現在各行各業紛紛選擇接入大模型,其中最火且可行性最高的形式無異于智能文檔問答助手,而LangChain是其中主流技術實現工具,能夠輕松讓大語言模型與外部數據相結合,從而構建智能問答系統。ERNIE Bot SDK已接入文心大模型4.0能力,同時支持對話補全、函數調用、語義向量等功能。
本教程是基于文心一言ERNIE?Bot SDK與LangChain構建基于Embedding Vector方式的文本問答系統, 整體可以解構為三部分。
1、基于ERNIE Bot與LangChain結合的Embedding,獲取向量矩陣并保存
2、基于用戶問題,在向量矩陣庫中搜尋相近的原文句子
3、基于檢索到的原文與Prompt結合,從LLM獲取答案

背景介紹
問答系統處理流程
加載文件 -> 讀取文本 -> 文本分割 -> 文本向量化 -> 問句向量化 -> 在文本向量中匹配出與問句向量最相似的top_k個 -> 匹配出的文本作為上下文和問題一起添加到Prompt中 -> 提交給LLM生成回答
技術工具
ERNIE Bot SDK
ERNIE Bot SDK 提供便捷易用的接口,可以調用文心大模型的能力,包含文本創作、通用對話、語義向量、AI作圖等。

LangChain
LangChain 是一個強大的框架,旨在幫助開發人員使用語言模型構建端到端的應用程序。它提供了一套工具、組件和接口,可簡化創建由大型語言模型 (LLM) 和聊天模型提供支持的應用程序的過程。LangChain 可以輕松管理與語言模型的交互,將多個組件鏈接在一起,并集成額外的資源,例如API和數據庫。
項目代碼
環境準備
安裝相關庫
!pip?install?-qr?requirements.txt
讀取 access_token
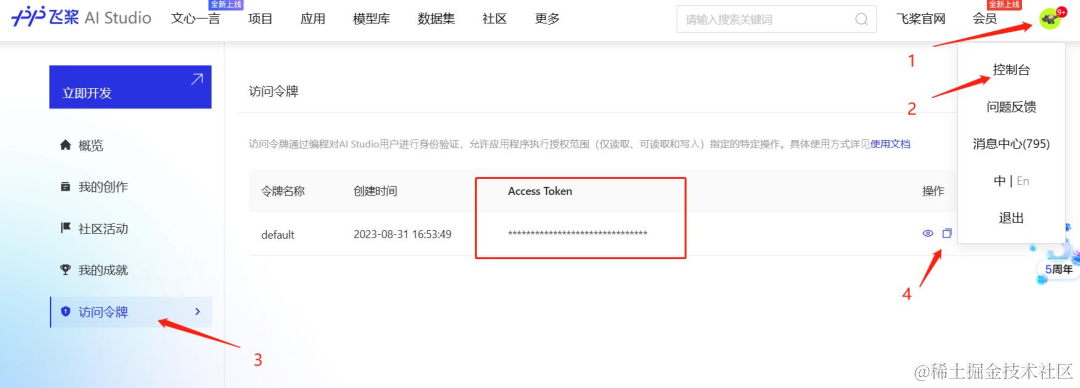
在星河社區的控制臺訪問令牌中找到自己的access_token,替換access_token.txt或下面代碼中的access_token。
fileName='access_token.txt'
access_token=''
if?len(access_token)==0:with?open(fileName,'r')?as?f:#逐行讀取文件內容lines?=?f.readlines()for?line?in?lines:if?line[:13]=='access_token=':access_token=line[13:]
assert?len(access_token)>10
print('access_token:',access_token)
LangChain及Embedding部分
獲取文檔載入器
使用GetLoader(source)獲取LangChain中的Loader,GetLoader會根據source類型,調用對應的LangChain文本載入器。
創建或載入向量庫
引入Embeddings函數并切分文本,chunk_size按ERNIE Bot SDK要求設為384
text_splitter?=?RecursiveCharacterTextSplitter(chunk_size=ernieChunkSize,?chunk_overlap=0)
splits?=?text_splitter.split_documents(documents)?
獲取整個文檔或網頁的Embedding向量并保存。
??embeddings=ErnieEmbeddings(access_token=access_token)#?vectorstore?=?Chroma.from_documents(documents=splits,?embedding=OpenAIEmbeddings())vectorstore?=?Chroma.from_documents(persist_directory=persist_directory,documents=splits,?embedding=embeddings)
根據用戶問題獲取文檔中最相近的原文片段
使用了LangChain中的similarity_search_with_score就可以獲取所需的top_k個文案片段,并且返回其score。結果顯示score差別不是很大。
def?searchSimDocs(query,vectorstore,top_k=3,scoreThershold=5):packs=vectorstore.similarity_search_with_score(query,k=top_k)contentList=[]for?pack?in?packs:doc,score=packif?score<scoreThershold:##好像設置5,基本都會返回contentList.append(doc.page_content)#?print('content',contentList)return?contentList
具體Embedding代碼見下方:
import?osos.environ['access_token']=access_token
from?langchain.vectorstores?import?Chroma
from?langchain.chains?import?RetrievalQA
from?langchain_embedding_ErnieBotSDK?import?ErnieEmbeddings#?Load?documentsfrom?langchain.document_loaders?import?WebBaseLoader
from?langchain.document_loaders.text?import?TextLoader
from?langchain.text_splitter?import?RecursiveCharacterTextSplitter
from?langchain.vectorstores?import?Chroma
import?erniebot##?https://python.langchain.com/docs/integrations/chat/ernie#?loader?=?WebBaseLoader("https://cloud.tencent.com/developer/article/2329879")##?創建新的chroma向量庫
