機器學習與人工智能:一場革命性的變革
- 人工智能的概述
- 什么是機器學習
- 定義
- 解釋
- 數據集結構
- 機器學習應用場景
人工智能的概述
1956年8月,在美國漢諾斯小鎮寧靜的達特茅斯學院中,約翰·麥卡錫(John McCarthy)、馬文·閔斯基(MarvinMinsky,人工智能與認知學專家)、克勞德·香農(Claude Shannon,信息論的創始人)、艾倫·紐厄爾(AllenNewell,計算機科學家)、赫伯特·西蒙(Herbert Simon,諾貝爾經濟學獎得主)等科學家正聚在一起,討論著一個完全不食人間煙火的主題:用機器來模仿人類學習以及其他方面的智能,會議足足開了兩個月的時間,雖然大家沒有達成普遍的共識,但是卻為會議討論的內容起了一個名字:人工智能,因此,1956年也就成為了人工智能元年。
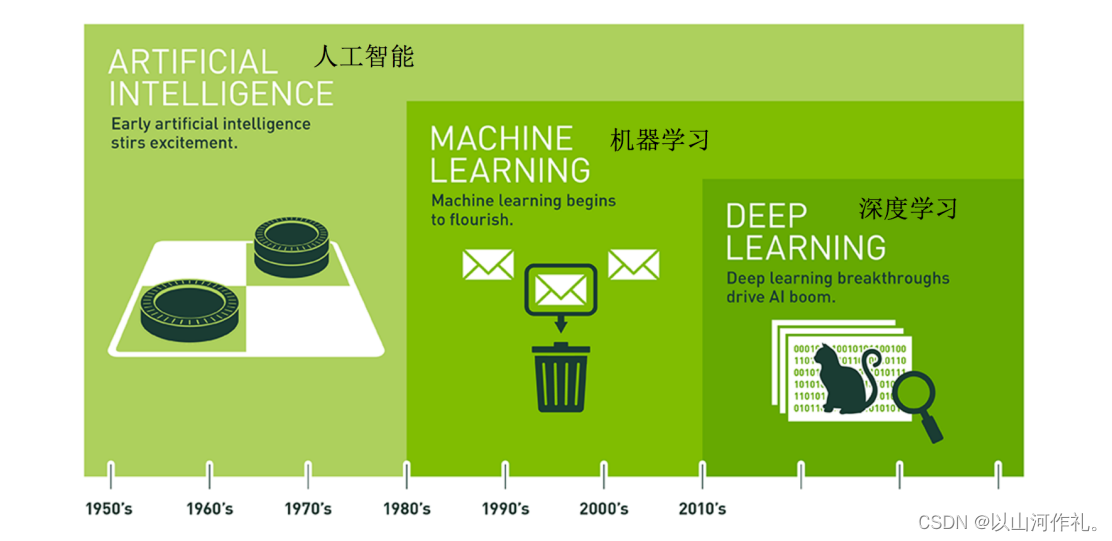
達特茅斯會議-人工智能的起點
- 人工智能、機器學習與深度學習的關系
- 機器學習是人工智能的一個實現途徑
- 深度學習是機器學習的一個方法發展而來
什么是機器學習
定義
湯姆·米切爾(Tom M.Mitchell,機器學習之父):A computer program is said to learn from experienceE with respect to some class of tasks T and performance measure P if its performance at tasks in T, asmeasured by P, improves with experience E.
假設用性能度量P來評估機器在完成某類任務T的性能,如果該機器利用經驗E(即數據D)在任務T中改善了其性能度量P,那么可以說機器對經驗E進行了學習,即機器學習
機器學習是從歷史數據中分析獲得算法模型,并利用算法模型對未知數據進行預測.
解釋
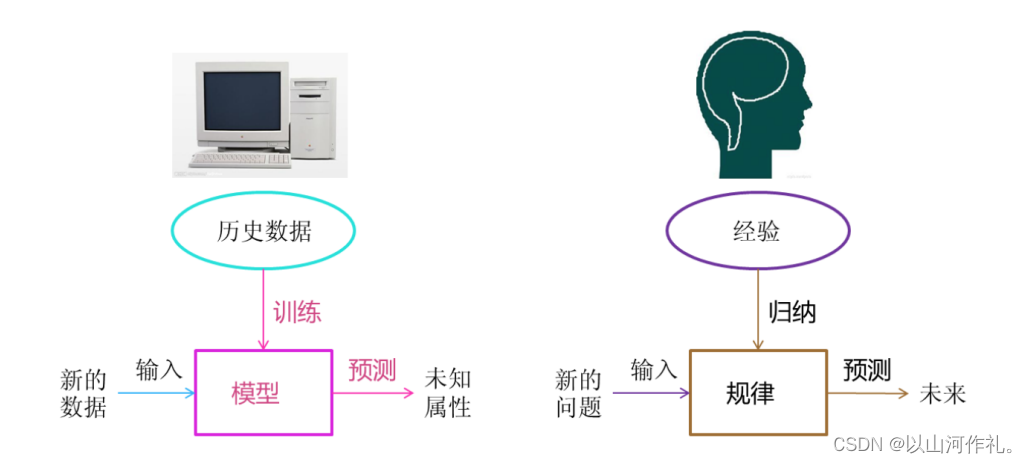
我們人從大量的日常經驗中歸納規律,當面臨新的問題的時候,就可以利用以往總結的規律去分析現實狀況,采取最佳策略。

