提示:Grounding DINO、TAG2TEXT、RAM、RAM++論文解讀
文章目錄
- 前言
- 一、Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
- 1、摘要
- 2、背景
- 3、部分文獻翻譯
- 4、貢獻
- 5、模型結構解讀
- a.模型整體結構
- b.特征增強結構
- c.解碼結構
- 6、實驗有趣說明
- 二、TAG2TEXT: GUIDING VISION-LANGUAGE MODEL VIA IMAGE TAGGING
- 1、摘要
- 2、背景
- 3、貢獻
- 5、模型結構解讀
- 三、Recognize Anything: A Strong Image Tagging Model
- 1、摘要
- 2、背景/引言
- 3、數據獲得
- 4、貢獻
- 5、模型結構解讀
- 四、Inject Semantic Concepts into Image Tagging for Open-Set Recognition
- 1、摘要
- 2、背景/引言
- 3、CLIP-RAM-RAM++模型結構對比
- 4、貢獻
- 5、模型結構解讀
- 總結
前言
隨著SAM模型分割一切大火之后,又有RAM模型識別一切,RAM模型由來可有三篇模型構成,TAG2TEXT為首篇將tag引入VL模型中,由tagging、generation、alignment分支構成,隨后才是RAM模型,主要借助CLIP模型輔助與annotation處理trick,由tagging、generation分支構成,最后才是RAM++模型,該模型引入semantic concepts到圖像tagging訓練框架,RAM++模型能夠利用圖像-標簽-文本三者之間的關系,整合image-text alignment 和 image-tagging 到一個統一的交互框架里。作者也介紹將tag引入Grounding DINO模型,可實現目標定位。為此,本文將介紹這四篇文章。
一、Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
1、摘要
我們提出open-set檢測任務方法叫做groindding dino,該方法基于transform的dino預訓練模型相結合,可通過類別或相關表述來檢測任意目標。該模型解決open-set任務最核心方法是引入語言language,為有效融合語言與視覺模態特征,我們設定三個階段,并構建feature enhancer、a language-guided query selection與a cross-modality decoder for cross-modality fusion。我們方法與以往研究不一樣,以往研究基本是用模型評估開放數據集,我們是通過tag評估開放集數據(我們用tag、以往直接評估),我們方法在三個數據集表現sota

注:文章核心是tag提供語言信息結合到圖像中,可使用tag檢測定位grounding,即使未學習tag給到圖像也有不錯表現。
2、背景