def?createDB(loader,persist_directory='./chromaDB'):#loader?=?TextLoader(file_path=file_path,encoding='utf8')documents=loader.load()#?Split?documentsernieChunkSize=384text_splitter?=?RecursiveCharacterTextSplitter(chunk_size=ernieChunkSize,?chunk_overlap=0)splits?=?text_splitter.split_documents(documents)print('splits?len:',len(splits))#,splits[:5])#?Embed?and?store?splitsembeddings=ErnieEmbeddings(access_token=access_token)#?vectorstore?=?Chroma.from_documents(documents=splits,?embedding=OpenAIEmbeddings())vectorstore?=?Chroma.from_documents(persist_directory=persist_directory,documents=splits,?embedding=embeddings)#https://juejin.cn/post/7236028062873550908#?持久化?會結合之前保存下來的?vectorstore#vectorstore.persist()return?vectorstore
##?讀取已保存的chroma向量庫
def?readDB(persist_directory="./chromaDB"):assert?os.path.isdir(persist_directory)#?#?Embed?and?store?splitsembeddings=ErnieEmbeddings(access_token=access_token)vectorstore?=?Chroma(persist_directory=persist_directory,?embedding_function=embeddings)return?vectorstore
##?基于用戶的query去搜索庫中相近的文檔
def?searchSimDocs(query,vectorstore,top_k=3,scoreThershold=5):packs=vectorstore.similarity_search_with_score(query,k=top_k)contentList=[]for?pack?in?packs:doc,score=packif?score<scoreThershold:##好像設置5,基本都會返回contentList.append(doc.page_content)#?print('content',contentList)return?contentListdef?getLoader(source):if?source[-4:]=='.txt':#file_path='doupo.txt'assert?os.path.isfile(file_path)loader?=?TextLoader(file_path=file_path,encoding='utf8')elif?source[:4]=='http':#url='https://zhuanlan.zhihu.com/p/657210829'loader=?WebBaseLoader(source)return?loader#######################################
new=True?##新建向量庫,注意如果拿幾百萬字的小說embedding
source='https://zhuanlan.zhihu.com/p/657210829'
loader=getLoader(source)
if?new:vectorstore=createDB(loader)
else:vectorstore=readDB()
#?初始化?prompt?對象
query?=?"大模型長文本建模的難點是什么?"
contentList=searchSimDocs(query,vectorstore,top_k=5)
print('contentList',contentList)
LLM根據相關文檔片段回答問題
預置Prompt設定LLM角色,該Prompt將與向量計算中相關文檔片段進行結合,作為query輸入給大模型。
prompt=
"你是善于總結歸納并結合文本回答問題的文本助理。請使用以下檢索到的上下文來回答問題。如果你不知道答案,就說你不知道。最多使用三句話,并保持答案簡潔。問題為:\n"+query+"?\n上下文:\n"+'\n'.join(contentList)?+"?\n?答案:"
以下為response解析代碼:
def?packPrompt(query,contentList):prompt="你是善于總結歸納并結合文本回答問題的文本助理。請使用以下檢索到的上下文來回答問題。如果你不知道答案,就說你不知道。最多使用三句話,并保持答案簡潔。問題為:\n"+query+"?\n上下文:\n"+'\n'.join(contentList)?+"?\n?答案:"return?promptdef?singleQuery(prompt,model='ernie-bot'):response?=?erniebot.ChatCompletion.create(model=model,messages=[{'role':?'user','content':?prompt}])print('response',response)try:resFlag=response['rcode']except:????????resFlag=response['code']if?resFlag==200:try:data=response['body']except:data=responseresult=response['result']usedToken=data['usage']['total_tokens']else:result=""usedToken=-1return?result,usedTokenprompt=packPrompt(query,contentList)
res,usedToken=singleQuery(prompt,model='ernie-bot-4')
print(res)
該教程支持直接一鍵fork運行,點擊下方鏈接查看。
https://aistudio.baidu.com/projectdetail/7051316
該教程項目來源于飛槳星河社區五周年開發精品教程征集,更多教程或有投稿需求請點擊底部下方鏈接查看。
https://aistudio.baidu.com/topic/tutorial







方法)










)
