?
文章:Vision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving
作者: Yizhou Wang, Jen-Hao Cheng, Jui-Te Huang , Sheng-Yao Kuan , Qiqian Fu , Chiming Ni?
編輯:點云PCL
歡迎各位加入知識星球,獲取PDF論文,歡迎轉發朋友圈。文章僅做學術分享,如有侵權聯系刪文。
公眾號致力于點云處理,SLAM,三維視覺,高精地圖等領域相關內容的干貨分享,歡迎各位加入,有興趣的可聯系dianyunpcl@163.com。侵權或轉載聯系微信cloudpoint9527。
摘要
傳感器融合對于自動駕駛車輛上的準確和魯棒的感知系統至關重要。大多數現有的數據集和感知解決方案側重于將攝像機和激光雷達進行融合。然而,攝像機和毫米波雷達之間的融合未被顯著的充分利用。從攝像機獲取豐富的語義信息,以及從雷達獲取可靠的三維信息,潛在地可以實現對于3D目標感知任務的高效、廉價和便攜的解決方案。由于毫米波雷達具有適應不同光照或全天候駕駛場景的能力,這種解決方案還可以具有健壯性。在本文中,我們介紹了CRUW3D數據集,包括在各種駕駛場景中同步和校準的66,000幀攝像機、毫米波雷達和激光雷達數據。與其他大規模自動駕駛數據集不同,我們的雷達數據采用射頻(RF)張量的格式,其中包含了不僅有3D位置信息還有時空語義信息。這種毫米波雷達格式使得機器學習模型能夠在攝像機和雷達之間相互交互和融合信息或特征后生成更可靠的目標感知結果。
主要貢獻
有關雷達RF張量的標注的公共數據集有限,如表1所示。
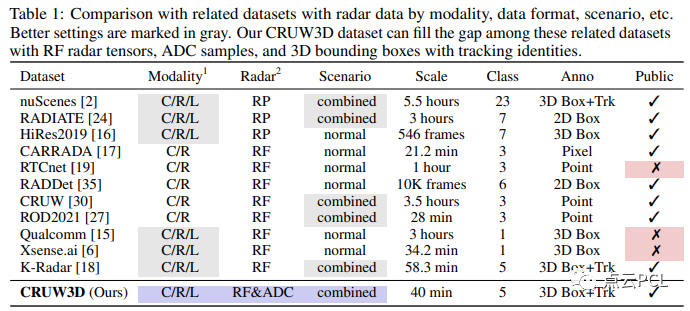
為了填補這方面的不足,我們引入了一個新的數據集名為CRUW3D,其中包含66,000幀同步的攝像機、毫米波雷達和激光雷達數據,涵蓋了各種駕駛場景,并帶有對象3D邊界框和軌跡標注。圖1顯示了我們在CRUW3D中的數據和注釋的一些示例。

