
文章目錄
- -
- Abstract
- 1. Introduction
- diss former method
- our method
- 2. Related Work
- 3. Compound Model Scaling
- 3.1. 問題公式化
- 3.2. Scaling Dimensions
- 3.3. Compound Scaling
- 4. EfficientNet Architecture
- 5. Experiments
- 6. Discussion
- 7. Conclusion
原文鏈接
源代碼
-
本文中的寬度可以理解為通道數,一般認為高的FLOPS更好,因為計算效率快
但本文中作者認為低的浮點運算數(FLOPS)更好是因為較低的FLOPS意味著模型在執行推理或訓練時需要更少的計算資源,這對于在計算能力有限的設備上部署模型或在大規模應用中效率更高都是很重要的。通過降低FLOPS,可以在保持性能的同時減少模型的復雜度,這有助于提高模型的速度和效率
Abstract
卷積神經網絡(ConvNets)通常是在固定的資源預算下開發的,如果有更多的資源可用,則可以擴展以獲得更好的準確性。在本文中,我們系統地研究了模型縮放,并確定仔細平衡網絡深度,寬度和分辨率可以帶來更好的性能。基于這一觀察結果,我們提出了一種新的縮放方法,該方法使用簡單而高效的復合系數對深度/寬度/分辨率的所有維度進行均勻縮放。我們證明了該方法在擴展MobileNets和ResNet方面的有效性
為了更進一步,我們使用神經架構搜索來設計一個新的基線網絡,并將其擴展以獲得一系列模型,稱為EffentNets,它比以前的ConvNets具有更好的準確性和效率。特別是,我們的EfficientNet-B7在ImageNet上達到了最先進的84.3%的top-1精度,同時比現有最好的ConvNet小8.4倍,推理速度快6.1倍。我們的EfficientNets在CIFAR-100(91.7%)、Flowers(98.8%)和其他3個遷移學習數據集上的遷移效果也很好,達到了最先進的準確率,參數減少了一個數量級
