1. 引言
在之前的文章《PandasAI連接LLM進行智能數據分析》中實現了使用PandasAI連接與DeepSeek模型通過自然語言進行數據分析。不過那個例子中使用的是PandasAI 2.X,并且使用的是本地.csv文件來作為數據。在實際應用的系統中,使用.csv作為庫表的情況比較少見。在本文中,就試試使用最新的PandasAI 3.0對MySQL數據庫中涉及到多個表的數據進行數據分析。
2. 詳述
既然要連接MySQL數據庫,那么就要先準備數據了。在MySQL創建一個數據庫chinese_retail_data,在數據庫中創建兩張表customers和orders,并且插入數據。這里模擬的是電商系統重點用戶表和訂單表。具體的SQL語句如下所示:
-- 創建數據庫
CREATE DATABASE IF NOT EXISTS chinese_retail_data;
USE chinese_retail_data;-- 創建客戶表 (主表)
CREATE TABLE customers (customer_id INT PRIMARY KEY AUTO_INCREMENT,customer_name VARCHAR(100) NOT NULL,gender VARCHAR(10) NOT NULL,age_group VARCHAR(20) NOT NULL,city VARCHAR(50) NOT NULL,membership_level VARCHAR(20) DEFAULT '普通會員',registration_date DATE NOT NULL
);-- 創建訂單表 (從表,通過customer_id關聯)
CREATE TABLE orders (order_id INT PRIMARY KEY AUTO_INCREMENT,customer_id INT,product_name VARCHAR(100) NOT NULL,category VARCHAR(50) NOT NULL,quantity INT NOT NULL,unit_price DECIMAL(10,2) NOT NULL,order_date DATE NOT NULL,payment_method VARCHAR(20) NOT NULL,delivery_status VARCHAR(20) NOT NULL,FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);-- 插入客戶數據(字段值使用中文)
INSERT INTO customers (customer_name, gender, age_group, city, membership_level, registration_date) VALUES
('張偉', '男', '25-34歲', '北京', '黃金會員', '2023-01-15'),
('李娜', '女', '35-44歲', '上海', '鉑金會員', '2022-03-20'),
('王強', '男', '18-24歲', '廣州', '普通會員', '2024-01-05'),
('陳靜', '女', '45-54歲', '深圳', '黃金會員', '2023-06-12'),
('劉洋', '男', '25-34歲', '杭州', '普通會員', '2024-02-18'),
('趙敏', '女', '35-44歲', '成都', '鉑金會員', '2022-11-30'),
('孫浩', '男', '18-24歲', '南京', '普通會員', '2024-03-08'),
('周芳', '女', '45-54歲', '武漢', '黃金會員', '2023-09-25');-- 插入訂單數據(字段值使用中文,關聯customer_id)
INSERT INTO orders (customer_id, product_name, category, quantity, unit_price, order_date, payment_method, delivery_status) VALUES
(1, '華為手機', '電子產品', 1, 5999.00, '2024-04-01', '支付寶', '已送達'),
(2, '美的空調', '家用電器', 1, 3200.00, '2024-04-03', '微信支付', '已送達'),
(3, '李寧運動鞋', '服飾鞋帽', 2, 499.00, '2024-04-05', '信用卡', '運輸中'),
(1, '小米手環', '電子產品', 1, 299.00, '2024-04-08', '支付寶', '已送達'),
(4, '格力冰箱', '家用電器', 1, 4800.00, '2024-04-10', '微信支付', '已送達'),
(5, '耐克T恤', '服飾鞋帽', 3, 199.00, '2024-04-12', '支付寶', '已送達'),
(2, '蘋果平板', '電子產品', 1, 3899.00, '2024-04-15', '微信支付', '已送達'),
