繼續下一個階段:
Train policy
python act/imitate_episodes.py \ --task_name [TASK] \ --ckpt_dir data/outputs/act_ckpt/[TASK]_waypoint \ --policy_class ACT --kl_weight 10 --chunk_size 50 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 \ --num_epochs 8000 --lr 1e-5 \ --seed 0 --temporal_agg --use_waypoint
For human datasets, set --kl_weight=80, as suggested by the ACT authors. To evaluate the policy, run the same command with --eval.
翻譯:對于人類數據集,如ACT作者所建議的,設置--kl_weight=80。若要評估策略,請使用-eval運行相同的命令。
在完成了Bimanual Simulation Suite(Save waypoints)的這個博客內容之后,即
Save waypoints的操作完成后,下面便可以進行sim_transfer_cube_scripted這一任務的訓練,即
Train policy:
首先進入awe的文件夾目錄中,在linux的終端中輸入以下的命令:
python act/imitate_episodes.py \ --task_name sim_transfer_cube_scripted \ --ckpt_dir data/outputs/act_ckpt/sim_transfer_cube_scripted_waypoint \ --policy_class ACT --kl_weight 10 --chunk_size 50 --hidden_dim 512 --batch_size 8 --dim_feedforward 3200 \ --num_epochs 8000 --lr 1e-5 \ --seed 0 --temporal_agg --use_waypoint
終端會進行訓練進度的顯示,截圖如下:
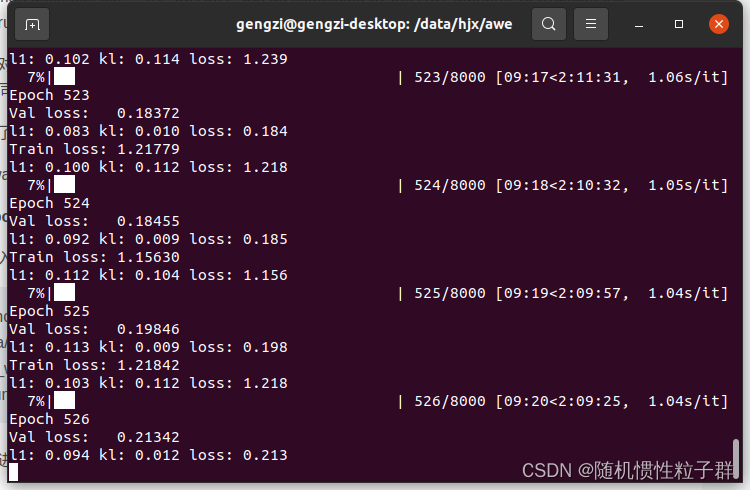
這時說明Train policy已經在進行了,等待訓練結束即可。
在運行這個Train policy時,遇到了一些小bug(報錯),記錄如下:
ModuleNotFoundError: No module named 'gym' 的解決方案:
pip install gym
ModuleNotFoundError: No module named 'gym' 錯誤表示你的Python環境中缺少了名為 gym 的Python模塊。gym 是用于開發和測試強化學習算法的一個常用庫,通常與OpenAI Gym一起使用。
ModuleNotFoundError: No module named 'dm_control' 的解決方案:
pip install dm_control
ModuleNotFoundError: No module named 'dm_control' 錯誤表示你的Python環境中缺少了名為 dm_control 的Python模塊。dm_control 是DeepMind開發的一個用于機器人控制和物理仿真的庫,通常與MuJoCo一起使用。
FileNotFoundError: [Errno 2] Unable to synchronously open file (unable to open file: name = 'data/act/sim_transfer_cube_scripted_copy/episode_0.hdf5', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0) 的解決方案:
在awe/data/act/的文件路徑中將sim_transfer_cube_scripted文件夾復制一份后更名為sim_transfer_cube_scripted_copy
FileNotFoundError 錯誤表示在指定的路徑下找不到文件。具體來說,錯誤消息中提到了文件路徑 'data/act/sim_transfer_cube_scripted_copy/episode_0.hdf5',但系統無法找到該文件,因為文件或路徑不存在。
raise AssertionError("Torch not compiled with CUDA enabled") AssertionError: Torch not compiled with CUDA enabled 的的解決方案:
nvidia-smi # 查看顯卡的CUDA Version: 12.2 我這里是 12.2,在去查找CUDA 12.2的PyTorch版本是1.10.0
?pip install torch==1.10.0 # 安裝CUDA 12.2的對應版本
請根據你的PyTorch版本和需求進行安裝。
pip install torch==1.10.0安裝完成后,接著進行Train policy時,又遇到了:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. torchvision 0.16.0 requires torch==2.1.0, but you have torch 1.10.0 which is incompatible.
