參考《大規模語言模型--從理論到實踐》
目錄
一、綜述
二、Transformer 模型
三、?嵌入表示層(位置編碼代碼)
一、綜述
語言模型目標是建模自然語言的概率分布,在自然語言處理研究中具有重要的作用,是自然 語言處理基礎任務之一。大量的研究從 n 元語言模型(n-gram Language Models)、神經語言模 型(Neural Language Models,NLM)以及預訓練語言模型(Pre-trained Language Models,PLM) 等不同角度開展了系列工作。這些研究在不同階段都對自然語言處理任務有著重要作用。隨著基 于 Transformer 各類語言模型的發展以及預訓練微調范式在自然語言處理各類任務中取得突破性 進展,從 2020 年 OpenAI 發布 GPT-3 開始,大語言模型研究也逐漸深入。雖然大語言模型的參數 量巨大,通過有監督微調和強化學習能夠完成非常多的任務,但是其基礎理論也仍然離不開對語 言的建模。
本章將首先介紹 Transformer 結構,并在此基礎上介紹生成式預訓練語言模型 GPT、大語言模
型網絡結構和注意力機制優化以及相關實踐。n 元語言模型、神經語言模型以及其它預訓練語言
模型可以參考《自然語言處理導論》第 6 章[8],這里就不再贅述。
二、Transformer 模型
Transformer 模型[48] 是由谷歌在 2017 年提出并首先應用于機器翻譯的神經網絡模型結構。機
器翻譯的目標是從源語言(Source Language)轉換到目標語言(Target Language)。Transformer 結 構完全通過注意力機制完成對源語言序列和目標語言序列全局依賴的建模。當前幾乎全部大語言 模型都是基于 Transformer 結構,本節以應用于機器翻譯的基于 Transformer 的編碼器和解碼器介 紹該模型。 基于 Transformer 結構的編碼器和解碼器結構如圖2.1所示,左側和右側分別對應著編碼器(Encoder)和解碼器(Decoder)結構。它們均由若干個基本的Transformer 塊(Block)組成(對應著圖 中的灰色框)。這里 N× 表示進行了 N 次堆疊。每個 Transformer 塊都接收一個向量序列 {xi}作為輸入,并輸出一個等長的向量序列作為輸出 {yi}。這里的 xi 和 yi 分別對應著文本序列 中的一個單詞的表示。而 yi 是當前 Transformer 塊對輸入 xi 進一步整合其上下文語義后對應的輸 出。在從輸入 {xi}t到輸出 {yi}t的語義抽象過程中,主要涉及到如下幾個模塊:
- 注意力層:使用多頭注意力(Multi-Head Attention)機制整合上下文語義,它使得序列中任意兩個單詞之間的依賴關系可以直接被建模而不基于傳統的循環結構,從而更好地解決文本 的長程依賴。
- 位置感知前饋層(Position-wise FFN):通過全連接層對輸入文本序列中的每個單詞表示進行 更復雜的變換。
- 殘差連接:對應圖中的 Add 部分。它是一條分別作用在上述兩個子層當中的直連通路,被用 于連接它們的輸入與輸出。從而使得信息流動更加高效,有利于模型的優化。
- 層歸一化:對應圖中的 Norm 部分。作用于上述兩個子層的輸出表示序列中,對表示序列進 行層歸一化操作,同樣起到穩定優化的作用。
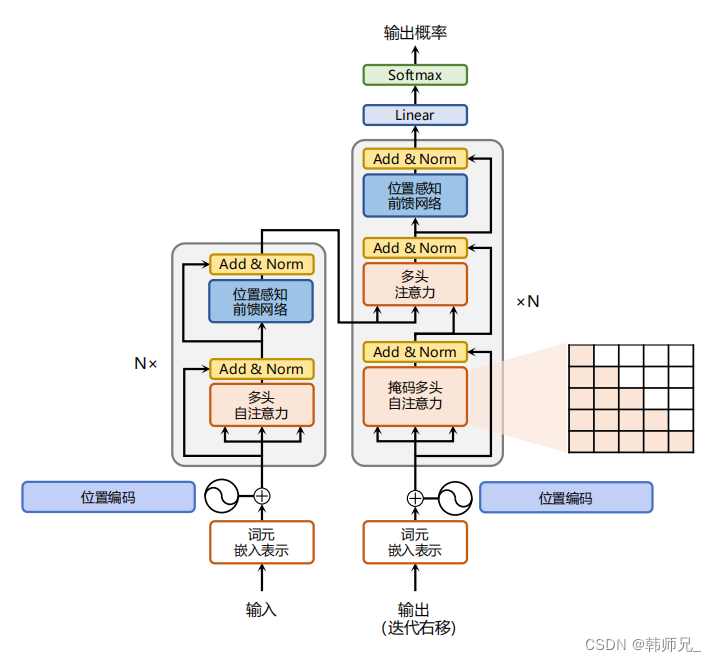
三、?嵌入表示層(位置編碼)