圖1:CRUW3D數據集中的示例,每個示例包含攝像機RGB圖像和一個雷達RF張量對。為了更好地可視化,RF張量被轉換為笛卡爾坐標。我們提供了不同駕駛場景和照明條件下的數據示例,相應的3D邊界框注釋分別投影到RGB和RF張量上。
為了提高數據標注的精度,我們在數據收集系統中包含了一個激光雷達。基于激光雷達點云,我們在每個時間幀內仔細標注了對象的3D邊界框,并在整個時間序列中標注了對象的軌跡。我們還提供了傳感器之間的校準參數,以允許在不同模態之間進行數據/信息轉換或進行傳感器融合設置。我們希望CRUW3D數據集能夠促進更多關于可靠和健壯協同感知的研究。CRUW3D數據集將很快公開提供。總體而言,我們的CRUW3D數據集具有以下主要貢獻:
-
據我們所知,這是第一個具有同步攝像機RGB圖像、原始雷達模數轉換器(ADC)數據、帶有相位的雷達RF張量和激光雷達點云的公共數據集。
-
它包括3D邊界框和3D對象軌跡的對象標注,對于各種對象感知任務,例如3D目標檢測和3D多目標跟蹤具有一定價值。
-
它包含不同的光照條件,對于基于視覺的對象感知方法具有挑戰性,因此為基于傳感器融合的對象感知算法提供了一個很好的基準。
內容概述
數據收集?
我們提出了一個使用雙目攝像機、毫米波雷達和激光雷達的數據集收集流程,包括一個傳感器平臺、一個數據收集軟件和一個傳感器校準方法。通過我們提出的流程,從三個傳感器模態收集的數據可以在時間上同步和在空間上進行精確校準。
傳感器平臺?
我們的數據集收集傳感器系統如圖2所示,有兩個FLIR BFS-U3-16S2C-CS攝像機,一個TI AWR1843雷達板和一個Livox Horizon激光雷達。詳細規格列在表2中。
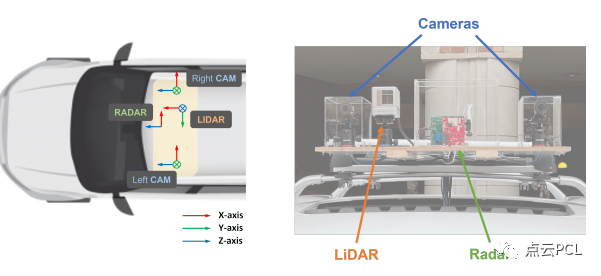
圖2:我們CRUW3D數據集的傳感器坐標和傳感器平臺,包括兩個攝像機、一個毫米波雷達和一個激光雷達。請注意,我們的雷達沒有俯仰角分辨率(即y軸),因此在兩個傳感器之間應用平移向量之后,它等效于攝像機的鳥瞰圖。

傳感器同步?
我們的數據集收集軟件基于Ubuntu下的機器人操作系統(ROS)。對于攝像機和激光雷達,由于它們提供開源API,我們直接將它們集成到ROS系統中。然而TI只提供基于Windows和MATLAB的軟件。因此我們在Ubuntu系統中創建了一個Windows虛擬機,并通過ROS進行進程間通信。我們使用由右側攝像機生成的Transistor-Transistor Logic(TTL)信號進行攝像機和激光雷達之間的硬件時間同步。攝像機和激光雷達傳感器都通過它們的API支持TTL信號時間同步。在軟件層面上,我們使用ROS庫提供的ApproximateTime同步策略將三個傳感器的數據對齊到30 FPS的時間槽中。為了在雷達和其他傳感器之間同步,我們使用軟件觸發器啟動數據序列收集。服務客戶端在收到響應后觸發雷達數據的收集過程,并在開始其他傳感器數據的收集過程時啟動另一個過程。根據我們的實驗證明,軟件觸發器的延遲在幾毫秒以下,是可以忽略的。
傳感器校準?
首先使用Zhang的方法校準了雙目攝像機,該方法給出了兩個攝像機的內參、畸變系數和外參,這些結果將用于立體矯正。對于攝像機和激光雷達之間的傳感器校準,我們采用了Dhall等人提出的校準算法。這將給我們兩個變換矩陣,分別表示左攝像機和激光雷達之間的變換,以及右攝像機和激光雷達之間的變換。至于雷達,它根據其俯仰角度仔細安裝和與攝像機和激光雷達對齊,其坐標平行于攝像機的鳥瞰圖(BEV)。還測量了傳感器之間的平移向量,以形成攝像機和雷達之間的完整變換矩陣。
數據處理
攝像頭數據處理:首先,由雙目攝像頭捕捉的圖像序列根據攝像頭校準進行去畸變和矯正。然后針對由于不良光照條件導致的低質量圖像,我們進行圖像增強,以提高收集到的視頻的質量和光照穩定性。在這里實現了一種基于深度學習的方法,名為RRDNet,使用三分支CNN在零鏡頭拍攝中恢復曝光不足的圖像。為了實現對視頻序列的穩定增強結果,我們僅使用每個序列的第一幀對網絡進行訓練,并對其余幀進行推理。
雷達數據處理:我們的雷達數據處理類似于[28]中提到的預處理,其中雷達范圍-方位坐標中的RF張量被描述為俯視圖(BEV)表示,其中x軸表示方位(角度),y軸表示距離(距離)。從原始雷達數據中,我們首先對接收到的樣本進行范圍快速傅里葉變換(FFT)以估算反射的范圍。然后我們對不同接收天線上的樣本進行第二次角度FFT,以估算反射的方位角。此外,我們還將RF張量轉換為笛卡爾坐標,以更好地與攝像機對齊并進行更清晰的可視化。我們的雷達數據處理的更詳細描述在補充文件中提到。
激光雷達數據處理:Livox激光雷達采用了一種稱為非重復水平掃描的特殊激光掃描技術,與大多數傳統激光雷達傳感器提供的重復線性掃描顯著不同。它積累了在FOV內捕獲的點,以在集成時間窗口內獲得更密集的點云。然而,基于這項技術,激光雷達的點云無法在相機幀(即1/30秒)內覆蓋整個FOV。為確保每個相機/雷達幀都有一個相應的激光雷達幀進行注釋,我們將連續三幀(即1/10秒時間窗口)內捕獲的點云累積為一個完整的幀,這意味著我們的激光雷達的幀率為10 FPS,如表2中所述。
數據標注
在CRUW3D數據集中,我們在LiDAR點云上標注3D邊界框。與KITTI數據集中的3D邊界框標簽不同,我們使用三個歐拉角來表示每個邊界框的方向,因為CRUW3D數據集中的街道不像KITTI數據集中的街道那樣平坦。在此,我們在標注過程中考慮以下5個對象類別:行人、汽車、貨車、卡車和公共汽車。除了3D邊界框之外,我們還為后續的多目標跟蹤(MOT)任務標注了對象跟蹤ID。然而,由于不同的傳感器具有不同的視場(FOV),而且遠處物體的點云通常是稀疏的,我們只在重疊區域內標注了對象,如圖3所示。在LiDAR點云上標記了3D邊界框之后,我們通過來自傳感器校準的轉換矩陣將所有邊界框投影到攝像機和雷達坐標系中。然后,可以使用這些注釋分別訓練攝像機和雷達的網絡。