Grounding DINO相對于GLIP有以下優勢:
1、基于Transformer結構與語言模型接近,易于處理跨模態特征;
2、基于Transformer的檢測器有利用大規模數據集的能力;
3、DINO可以端到端優化,無需精細設計模塊,比如:NMS
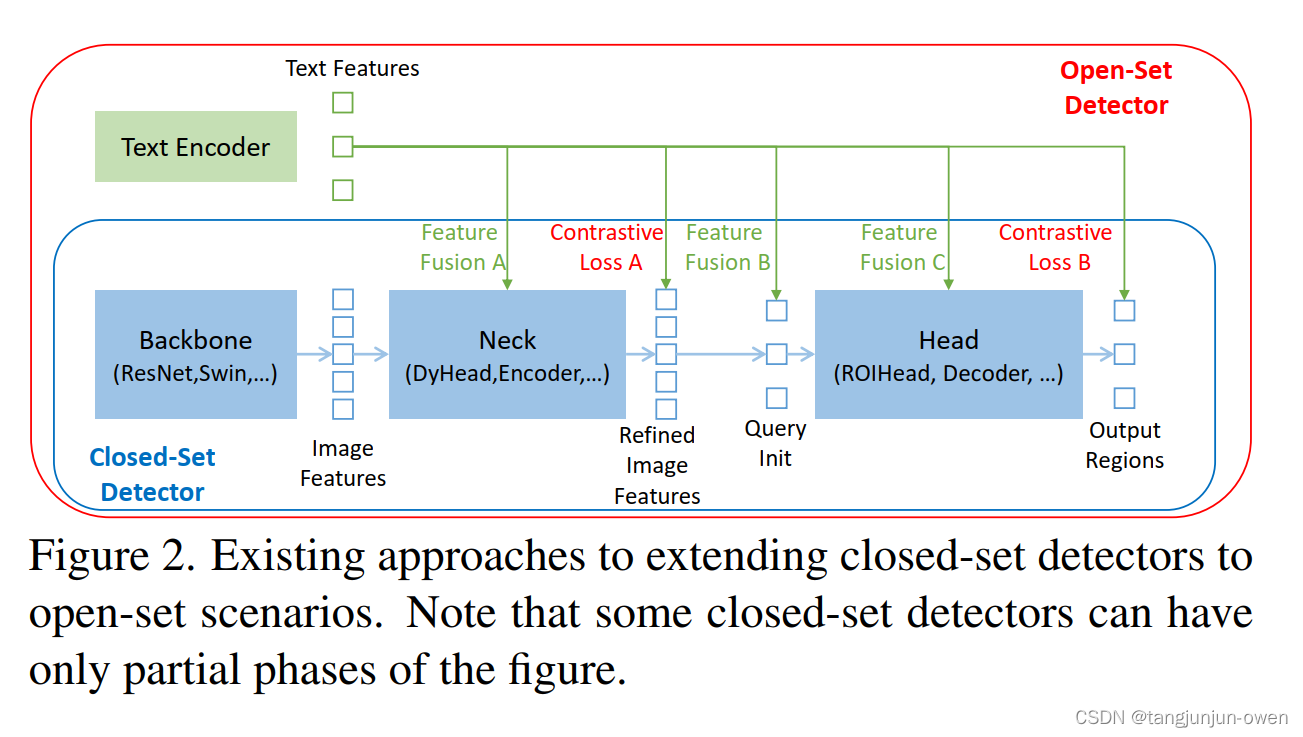
先前研究open-set檢測器是由閉集檢測器引入語言信息實現,如圖2所示,一個封閉集檢測器通常有三個重要模塊,一個主干網絡用于特征提取,一個頸部用于特征增強,以及一個頭部用于區域調整(或框預測)。可以通過學習語義意識的區域嵌入來將封閉集檢測器推廣到檢測新對象,以便每個區域可以在語義意識的語義空間中分類為新類別。實現這一目標的關鍵是在頸部和/或頭部輸出處使用區域輸出和語言特征之間的對比損失。為了幫助模型對齊跨模態信息,一些工作嘗試在最終損失階段之前融合特征。圖2顯示,特征融合可以在三個階段進行:頸部(階段A)、查詢初始化(階段B)和頭部(階段C)。例如,GLIP[26]在頸部模塊(階段A)中執行了早期融合,OV-DETR[56]將語言感知查詢用作頭部輸入(階段B)。
3、部分文獻翻譯
檢測Transformer。基于定位的DINO建立在類似DETR的模型DINO [58]之上,DINO是一個端到端的基于Transformer的檢測器。DETR首先在[2]中提出,然后在過去幾年中從許多方面得到改進[4,5,12,17,33,50,64]。DAB-DETR [31]引入了錨框作為DETR查詢,以進行更準確的框預測。DN-DETR [24]提出了查詢去噪以穩定匹配。DINO [58]進一步開發了幾種技術,在COCO物體檢測基準測試中刷新了記錄。然而,這些檢測器主要側重于封閉集檢測,很難推廣到新類別,因為預定義類別有限。
開放集物體檢測。開放集物體檢測使用現有的邊界框注釋進行訓練,目的是檢測任意類別的對象,語言泛化提供幫助。OV-DETR [57]使用由CLIP模型編碼的圖像和文本嵌入作為查詢,以在DETR框架中解碼類別指定的框。ViLD [13]從CLIP老師模型中蒸餾知識到類似R-CNN的檢測器,以便學習到的區域嵌入包含語言的語義。GLIP [11]將物體檢測形式化為定位問題,利用額外的定位數據幫助學習短語和區域層面上的語義對齊。它顯示這樣的表述甚至可以在完全監督的檢測基準測試上取得更強的性能。DetCLIP [53]涉及大規模圖像字幕數據集,并使用生成的偽標簽來擴展知識數據庫。生成的偽標簽有效幫助擴展檢測器的泛化能力。
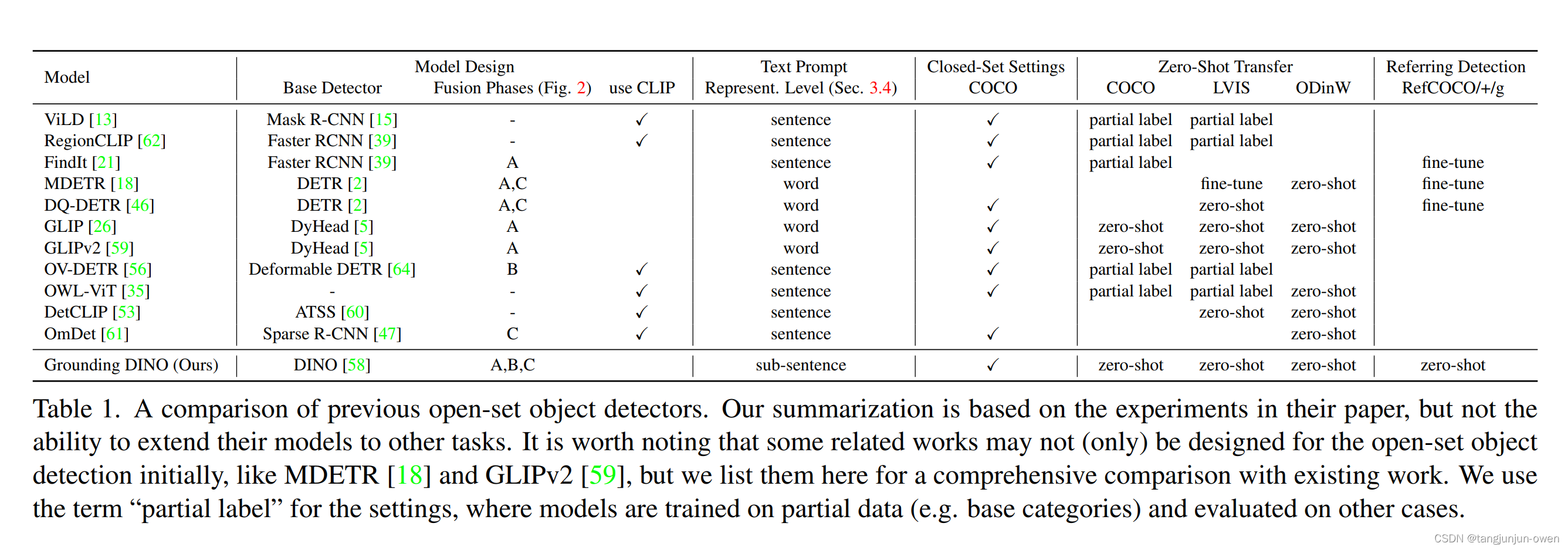
然而,以前的工作只在部分階段融合多模態信息,這可能會導致次優的語言泛化能力。例如,GLIP僅考慮在特征增強(階段A)中進行融合,而OV-DETR僅在解碼器輸入(階段B)處注入語言信息。此外,REC任務在評估中通常被忽視,這是開放集檢測的一個重要場景。我們在表1中比較了我們的模型與其他開放集方法。
4、貢獻