從數據(大量的貓和狗的圖片)中自動分析獲得模型(辨別貓和狗的規律),從而使機器擁有識別貓和狗的能力。

從數據(房屋的各種信息)中自動分析獲得模型(判斷房屋價格的規律),從而使機器擁有預測房屋價格的能力。
數據集結構
從歷史數據中獲得規律?那么歷史數據是什么樣的格式?
- 數據集結構:
特征值+目標值
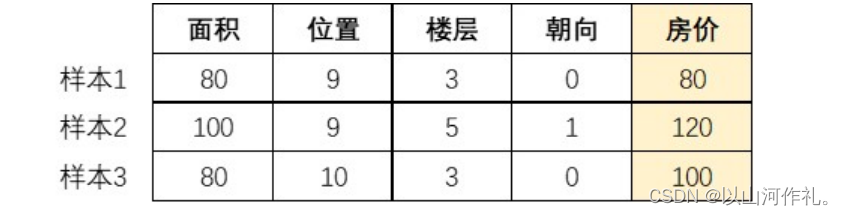
- 每行數據,稱為
樣本(sample)或實例(instance) - 研究對象的性質,例如面積、位置、樓層、朝向,稱為
特征(feature)或輸入(input) - 特征的具體數值,例如【樣本1】對應的80、9、3、0,稱為
特征值(feature value) - 樣本的結果信息,例如【樣本1】的房價為80,稱為
標簽(label)或目標(target)或輸出(output) - 從數據中學習得到模型的過程稱為
學習(learn)或訓練(train) - 用于訓練模型的樣本數據集稱為
訓練集(train set) - 用于測試模型的樣本數據集稱為
測試集(test set)
注意:有些數據集可以沒有目標值

機器學習應用場景
機器學習的應用場景非常廣泛,可以說滲透各行各業,例如醫療、航空、教育、物流、電商等領域的各種場景
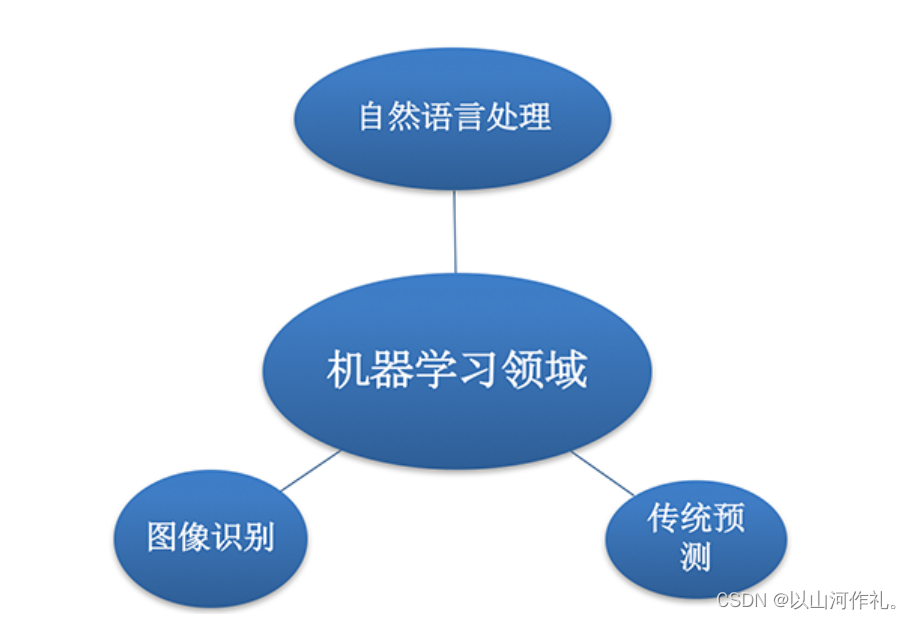
用在挖掘、預測領域:
應用場景:店鋪銷量預測、量化投資、廣告推薦、企業客戶分類等
用在圖像領域:
應用場景:街道交通標志檢測、人臉識別等

用在自然語言處理領域:
應用場景:文本分類、情感分析、自動聊天、文本檢測等






實驗一:HTML5排版標簽使用)












-terraform創建阿里云資源)