Pytorch團隊提出了一種純粹通過PyTorch新特性在的自下而上的優化LLM方法,包括:
Torch.compile: PyTorch模型的編譯器
GPU量化:通過降低精度操作來加速模型
推測解碼:使用一個小的“草稿”模型來加速llm來預測一個大的“目標”模型的輸出
張量并行:通過在多個設備上運行模型來加速模型。
我們來看看這些方法的性能比較:
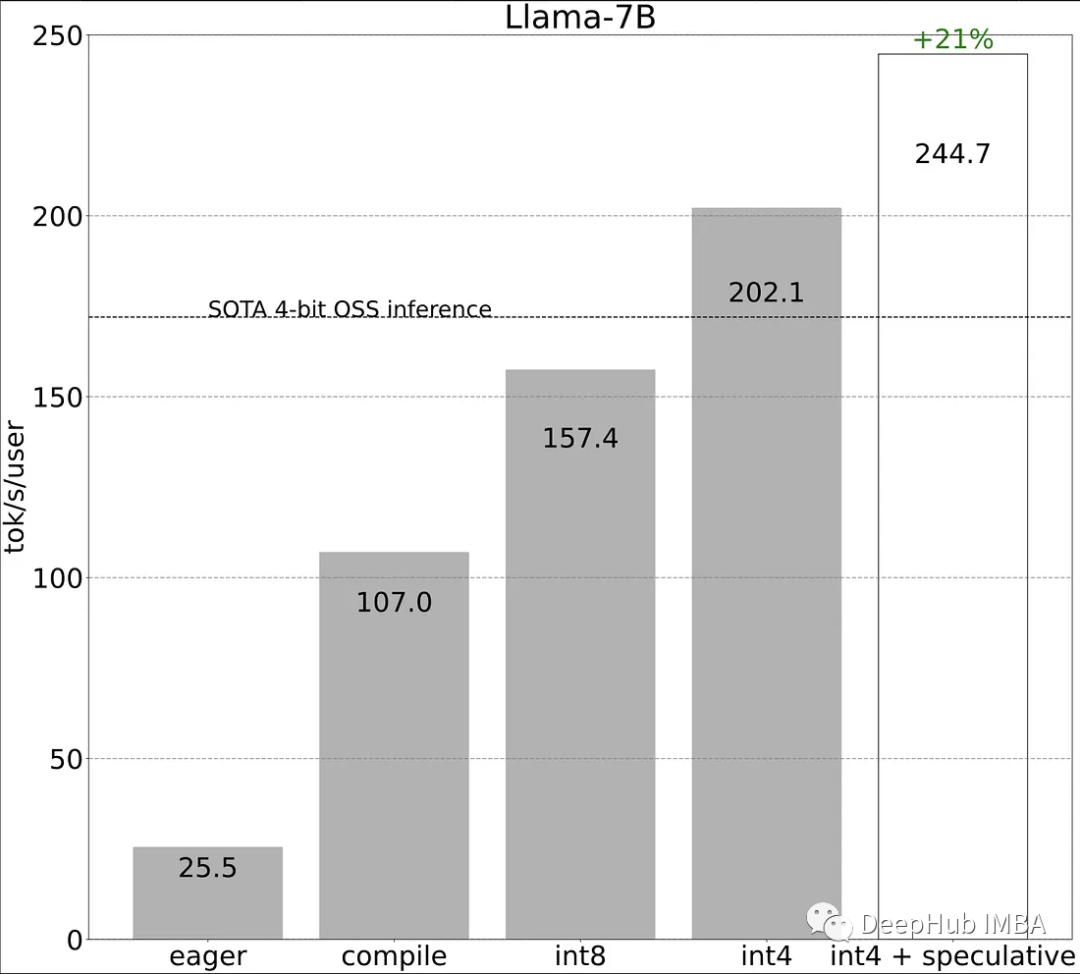
作為對比,傳統的方式進行LLaMA-7b的推理性能為25tokens/秒,我們來看看看這些方法對推理性能的提高。
使用新的編譯器和分配(76 TOK/S):
Pytorch分析了cpu限制的性能問題。這意味著編譯開銷是提高效率的首要目標。
所以使用編譯器將較大的區域編譯為預編譯狀態,每個操作的CPU調用數量會減少。這意味著該包裝器現在可以在沒有間隙的情況下執行,如下所示。