數據統計
我們的CRUW3D數據集包含約66,000幀各種駕駛場景下的同步攝像機、雷達和激光雷達數據,具有不同的光照條件。大約70%的數據是在正常的駕駛場景中捕獲的,具有良好的光照條件。其余30%是在不利的光照條件下捕獲的,例如夜間或強光照。表3中顯示了一些數據統計信息。在所有數據幀中,我們在訓練集中標注了19,000幀,在測試集中標注了10,000幀。
CRUW3D數據集的標注
至于CRUW3D數據集的標注,我們在圖4中分析了我們標記的對象的不同分布,包括3D邊界框的數量、3D對象軌跡的數量、對象深度、對象方位角和對象尺寸。

圖4:CRUW3D數據集中的對象標注分布,包括(a)對象3D邊界框分布,(b)對象軌跡分布,(c)對象深度分布,(d)對象方位角分布和(e)對象長度分布。
實驗
在CRUW3D數據集上進行了一系列基線實驗,包括基于相機的3D目標檢測、基于相機的3D目標跟蹤、基于雷達的目標檢測以及相機-雷達融合的基線。在接下來的實驗中,我們只考慮行人和汽車作為我們感知的目標類別。
基于相機的3D目標檢測
對于自動駕駛應用來說,單目3D目標檢測是至關重要的。用于3D目標檢測的神經網絡提取圖像特征,并在透視圖或鳥瞰圖中檢測對象。我們在我們的基準測試中實現了SMOKE和 DD3D作為基線。
SMOKE 是基于 CenterNet的單級3D目標檢測方法。給定輸入圖像,它檢測目標對象在圖像平面上投影的3D中心。然而,該算法最初是為KITTI數據集設計的,其3D邊界框方向僅包括偏航角。我們通過忽略俯仰和橫滾將每個邊界框的四元數方向標簽轉換為偏航角,假設其他旋轉角度可以忽略。在此,我們在實現過程中使用DLA-34作為SMOKE的骨干網絡。
DD3D 建立在另一個2D目標檢測器 FCOS 之上。它使用大規模深度數據集 DDAD15M 對網絡進行預訓練,以從圖像中獲得更好的深度感知特征,從而在單目3D目標檢測方法中取得了最先進的效果。在實現過程中,我們嘗試了兩個不同的骨干網絡,即 DLA-34和 V2-99 。
與KITTI類似,評估指標包括3D邊界框的平均精度(AP)和在IOU閾值為0.5或0.7(對于汽車)以及0.3或0.5(對于行人)時的BEV 2D邊界框的平均精度。定量結果如表4所示。從實驗結果可以看出,與SMOKE相比,DD3D在各個方面都表現更好。使用更大的骨干V2-99,DD3D在汽車和行人方面均取得了最佳性能。

