前言:數據倉庫建設,初級的理解就是建表,將業務數據、日志數據、消息隊列數據等,通過各種調度任務寫入到表里供OLAP引擎使用。但要想建好數倉也是一個復雜、龐大的工程,比如要考慮:數據清洗、數據建模(星型模型、雪花模型、寬表模型、主題、維度、指標)、數據時效性(實時、T+1)、延遲容錯、機器資源等。
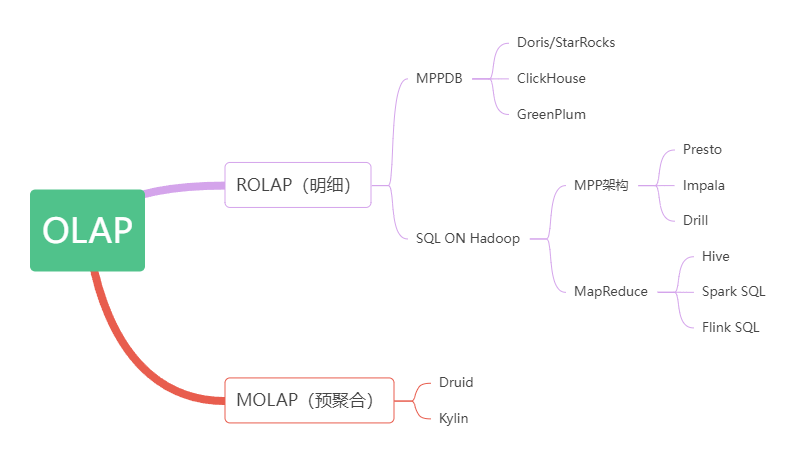
1、OLTP和OLAP區別
-
OLAP(On-Line Analytical Processing)聯機分析處理,也稱為面向交易的處理過程,其基本特征是前臺接收的用戶數據可以立即傳送到計算中心進行處理,并在很短的時間內給出處理結果,是對用戶操作快速響應的方式之一。應用在數據倉庫,使用對象是決策者。OLAP系統強調的是數據分析,響應速度要求沒那么高。目前市面上主流的開源OLAP引擎包含不限于:Hive、ClickHouse、StarRocks、Presto、Kylin、Impala、Sparksql、Druid等
-
?OLTP(On-Line Transaction Processing)聯機事務處理,它使分析人員能夠迅速、一致、交互地從各個方面觀察信息,以達到深入理解數據的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多維信息的快速分析的特征。主要應用是傳統關系型數據庫。OLTP系統強調的是內存效率,實時性比較高。Oracle、Redis、NySQL.
2、OLAP查詢類型劃分
-
即席查詢:?通過手寫sql完成一些臨時的數據分析需求,這類sql形式多變、邏輯復雜,對查詢時間沒有嚴格要求
-
固化查詢:指的是一些固化下來的取數、看數需求,通過數據產品的形式提供給用戶,從而提高數據分析和運營的效率。這類的sql固定模式,對響應時間有較高要求。
3、按照架構劃分的主流OLAP引擎:
-
MPP架構系統(Presto/Impala/SparkSQL/Drill等)。這種架構主要還是從查詢引擎入手,使用分布式查詢引擎,而不是使用hive+mapreduce架構,提高查詢效率。
-
MapReduce:MapReduce是一種編程模型和分布式計算框架,用于處理大規模數據集。它由兩個主要階段組成:Map階段和Reduce階段。在Map階段,數據被分割成多個小塊,每個小塊由獨立的計算節點進行處理,并生成中間結果。在Reduce階段,中間結果被合并和聚合,生成最終的結果。MapReduce適用于批量處理大規模數據,如日志分析、離線數據處理等。
-
預計算系統(Druid/Kylin等)則在入庫時對數據進行預聚合,進一步犧牲靈活性換取性能,以實現對超大數據集的秒級響應。
-
搜索引擎架構的系統(es,solr等),在入庫時將數據轉換為倒排索引,采用Scatter-Gather計算模型,犧牲了靈活性換取很好的性能,在搜索類查詢上能做到亞秒級響應。但是對于掃描聚合為主的查詢,隨著處理數據量的增加,響應時間也會退化到分鐘級。
3.1、MapReduce
SparkSql, odps工作臺就是典型的代表通過task schedule創建各類task,執行MR去處理數據,整合成需要展示的形態,。其特點就是能針對海量數據做處理,但是最大的問題就是慢。
慢的原因主要有兩點 1. 任務的資源創建。 2.MR過程中中間結果在shuffle階段的傳輸和存儲非常耗時。
MR的適用場景是百億級海量數據,對RT要求不敏感,分鐘級以上的業務場景。
3.2、MPP[massive parallel processor]
MPP 是一種很常見的架構方式, 旨在利用了整個集群的計算能力。主要是架構形式是Master/Slave,把一次查詢的計算和數據獲取分布到各臺slave上。
這里為了方便大家理解,舉個很常見的例子來說明,如果按照對用戶id分庫分表的mysql集群來說,每次你查詢的條件都是諸如age > 5這樣的,每個分庫遍歷之后,由proxy聚合給到client,這樣的形式也可以叫MPP架構。
整體MPP因為是SQL的查詢方式,速度還是會比MR快上不少的。MPP的典型代表是GP, Impala, ES。
3.3、預聚合體系
預聚合體系非常像聚合計算統計,提前知道維度,然后預先根據維度去批量計算結果預存好數據,獲得毫秒級的查詢速度。