- 我們提出了Grounding DINO,它通過在多個階段執行視覺語言模態融合來擴展封閉集檢測器DINO,包括特征增強器、語言指導的查詢選擇模塊和跨模態解碼器。 這種深度融合策略有效改進了開放集物體檢測。
- 我們提出將開放集物體檢測的評估擴展到REC數據集。 它有助于評估模型對自由文本輸入的性能。
- 在COCO、LVIS、ODinW和RefCOCO/+/g數據集上的實驗表明,Grounding DINO在開放集物體檢測任務上的有效性。
5、模型結構解讀
模型整體框架為block1坐標,特征增強層為block2右下角,解碼層為block3右上角,我將大概說下這三個block內容。
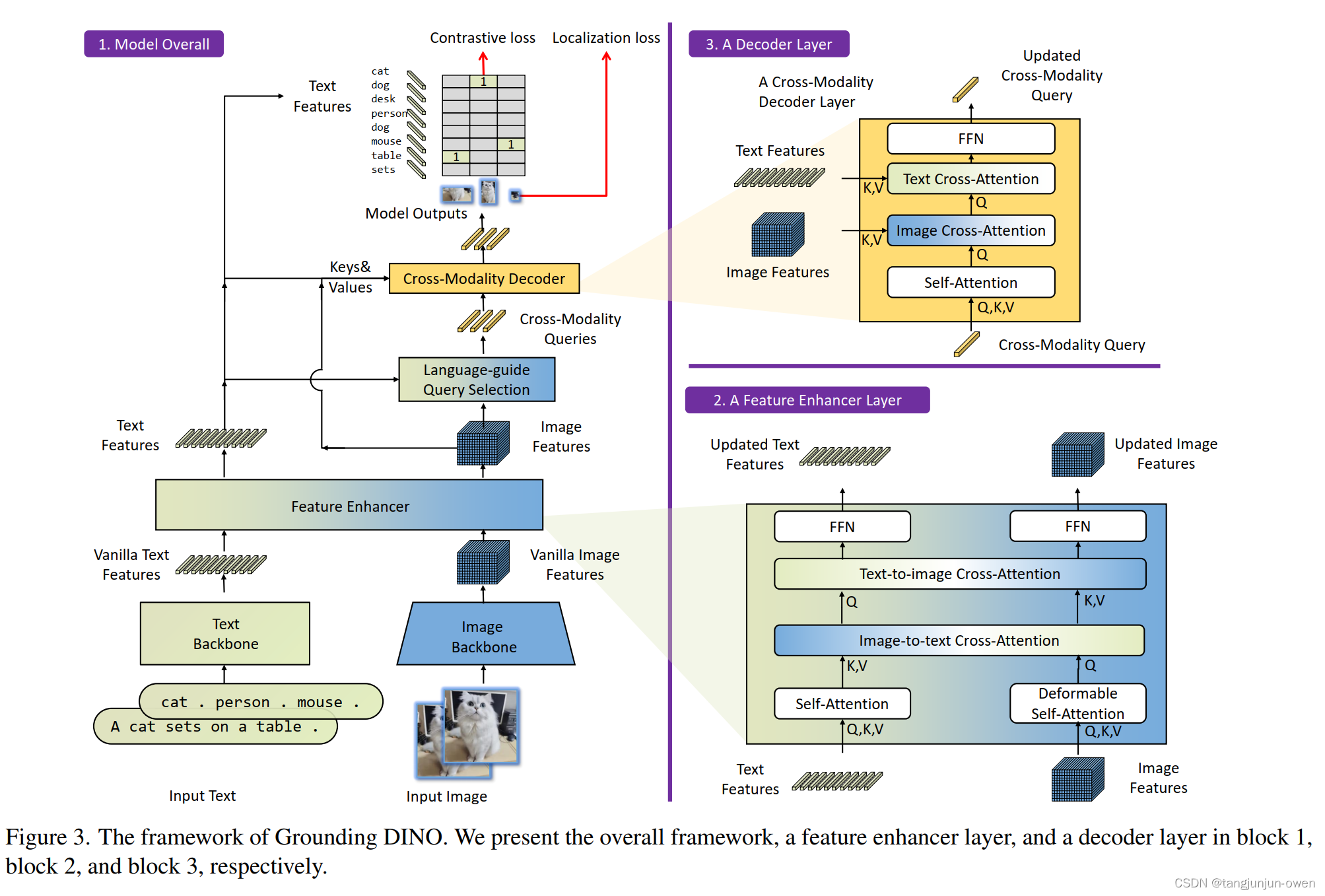
a.模型整體結構
block1內容:最下面可看出文本tag使用的文本特征提取的backbone,而圖像使用圖像特征提取的backbone,這2個是獨立的;其次中將層feature enhancer為block2我待會再說;然后繼續往上,可看到text feature基本結束,類似clip圖像特征與最終圖像特征做相似度匹配,而中間文本特征還往右圖的圖像特征做了或引導或KV特征;右邊image features向上接受文本特征指引,隨后在向上為解碼模塊block3,我將在下面介紹。
b.特征增強結構
block2內容:特征增強,即特征融合方式,文本與特征分別使用自注意力attention結構,隨后圖像提供Q在提供KV實現圖像特征輸出;文本提供KV在提供Q實現文本特征輸出。(這里細節建議查看源碼,但這里思路可借鑒)
c.解碼結構
block3內容:實際是為圖像特征解碼做后面圖像與文本特征匹配與定位任務,首先文本特征駛向圖像特征完成文本指導,從圖中看是做了cross-Modality,大膽猜測文本為Q、圖像為KV的融合,隨后再成Q分別再次將圖像特征KV進行attention,獲得結果再次作為Q對文本特征KV進行attention,最終為圖像特征輸出。
6、實驗有趣說明
有趣的是,在相同設置下,DINO預訓練的Grounding DINO優于標準Grounding DINO在LVIS上的性能。結果表明模型訓練還有很大的改進空間,這將是我們未來要探索的方向。
二、TAG2TEXT: GUIDING VISION-LANGUAGE MODEL VIA IMAGE TAGGING
1、摘要
本文介紹了 Tag2Text,一種視覺語言預訓練 (VLP) 框架,它將圖像標記引入視覺語言模型以指導視覺語言特征的學習。與使用手動標記或使用有限檢測器自動檢測的對象標簽的先前工作相比,我們的方法利用從其配對文本解析的標簽來學習圖像標記器,同時為視覺語言模型提供指導。鑒于此,Tag2Text 可以根據圖像文本對使用大規模無注釋圖像標簽,并提供超越對象的更多樣化的標簽類別。因此,Tag2Text 通過利用細粒度的文本信息實現了卓越的圖像標簽識別能力。此外,通過利用標記指導,Tag2Text 有效地增強了視覺語言模型在基于生成和基于對齊的任務上的性能。在廣泛的下游基準測試中,Tag2Text 以相似的模型大小和數據規模取得了最先進或有競爭力的結果,證明了所提出的標記指南的有效性。