1. Introduction
擴大卷積神經網絡被廣泛用于獲得更好的準確率。例如,ResNet (He et al., 2016)可以通過使用更多的層從ResNet-18擴展到ResNet-200;最近,GPipe (Huang et al., 2018)通過將基線模型放大四倍,實現了84.3%的ImageNet top-1精度
diss former method
然而,擴大卷積神經網絡的過程從未被很好地理解,目前有很多方法可以做到這一點。最常見的方法是通過深度(He et al., 2016)或寬度(Zagoruyko & Komodakis, 2016)來擴展卷積神經網絡。另一種不太常見但越來越流行的方法是按圖像分辨率縮放模型(Huang et al., 2018)。在以前的工作中,通常只縮放三個維度中的一個——深度、寬度和圖像大小。雖然可以任意縮放兩個或三個維度,但任意縮放需要繁瑣的手動調優,并且仍然經常產生次優的精度和效率
our method
在本文中,我們想要研究和重新思考放大卷積神經網絡的過程。特別是,我們研究了一個核心問題:是否有一種原則性的方法來擴大卷積神經網絡,從而達到更好的準確性和效率?我們的實證研究表明,平衡網絡寬度/深度/分辨率的所有維度是至關重要的,令人驚訝的是,這種平衡可以通過簡單地以恒定的比例縮放每個維度來實現。在此基礎上,我們提出了一種簡單有效的復合標度方法。與傳統的任意縮放這些因素的做法不同,我們的方法用一組固定的縮放系數統一地縮放網絡寬度、深度和分辨率。例如,如果我們想使用2^N倍的計算資源,那么我們可以簡單地將網絡深度增加α N,寬度增加β N,圖像大小增加γ N,其中α,β,γ是由原始小模型上的小網格搜索確定的常系數。圖2說明了我們的縮放方法與傳統方法之間的區別
(a)是一個基線網絡示例;(b)-(d)為常規縮放,僅增加網絡寬度、深度或分辨率的一個維度。(e)是我們提出的以固定比例均勻縮放所有三個維度的復合縮放方法