典型的代表是預定義cube的kylin 和 druid。 kylin的概念更好理解些,用的技術都是hadoop體系非常容易理解, 是通過hadoop小批量計算后把數據存在hbase里。
而druid的功能更豐富些,能接收消息隊列數據,實時性更好些。
預聚合體系的場景是優點是毫秒級的數據RT,QPS比較高。缺點是不能不夠動態,增添維度比較難,不能進行join。
4、MPP、Map Reduce、MPPDB區別
MPP (Massively Parallel Processing)、MapReduce 和 MPPDB(Massively Parallel Processing Database)是三個不同的概念和技術,三者定義如下:
-
MPP(Massively Parallel Processing):MPP是一種并行計算架構,用于處理大規模數據。MPP系統將數據分割成多個分片,每個分片由獨立的計算節點處理。每個節點負責處理自己的數據分片,然后將結果合并。這種并行計算架構可以提高數據處理的速度和效率。
-
MapReduce:MapReduce是一種編程模型和分布式計算框架,用于處理大規模數據集。它由兩個主要階段組成:Map階段和Reduce階段。在Map階段,數據被分割成多個小塊,每個小塊由獨立的計算節點進行處理,并生成中間結果。在Reduce階段,中間結果被合并和聚合,生成最終的結果。MapReduce適用于批量處理大規模數據,如日志分析、離線數據處理等。
-
MPPDB(Massively Parallel Processing Database):MPPDB是一種基于MPP架構的分布式數據庫系統。它將數據分割成多個分片存儲在不同的節點上,并利用并行計算能力進行查詢和分析。MPPDB具有高度可擴展性和并行處理能力,可以處理大規模數據集,并提供高性能的查詢和分析功能。
MPP是一種并行計算架構,而MapReduce是一種編程模型和分布式計算框架。
MapReduce適用于批量處理大規模數據,而MPPDB是一種分布式數據庫系統,適用于實時查詢和分析大規模數據。
MPPDB基于MPP架構,具有高度可擴展性和并行處理能力,而MapReduce可以在各種分布式計算框架中實現,如Hadoop。 MPPDB提供高性能的查詢和分析功能,而MapReduce更適用于離線數據處理和復雜計算任務。
總的來說,MPP是一種并行計算架構,MapReduce是一種編程模型和分布式計算框架,而MPPDB是一種基于MPP架構的分布式數據庫系統。它們在處理大規模數據和分布式計算方面有各自的原理和應用場景。
5、OLAP主流框架對比
OLAP核心的詞匯是Analysis。既然是分析其實多的是類似COUNT,SUM,GroupBy這樣的聚合操作。學術一點的是上鉆,下鉆,切片,切塊這樣的操作,這樣的操作往往需要列式存儲的支持才能達到更好的性能,所以往往很多OLAP引擎的底層存儲就是列式的。
OLAP技術有很多類型,主要分為MPP(大規模并行)、視圖預聚合、MapReduce(勉強算)幾種類型。每一種類型都有其使用場景,針對業務需求能讓我們更加了解對應的引擎。
5.1、Clickhouse
ClickHouse由俄羅斯第一大搜索引擎Yandex于2016年6月發布,開發語言為C++,是一個面向聯機分析處理(OLAP)的開源的面向列式存儲的DBMS,簡稱CK,與Hadoop、Spark這些巨無霸組件相比,ClickHouse很輕量級,查詢性能非常好。目前國內社區火熱,各個大廠紛紛跟進大規模使用。
ClickHouse從OLAP場景需求出發,定制開發了一套全新的高效列式存儲引擎,并且實現了數據有序存儲、主鍵索引、稀疏索引、數據Sharding、向量執行、剪枝優化、主備復制等豐富功能。以上功能共同為ClickHouse極速的分析性能奠定了基礎。
5.2、Presto
Presto 是 Facebook 推出分布式SQL交互式查詢引擎,采用MPP架構,完全基于內存的并行計算。Presto比Hive快的原因就在于不在落盤,而是全內存操作。Presto在支持的SQL計算上更加通用,更適合ad-hoc查詢場景,然而這些通用系統往往比專用系統更難做性能優化,所以不太適合做對查詢QPS(參考值QPS > 1000)、延遲要求比較高(參考值search latency < 500ms)的在線服務,更適合做公司內部的查詢服務和加速Hive查詢的服務。