注:文章核心是將tag引入到VL模型且提供tag制作方法。
2、背景
①表示先前研究基于檢測器范式將tag引入檢測器中,該方法是有效的,②表示提取圖像特征,將這些特征送入多模態圖像文本交互校準。然這些方法限制了檢測模型能力且耗時, 近期研究者使用如何避免這樣問題的方法,但結果表明其方法不能有效使用tag信息,③為圖像tag指引,使用一個簡單tag相關head頭將圖像tag引入②中detector-free VL模型中且憑借文本解析圖像圖像對應的tag去監督引入頭,而我們完成監督tagging能力模型方法,且有效增強視覺語言任務性能。b圖顯示我們與基于目標檢測范式的內容比較。
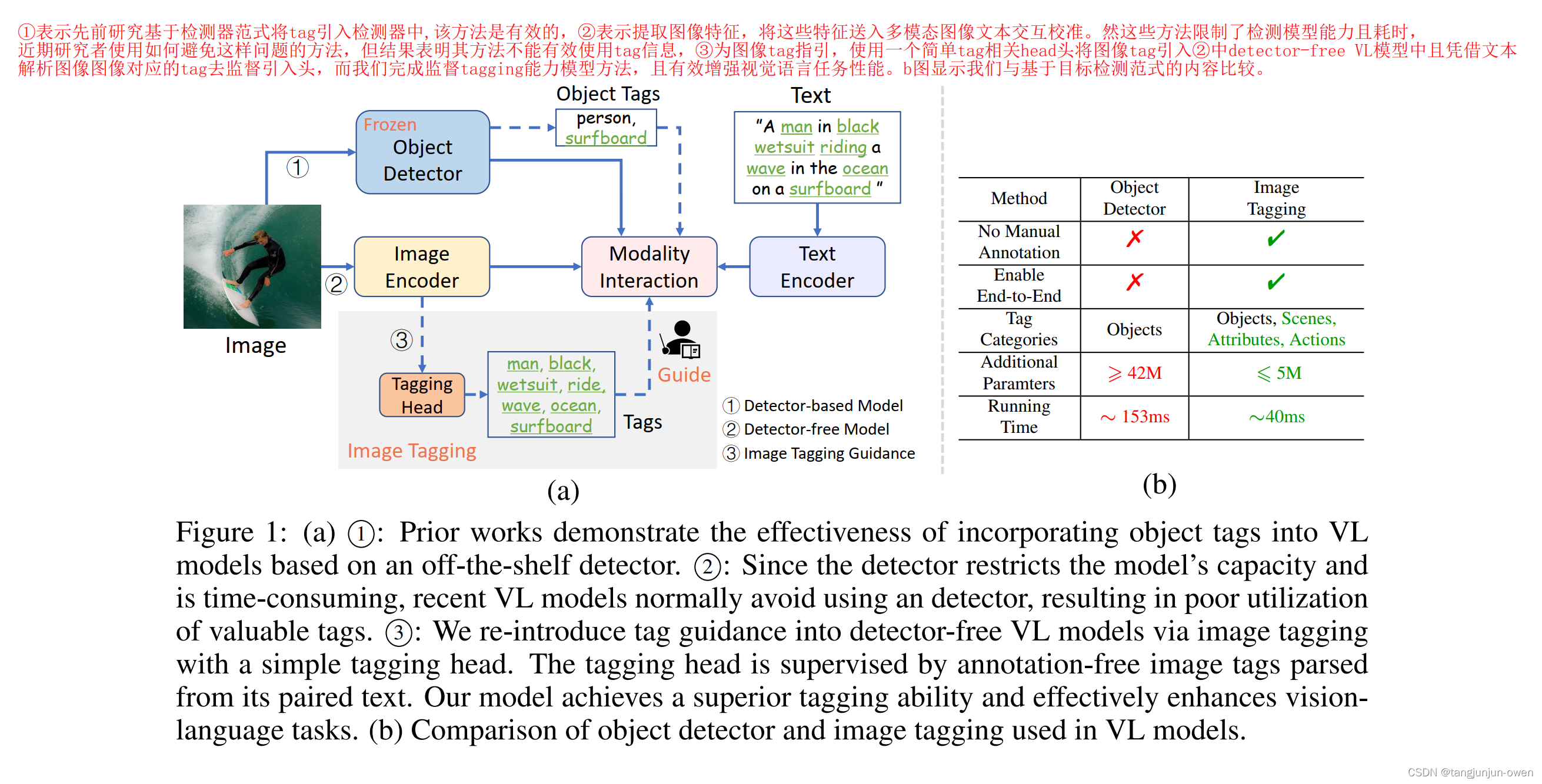
作者提出引入tag作為視覺-文本任務,有兩個關鍵問題:數據和網絡結構,其中數據也是本文提出的重點,如何構造圖片的tag作為 label訓練。實際image-text對數據很豐富,作者使用文本語義解析在text中獲取圖片對應tags。這樣,圖像tags能提供了圖像和文本之間更好的橋梁,解析的標記類別更加多樣化,比目標檢測的object更豐富,有例如場景、屬性、動作等。這就是數據發揮的重要作用。模型結構我將在下節介紹。
3、貢獻
1、首先,證明了tag2text模型利用現成圖像文本對解析的tag訓練的模型在imge tagging能力,且zero-shot能力與全監督方法相當。
2、tag2text使用tag指導方式通過imamge tagging無縫連接整合現有vlm模型中,有效增強生成任務與校準任務的能力。
3、 一系列下游任務實驗等,證明了tagging能力,且說明了tagging 引導信息整合到VLM模型的有效性。

5、模型結構解讀
模型結構包含3個分支:Tagging, Generation, Alignment,為不同的任務分支,多標簽識別(就是tagging),Image Caption圖像解說,Image-Text對齊。其中核心為tagging分支。
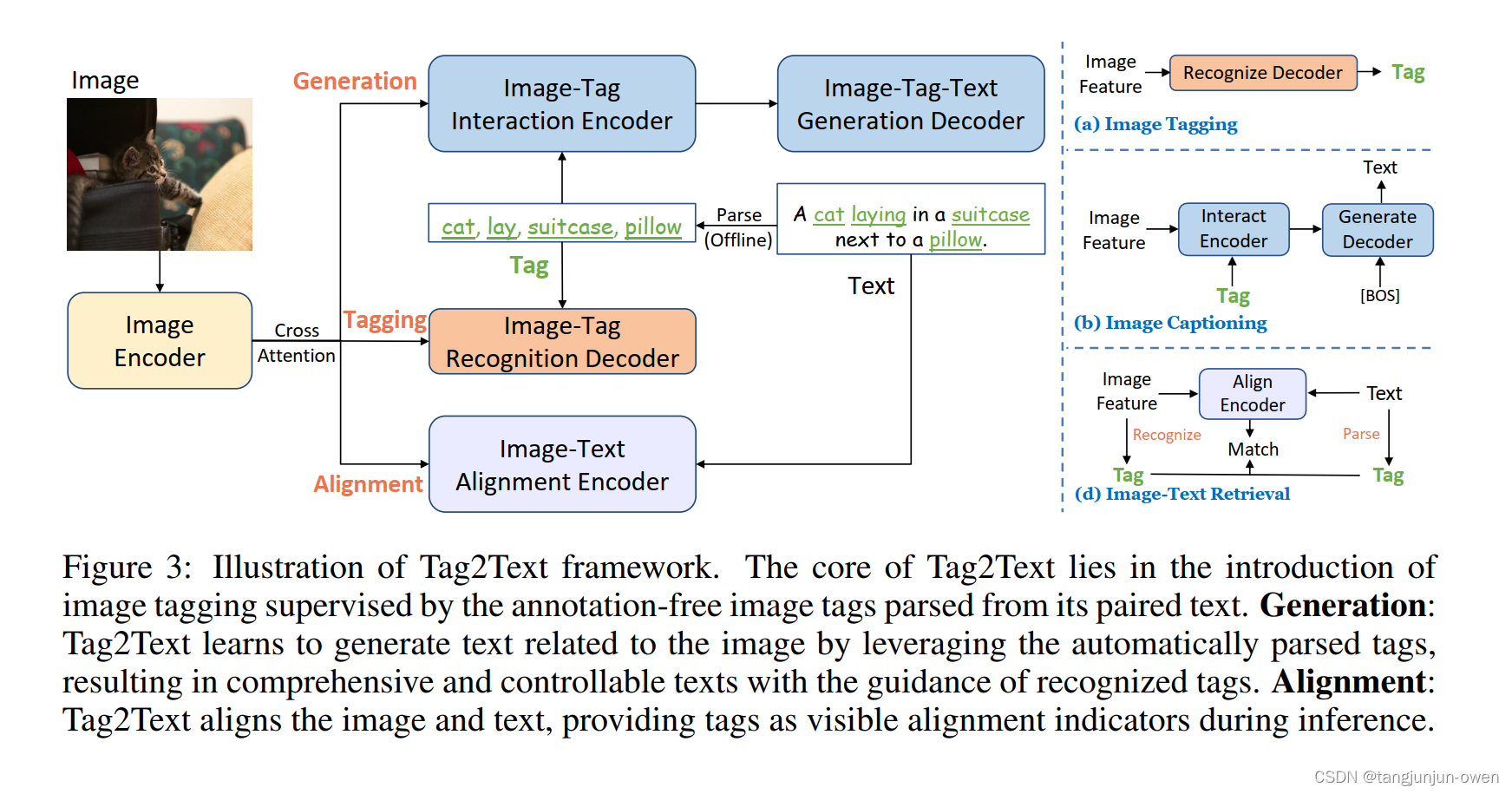
Tagging:用了Query2Label中的多label分類transformer decoder,同時為了避免解析的tags中有某些對應圖片tag的缺失、正負樣本的不平衡,使用了Asymmetirc Loss。
Generation:用了NLP中標準的transformer的編解碼encoder-decoder框架,tags/text 映射為 embeding,然后 tags embeding(隨機亂序,防止順序影響學習)與 image embedding(features) 一起送入 encoder,再經過decoder解碼。輸出與text embedding進行loss計算,相當于用 tag 指導 image 生成 text。