直觀地說,復合縮放方法是有意義的,因為如果輸入圖像更大,那么網絡需要更多的層來增加接受域,需要更多的通道來捕獲更大圖像上的更細粒度的模式。事實上,之前的理論(Raghu et al., 2017;Lu et al., 2018)和實證結果(Zagoruyko & Komodakis, 2016)都表明網絡寬度和深度之間存在一定的關系,但據我們所知,我們是第一個對網絡寬度、深度和分辨率這三個維度之間的關系進行實證量化的人
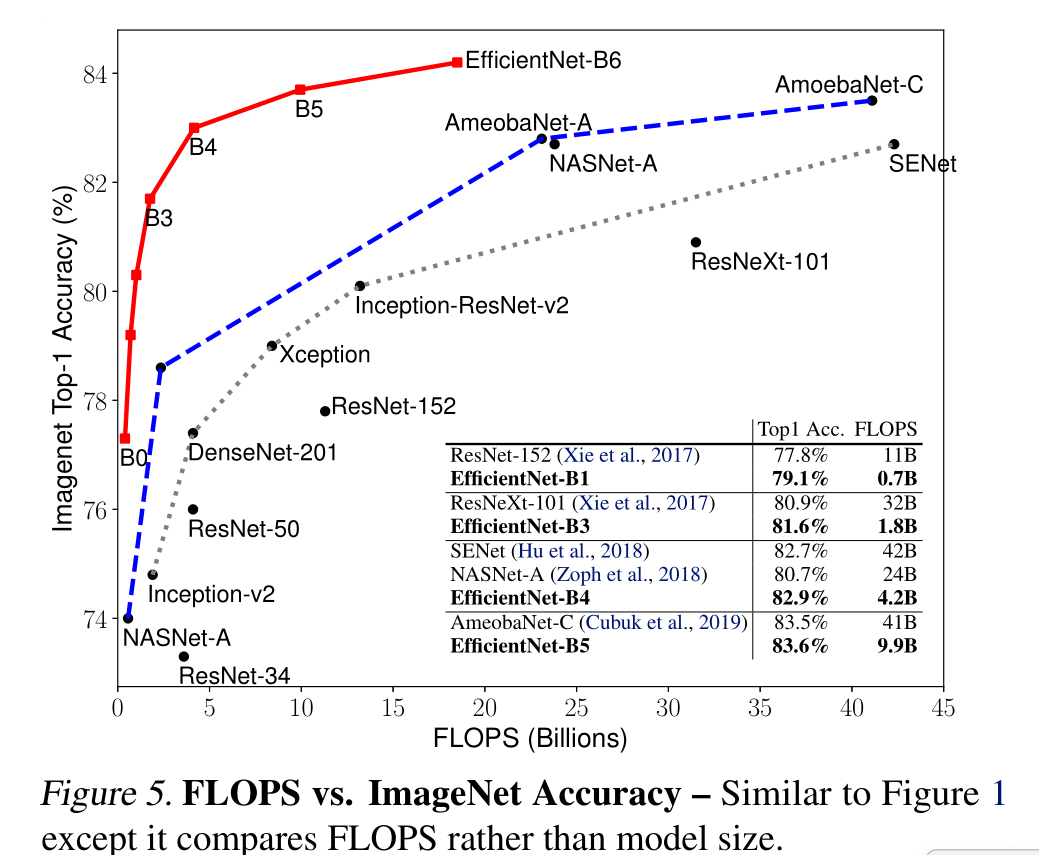
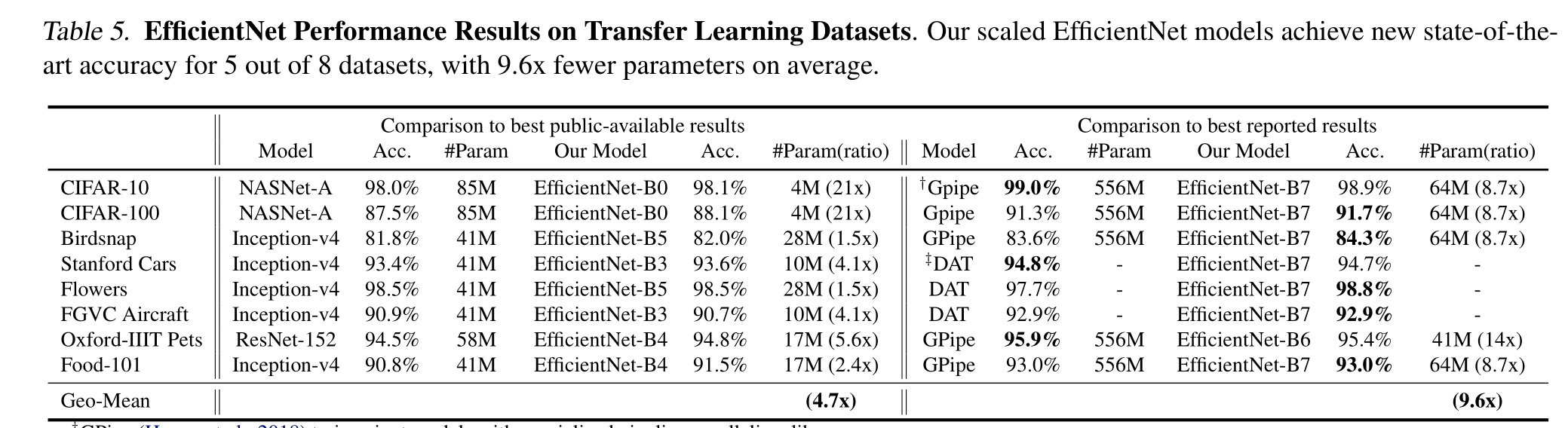
我們證明了我們的縮放方法在現有的mobilenet上工作得很好(Howard等人,2017;Sandler等人,2018)和ResNet (He等人,2016)。值得注意的是,模型縮放的有效性嚴重依賴于基線網絡;更進一步,我們使用神經架構搜索(Zoph & Le, 2017;Tan et al., 2019)開發一個新的基線網絡,并將其擴展以獲得一系列模型,稱為EfficientNets。圖1總結了ImageNet的性能,其中我們的EfficientNets明顯優于其他ConvNets。特別是,我們的EfficientNet-B7超過了現有的最佳GPipe精度(Huang et al., 2018),但使用的參數減少了8.4倍,在參考上運行速度提高了6.1倍。與廣泛使用的ResNet-50 (He et al., 2016)相比,我們的EfficientNet-B4在FLOPS相似的情況下,將top-1的準確率從76.3%提高到83.0%(+6.7%)。除了ImageNet, EfficientNets在8個廣泛使用的數據集中的5個上也能很好地傳輸并達到最先進的精度,同時比現有的ConvNets減少了高達21倍的參數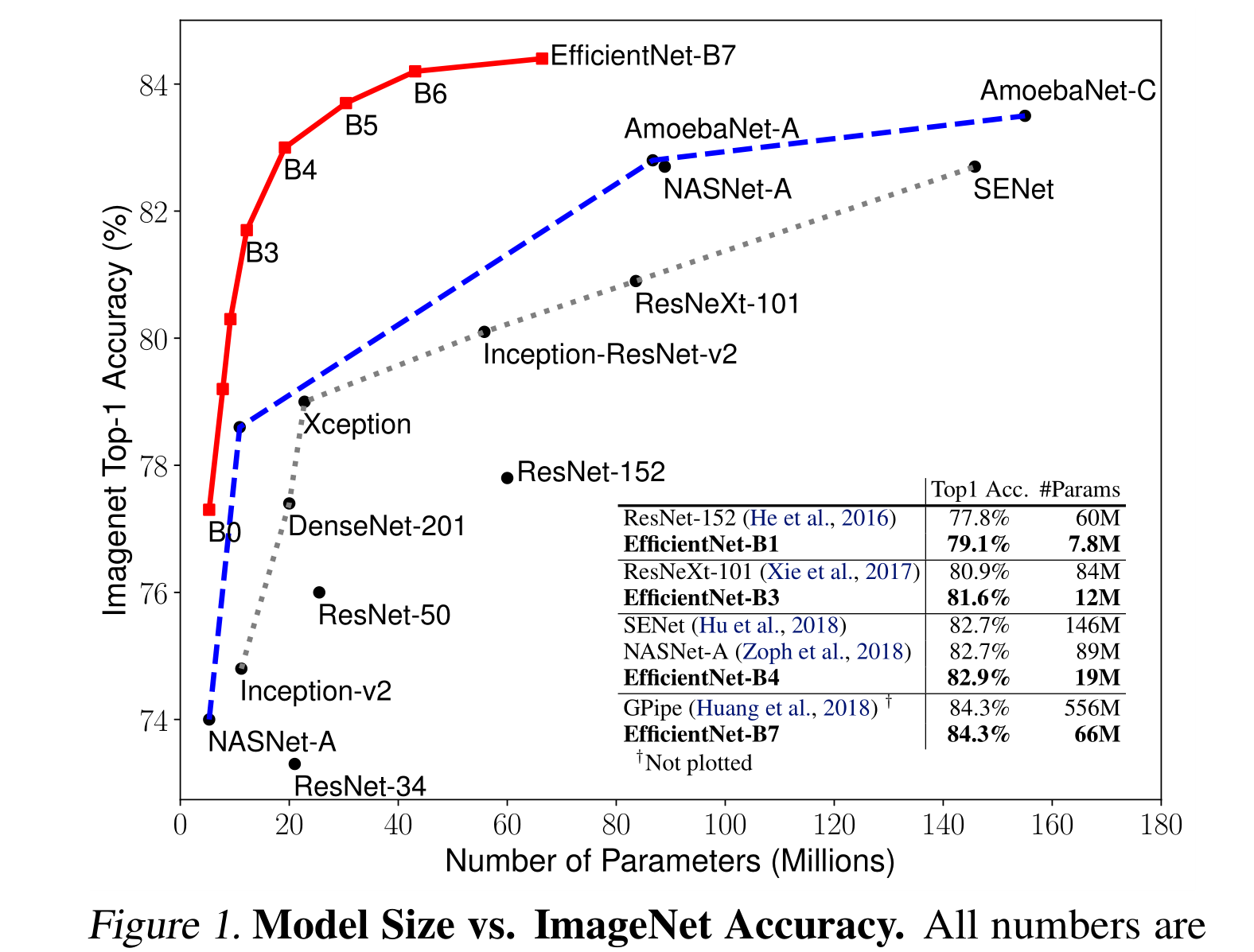
2. Related Work
簡單夸贊了下前人的work,從精度、效率和模型縮放方面
在本文中,我們的目標是研究超大規模卷積神經網絡的模型效率,以超越目前的精度。為了實現這一目標,我們采用模型縮放