5.3、Doris/StarRocks
Doris是由百度開源的一款MPP數據庫,實現了MySQL協議,集成Google Mesa 和Apache Impala 的技術。DorisDB是基于 Apache Doris 做的閉源商業化產品,后該產品又基于Elastic License 2.0開源并更名為StarRocks。
5.4、Spark SQL
Spark是UC Berkeley AMP lab開源的類MapReduce的通用的并行計算框架。SparkSQL 是 Spark 處理結構化數據的模塊。本質上也是基于 DAG (有向無環圖,Directed Acyclic Graph的縮寫,常用于建模) 的 MPP。

5.5、Kylin
Kylin 是2014年由 eBay 中國研發中心開源的OLAP引擎,提供 Hadoop/Spark 之上的 SQL 查詢接口及多維分析能力以支持超大規模數據,它能在亞秒內查詢巨大的Hive表。其核心技術點在于預計算和Cube(立方體模型)的設置:首先, 對需要分析的數據進行建模,框定需要分析的維度字段;然后通過預處理的形式,對各種維度進行組合并事先聚合;最后,將聚合結果以某種索引或者緩存的形式保存起來(通常只保留聚合后的結果,不存儲明細數據)。這樣一來,在隨后的查詢過程中,就可以直接利用結果返回數據。

5.6、Druid
Druid是由廣告公司 MetaMarkets 于2012年開源的實時大數據分析引擎。Druid 作為MOLAP引擎,也是對數據進行預聚合。只不過預聚合的方式與Kylin不同,Kylin是Cube化,Druid的預聚合方式只是全維度進行Group-by,相當于是Kylin Cube 的 base cuboid。Druid 支持低延時的數據攝取,靈活的數據探索分析,高性能的數據聚合,簡便的水平擴展。Druid支持更大的數據規模,具備一定的預聚合能力,通過倒排索引和位圖索引進一步優化查詢性能,在廣告分析場景、監控報警等時序類應用均有廣泛使用。

參考鏈接:
常見開源OLAP技術架構對比 - 知乎
OLAP引擎對比分析 - 知乎
大數據四大陣營之OLTP陣營(上) - 知乎



![實用篇 | 3D建模中Blender軟件的下載及使用[圖文詳情]](http://pic.xiahunao.cn/實用篇 | 3D建模中Blender軟件的下載及使用[圖文詳情])

方法或展開語法(...)來合并對象)
聊天簡易版)








和WI(操作指導書)的聯系和區別)
)