基于相機的3D目標跟蹤
在預測對象3D檢測結果之后,我們進一步實現了一個3D多目標跟蹤(MOT)算法,稱為AB3DMOT,以獲得對象3D邊界框軌跡。我們根據表4中的3D目標檢測結果,即 SMOKE 和 DD3D,進行了基于AB3DMOT框架的實驗。AB3DMOT單獨跟蹤不同的對象類別,并在最后階段將它們合并,因此我們也分別評估汽車和行人的3D MOT性能,如表5所示。
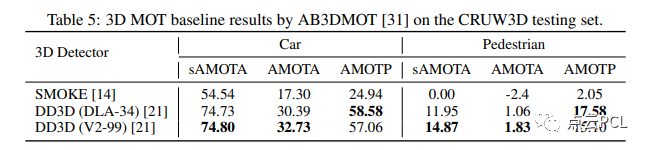
對于3D MOT的評估指標,我們采用了[31]中提出的指標,包括縮放平均多目標跟蹤準確度(sAMOTA)、平均多目標跟蹤準確度(AMOTA)和平均多目標跟蹤精度(AMOTP)。從表5可以看出,“DD3D+AB3DMOT”的組合在3D MOT性能方面表現最佳。由于前一階段3D檢測質量較差,“SMOKE+AB3DMOT”在行人跟蹤方面的性能非常差。
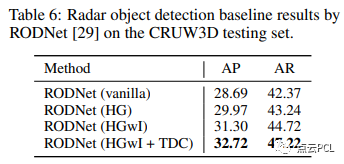
毫米波雷達目標檢測
對于基于毫米波雷達的目標檢測,它將每個對象檢測為RF張量中的一個點,我們使用RODNet作為基線方法。評估指標包括使用不同對象位置相似度(OLS)閾值的平均精度(AP)和平均召回率(AR),這與我們先前的CRUW數據集相同。定量結果如表6所示。整體性能低于CRUW數據集,顯示出我們的CRUW3D數據集要更具挑戰性,使用HGwI骨干和時間變形卷積的RODNet取得了最佳性能。
總結
本文介紹了一個名為CRUW3D的新基準數據集,其中包含了同步且校準良好的相機、雷達和激光雷達數據,并附有目標3D邊界框和軌跡標注。據我們所知,這是第一個具有雷達RF張量、包含幅度和相位信息的公開數據集,可用于3D目標檢測和多目標跟蹤任務。通過CRUW3D數據集,相機和毫米波雷達之間的傳感器融合可以進一步利用,以提高自動駕駛的可靠性和魯棒性。
以上內容如有錯誤請留言評論,歡迎指正交流。如有侵權,請聯系刪除
讓我們一起分享一起學習吧!期待有想法,樂于分享的小伙伴加入知識星球注入愛分享的新鮮活力。分享的主題包含但不限于三維視覺,點云,高精地圖,自動駕駛,以及機器人等相關的領域。
分享與合作:微信“cloudpoint9527”(備注:姓名+學校/公司+研究方向) 聯系郵箱:dianyunpcl@163.com。
為分享的伙伴們點贊吧!


)


開發板刷Android12的挖掘機方案的LOG)
![[python高級編程]:01-數據結構](http://pic.xiahunao.cn/[python高級編程]:01-數據結構)




)
)



(1.4) ESP32 wifi telemetry)