對于輸入文本序列,首先通過輸入嵌入層(Input Embedding)將每個單詞轉換為其相對應的 向量表示。通常直接對每個單詞創建一個向量表示。由于 Transfomer 模型不再使用基于循環的方 式建模文本輸入,序列中不再有任何信息能夠提示模型單詞之間的相對位置關系。在送入編碼器 端建模其上下文語義之前,一個非常重要的操作是在詞嵌入中加入位置編碼(Positional Encoding) 這一特征。具體來說,序列中每一個單詞所在的位置都對應一個向量。這一向量會與單詞表示對 應相加并送入到后續模塊中做進一步處理。在訓練的過程當中,模型會自動地學習到如何利用這 部分位置信息。 為了得到不同位置對應的編碼,Transformer 模型使用不同頻率的正余弦函數如下所示:
PE(pos, 2i) = sin( pos 100002i/d )? ? ? ? ? ? ? ? ? ? ? ? ? ? (1)
PE(pos, 2i + 1) = cos( pos 100002i/d )? ? ? ? ? ? ? ? ? ? ?(2)
其中,pos 表示單詞所在的位置,2i 和 2i+ 1 表示位置編碼向量中的對應維度,d 則對應位置編碼的 總維度。通過上面這種方式計算位置編碼有這樣幾個好處: 首先,正余弦函數的范圍是在 [-1,+1], 導出的位置編碼與原詞嵌入相加不會使得結果偏離過遠而破壞原有單詞的語義信息。其次,依據 三角函數的基本性質,可以得知第 pos + k 個位置的編碼是第 pos 個位置的編碼的線性組合,這就 意味著位置編碼中蘊含著單詞之間的距離信息。
使用 Pytorch 實現的位置編碼參考代碼如下:
import torch.nn as nn
import torch
import math
from torch.autograd import Variableclass PositionalEncoder(nn.Module):def __init__(self, d_model, max_seq_len = 80):super().__init__()self.d_model = d_model# 根據 pos 和 i 創建一個常量 PE 矩陣pe = torch.zeros(max_seq_len, d_model)for pos in range(max_seq_len):for i in range(0, d_model, 2):pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):# 使得單詞嵌入表示相對大一些x = x * math.sqrt(self.d_model)# 增加位置常量到單詞嵌入表示中seq_len = x.size(1) x = x + Variable(self.pe[:,:seq_len], requires_grad=False).cuda()return xpos_en = PositionalEncoder(d_model=64)
x = torch.randn(100, 1, dtype=torch.float32).cuda() # 100 x 1
print(pos_en(x).shape) # 100 x 64
print('')

![實用篇 | 3D建模中Blender軟件的下載及使用[圖文詳情]](http://pic.xiahunao.cn/實用篇 | 3D建模中Blender軟件的下載及使用[圖文詳情])

方法或展開語法(...)來合并對象)
聊天簡易版)








和WI(操作指導書)的聯系和區別)
)