代碼也非常簡單:
torch.compile(decode_one_token, mode="reduce-overhead", fullgraph=True)
當生成更多令牌時,kv-cache會增長,每次緩存增長時都需要重新分配和復制(昂貴的計算)。聲明大緩存以允許最大大小。
在預填充階段需要分別編譯兩種策略。整個提示被動態處理,令牌被解碼為上面所示的代碼。保持這些策略并行可以進一步優化。單獨使用這兩種策略,可以獲得3倍的推理性能提高。
消除內存瓶頸,(102 TOK/S)
以靜態方式為緩存分配最大內存時,會使內存問題變得更糟,因為我們上面只是讓CPU計算更加高效,比如緩存肯定會加大內存的使用。
優化內存的最簡單方式就是量化。量化試圖將權重和計算轉換為Int8甚至Int4——這將矩陣的大小減少了4 - 16倍,從而在矩陣操作期間大量節省內存。
如果有72億個參數需要處理,每個權重需要2字節(fp16)來保存;我們可以計算每秒生成100個令牌所需的帶寬。這意味著,要以每秒100個令牌的速度運行推理,我們需要處理總計1.4TB的內存吞吐量。A100的理論上限為2Tb/s,這意味著使用72%的帶寬(沒有瓶頸),A100可以輕松地每秒運行100個令牌。這取決于你的GPU,如果你是4090呢,大家可以計算一下,4090具有1008GBPS的內存帶寬,基本上就是少了一半還要少一些。
重構問題(157.4 TOK/s)
假設對于要生成的每個新單詞,要一次又一次地加載和處理所有標記。在自回歸世代中我們不需要序列依賴。我們可以使用草稿模型和驗證模型(緩慢但準確)并行生成下8個令牌,作為8個副本來驗證生成。與驗證器不匹配的草稿模型輸出將被丟棄。