(6, '海爾洗衣機', '家用電器', 1, 2800.00, '2024-04-18', '信用卡', '已送達'),
(7, '阿迪達斯運動褲', '服飾鞋帽', 1, 599.00, '2024-04-20', '支付寶', '運輸中'),
(1, '戴爾筆記本', '電子產品', 1, 7999.00, '2024-04-25', '微信支付', '已送達'),
(8, '西門子烤箱', '家用電器', 1, 2200.00, '2024-04-28', '信用卡', '已送達'),
(3, '優衣庫襯衫', '服飾鞋帽', 4, 199.00, '2024-05-01', '支付寶', '已送達'),
(4, 'OPPO手機', '電子產品', 1, 2999.00, '2024-05-05', '微信支付', '已送達'),
(5, '彪馬運動鞋', '服飾鞋帽', 1, 699.00, '2024-05-08', '信用卡', '運輸中'),
(2, '索尼耳機', '電子產品', 2, 899.00, '2024-05-12', '支付寶', '已送達');
然后準備PandasAI的環境。注意默認的Python環境pip安裝的可能仍然是2.X版本,不過在使用PandasAI官方文檔推薦使用Poetry之后,就可以pip安裝3.0了。
最后給出具體的Python腳本:
import pandasai
from pandasai_litellm import LiteLLMllm_url = "https://dashscope.aliyuncs.com/compatible-mode/v1"
llm_key = "sk-xxxxx"
llm_model_name = "deepseek-r1"mysql_host = "127.0.0.1"
mysql_port = 3306
mysql_user = "root"
mysql_password = "test"def init_dataset(table_names):pandasai.create(path = table_names[0],description = "電商系統客戶的基本信息,包括個人屬性、地理位置和會員等級等靜態特征。",source={"type": "mysql","connection": {"host": mysql_host,"port": mysql_port,"user": mysql_user, "password": mysql_password,"database": "chinese_retail_data"},"table": "customers", },columns = [{"name": "customer_id", "type": "integer", "description": "客戶的唯一標識符,用于關聯訂單數據。"},{"name": "customer_name", "type": "string", "description": "客戶的姓名,用于識別和溝通。"},{"name": "gender", "type": "string", "description": "客戶的性別,用于人口統計分析。"},{"name": "age_group", "type": "string", "description": "客戶所屬的年齡段,用于年齡相關的市場細分。"},{"name": "city", "type": "string", "description": "戶所在的城市,用于地域性銷售分析。"},{"name": "membership_level", "type": "string", "description": "客戶的會員等級,反映客戶價值和忠誠度。"},{"name": "registration_date", "type": "datetime", "description": "客戶的注冊日期,用于計算客戶生命周期。"},])pandasai.create(path = table_names[1],description = "電商系統客戶的訂單交易詳情,包括購買的商品、數量、價格、時間和狀態等動態行為。",source={"type": "mysql","connection": {"host": mysql_host,"port": mysql_port,"user": mysql_user,"password": mysql_password,"database": "chinese_retail_data"},"table": "orders",},columns = [{"name": "order_id", "type": "integer", "description": "訂單的唯一標識符,用于追蹤和管理訂單。"},{"name": "customer_id", "type": "integer", "description": "關聯到客戶的外鍵,建立與客戶表的聯系。"},{"name": "product_name", "type": "string", "description": "所購商品的名稱,用于產品銷售分析。"