參考
4.5 讀取和存儲
到目前為止,我們介紹了如何處理數據以及如何構建、訓練和測試深度學習模型。然而在實際中,我們有時需要把訓練好的模型部署到很多不同的設備。在這種情況下,我們可以把內存中訓練好的模型參數存儲在硬盤上供后續讀取使用。
4.5.1 讀寫tensor
我們可以直接使用save函數和load函數分別存儲和讀取Tensor。
下面的例子創建了Tensor變量x,并將其存儲在文件名為x.pt的文件里.
import torch
import torch.nn as nnx = torch.ones(3)
torch.save(x, 'x.pt')

然后我們將數據從存儲的文件讀回內存
x2 = torch.load('x.pt')
x2
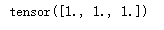
存儲一個Tensor列表并返回
y =torch.zeros(4)
torch.save([x, y], 'xy.pt')
xy_list = torch.load('xy.pt')
xy_list

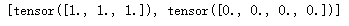
存儲并讀取一個從字符串映射到Tensor的字典
torch.save({'x': x,'y': y
}, 'xy_dict.pt')
xy = torch.load('xy_dict.pt')
xy
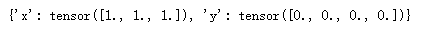
4.5.2 讀寫模型
4.5.2.1 state_dict
static_dict是一個從參數名稱映射到參數Tensor的字典對象
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.hidden = nn.Linear(3, 2)self.act = nn.ReLU()self.output = nn.Linear(2, 1)def forward(self, x):a = self.act(self.hidden(x))return self.output(a)net = MLP()
net.state_dict()

注意,只有具有可學習參數的層(卷積層、線性層)才有 state_dict中的條目
optimizer = torch.optim.SGD(net.parameters(), lr= 0.001, momentum=0.9)
optimizer.state_dict()

4.5.2.2 保存和加載模型
PyTorch中保存和加載訓練模型有兩種常見的方法:
- 僅保存和加載模型參數(state_dict)
- 保存和加載整個模型。
1. 保存加載static_dict(推薦方式)
torch.save(model.state_dict(), PATH)
# 保存
torch.save(model.state_dict(), PATH)# 加載
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.laod(PATH))
2. 保存和加載整個模型
# 保存
torch.save(model, PATH)# 加載
model = torch.load(PATH)
采用第一種方法來試驗一下:
X = torch.randn(2, 3)
Y = net(X)PATH = "./net.pt"
torch.save(net.state_dict(), PATH)net2 = MLP()
net2.load_state_dict(torch.load(PATH))
Y2 = net2(X)Y2 ==Y


)

![[pytorch、學習] - 4.6 GPU計算](http://pic.xiahunao.cn/[pytorch、學習] - 4.6 GPU計算)


)
![[pytorch、學習] - 5.1 二維卷積層](http://pic.xiahunao.cn/[pytorch、學習] - 5.1 二維卷積層)
![[51CTO]給您介紹Windows10各大版本之間區別](http://pic.xiahunao.cn/[51CTO]給您介紹Windows10各大版本之間區別)
-NSData轉換成int)
)
![[pytorch、學習] - 5.2 填充和步幅](http://pic.xiahunao.cn/[pytorch、學習] - 5.2 填充和步幅)



![[pytorch、學習] - 5.3 多輸入通道和多輸出通道](http://pic.xiahunao.cn/[pytorch、學習] - 5.3 多輸入通道和多輸出通道)


![[pytorch、學習] - 5.4 池化層](http://pic.xiahunao.cn/[pytorch、學習] - 5.4 池化層)