Image-Text Alignment:用了BLIP中 Encoder 結構,image embedding 與 text embeding送入encoder,用粗粒度的 Image-Text Contrastive(ITC) Loss 和 細粒度的 Image-Text Matching(ITM) Loss 分別進行監督。
三、Recognize Anything: A Strong Image Tagging Model
1、摘要
我們提出了RAM模型,一個image tagging任務的基準模型。ram在計算視覺中邁出一大步,能帶有很高精度與zero-shot能力,識別任意類別。ram在image tagging任務中提出了新的范式,利用大量圖像-文本對訓練,從而替換了人工標注工作。RAM分四個步驟,第一通過自動文本語義解析獲得image-text標簽;第二訓練一個統一描述與標簽的初始模型;第三數據引擎用來生成額外注釋和清除不對的數據;第四模型通過預訓練并使用精度高標注的數據做fitune訓練。作者也在多個基準上測試模型,性能已超過CLIP與BLIP能力。

2、背景/引言
LLM因其大數據在NLP領域很火,這些模型展現更好zero-shot能力,且能處理超出訓練領域外的任務與數據分布。說到cv領域,SAM模型因大數據訓練,已被證明有很強的定位能力。
然而sam模型缺乏輸出語義標簽能力。多標簽圖像識別是眾所周知的image tagging,目的是通過給定多標簽圖像識別語義標簽。image tagging是一個重要而具有現實意義的視覺任務,多標簽可包含目標標簽、場景、屬性和行為。遺憾的是,存在多標簽分類、檢測、分割和視覺語言方法在tagging中存在缺陷,為受限范圍與精度(與本文ram可識別一切相比),如圖1描述,sam定位能力很強但無法識別,與ram相比,ram能給出識別能力且不受scope與accuracy限制(個人理解scope有5000多個類當然scope大了,accuracy因大大數據使其性能好了)。
自然引出網格核心問題,一個是數據制作一個是模型結構。
沒有更強識別能力,可突破scope與accuracy限制
3、數據獲得
Tag2Text利用 image-text-pair 的 text 進行解析,得到 tags,高頻排序篩選前top-5k的標簽,頻率越高越重要。而RAM進一步擴大了數據量,篩選擴大到top-10k。原文具體做法如下:
標簽系統:我們首先建立一個通用和統一的標簽系統。我們結合了來自流行學術數據集(分類、檢測和分割)以及商業標記產品(谷歌、微軟、蘋果)的類別。我們的標簽系統是通過將所有公共標簽與文本中的公共標簽合并而獲得的,從而覆蓋了大多數公共標簽,數量適中,為 6,449。剩余的開放詞匯標簽可以通過開放集識別來識別。
數據集:如何用標簽系統自動標注大規模圖像是另一個挑戰[30]。從 CLIP [22] 和 ALIGN [11] 中汲取靈感,它們大規模利用公開可用的圖像文本對來訓練強大的視覺模型,我們采用類似的數據集進行圖像標記。為了利用這些大規模圖像文本數據進行標記,按照[9、10],我們解析文本并通過自動文本語義解析獲得圖像標簽。這個過程使我們能夠根據圖像文本對獲得各種各樣的無注釋圖像標簽。
