Stable Diffusion 的整個算法組合為: UNet + VAE + 文本編碼器
UNet:就是我們大模型里的核心。
文本編碼器:將我們的prompt進行encoder為算法能理解的內容(可以理解為SD外包出去的項目CLIP)。
VAE:對UNet生成的圖像作后處理。
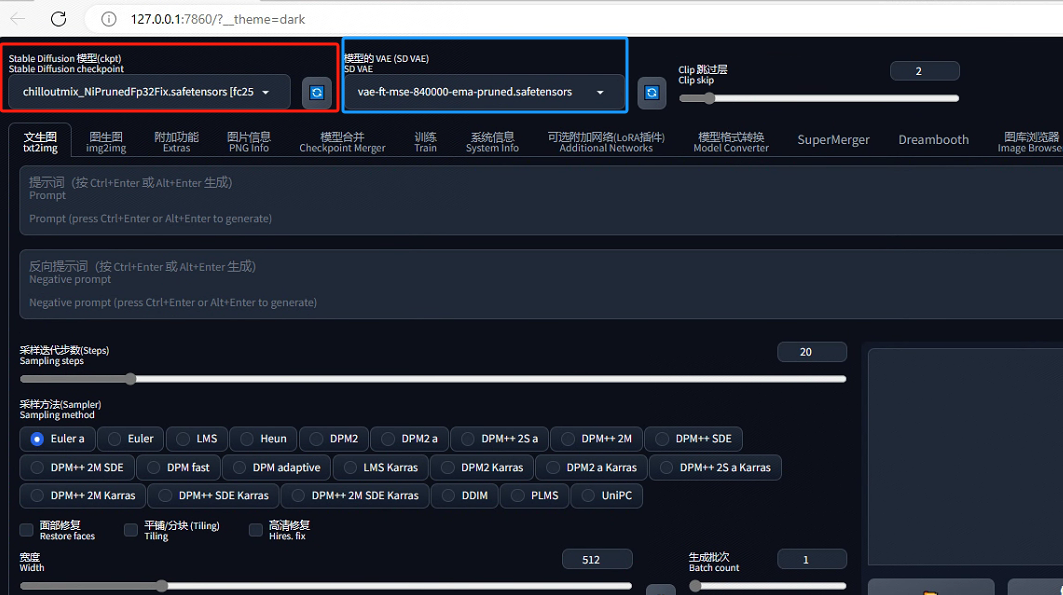
上圖中紅框代表的是大模型,可以通過下拉的方式來替換自己所需要的大模型。該參數控制著出圖內容的基調,如真實場景、二次元或建筑模型。我們可以將其理解為擁有無數圖像的數據庫,根據prompt拿出一堆相關圖像拼到一起生成出最終的圖像。也就是說想要生成什么樣的內容,就得需要一個什么樣的數據庫。通常,我們所使用的大模型都是在最原始的大模型SD1.5或者XL1.0上進行微調的,如dreambooth,其大小一般在2G,4G或7G不等。其存放目錄如下所示:
大模型本身是自帶VAE的,正常情況下藍框只需要選擇無或自動匹配即可。如果藍框做了選擇,即使用了外掛VAE,那么大模型本身的VAE就不會起作用。
CLIP(Contrastive language-image pre-training):其作用是將文字和圖像轉化為AI能夠識別的數據后再將它們一一對應。在藍框旁邊,有一個“CLIP跳過層”選項。主要作用是將CLIP模型提前停止。數值設幾就代表在倒數第幾層停止。通俗一點來說,CLIP模型的推理是一個添加N次提示詞的內容,每添加一次,生成的內容就越接近prompt。因此這個數值可以控制prompt和生成圖片的相關程度,但不會控制圖像風格的變化。實際作用大不大,只能說仁者見仁,智者見智。因為有時候前向跑的過多了反而含義就錯了。

