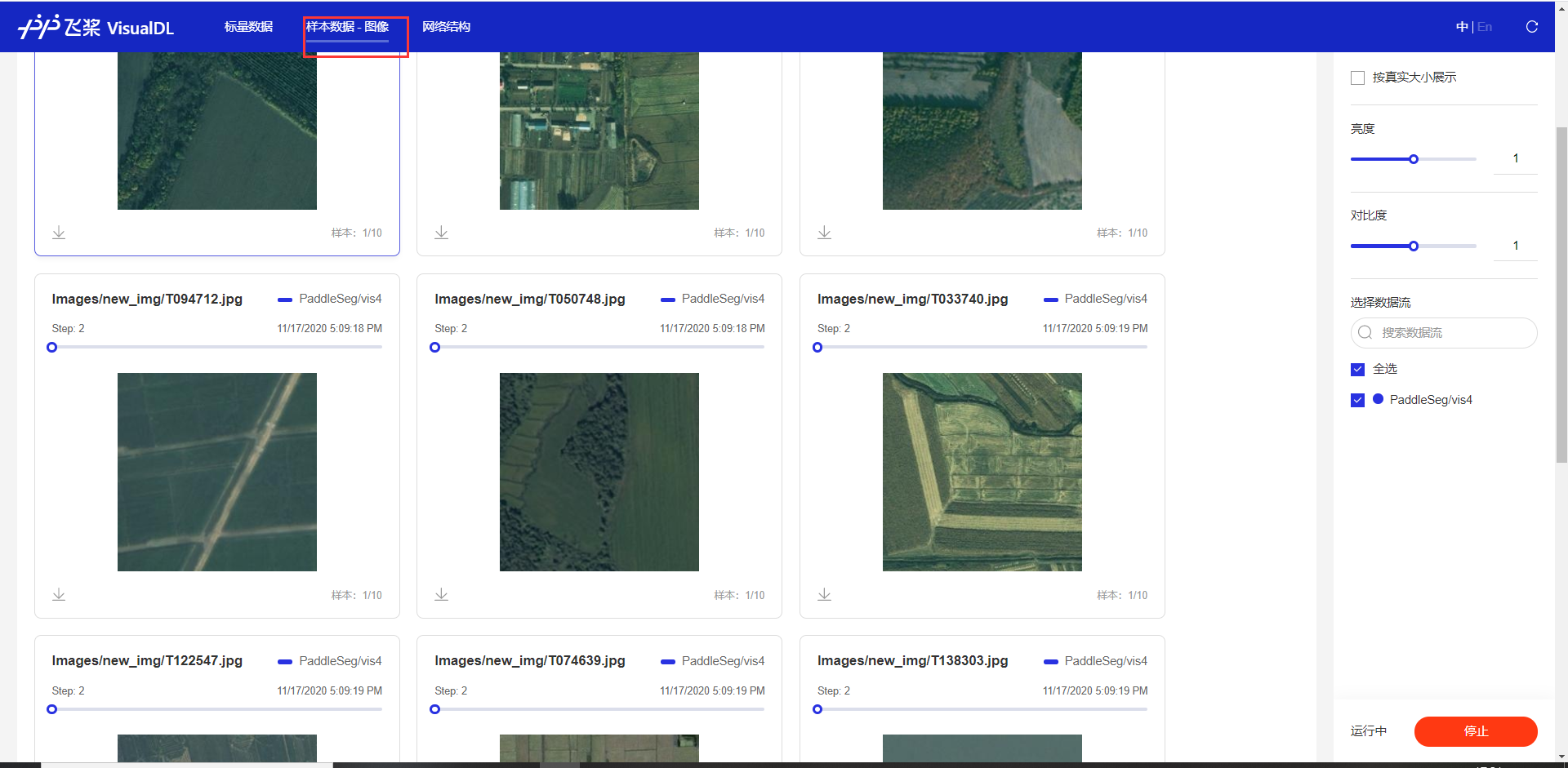
5.查看數據集
- 在aistudio環境中查看圖片其實不太方便的,不過很多和我一樣的小伙伴們又得用aistudio上的gpu環境,這個時候怎么辦呢?就可以用我們的vdl工具了,直接可視化出來你要看的一部分數據,想看哪些看哪些!
- log日志在vis4中
- 要在vdl查看數據集的話,需要配置deeplabv3.yaml文件中的一個參數:
VIS_FILE_LIST: "./dataset/rs_data/test_list.txt" - 會在訓練過程中保存模型時候打印一次,如果不想打印/在vdl中查看數據,可以將此參數設置為None:
VIS_FILE_LIST: None
四.總結
- 在訓練過程中,也有打印loss等信息,可是訓練多個epoch的話,打印的信息會非常多,每一條挨個看過去是非常累的。使用VDL2.0工具,可以將這些信息用幾張圖片展示出來,鼠標移動到圖上,數據也會動態顯示,可以幫助開發者們去更好的分析模型的一些情況。目前VisualDL2.0工具有6大功能,支持多個框架的模型可視化。
- 標量數據的展示
- 直方圖
- 樣本數據
- 網絡結構
- P-R曲線
- high dimensional
- 最后,歡迎大家去VDL GitHub上點個star鴨!!
- github首頁:https://github.com/PaddlePaddle/VisualDL
- 官網:https://www.paddlepaddle.org.cn/paddle/visualdl
- aistudio項目:【VisualDL2.0–眼疾識別訓練可視化】https://aistudio.baidu.com/aistudio/projectdetail/502834
- aistudio項目:【VisualDL2.0–基于「手寫數字識別」模型的全功能展示】https://aistudio.baidu.com/aistudio/projectdetail/622772
- aistudio論壇:https://ai.baidu.com/forum/topic/show/960053?pageNo=2
下載安裝命令## CPU版本安裝命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle## GPU版本安裝命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu


)

![[dts]Device Tree機制【轉】](http://pic.xiahunao.cn/[dts]Device Tree機制【轉】)











)