數據引擎:然而,來自網絡的圖像文本對本質上是嘈雜的,通常包含缺失或不正確的標簽。為了提高注釋的質量,我們設計了一個標記數據引擎。在解決丟失的標簽時,我們利用現有模型生成額外的標簽。對于不正確的標簽,我們首先定位與圖像中不同標簽對應的特定區域。隨后,我們采用區域聚類技術來識別和消除同一類中的異常值。此外,我們過濾掉在整個圖像及其相應區域之間表現出相反預測的標簽,確保更清晰和更準確的注釋。
4、貢獻
1.Strong and general(強大的圖片tag能力):實驗說明在zero-shot上RAM的tags能力更強;
2.Reproducible and affordable(低成本復現與標注):可需要更少數據work,最強版本需要3天8張A100訓練
3.Flexible and versatile(靈活且滿足各種應用場景):可以單獨使用作為標記系統,應用場景廣,通過選擇特殊類,ram能直接解決特殊類需要,能進一步和grounding dino結合實現語義分析(tag給grounding dino實現框定位等)
5、模型結構解讀
RAM模型架構如圖,大量圖像對應tags數據通過自動文本語義解析模型從圖像文本對中獲得(現有數據很多)。在圖像、標簽、文本三塊中,RAM實現圖像caption與tagging任務。特別,RAM引入了一個現成的文本編碼器,將標簽編碼器到語義豐富的文本標簽查詢中,從而在訓練階段實現對未知類別的泛化。
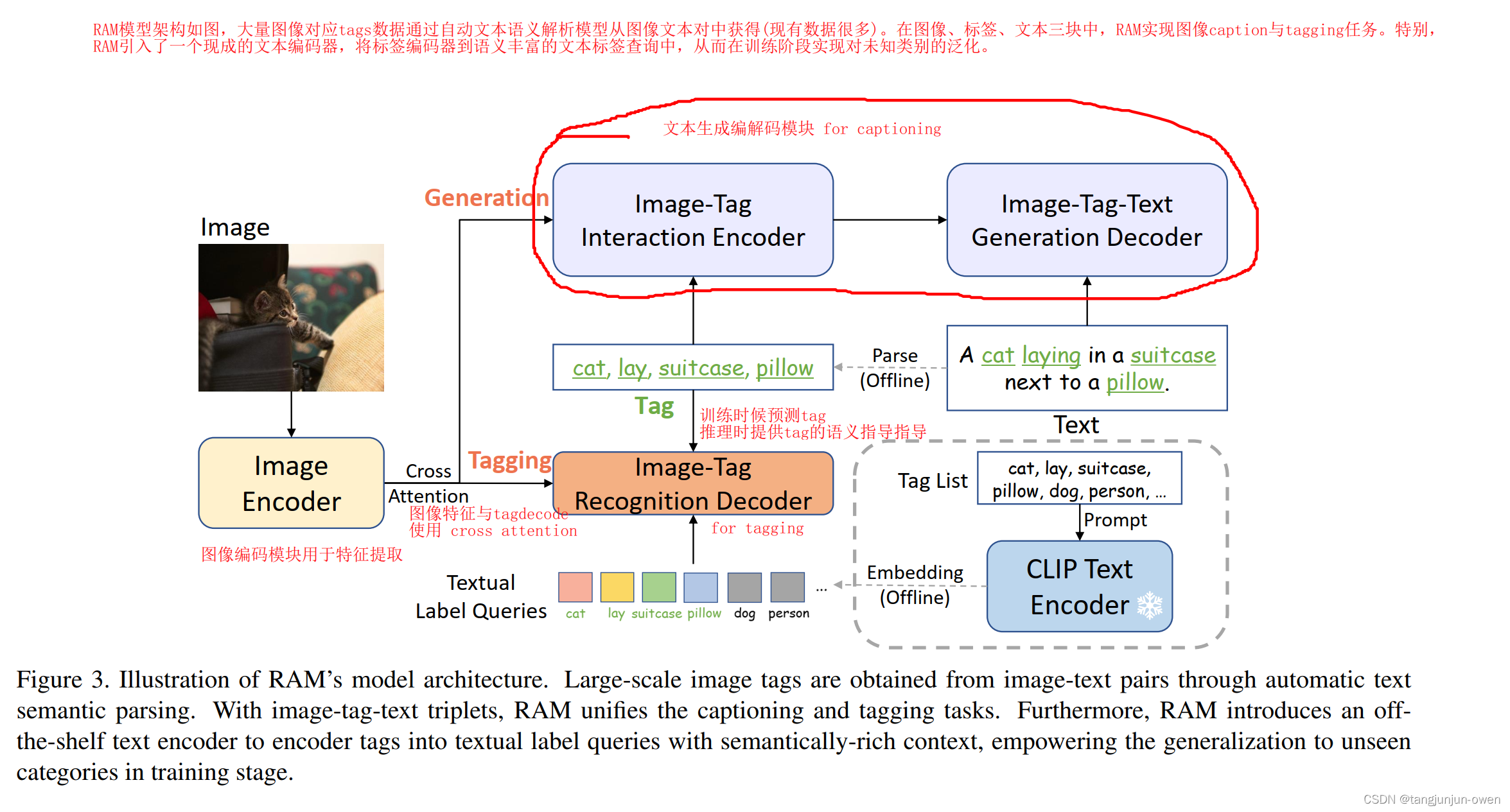
該模型屏蔽了tag2text的alignment分支,只有tagging與generation分支。
Tagging 分支用來多tags推理,完成識別任務;
Generation用來做 image caption任務;
Image Encoder 使用 Swin訓練時,Tagging分支和Generation分支都用解析的Tags作為label;
測試時,Tagging會輸出Tags,用于Generation的Caption任務生成最終的Text;
這里與tag2text最大不同在與CLIP的使用,作者把每個Tag進行prompt ensembling[22] 擴充,然后送入訓好的CLIP Text Encoder得到其對應的文本標簽查詢(Textual label queries,其實就是 promopt + tag 的 embedding),作者認為這些 queries 比可學習的參數有更強的語義性和上下文信息。然后將這些Label Queris送進Tagging Decoder用image features進行Cross Attention。
引用該篇博客進一步解釋:點擊這里
1)訓練過程沒有上圖右側的CLIP Text Encoder。N個類別對應N個textual label queries——也就是可學習的參數,假設論文4585個類,每個類768維度表示,那么就是4585*768。
2)訓練輸入是三個元素:圖片-Tag-文本構成,對應網絡的一個輸入(圖像,文本輸入不算,是網絡自己的可學習參數)+ 2個輸出(文本描述和多標簽分類)。損失也就是常見的文本生成損失+多標簽ASL損失。