根據Pytorch文檔,它不會降低生成文本的質量。實驗也證明了這一點。當運行codellam - 34b + codellam - 7b時,能夠在生成代碼時獲得2倍的token /s提升。當使用Llama-7B + TinyLlama-1B時,在token /s中獲得1.3倍的提升。
Int4 (202 TOK/s)
從浮點數變為Int8可以減少內存帶寬,我們可以通過將其降低到Int4來測試極限(最小值為-2147483648)。最大值為2147483647)。考慮到INT的范圍仍然從負到正十億,有足夠的細微差別,在獲得額外提升推理速度的同時,不會失去太多的準確性。
把上面所有的東西結合起來(240 TOK/s)
當所有上述方法一起使用時,由于不同策略的協同作用,還會帶來額外的21%的收益。
總結
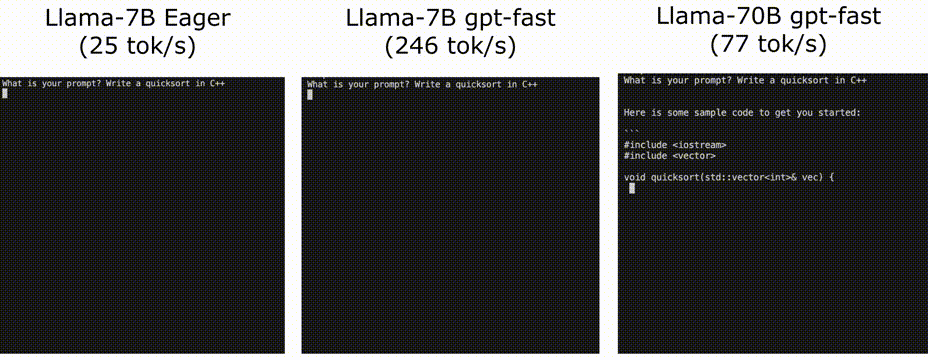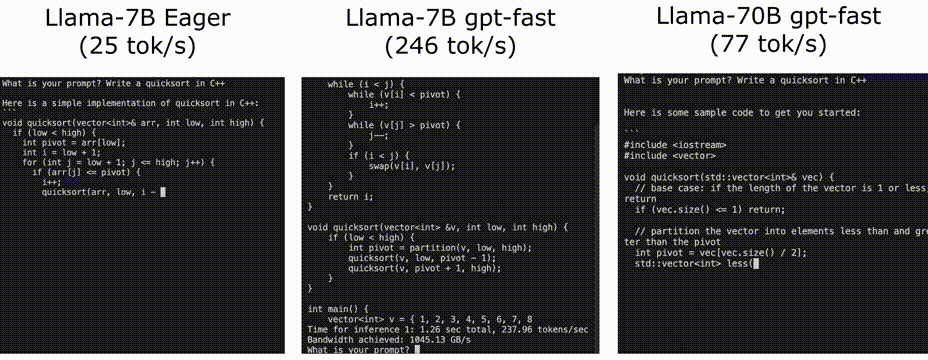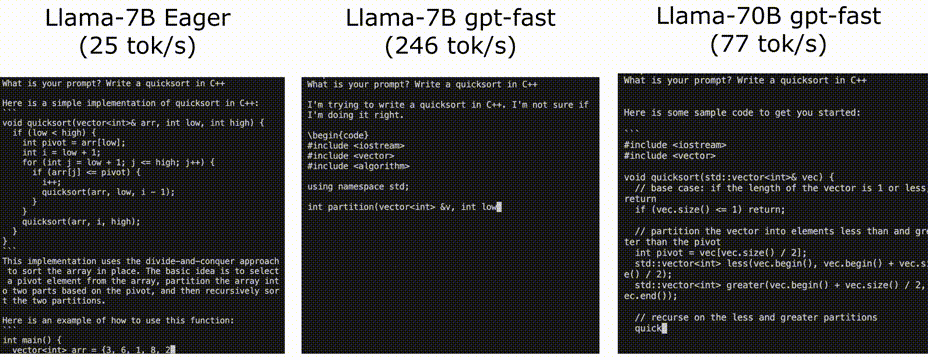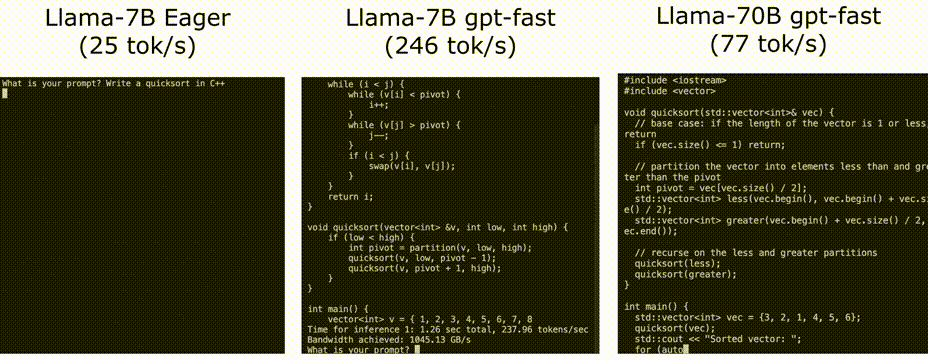
可以看到,我們最終獲得了10倍左右的提高 25 TOK/s -》 246 TOK/s
使用Llama-7B,我們能夠使用編譯+ int4量化+推測解碼達到246 tok/s。通過llama-70B,我們還可以將張量并行性提高到80 tok/s。這些都接近或超過SOTA性能數字!
本文代碼:
https://avoid.overfit.cn/post/58c4ba8ee4f546ca81744c50733e46d9
作者:Dr. Mandar Karhade, MD. PhD
實驗三:CSS字體等屬性使用)




 - 華為OD統一考試(C卷))





環境搭建)




)