其解決方案為:
pip install torchvision --upgrade
這將安裝 torchvision 的最新版本,該版本可能與你的 PyTorch 版本兼容。
這個錯誤消息表明 torchvision 需要與特定版本的 PyTorch 兼容,但你當前的 PyTorch 版本與 torchvision 不兼容。為了解決這個問題,你需要升級 torchvision 或降級 PyTorch,以使它們兼容。
最后有必要解讀一下 act/imitate_episodes.py 這個python文件,部分代碼粘貼如下:
def main(args):set_seed(1)# command line parametersis_eval = args["eval"]ckpt_dir = args["ckpt_dir"]policy_class = args["policy_class"]onscreen_render = args["onscreen_render"]task_name = args["task_name"]batch_size_train = args["batch_size"]batch_size_val = args["batch_size"]num_epochs = args["num_epochs"]use_waypoint = args["use_waypoint"]constant_waypoint = args["constant_waypoint"]if use_waypoint:print("Using waypoint")if constant_waypoint is not None:print(f"Constant waypoint: {constant_waypoint}")# get task parameters# is_sim = task_name[:4] == 'sim_'is_sim = True # hardcode to True to avoid finding constants from alohaif is_sim:from constants import SIM_TASK_CONFIGStask_config = SIM_TASK_CONFIGS[task_name]else:from aloha_scripts.constants import TASK_CONFIGStask_config = TASK_CONFIGS[task_name]dataset_dir = task_config["dataset_dir"]num_episodes = task_config["num_episodes"]episode_len = task_config["episode_len"]camera_names = task_config["camera_names"]# fixed parametersstate_dim = 14lr_backbone = 1e-5backbone = "resnet18"if policy_class == "ACT":enc_layers = 4dec_layers = 7nheads = 8policy_config = {"lr": args["lr"],"num_queries": args["chunk_size"],"kl_weight": args["kl_weight"],"hidden_dim": args["hidden_dim"],"dim_feedforward": args["dim_feedforward"],"lr_backbone": lr_backbone,"backbone": backbone,"enc_layers": enc_layers,"dec_layers": dec_layers,"nheads": nheads,"camera_names": camera_names,}elif policy_class == "CNNMLP":policy_config = {"lr": args["lr"],"lr_backbone": lr_backbone,"backbone": backbone,"num_queries": 1,"camera_names": camera_names,}else:raise NotImplementedErrorconfig = {"num_epochs": num_epochs,"ckpt_dir": ckpt_dir,"episode_len": episode_len,"state_dim": state_dim,"lr": args["lr"],"policy_class": policy_class,"onscreen_render": onscreen_render,"policy_config": policy_config,"task_name": task_name,"seed": args["seed"],"temporal_agg": args["temporal_agg"],"camera_names": camera_names,"real_robot": not is_sim,}if is_eval:ckpt_names = [f"policy_best.ckpt"]results = []for ckpt_name in ckpt_names:success_rate, avg_return = eval_bc(config, ckpt_name, save_episode=True)results.append([ckpt_name, success_rate, avg_return])for