參考
4.4 自定義層
深度學習的一個魅力在于神經網絡中各式各樣的層,例如全連接層和后面章節將要用介紹的卷積層、池化層與循環層。雖然PyTorch提供了大量常用的層,但有時候我們依然希望自定義層。本節將介紹如何使用Module來自定義層,從而可以被重復調用。
4.4.1 不含模型參數的自定義層
我們先介紹如何定義一個不含模型參數的自定義層。
import torch
from torch import nnclass CenteredLayer(nn.Module):def __init__(self, **kwargs):super(CenteredLayer, self).__init__(**kwargs)def forward(self, x):return x - x.mean()
layer = CenteredLayer()
layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))
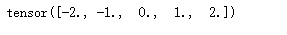
我們也可以用它來構造更復雜的模型。
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
y = net(torch.rand(4, 8))
y.mean().item()
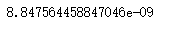
4.4.2 含模型參數的自定義層
我們還可以自定義含模型參數的自定義層。其中的模型參數可以通過訓練學習。
Parameter類其實是Tensor的子類,如果一個Tensor是Parameter,那么它會自動被添加到模型的參數列表里。所以在自定義含模型參數的層時,我們應該將參數定義成Parameter,除了像4.2.1節那樣直接定義成Parameter類外,還可以使用ParameterList和ParameterDict分別定義參數的列表和字典。
ParameterList接收一個Parameter實例的列表作為輸入然后得到一個參數列表,使用的時候可以用索引來訪問某個參數,另外也可以使用append和extend在列表后面新增參數。
class MyDense(nn.Module):def __init__(self):super(MyDense, self).__init__()self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])self.params.append(nn.Parameter(torch.randn(4, 1)))def forward(self, x):for i in range(len(self.params)):x = torch.mm(x, self.params[i])return xnet = MyDense()
print(net)

而ParameterDict接收一個Parameter實例的字典作為輸入然后得到一個參數字典,然后可以按照字典的規則使用了。
class MyDictDense(nn.Module):def __init__(self):super(MyDictDense, self).__init__()self.params = nn.ParameterDict({'linear1': nn.Parameter(torch.randn(4, 4)),'linear2': nn.Parameter(torch.randn(4, 1))})self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))})def forward(self, x, choice='linear1'):return torch.mm(x, self.params[choice])net = MyDictDense()
print(net)

x = torch.ones(1, 4)
print(net(x, 'linear1'))
print(net(x, 'linear2'))
print(net(x, 'linear3'))
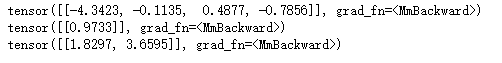
我們也可以使用自定義層構造模型。它和PyTorch的其他層在使用上很類似。
net = nn.Sequential(MyDictDense(),MyDictDense()
)
print(net)
print(net(x))


)

![[pytorch、學習] - 4.5 讀取和存儲](http://pic.xiahunao.cn/[pytorch、學習] - 4.5 讀取和存儲)

)

![[pytorch、學習] - 4.6 GPU計算](http://pic.xiahunao.cn/[pytorch、學習] - 4.6 GPU計算)


)
![[pytorch、學習] - 5.1 二維卷積層](http://pic.xiahunao.cn/[pytorch、學習] - 5.1 二維卷積層)
![[51CTO]給您介紹Windows10各大版本之間區別](http://pic.xiahunao.cn/[51CTO]給您介紹Windows10各大版本之間區別)
-NSData轉換成int)
)
![[pytorch、學習] - 5.2 填充和步幅](http://pic.xiahunao.cn/[pytorch、學習] - 5.2 填充和步幅)



![[pytorch、學習] - 5.3 多輸入通道和多輸出通道](http://pic.xiahunao.cn/[pytorch、學習] - 5.3 多輸入通道和多輸出通道)