網絡深度和寬度對卷積神經網絡的表達能力都很重要,但如何有效地擴展卷積神經網絡以獲得更好的效率和準確性仍然是一個懸而未決的問題。我們的工作系統地和經驗地研究了網絡寬度、深度和分辨率這三個維度的卷積神經網絡縮放
3. Compound Model Scaling
我們將制定縮放問題,研究不同的方法,并提出我們的新縮放方法
3.1. 問題公式化
卷積層i可以定義為一個函數:Y i = F i (X i),其中F i是算子,Y i是輸出張量,X i是輸入張量,張量的形狀是<H i,W i,C i >1,其中,hi和wi為空間維度,ci為通道維度。卷積神經網絡N可以用一個組合層的列表表示:N = F k ⊙…⊙f2 ⊙f1 (x1) = ⊙j = 1…k F j (x1)在實踐中,ConvNet層通常被劃分為多個階段,每個階段的所有層都共享相同的架構:例如,ResNet (He et al., 2016)有五個階段,每個階段的所有層都具有相同的卷積類型,除了第一層執行下采樣。因此,我們可以將ConvNet定義為:
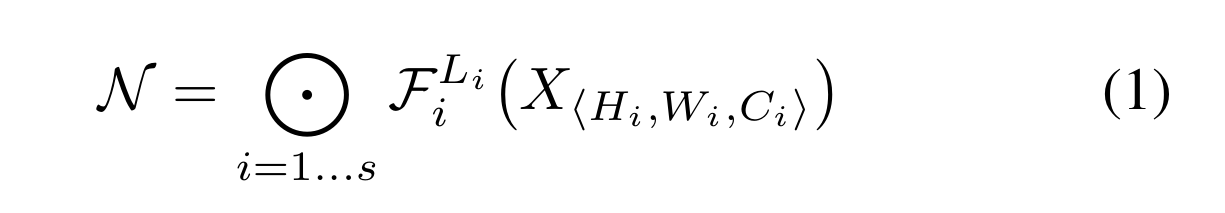
其中fl i i表示層F i在階段i重復L i次,表示第i層輸入張量X的形狀。圖2(a)展示了一個具有代表性的ConvNet,其中空間維度逐漸縮小,但通道維度逐層擴展,例如,從初始輸入形狀<224,224,3>到最后輸出形狀<7,7,512>
與常規的ConvNet設計不同,模型縮放試圖擴展網絡長度(L i)、寬度(C i)和/或分辨率(H i,W i),而不改變基線網絡中預定義的F i。通過固定F i,模型縮放簡化了針對新資源約束的設計問題,但對于每一層探索不同的L i,C i,H i,W i仍然有很大的設計空間。為了進一步縮小設計空間,我們限制所有層必須以恒定比例均勻縮放。我們的目標是在任何給定的資源約束下使模型精度最大化,這可以表述為一個優化問題:
式中,w、d、r為縮放網絡寬度、深度和分辨率的系數;F i、L i、H i、W i、C i是基線網絡中預定義的參數(示例見表1)。