ckpt_name, success_rate, avg_return in results:print(f"{ckpt_name}: {success_rate=} {avg_return=}")print()exit()train_dataloader, val_dataloader, stats, _ = load_data(dataset_dir,num_episodes,camera_names,batch_size_train,batch_size_val,use_waypoint,constant_waypoint,)# save dataset statsif not os.path.isdir(ckpt_dir):os.makedirs(ckpt_dir)stats_path = os.path.join(ckpt_dir, f"dataset_stats.pkl")with open(stats_path, "wb") as f:pickle.dump(stats, f)best_ckpt_info = train_bc(train_dataloader, val_dataloader, config)best_epoch, min_val_loss, best_state_dict = best_ckpt_info# save best checkpointckpt_path = os.path.join(ckpt_dir, f"policy_best.ckpt")torch.save(best_state_dict, ckpt_path)print(f"Best ckpt, val loss {min_val_loss:.6f} @ epoch{best_epoch}")這段代碼是一個主程序,用于訓練或評估一個深度學習模型。以下是代碼的主要功能:
-
從命令行參數中獲取模型訓練和評估的相關配置。
-
根據任務名稱和配置獲取任務參數,例如數據集目錄、任務類型等。
-
定義模型的架構和超參數,包括學習率、網絡結構、層數等。
-
創建數據加載器,加載訓練和驗證數據集。
-
訓練模型并保存最佳模型的權重。如果模型已經在以前的訓練中保存了最佳權重,可以選擇加載這些權重并進行評估。
-
如果設置為評估模式,加載保存的模型權重并在驗證集上評估模型性能,計算成功率和平均回報。
-
最后,將結果打印出來。
請注意,這段代碼需要其他模塊和庫的支持,例如數據加載、模型定義、訓練和評估函數等。要運行這段代碼,你需要確保所有的依賴項都已安裝,并提供正確的命令行參數以配置模型訓練或評估的行為。
?
def make_policy(policy_class, policy_config):if policy_class == "ACT":policy = ACTPolicy(policy_config)elif policy_class == "CNNMLP":policy = CNNMLPPolicy(policy_config)else:raise NotImplementedErrorreturn policy這個函數根據指定的policy_class(策略類別)和policy_config(策略配置)創建一個策略模型對象。策略模型用于執行某種任務或動作,通常是在強化學習中使用的。
函數的工作流程如下:
-
接受兩個參數:
policy_class表示要創建的策略模型的類別,policy_config表示策略模型的配置參數。 -
根據
policy_class的值,決定創建哪種類型的策略模型。目前支持兩種類型:"ACT"和"CNNMLP"。 -
創建指定類型的策略模型,并使用傳遞的
policy_config來配置模型的超參數和設置。 -
返回創建的策略模型對象。
這個函數的主要作用是根據需要創建不同類型的策略模型,并提供一個統一的接口供其他部分的代碼使用。根據具體的應用和任務,可以選擇不同的策略模型類型,以滿足任務的需求。如果需要了解更多關于不同策略模型類型的詳細信息,可以查看對應的策略模型的定義(例如,ACTPolicy和CNNMLPPolicy)。
?
def make_optimizer(policy_class, policy):if policy_class == "ACT":optimizer = policy.configure_optimizers()elif policy_class == "CNNMLP":optimizer = policy.configure_optimizers()else:raise NotImplementedErrorreturn optimizer這個函數用于創建策略模型的優化器(optimizer),并返回創建的優化器對象。優化器的作用是根據策略模型的損失函數來更新模型的參數,以使損失函數盡量減小。
函數的工作流程如下:
-
接受兩個參數:
policy_class表示策略模型的類別,policy表示已經創建的策略模型對象。 -
根據
policy_class的值,決定使用哪種類型的優化器配置。目前支持兩種類型:"ACT"和"CNNMLP"。 -
調用策略模型的
configure_optimizers方法,該方法通常會返回一個用于優化模型的優化器對象。 -
返回創建的優化器對象。
這個函數的主要作用是根據策略模型的類別和已經創建的策略模型對象來創建相應的優化器。不同的策略模型可能需要不同的優化器配置,因此通過調用策略模型的方法來創建優化器,以確保配置的一致性。優化器對象通常用于后續的訓練過程中,用于更新模型的參數以最小化損失函數。
?
