參考
4.1 模型構造
讓我們回顧以下多重感知機的簡潔實現中包含單隱藏層的多重感知機的實現方法。我們首先構造Sequential實例,然后依次添加兩個全連接層。其中第一層的輸出大小為256,即隱藏層單元個數是256;第二層的輸出大小為10,即輸出層單元個數是10.
4.1.1 繼承Module類來構造模型
Module類是nn模塊里提供的一個模型構造類,是所有神經網絡模塊的基類,我們可以繼承它來定義我們想要的模型。下面繼承Module類構造本節開頭提到的多層感知機。這里定義的MLP類重載了Module類的__init__函數。它們分別用于創建模型和定義前向計算。
import torch
from torch import nnclass MLP(nn.Module):# 聲明帶有模型參數的層,這里聲明了兩個全連接層def __init__(self, **kwargs):# 調用MLP父類Module的構造函數來進行必要的初始化。這樣在構造實例時還可以指定其他函數# 參數,如"模型參數的訪問、初始化和共享"super(MLP, self).__init__(**kwargs)self.hidden = nn.Linear(784, 256)self.act = nn.ReLU()self.output = nn.Linear(256,10)# 定義模型的向前運算,即如何根據輸入x計算返回所需要的模型輸出def forward(self, x):a = self.act(self.hidden(x))return self.output(a)
以上MLP類中無須定義反向傳播函數。系統將通過自動求梯度而生成反向傳播所需的backward函數。
我們可以實例化MLP類得到模型變量net。下面的代碼初始化net并傳入數據X做一次前向計算。
X = torch.rand(2, 784)
net = MLP()
print(net)

注意,這里并沒有將Module類命名為Layer(層)或者Model(模型)之類的名字,這是因為該類是一個可供自由組建的部件。它的子類既可以是一個層(如PyTorch提供的Linear類),又可以是一個模型(如這里定義的MLP類),或者是模型的一個部分。我們下面通過兩個例子來展示它的靈活性。
4.1.2 Module的子類
我們剛剛提到,Module類是一個通用的部件。事實上,PyTorch還實現了繼承自Module的可以方便構建模型的類: 如Sequential、ModuleList和ModuleDict等等。
4.1.2.1 Sequential類
它可以接收一個子模塊的有序字典(OrderedDict)或者一系列子模塊作為參數來逐一添加Module的實例,而模型的前向計算就是將這些實例添加的順序逐一計算。
下面我們實現一個與Sequential類有相同功能的MySequential類。這或許可以幫助讀者更加清晰地理解Sequential類的工作機制
class MySequential(nn.Module):from collections import OrderedDictdef __init__(self, *args):super(MySequential, self).__init__() # 調用父類if len(args) == 1 and isinstance(args[0], OrderedDict): # 如果傳入的是一個OrderedDictfor key, module in args[0].items():self.add_module(key, module) # add_module方法會將module添加進self._modules(一個OrderedDict)else: # 傳入的是一些Modulefor idx, module in enumerate(args):self.add_module(str(idx), module)def forward(self, input):# self._modules返回一個 OrderedDict(),保證會按照成員添加時的順序遍歷成員for module in self._modules.values():input = module(input)return input
# 利用 MySequential類定義網絡
net = MySequential(nn.Linear(784, 256),nn.ReLU(),nn.Linear(256, 10)
)
print(net)
net(X)

4.1.2.2 ModuleList類
ModuleList接收一個子模塊的列表作為輸入,然后也可以類似List那樣進行append和extend操作:
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net.append(nn.Linear(256, 10)) # 類似List的append操作
print(net[-1])
print(net)