以下是對文生圖的部分使用說明:
提示詞和反向提示詞:控制著生成圖片中想要的元素和不想要的元素。
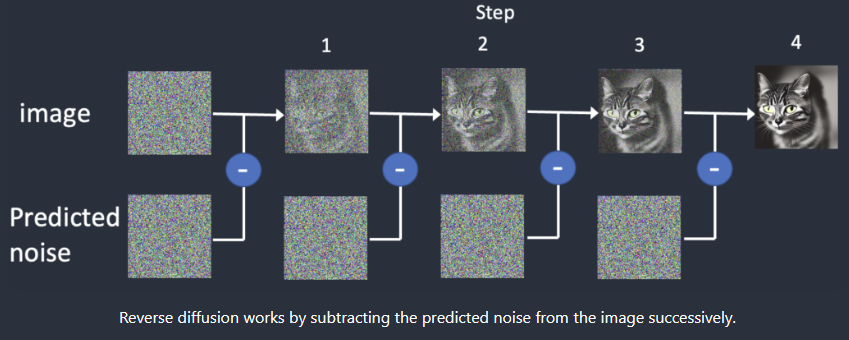
采樣迭代步數和采樣方法:在說這個前,我們首先得明白SD的工作原理。首先,模型會生成一張完全隨機的噪聲圖像。隨后噪聲預測器將生成需要剔除部分的噪聲并和原始圖像運算得到下一步的輸出。隨后不斷重復這個過程,得到最終的結果。整個去噪的過程就是采樣的過程,每次采樣就算迭代一次,去噪的手段就是采樣方法。其中采樣器有以下幾個:
- 經典ODE采樣器:Eular采樣器:歐拉采樣方法,好用卻不太準確。Heun采樣器:歐拉的一個更準確但更慢的版本。LMS采樣器:線性多步法,與歐拉采樣器速度相仿,但是更準確。
- DPM:擴散概率模型求解器。DPM會自適應調整步長,不能保證在約定的采樣步驟內完成任務,速度較慢。DPM++相對來說結果更準確,但速度更更慢。
- 祖先采樣器:名稱中帶有a標識的采樣器都是祖先采樣器。這一類采樣器在每個采樣步中都會向圖像添加噪聲,導致結果具有隨機性。部分沒有帶a的采樣器也屬于祖先采樣器,如Eular a,DPM2 a,DPM++2S a,DPM++2S a?KARRAS,DPM++ SDE,DPM++SDE KARRAS。
- Karras Noise Schedule:帶有Karras字樣的采樣器,最大的特色是使用了Karras論文中的噪聲計劃表,主要表現是去噪的程度在開頭會比較高,在接近尾聲時會變小,有助于提升圖像質量。
- UniPC:統一預測矯正器。一種可以在5~10步實現高質量圖像的方法。
- DPM Adaptive:采樣器不會跟著步數去收斂,會一直收斂至最好的效果。
有一個知乎大佬對采樣方法做了測試得到以下結論:
- Eular和Heun:日常訓練中,只想看一看出圖的內容是什么樣的,相對準確且快。
- DPM++2M KARRAS和UniPc:能夠輸出一張各方面均衡且高質量的圖片。
- DPM++SDE KARRAS:能夠輸出一張有一定隨機變化的且高質量的圖片。
關于采樣步數的設定:不要太大也不要太小。太小則來不及把細節都畫完,太大則容易在某一個地方不斷的精細化導致光斑或裂縫。推薦50以下。
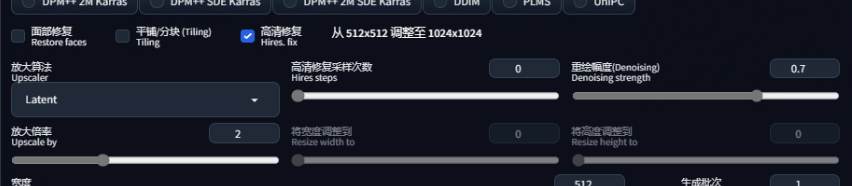
面部修復:解決SD1.5在畫人臉上的一些問題。對真人的人臉進行一定程度的調整,有效但不絕對。尤其是畫特定臉時就不要開啟這個面部修復了。
平鋪分塊:生成的圖像復制多份時能夠彼此無縫銜接。
高清修復:解決SD1.5無法生成像素較高的圖像。除去XL1.0模型是以1024分辨率為基礎的。常用的SD1.5的底模是512分辨率的,導致出圖時只有接近512的像素才會得到一個比較好的效果(增大尺寸可能會導致多頭多手)。高清修復采樣次數如果為0,則以采樣迭代步數作為實際步數。重繪幅度如果為0就代表修復后的圖片不會有任何變化。對于放大算法的選擇:
- 4x-UltraSharp:基于ESRGAN做了優化模型,更適合常見的圖片格式真人模型最佳選擇。各方面能力出眾,目前最實用,最優的選擇,更貼合真實效果。
- SwinIR 4x:使用SwinTransformer模型,擁有局部自適應的內容,更好的提取可特征,提高圖像細節,保證放大圖片真實感穩定訓練,很全面卻沒有一方面超過別的算法。
- Nearest:非常傳統的歸類找近似值的方法,計算新的東西和舊的東西的相似度,以最相似的內容去出圖,大數據時效果好,實際一般。