},{"name": "category", "type": "string", "description": "商品所屬的類別,用于分類統計和趨勢分析。"},{"name": "quantity", "type": "integer", "description": "購買的商品數量,影響總銷售額和庫存。"},{"name": "unit_price", "type": "float", "description": "商品的單價,用于計算訂單金額和利潤。"},{"name": "order_date", "type": "datetime", "description": "訂單創建的日期,用于時間序列和趨勢分析。"},{"name": "payment_method", "type": "string", "description": "客戶使用的支付方式,反映支付偏好。"},{"name": "delivery_status", "type": "string", "description": "訂單的配送狀態,用于監控物流和客戶滿意度。"},])def ai_chat(table_names):llm = LiteLLM(model=llm_model_name, api_base=llm_url, api_key=llm_key, custom_llm_provider="openai", temperature=0.0, seed=10080)pandasai.config.set({"llm": llm, "save_logs": True, "verbose": False, "max_retries": 3})# 加載所有相關的表 tables = [pandasai.load(name) for name in table_names]chat_content = "統計一下目前電商系統中會員類型的占比,以及每種會員類型購買商品的數額在銷售額總量的占比。請使用中文回答。"result = pandasai.chat(chat_content, *tables)print(result)if __name__ == "__main__": table_names = ["example/ecommerce-customers", "example/ecommerce-orders"]#init_dataset(table_names) #初始化只能一次ai_chat(table_names)
有以下幾點需要注意:
-
PandasAI 3.0比PandasAI 2.X方便的一點可以不用自定義
LLM類來連接自定義的大模型了,使用內置的LiteLLM就可以了。另外PandasAI官方還提供大模型可以使用,不過需要申請key。這里筆者連接的還是阿里云百煉平臺的DeepSeek。 -
PandasAI設計的數據接口筆者覺得有點奇怪,主要有兩點:
pandasai.create創建的表格數據只能使用一次,如果數據存在第二次再調用這個函數(在init_dataset函數中)就會報錯。- PandasAI對創建的數據集名稱還有要求,比如多個單詞必須以"-"進行連接。
-
PandasAI官網創建MySQL數據集的案例代碼1是:
sql_table = pai.create(path="example/mysql-dataset",description="Heart disease dataset from MySQL database",source={"type": "mysql","connection": {"host": "database.example.com","port": 3306,"user": "${DB_USER}","password": "${DB_PASSWORD}","database": "medical_data"},"table": "heart_data","columns": [{"name": "Age", "type": "integer", "description": "Age of the patient in years"},{"name": "Sex", "type": "string", "description": "Gender of the patient (M = male, F = female)"},{"name": "ChestPainType", "type": "string", "description": "Type of chest pain (ATA, NAP, ASY, TA)"},{"name": "RestingBP", "type": "integer", "description": "Resting blood pressure in mm Hg"},{"name": "Cholesterol", "type": "integer", "description": "Serum cholesterol in mg/dl"},{"name": "FastingBS", "type": "integer", "description": "Fasting blood