3)image-Tag-interaction encoder 的文本輸入是label 解析的Tag,不是模型的輸出(推理時是模型的輸出)
4)訓練過程的某個節點(論文沒有詳細說)使用了CLIP image encoder 的輸出進行蒸餾(distill)RAM 自己的image encoder。(這個我的理解是潛在對齊了CLIP Text encoder ,才更好的實現了后面推理階段的open set 的識別。)
個人覺得比較重要是CLIP引用的蒸餾方式。
四、Inject Semantic Concepts into Image Tagging for Open-Set Recognition
1、摘要
在這篇論文中,我們引入了RAM++模型,一個在open-set很強能力的圖像識別模型,該方法引入semantic concepts到圖像tag中去訓練的框架。對比先前方法要么是image tagging模塊受有限語義制約,要么視覺語言模型淺交互在multi-tag識別中獲得次優性能。相比與RAM++模型,該方法基于image-tags-text triplets整合圖像文本校準與圖像taging為統一細粒度交互框架。這種設計使RAM++能識別定義類,更重要是有識別open-set類的能力。RAM++利用LLMS生成多樣可視的tag描述,首創使用LLM知識融合到圖像 tagging訓練中。在open-set識別中整合視覺藐視concepts進行推理。實驗在多個圖像識別基準中表明了RAM++圖像識別方面取得了SOTA。

2、背景/引言
圖像識別已經是研究者長期研究領域,使機器從被給圖像中自動識別語義內容輸出。隨著自然語言過程[3,36]和圖像定位[21,26]等領域基礎模型的出現,構建圖像識別基礎模型具有重要意義,一個圖像識別基準應該有更強的泛化能力,能在任意視覺概念數據中有效.
image recognition有2種研究方向:
image tagging是大家熟知的多標簽識別,該方法主要依賴有標注的數據,而受數據限制,模型結果也都在特定數據與特定類表現很好;
vision-language是視覺語言模型,該方法基于大量圖像文本對實現圖像文本校準,其代表文章為CLIP,該文章有很強open-set能力,也能在其它領域泛化,如open-set object detection [15], image segmentation [15] and video tasks [32]
盡管CLIP在一圖單標簽的zero-shot效果顯著,但是它的視覺語言交互是粗糙的使用點乘獲得相關性,這樣方式很困難處理更多現實細粒度image tagging tasks。近期RAM構建自動在圖像文本對中獲得tag方式,構建了綜合的標簽系統over 4500類,提取圖像tag 標注。基于更細粒度image tagging模型框架,與CLIP對比,ram在識別tag中證明提升很大。