3.2. Scaling Dimensions
問題2的主要難點在于最優的d、w、r相互依賴,且在不同的資源約束條件下其值是變化的。由于這個困難,傳統的方法主要是在以下一個維度上縮放卷積神經網絡:
**深度(d)😗*縮放網絡深度是許多卷積網絡最常用的方法(He et al., 2016;黃等人,2017;Szegedy等,2015;2016)。直覺是,更深層次的卷積神經網絡可以捕獲更豐富、更復雜的特征,并且可以很好地泛化新任務。然而,由于梯度消失問題,更深層的網絡也更難以訓練(Zagoruyko & Komodakis, 2016)。盡管跳躍連接(He et al., 2016)和批處理歸一化(ioffe&szegedy, 2015)等幾種技術緩解了訓練問題,但非常深的網絡的精度增益減少了:例如,ResNet-1000具有與ResNet-101相似的精度,盡管它具有更多的層。圖3(中)顯示了我們對不同深度系數d的基線模型進行縮放的實證研究,進一步表明了非常深的卷積神經網絡的精度回報遞減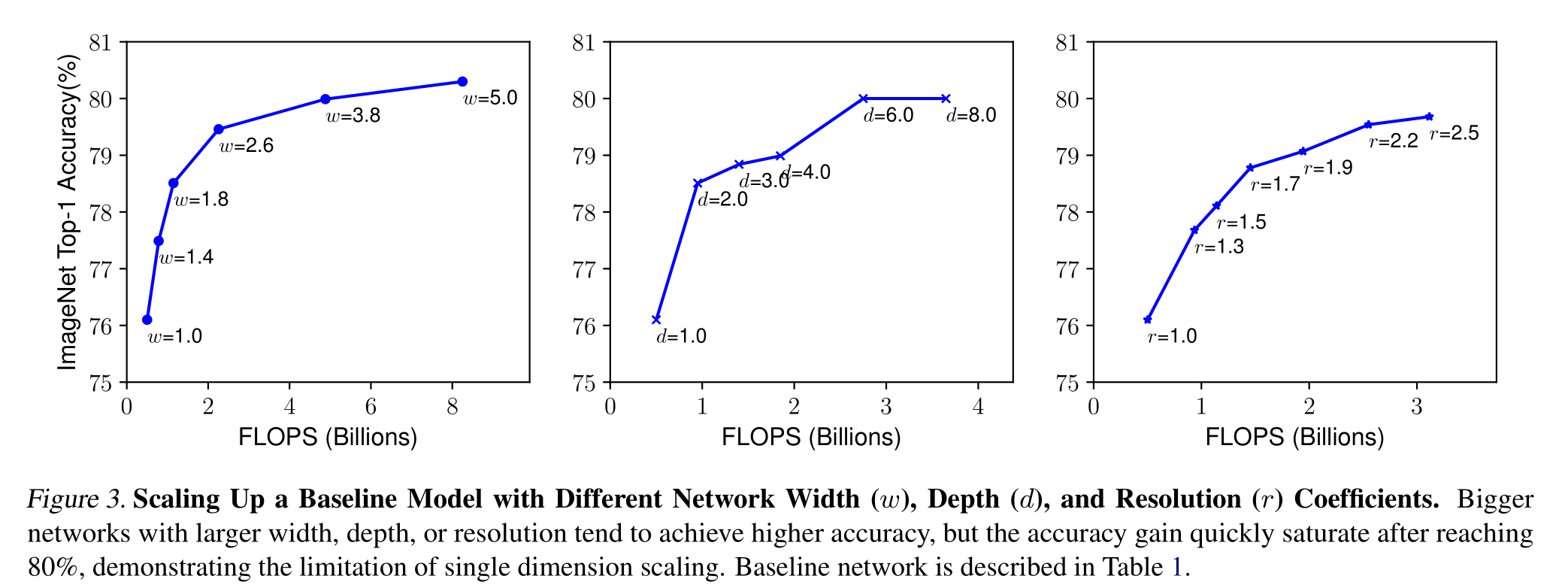
更大的網絡,具有更大的寬度、深度或分辨率,往往可以獲得更高的精度,但精度增益在達到80%后很快飽和,這表明了單維度縮放的局限性
寬度(w):通常用于縮放網絡寬度小尺寸模型(Howard et al., 2017;Sandler et al., 2018;Tan et al., 2019)正如(Zagoruyko & Ko-modakis, 2016)中所討論的,更廣泛的網絡往往能夠捕獲更細粒度的特征,并且更容易訓練。然而,極寬但較淺的網絡往往難以捕獲更高級的特征。我們在圖3(左)中的經驗結果表明,當網絡變得更寬,w更大時,準確性很快飽和
分辨率?:使用更高分辨率的輸入圖像,ConvNets可以捕獲更細粒度的模式。從早期ConvNets的224x224開始,現代ConvNets傾向于使用299x299 (Szegedy等人,2016)或331x331 (Zoph等人,2018)以獲得更好的精度。