sugar > 120 mg/dl (1 = true, 0 = false)"},{"name": "RestingECG", "type": "string", "description": "Resting electrocardiogram results (Normal, ST, LVH)"},{"name": "MaxHR", "type": "integer", "description": "Maximum heart rate achieved"},{"name": "ExerciseAngina", "type": "string", "description": "Exercise-induced angina (Y = yes, N = no)"},{"name": "Oldpeak", "type": "float", "description": "ST depression induced by exercise relative to rest"},{"name": "ST_Slope", "type": "string", "description": "Slope of the peak exercise ST segment (Up, Flat, Down)"},{"name": "HeartDisease", "type": "integer", "description": "Heart disease diagnosis (1 = present, 0 = absent)"}]} )但是筆者這里嘗試的正確的用法是:
pandasai.create(path = table_names[0],description = "電商系統客戶的基本信息,包括個人屬性、地理位置和會員等級等靜態特征。",source={"type": "mysql","connection": {"host": mysql_host,"port": mysql_port,"user": mysql_user, "password": mysql_password,"database": "chinese_retail_data"},"table": "customers", },columns = [{"name": "customer_id", "type": "integer", "description": "客戶的唯一標識符,用于關聯訂單數據。"},{"name": "customer_name", "type": "string", "description": "客戶的姓名,用于識別和溝通。"},{"name": "gender", "type": "string", "description": "客戶的性別,用于人口統計分析。"},{"name": "age_group", "type": "string", "description": "客戶所屬的年齡段,用于年齡相關的市場細分。"},{"name": "city", "type": "string", "description": "戶所在的城市,用于地域性銷售分析。"},{"name": "membership_level", "type": "string", "description": "客戶的會員等級,反映客戶價值和忠誠度。"},{"name": "registration_date", "type": "datetime", "description": "客戶的注冊日期,用于計算客戶生命周期。"},] )關鍵不同點就在于columns屬性值的位置。使用前者實際上是會丟失表格字段描述的。表格字段描述非常重要,PandasAI會將其傳遞給LLM來理解表格數據。如果創建成功的話,可以在Python腳本所在目錄的datasets文件夾中,找到創建好的.yaml文件,其中有表格數據的字段表述值:
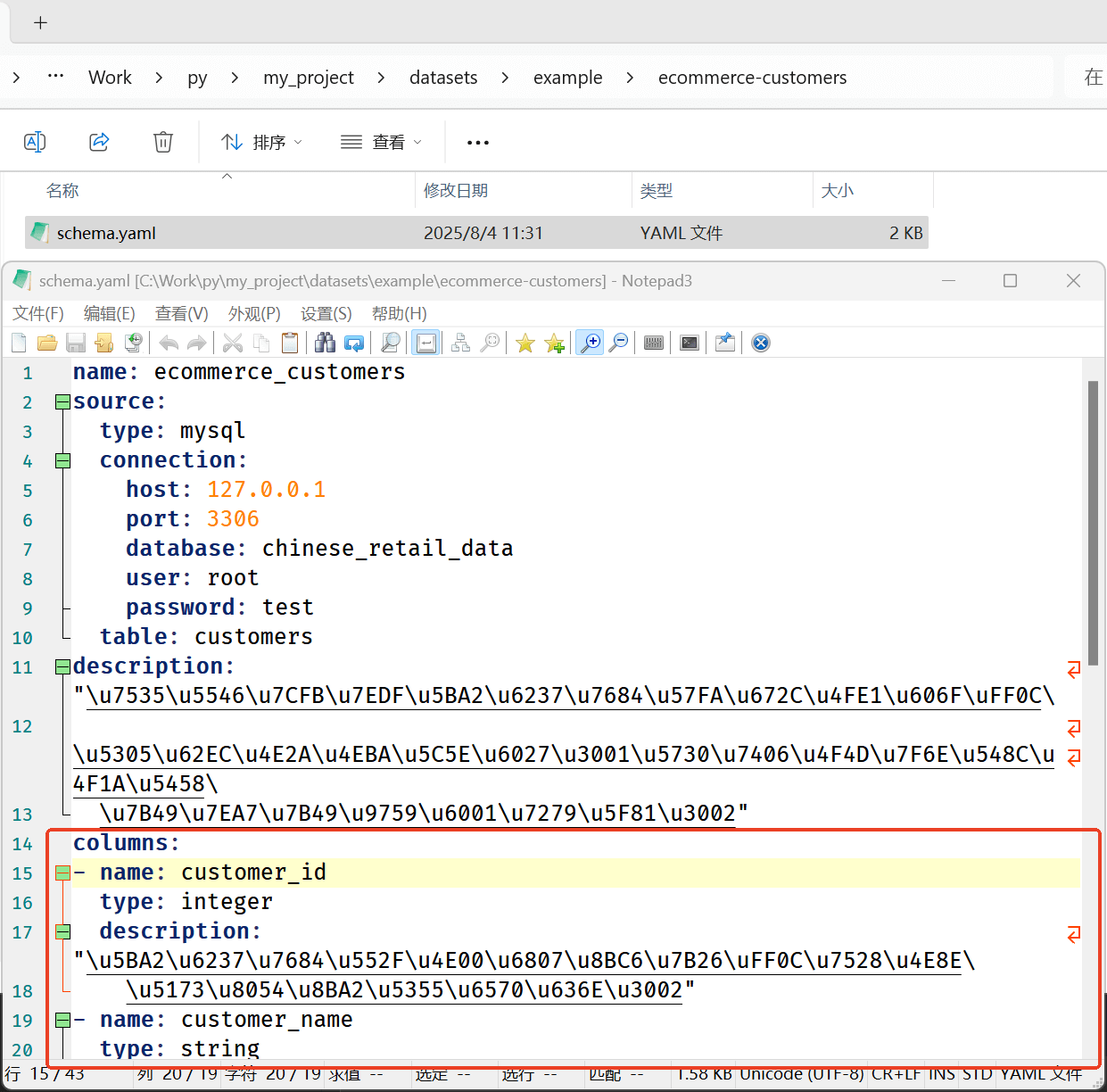
3. 結果
最終運行結果如下所示:
membership_level 會員占比(%) 銷售額占比(%)
0 普通會員 37.5 9.30
1 鉑金會員 25.0 29.48
2 黃金會員 37.5 61.23
本例中還有一點值得注意的是這里進行的數據分析是跨表數據分析,而不是像《PandasAI連接LLM進行智能數據分析》中那樣使用的是單表。其實這就是個很有趣的問題,我們都知道業務系統的核心就是CURD,那么如果跨表查詢可以實現,是不是意味著以后就可以通過自然語言來進行業務呢?現在語音的正確識別率也不低,通過語言來進行業務操作也不難吧?這就回到了筆者在之前的文章《行業思考:不是前端不行,是只會前端不行》中的討論:也許AI可能會對傳統Web前端方向帶來革命性的影響。
PandasAI官方文檔 ??

![【BUUCTF系列】[極客大挑戰 2019]LoveSQL 1](http://pic.xiahunao.cn/【BUUCTF系列】[極客大挑戰 2019]LoveSQL 1)


的 Qt 程序)


是 右Ctrl 鍵(即鍵盤右側的 Ctrl 鍵)筆記250802)

)

腳本)