然而,ram缺陷是不能識別超過預定的類別,這就因固定類中限制其ram語義生成能力(只能固定提取),結果也限制RAM模型隱藏更多能力,舉個列子,系統標簽只有恐龍標簽,模型最多只知道子標簽霸王龍或三角龍。更多豐富語義如摔倒人等受到挑戰。為解決這樣限制問題,我們引用語義概念到圖像tagging中。具體的,我們將提出2個方法, Image-Text Alignment and LLM-Based Tag Description.
Image-Text Alignment :圖像文本對齊,我們設計兼備CLIP與RAM優勢,整合到image tagging結構中。這種設計能使模型在訓練期間學習超過固定類限制的更廣問題語義信息。這個對齊架構是基于細粒度視覺語言特征交互,結合online/offline設置,我們的模型能更好平衡效率與性能。
LLM-Based Tag Description:對于LLM-Based Tag Description,近期研究利用LLM增強識別模型。基于此,我們也將LLM知識整合到image tagging訓練。特別地,我們采用LLM為每個tag類自動生成豐富的視覺描述,并與tag合并成embedding去與圖像特征對齊。這樣方法進一步引入豐富語義信息到模型中,在推理期間合并視覺概念到開放詞匯任務。除此之外,我們對tag類別的多視覺描述設計了自動權重re-weighting機制,在沒有額外消耗下進一步增強性能。
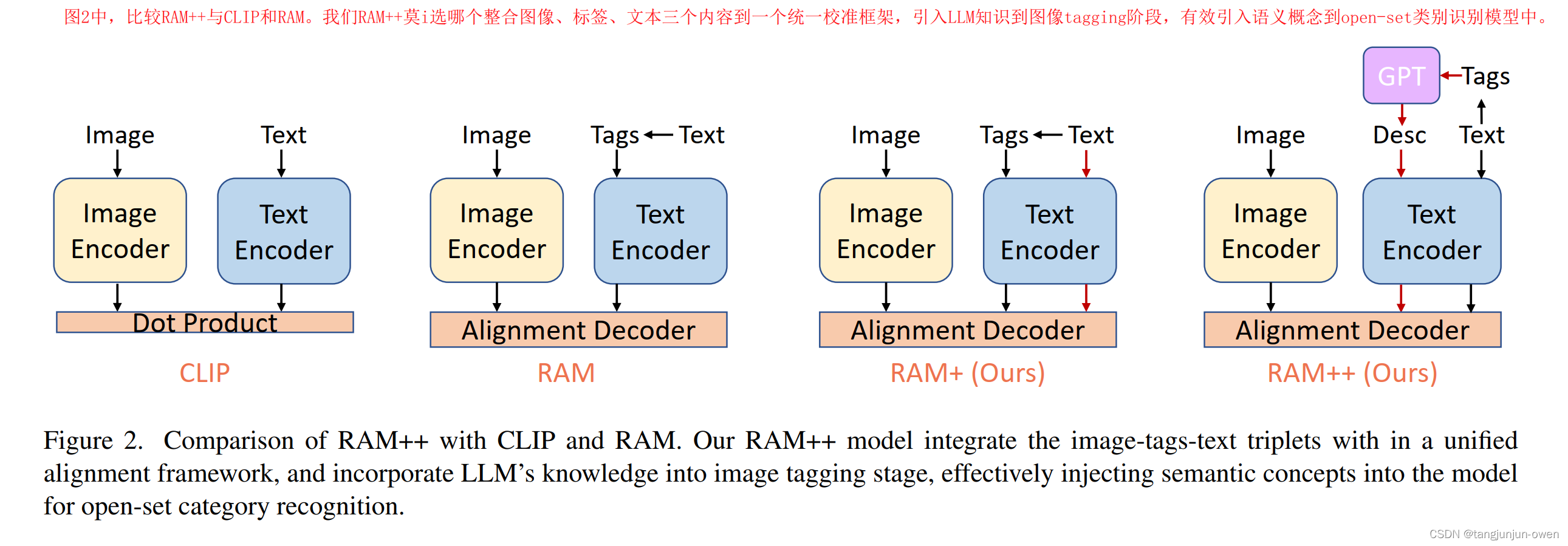
3、CLIP-RAM-RAM++模型結構對比
圖2中,比較RAM++與CLIP和RAM。我們RAM++莫i選哪個整合圖像、標簽、文本三個內容到一個統一校準框架,引入LLM知識到圖像tagging階段,有效引入語義概念到open-set類別識別模型中。
4、貢獻
1、我們整合image-tags-texts信息統一到aligment架構中,這種方式不僅在預定義tag類別更好work,還在open-set類別中也work。
2、據我們所知,我們研究是第一個將LLM模型知識整合到image tagging任務中,讓模型在推理期間能整合open-set類別識別的視覺描述concept(利用llm獲得概念就可在圖像中識別未知類)。
3、作者又是一大堆benchmark實驗,證明模型有效與sota。
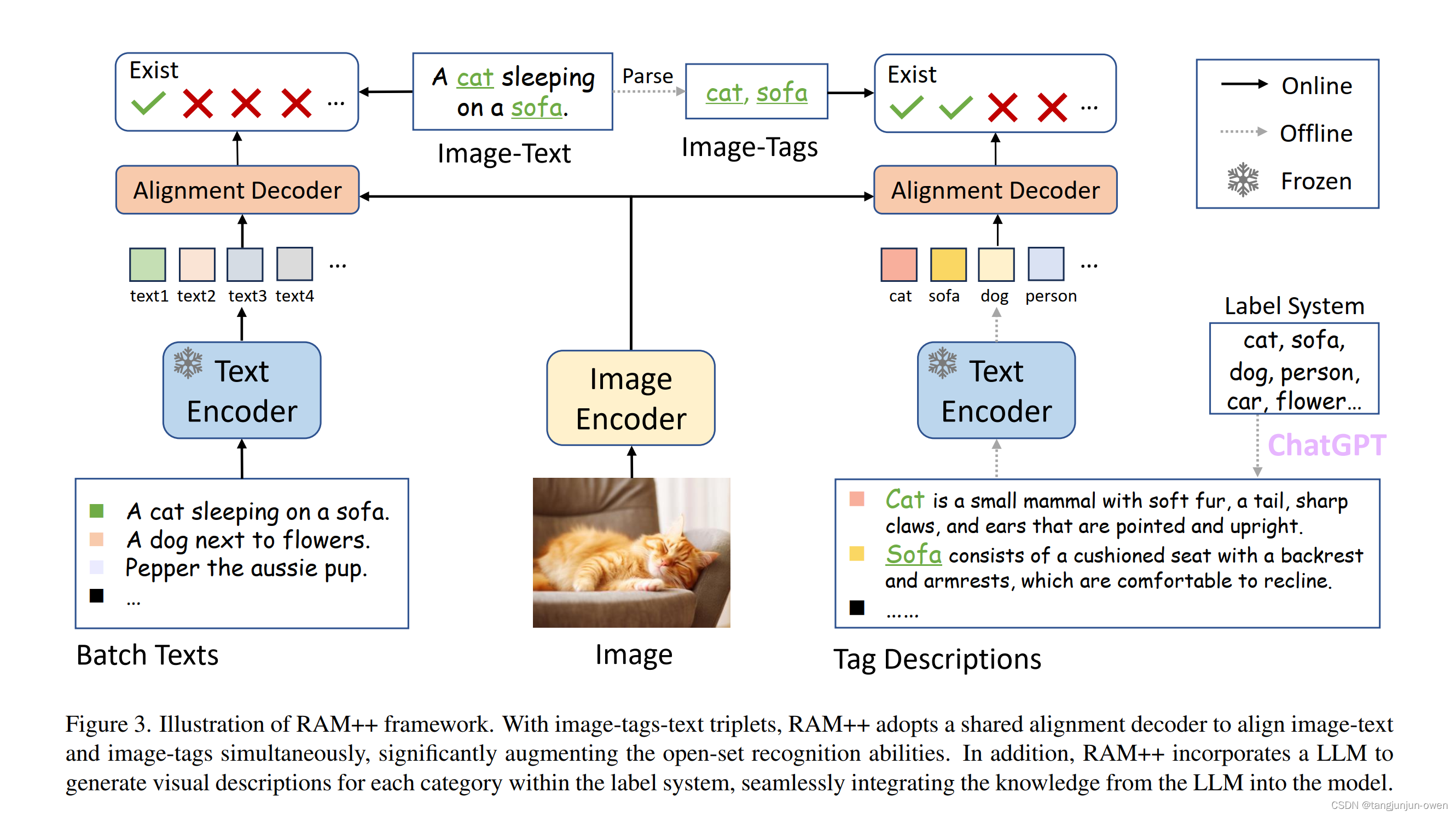
5、模型結構解讀
還是三個信息內容圖像image、標簽tags、文本text內容,RAM++采用共享alignment decode去校準圖像文本(左邊)與圖像標簽(右邊),這樣能顯著增強open-set識別能力。除此之外RAM++整合LLM模型為每個類別生成視覺描述,將LLM的知識整合到模型中。而這篇文章最大特點是引入LLM模型,這樣就有更多的語義描述信息,具體如下:
總結
第一篇是標簽定位內容;
第二篇是tag引入模型;
第三篇是修改模型架構與數據制作方式;
第四篇是在第三篇基礎上引入LLM模型與共享align decode結構;


數據增強)








(模擬,c++,vector建二叉樹))