最近,GPipe (Huang et al., 2018)在480 × 480分辨率下實現了最先進的ImageNet精度。更高的分辨率,如600x600,也廣泛用于目標檢測卷積神經網絡(He et al., 2017;Lin等人,2017)。圖3(右)顯示了縮放網絡分辨率的結果,其中更高的分辨率確實提高了精度,但對于非常高的分辨率,精度增益會降低(r = 1.0表示分辨率224x224, r = 2.5表示分辨率560x560)
通過以上分析,我們得出了第一個結論:
放大網絡寬度、深度或分辨率的任何維度都可以提高精度,但對于更大的模型,精度增益會降低
3.3. Compound Scaling
我們通過經驗觀察到,不同的標度維度并不是相互獨立的。直觀地說,對于更高分辨率的圖像,我們應該增加網絡深度,這樣更大的接受域可以幫助捕獲在更大的圖像中包含更多像素的相似特征。相應的,我們也應該在分辨率較高時增加網絡寬度,以便在高分辨率圖像中以更多的像素捕獲更細粒度的圖案。這些直覺表明,我們需要協調和平衡不同的縮放維度,而不是傳統的單一維度縮放
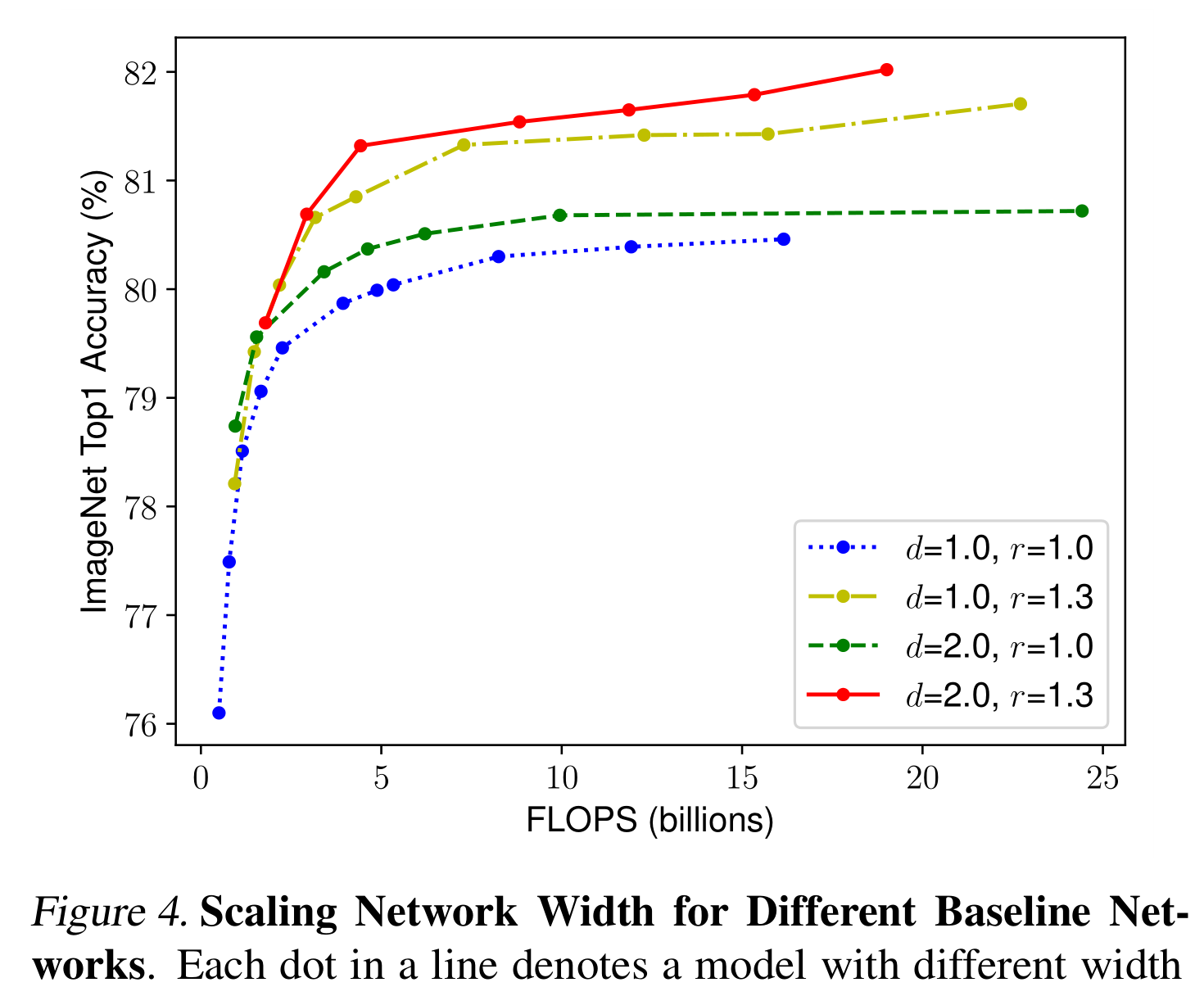
為了驗證我們的直覺,我們比較了不同網絡深度和分辨率下的寬度縮放,如圖4所示。如果我們只縮放網絡寬度w而不改變深度(d =1.0)和分辨率(r =1.0),則精度很快飽和。在相同的FLOPS成本下,在更深(d =2.0)和更高的分辨率(r =2.0)下,寬度縮放可以獲得更好的精度。這些結果將我們引向第二個觀察結果:
為了追求更好的精度和效率,在卷積神經網絡縮放過程中,平衡網絡寬度、深度和分辨率的各個維度是至關重要的
事實上,之前的一些工作(Zoph et al., 2018;Real et al., 2019)已經嘗試任意平衡網絡寬度和深度,但它們都需要繁瑣的手動調優
本文提出了一種新的復合縮放方法,該方法利用復合系數φ對網絡寬度、深度和分辨率進行有原則的均勻縮放:
其中α,β,γ是可以通過小網格搜索確定的常數。直觀地說,φ是一個用戶指定的系數,它控制有多少資源可用于模型縮放,而α,β,γ分別指定如何將這些額外的資源分配給網絡寬度,深度和分辨率