def get_image(ts, camera_names):curr_images = []for cam_name in camera_names:curr_image = rearrange(ts.observation["images"][cam_name], "h w c -> c h w")curr_images.append(curr_image)curr_image = np.stack(curr_images, axis=0)curr_image = torch.from_numpy(curr_image / 255.0).float().cuda().unsqueeze(0)return curr_image這個函數的作用是獲取一個時間步(ts)的圖像數據。函數接受兩個參數:ts和camera_names。
-
ts是一個時間步的數據,包含了多個相機(攝像頭)拍攝的圖像。ts.observation["images"]包含了各個相機拍攝的圖像數據,而camera_names是一個列表,包含了要獲取的相機的名稱。 -
函數通過循環遍歷
camera_names中的相機名稱,從ts.observation["images"]中獲取對應相機的圖像數據。這些圖像數據首先通過rearrange函數重新排列維度,將"height-width-channels"的順序變為"channels-height-width",以適應PyTorch的數據格式。 -
獲取的圖像數據被放入
curr_images列表中。 -
接下來,函數將
curr_images列表中的所有圖像數據堆疊成一個張量(tensor),np.stack(curr_images, axis=0)這一行代碼實現了這個操作。 -
接著,圖像數據被歸一化到[0, 1]的范圍,然后轉換為PyTorch的
float類型,并移到GPU上(如果可用)。最后,圖像數據被增加了一個額外的維度(unsqueeze(0)),以適應模型的輸入要求。
最終,函數返回包含時間步圖像數據的PyTorch張量。這個圖像數據可以被用于輸入到神經網絡模型中進行處理。
?
def eval_bc(config, ckpt_name, save_episode=True):set_seed(1000)ckpt_dir = config["ckpt_dir"]state_dim = config["state_dim"]real_robot = config["real_robot"]policy_class = config["policy_class"]onscreen_render = config["onscreen_render"]policy_config = config["policy_config"]camera_names = config["camera_names"]max_timesteps = config["episode_len"]task_name = config["task_name"]temporal_agg = config["temporal_agg"]onscreen_cam = "angle"# load policy and statsckpt_path = os.path.join(ckpt_dir, ckpt_name)policy = make_policy(policy_class, policy_config)loading_status = policy.load_state_dict(torch.load(ckpt_path))print(loading_status)policy.cuda()policy.eval()print(f"Loaded: {ckpt_path}")stats_path = os.path.join(ckpt_dir, f"dataset_stats.pkl")with open(stats_path, "rb") as f:stats = pickle.load(f)pre_process = lambda s_qpos: (s_qpos - stats["qpos_mean"]) / stats["qpos_std"]post_process = lambda a: a * stats["action_std"] + stats["action_mean"]# load environmentif real_robot:from aloha_scripts.robot_utils import move_grippers # requires alohafrom aloha_scripts.real_env import make_real_env # requires alohaenv = make_real_env(init_node=True)env_max_reward = 0else:from act.sim_env import make_sim_envenv = make_sim_env(task_name)env_max_reward = env.task.max_rewardquery_frequency = policy_config["num_queries"]if temporal_agg:query_frequency = 1num_queries = policy_config["num_queries"]max_timesteps = int(max_timesteps * 1) # may increase for real-world tasksnum_rollouts = 50episode_returns = []highest_rewards = []for rollout_id in range(num_rollouts):rollout_id += 0### set taskif "sim_transfer_cube" in task_name:BOX_POSE[0] = sample_box_pose() # used in sim resetelif "sim_insertion" in task_name:BOX_POSE[0] = np.concatenate(sample_insertion_pose()) # used in sim resetts = env.reset()### onscreen renderif onscreen_render:ax = plt.subplot()plt_img = ax.imshow(env._physics.render(height=480, width=640, camera_id=onscreen_cam))plt.ion()### evaluation loopif temporal_agg:all_time_actions = torch.zeros([max_timesteps, max_timesteps + num_queries, state_dim]).cuda()qpos_history = torch.zeros((1, max_timesteps, state_dim)).cuda()image_list = [] # for visualizationqpos_list = []target_qpos_list = []rewards = []with torch.inference_mode():for t in range(max_timesteps):### update onscreen render and wait for DTif onscreen_render:image = env._physics.render(height=480, width=640, camera_id=onscreen_cam)plt_img.set_data(image)plt.pause(DT)### process previous timestep to get qpos and image_listobs = ts.observationif "images" in obs:image_list.append(obs["images"])else:image_list.append({"main": obs["image"]})qpos_numpy = np.array(obs["qpos"])qpos = pre_process(qpos_numpy)qpos = torch.from_numpy(qpos).float().cuda().unsqueeze(0)qpos_history[:, t] = qposcurr_image = get_image(ts, camera_names)### query policyif config["policy_class"] == "ACT":if t % query_frequency == 0:all_actions = policy(qpos, curr_image)if temporal_agg:all_time_actions[[t], t : t + num_queries] = all_actionsactions_for_curr_step = all_time_actions[:, t]actions_populated = torch.all(actions_for_curr_step != 0, axis=1)actions_for_curr_step = actions_for_curr_step[actions_populated]k = 0.01exp_weights = np.exp(-k * np.arange(len(actions_for_curr_step)))exp_weights = exp_weights / exp_weights.sum()exp_weights = (torch.from_numpy(exp_weights).cuda().unsqueeze(dim=1))raw_action = (actions_for_curr_step * exp_weights).sum(dim=0, keepdim=True)else:raw_action = all_actions[:, t % query_frequency]elif config["policy_class"] == "CNNMLP":raw_action = policy(qpos, curr_image)else:raise NotImplementedError### post-process actionsraw_action = raw_action.squeeze(0).cpu().numpy()action = post_process(raw_action)target_qpos = action### step the environmentts = env.step(target_qpos)### for visualizationqpos_list.append(qpos_numpy)target_qpos_list.append(target_qpos)rewards.append(ts.reward)plt.close()if real_robot:move_grippers([env.puppet_bot_left, env.puppet_bot_right],[PUPPET_GRIPPER_JOINT_OPEN] * 2,move_time=0.5,) # openpassrewards = np.array(rewards)episode_return = np.sum(rewards[rewards != None])episode_returns.append(episode_return)episode_highest_reward = np.max(rewards)highest_rewards.append(episode_highest_reward)print(f"Rollout {rollout_id}\n{episode_return=}, {episode_highest_reward=}, {env_max_reward=}, Success: {episode_highest_reward==env_max_reward}")if save_episode:save_videos(image_list,DT,video_path=os.path.join(ckpt_dir, f"video{rollout_id}.mp4"),)success_rate = np.mean(np.array(highest_rewards) == env_max_reward)avg_return = np.mean(episode_returns)summary_str = f"\nSuccess rate: {success_rate}\nAverage return: {avg_return}\n\n"for r in range(env_max_reward + 1):more_or_equal_r = (np.array(highest_rewards) >= r).sum()more_or_equal_r_rate = more_or_equal_r / num_rolloutssummary_str += f"Reward >= {r}: {more_or_equal_r}/{num_rollouts} = {more_or_equal_r_rate*100}%\n"print(summary_str)# save success rate to txtresult_file_name = "result_" + ckpt_name.split(".")