既然Sequential和ModuleList都可以進行列表化構造函數,那二者區別是什么呢。
ModuleList僅僅是一個存儲各種模塊的列表,這些模塊之間沒有聯系也沒有順序(所以不用保證相鄰層的輸入輸出維度匹配),而且沒有實現forward功能需要自己實現,所以上面執行net(torch.zeros(1, 784))會報NotImplementedError;而Sequential內的模塊需要按照順序排列,要保證相鄰層的輸入輸出大小匹配,內部forward功能已經實現。
class MyModule(nn.Module):def __init__(self):super(MyModule, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])def forward(self, x):for i, l in enumerate(self.linears):x = self.linears[i // 2](x) + l(x)return x
# 另外, ModuleList不同于一般的Python的list,加入到ModuleList里面的所有模塊的參數會被自動添加到整個網絡中
class Module_ModuleList(nn.Module):def __init__(self):super(Module_ModuleList, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10)])class Module_List(nn.Module):def __init__(self):super(Module_List, self).__init__()self.linears = [nn.Linear(10, 10)]net1 = Module_ModuleList()
net2 = Module_List()print("net1: ")
for p in net1.parameters():print(p.size())print("net2: ")
for p in net2.parameters():print(p)
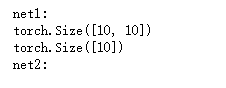
4.1.2.3 ModuleDict類
ModuleDict接收一個子模塊的字典作為輸入,然后也可以類似字典那樣添加訪問操作
net = nn.ModuleDict({'linear': nn.Linear(784, 256),'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10)
print(net['linear'])
print(net.output)
print(net)

4.1.3 構造復雜的模型
下面構造一個相對復雜的網絡FancyMLP。在這個網絡中,我們通過get_constant函數創建訓練中不被迭代的參數,即常數參數。在前向計算中,除了使用創建的常數參數外,我們還使用Tensor的函數和Python的控制流,并多次調用相同的層。
class FancyMLP(nn.Module):def __init__(self, **kwargs):super(FancyMLP, self).__init__(**kwargs)self.rand_weight = torch.rand((20, 20), requires_grad=False)self.linear = nn.Linear(20, 20)def forward(self, x):print(x)x = self.linear(x)# 使用創建的常數參數,以及nn.functional中的relu函數和mm函數# torch.mm矩陣的乘法x = nn.functional.relu(torch.mm(x, self.rand_weight.data) + 1)# 復用全連接層。x = self.linear(x)# 控制流,這里我們需要調用item函數來返回標量進行比較while x.norm().item() > 1:x /= 2if x.norm().item() < 0.8:x *= 10return x.sum()
X = torch.rand(2, 20)
net = FancyMLP()
net(X)

# 嵌套調用 FancyMLP和 Sequential類
class NestMLP(nn.Module):def __init__(self, **kwargs):super(NestMLP, self).__init__(**kwargs)self.net = nn.Sequential(nn.Linear(40, 30), nn.ReLU())def forward(self, x):return self.net(x)net = nn.Sequential(NestMLP(), nn.Linear(30, 20), FancyMLP())X = torch.rand(2, 40)
print(net)
net(X)


)
![[pytorch、學習] - 4.2 模型參數的訪問、初始化和共享](http://pic.xiahunao.cn/[pytorch、學習] - 4.2 模型參數的訪問、初始化和共享)
)

 和 CASE WHEN 的異同點)
![[pytorch、學習] - 4.4 自定義層](http://pic.xiahunao.cn/[pytorch、學習] - 4.4 自定義層)

)

![[pytorch、學習] - 4.5 讀取和存儲](http://pic.xiahunao.cn/[pytorch、學習] - 4.5 讀取和存儲)

)

![[pytorch、學習] - 4.6 GPU計算](http://pic.xiahunao.cn/[pytorch、學習] - 4.6 GPU計算)


)
![[pytorch、學習] - 5.1 二維卷積層](http://pic.xiahunao.cn/[pytorch、學習] - 5.1 二維卷積層)
![[51CTO]給您介紹Windows10各大版本之間區別](http://pic.xiahunao.cn/[51CTO]給您介紹Windows10各大版本之間區別)