值得注意的是,規則卷積op的FLOPS與d, w, r成正比,即網絡深度加倍將使FLOPS加倍,但網絡寬度或分辨率加倍將使FLOPS增加四倍。由于卷積運算通常在卷積網絡的計算成本中占主導地位,因此用公式3縮放卷積網絡將使總FLOPS大約增加(α·β 2·γ 2 )φ。在本文中,我們約束α·β 2·γ 2≈2,使得對于任何新的φ,總FLOPS將大約增加2 ^φ
4. EfficientNet Architecture
由于模型縮放不會改變基線網絡中的層算子F i,因此擁有一個良好的基線網絡也至關重要。我們將使用現有的卷積神經網絡來評估我們的縮放方法,但為了更好地展示我們的縮放方法的有效性,我們還開發了一個新的移動尺寸基線,稱為EffientNet
受(Tan et al., 2019)的啟發,我們通過利用多目標神經架構搜索來開發基線網絡,該搜索可優化準確性和FLOPS。里我們優化FLOPS而不是延遲,因為我們不針對任何特定的硬件設備。我們的搜索產生了一個高效網絡,我們將其命名為EfficientNet-B0
表1顯示了EfficientNet-B0的體系結構。它的主要構建塊是移動反向瓶頸MBConv (San- dler et al., 2018;Tan等人,2019),我們還添加了擠壓和激勵優化(Hu等人,2018)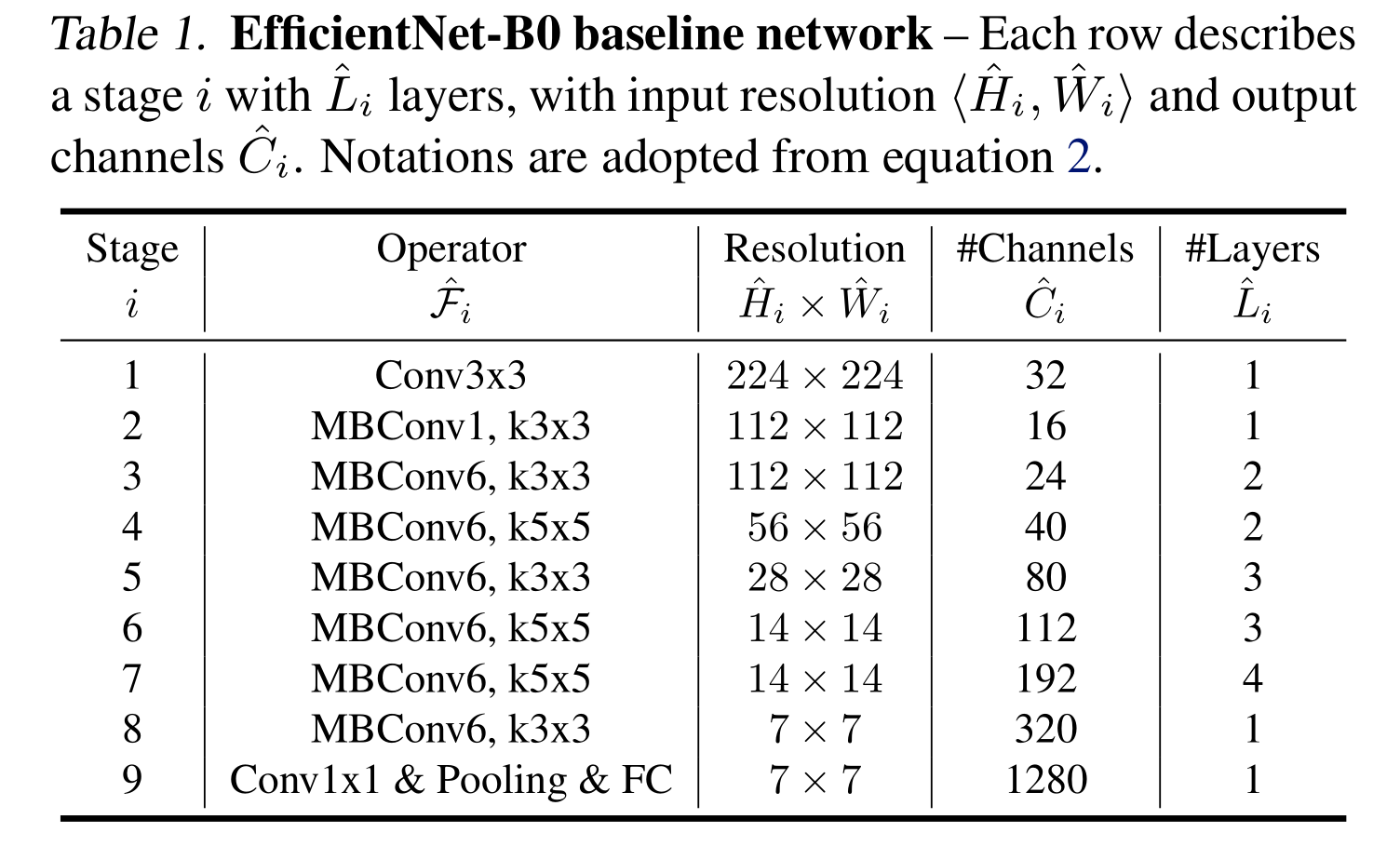
從基線EfficientNet-B0開始,我們采用復合擴展方法,分兩個步驟進行擴展:
? 第一步:我們首先固定φ = 1,假設兩倍以上的資源可用,并根據公式2和3進行α,β,γ的小網格搜索。特別地,我們發現在α·β 2·γ 2≈2的約束下,EfficientNet-B0的最佳值為α = 1.2,β = 1.1,γ = 1.15
?步驟2:然后我們將α,β,γ固定為常數,并使用公式3縮放具有不同φ的基線網絡,以獲得EfficientNet-B1到B7(詳細信息見表2)
即先固定φ ,計算α、β、γ,然后固定α、β、γ,計算φ