- Lanczos:把正交矩陣將原始矩陣變換為一個三對角矩陣,一種用于對稱矩陣的特征值分解的算法,比起其他幾種算法沒有什么優勢。
- R-ESRGAN 4x+:基于RealESRGAN的優化模型,針對照片效果不錯。提高圖像分辨率的同時,也可以增強圖像的細節和紋理,并且生成的圖像質量比傳統方法更高。
- R-ESRGAN 4x+ Anime6B:基于RealESRGAN的優化模型,在生成二次元圖片時更加準確且高效。
- Latent:一種基于原始圖像編碼圖像增強算法,對其進行隨機采樣和重構,從而增強圖像的質量、對比度和清晰度。顯存消耗比較小,效果中上,且貼合提示詞。
- ESRGAN:對SRGAN關鍵部分網絡結構、對抗損失、感知損失的增強。從這里開始就不是單純的圖像算法,進入人工智能的領域了。實測確實增加了很多看上去很真實的紋理,但是有時又會把一張圖片弄得全是鋸齒或怪異的紋理。可能對待處理的圖片類型有要求。
- ESRGAN 4x:它是ESRGAN算法的一種改進版本,可以將低分辨率的圖像通過神經網絡模型增強到4倍的分辨率,在增強圖像的細節信息和保留圖像質量方面有了明顯的提升。
- LDSR:潛在擴散超分辨率,效果寫實,但是慢。
以下是不同高清修復算法的原理:
Text2Image頁面中的Highres Upscaling:首先通過SD前半部分(給定提示詞,CLIP會將提示詞翻譯為可理解的向量,隨后喂入神經網絡生成Latent結果)。不同的是不會立即進行解碼,如果選擇了Latent Upscaler的話,會基于Latent做Upscaling,得到另外一個Latent。再去進行解碼。得到比原始輸入(512×512)還大的圖(1024×1024)。優勢:基于Latent速度比較快,且是在SD的模型中做的Upscaling,所以會更加好的去理解prompt,對圖片上下文進行處理。
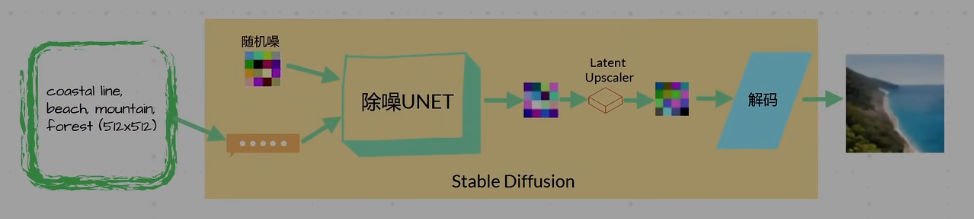
Image2Image Upscaling:需要的輸入有兩部分:512×512的圖和一段說明(指定輸入為1024×1024)。首先需要用編碼器將圖變為Latent,隨后再生成一個隨即噪音,何其進行Concat(可以理解為給圖像打了馬賽克)。文字說明則依舊通過CLIP變為一個可理解的向量。把這兩個東西同時輸入到SD的后半部分就完事了。(相比于上一個算法上下文的理解會稍微弱一點,而且僅用了SD模型本身的特性來生成這張圖像。)

Extra Upscaling:直接輸入一張圖,用通用的Upscaling算法生成一張大圖。沒有上下文,但更加靈活多用。

?SD UPscale Upscaling:Image2Image Upscaling的擴展版本。即通過通用的Upscaling的算法先把圖像擴大一倍。隨后將圖像分成小塊。在進行Image2Image Upscaling???????的過程,只不過是對每一個小塊做處理。最后將生成的四個小塊做拼接。

提示詞相關性(CFG Scale):越低越自由越放飛,越高則越嚴格按照prompt。太高也容易產生撕裂和光斑。推薦7~9。
Denoising strength:給一張原圖,想在原圖的基礎上畫新的圖。越低則越忠于原圖,越高則越放飛自我。









連接OpenSearch進行CRUD)


:讓模型表現更上一層樓!!!)



———CSS核心功能手冊:從熟悉到精通)