值得注意的是,通過在大型模型周圍直接搜索α,β,γ可以獲得更好的性能,但是在大型模型上搜索成本會變得非常昂貴。我們的方法解決了這個問題,只在小的基線網絡上做一次搜索(步驟1),然后對所有其他模型使用相同的縮放系數(步驟2)
5. Experiments

6. Discussion
為了區分我們提出的縮放方法對效率網架構的貢獻,圖8比較了相同效率網- b0基線網絡中不同縮放方法的ImageNet性能。一般來說,所有的縮放方法都以更高的FLOPS為代價來提高精度,但我們的復合縮放方法比其他單維縮放方法可以進一步提高精度,最高可達2.5%,這表明了我們提出的復合縮放方法的重要性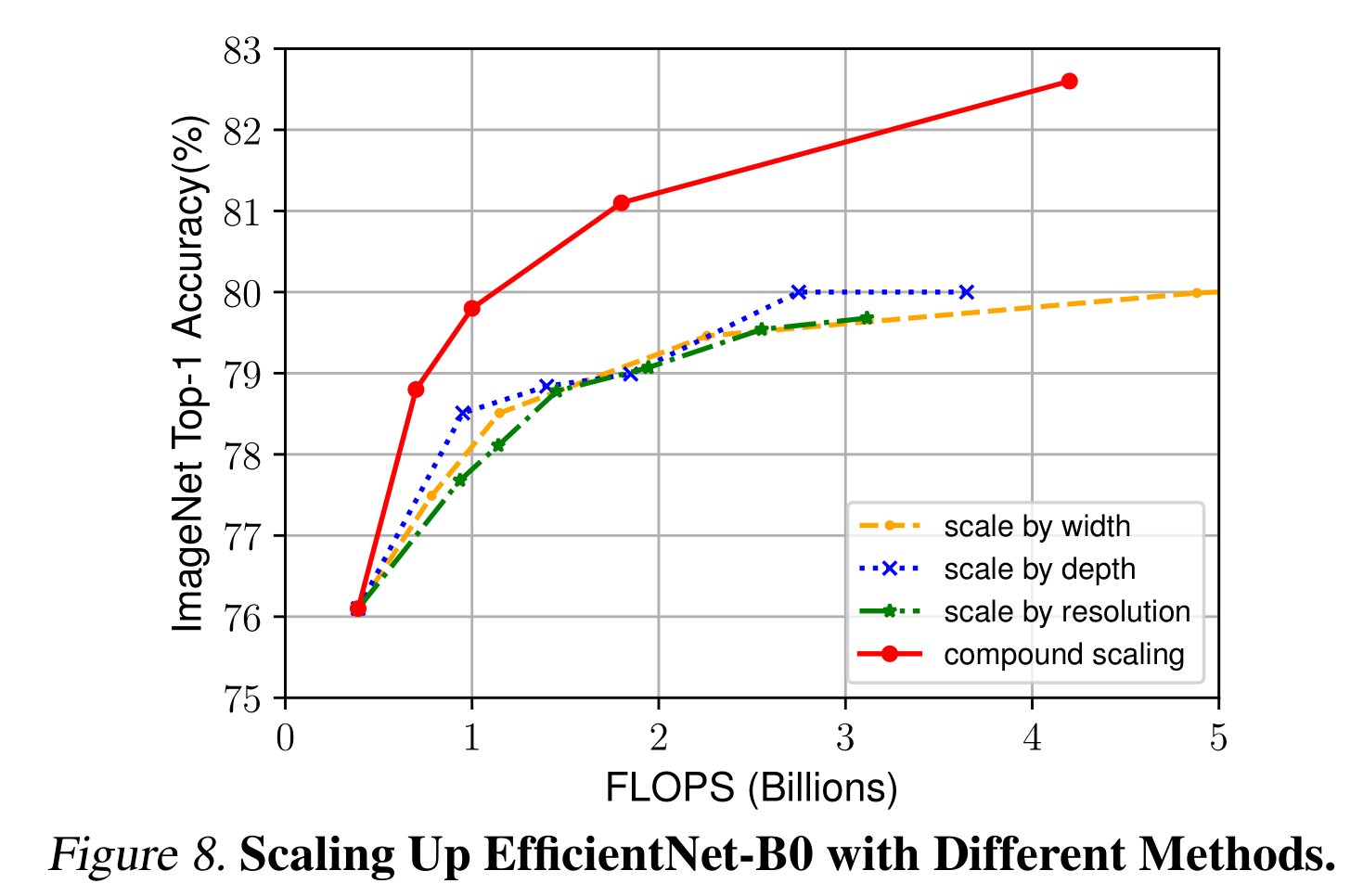
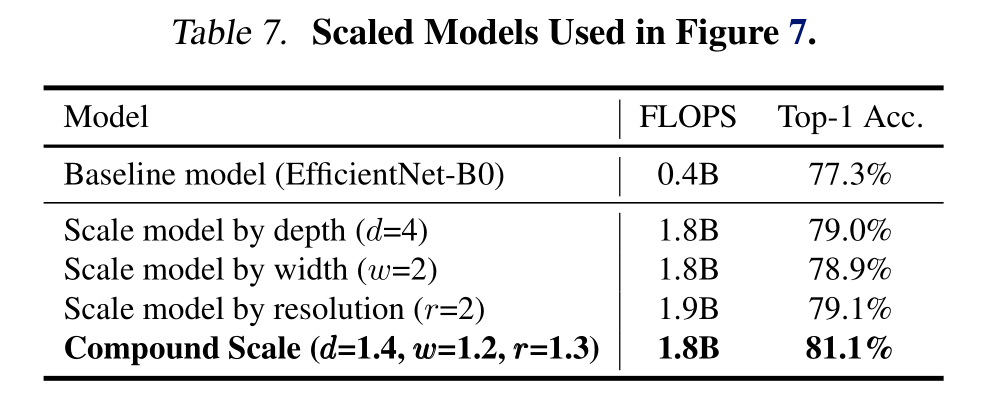
為了進一步理解為什么我們的復合縮放方法比其他方法更好,圖7比較了幾種不同縮放方法的代表性模型的類激活圖(Zhou et al., 2016)。所有這些模型都是從相同的基線進行縮放的,其統計數據如表7所示。圖像是從ImageNet驗證集中隨機選取的。如圖所示,復合縮放模型傾向于關注更相關的區域和更多的物體細節,而其他模型要么缺乏物體細節,要么無法捕獲圖像中的所有物體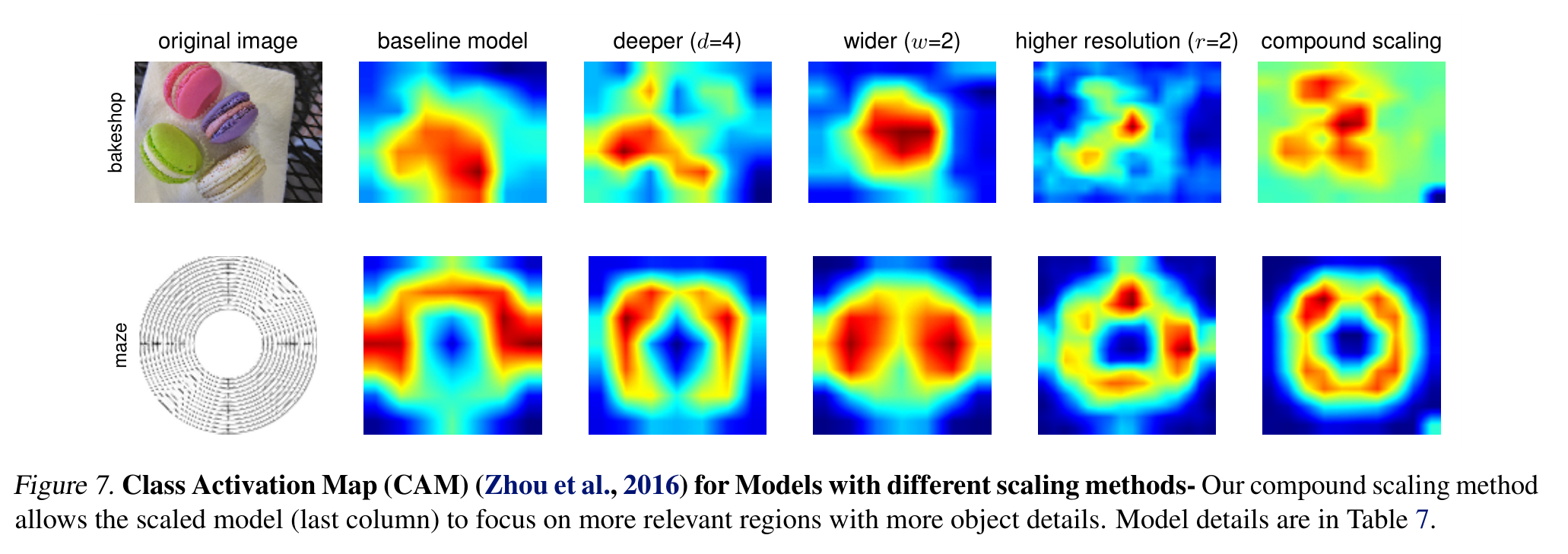
7. Conclusion
在本文中,我們系統地研究了卷積神經網絡的縮放,并確定仔細平衡網絡寬度,深度和分辨率是一個重要但缺失的部分,阻礙了我們更好的準確性和效率。為了解決這個問題,我們提出了一種簡單而高效的復合縮放方法,該方法使我們能夠以更有原則的方式輕松地將基線ConvNet擴展到任何目標資源約束,同時保持模型效率。在這種復合縮放方法的支持下,我們證明了移動尺寸的EfficientNet模型可以非常有效地縮放,在ImageNet和五種常用的遷移學習數據集上,以更少的參數和FLOPS超過了最先進的精度












 報錯 ValueError: Invalid format string)