[0] + ".txt"with open(os.path.join(ckpt_dir, result_file_name), "w") as f:f.write(summary_str)f.write(repr(episode_returns))f.write("\n\n")f.write(repr(highest_rewards))return success_rate, avg_return這個函數用于評估一個行為克隆(behavior cloning)模型。它接受以下參數:
config:配置信息,包含了模型、訓練參數等。ckpt_name:要加載的模型權重的文件名。save_episode:一個布爾值,表示是否要保存評估過程中的圖像數據。
函數的主要步驟如下:
-
加載行為克隆模型的權重文件,根據配置信息初始化模型,并將模型移動到GPU上。
-
加載數據集統計信息,用于對觀測數據進行歸一化和反歸一化。
-
根據配置信息創建模擬環境或真實機器人環境。
-
設置評估的循環次數(
num_rollouts),每次循環都會進行一次評估。 -
在每次循環中,初始化環境,執行模型生成的動作并觀測環境的響應。
-
將每個時間步的觀測數據(包括圖像、關節位置等)存儲在相應的列表中。
-
計算每次評估的總回報,以及每次評估的最高回報,并記錄成功率。
-
如果指定了保存評估過程中的圖像數據,將每次評估的圖像數據保存為視頻。
-
輸出評估結果,包括成功率、平均回報以及回報分布。
-
將評估結果保存到文本文件中。
最終,函數返回成功率和平均回報。這些結果可以用于評估模型的性能。
?
def forward_pass(data, policy):image_data, qpos_data, action_data, is_pad = dataimage_data, qpos_data, action_data, is_pad = (image_data.cuda(),qpos_data.cuda(),action_data.cuda(),is_pad.cuda(),)return policy(qpos_data, image_data, action_data, is_pad) # TODO remove None這個函數用于執行前向傳播(forward pass)操作,以生成模型的輸出。它接受以下參數:
data:包含輸入數據的元組,其中包括圖像數據、關節位置數據、動作數據以及填充標志。policy:行為克隆模型。
函數的主要步驟如下:
-
將輸入數據轉移到GPU上,以便在GPU上進行計算。
-
調用行為克隆模型的前向傳播方法(
policy),將關節位置數據、圖像數據、動作數據和填充標志傳遞給模型。 -
返回模型的輸出,這可能是模型對動作數據的預測結果。
在這里,需要注意的是,在調用模型的前向傳播方法時,傳遞了四個參數:qpos_data、image_data、action_data 和 is_pad。
?
def train_bc(train_dataloader, val_dataloader, config):num_epochs = config["num_epochs"]ckpt_dir = config["ckpt_dir"]seed = config["seed"]policy_class = config["policy_class"]policy_config = config["policy_config"]set_seed(seed)policy = make_policy(policy_class, policy_config)# if ckpt_dir is not empty, prompt the user to load the checkpointif os.path.isdir(ckpt_dir) and len(os.listdir(ckpt_dir)) > 1:print(f"Checkpoint directory {ckpt_dir} is not empty. Load checkpoint? (y/n)")load_ckpt = input()if load_ckpt == "y":# load the latest checkpointlatest_idx = max([int(f.split("_")[2])for f in os.listdir(ckpt_dir)if f.startswith("policy_epoch_")])ckpt_path = os.path.join(ckpt_dir, f"policy_epoch_{latest_idx}_seed_{seed}.ckpt")print(f"Loading checkpoint from {ckpt_path}")loading_status = policy.load_state_dict(torch.load(ckpt_path))print(loading_status)else:print("Not loading checkpoint")latest_idx = 0else:latest_idx = 0policy.cuda()optimizer = make_optimizer(policy_class, policy)train_history = []validation_history = []min_val_loss = np.infbest_ckpt_info = Nonefor epoch in tqdm(range(latest_idx, num_epochs)):print(f"\nEpoch {epoch}")# validationwith torch.inference_mode():policy.eval()epoch_dicts = []for batch_idx, data in enumerate(val_dataloader):forward_dict = forward_pass(data, policy)epoch_dicts.append(forward_dict)epoch_summary = compute_dict_mean(epoch_dicts)validation_history.append(epoch_summary)epoch_val_loss = epoch_summary["loss"]if epoch_val_loss < min_val_loss:min_val_loss = epoch_val_lossbest_ckpt_info = (epoch, min_val_loss, deepcopy(policy.state_dict()))print(f"Val loss: {epoch_val_loss:.5f}")summary_string = ""for k, v in epoch_summary.items():summary_string += f"{k}: {v.item():.3f} "print(summary_string)# trainingpolicy.train()optimizer.zero_grad()for batch_idx, data in enumerate(train_dataloader):forward_dict = forward_pass(data, policy)# backwardloss = forward_dict["loss"]loss.backward()optimizer.step()optimizer.zero_grad()train_history.append(detach_dict(forward_dict))e = epoch - latest_idxepoch_summary = compute_dict_mean(train_history[(batch_idx + 1) * e : (batch_idx + 1) * (epoch + 1)])epoch_train_loss = epoch_summary["loss"]print(f"Train loss: {epoch_train_loss:.5f}")summary_string = ""for k, v in epoch_summary.items():summary_string += f"{k}: {v.item():.3f} "print(summary_string)if epoch % 100 == 0:ckpt_path = os.path.join(ckpt_dir, f"policy_epoch_{epoch}_seed_{seed}.ckpt")torch.save(policy.state_dict(), ckpt_path)plot_history(train_history, validation_history, epoch, ckpt_dir, seed)ckpt_path = os.path.join(ckpt_dir, f"policy_last.ckpt")torch.save(policy.state_dict(), ckpt_path)best_epoch, min_val_loss, best_state_dict = best_ckpt_infockpt_path = os.path.join(ckpt_dir, f"policy_epoch_{best_epoch}_seed_{seed}.ckpt")torch.save(best_state_dict, ckpt_path)print(f"Training finished:\nSeed {seed}, val loss {min_val_loss:.6f} at epoch {best_epoch}")# save training curvesplot_history(train_history, validation_history, num_epochs, ckpt_dir, seed)return best_ckpt_info這個函數用于訓練行為克隆(Behavior Cloning)模型。它接受以下參數:
train_dataloader:訓練數據的數據加載器,用于從訓練集中獲取批次的數據。val_dataloader:驗證數據的數據加載器,用于從驗證集中獲取批次的數據。config:包含訓練配置信息的字典。
函數的主要步驟如下:
-
初始化訓練過程所需的各種參數和配置。
-
創建行為克隆模型,并根據是否存在之前的訓練檢查點來加載模型權重。
-
定義優化器,用于更新模型的權重。
-
進行訓練循環,每個循環迭代一個 epoch,包括以下步驟:
- 驗證:在驗證集上計算模型的性能,并記錄驗證結果。如果當前模型的驗證性能優于歷史最佳模型,則保存當前模型的權重。
- 訓練:在訓練集上進行模型的訓練,計算損失并執行反向傳播來更新模型的權重。
- 每隔一定周期,保存當前模型的權重和繪制訓練曲線圖。
-
訓練完成后,保存最佳模型的權重和繪制訓練曲線圖。
總體來說,這個函數負責管理模型的訓練過程,包括訓練循環、驗證和模型參數的保存。訓練過程中的損失、性能指標等信息都會被記錄下來以供后續分析和可視化。
?
def plot_history(train_history, validation_history, num_epochs, ckpt_dir, seed):# save training curvesfor key in train_history[0]:plot_path = os.path.join(ckpt_dir, f"train_val_{key}_seed_{seed}.png")plt.figure()train_values = [summary[key].item() for summary in train_history]val_values = [summary[key].item() for summary in validation_history]plt.plot(np.linspace(0, num_epochs - 1, len(train_history)),train_values,label="train",)plt.plot(np.linspace(0, num_epochs - 1, len(validation_history)),val_values,label="validation",)# plt.ylim([-0.1, 1])plt.tight_layout()plt.legend()plt.title(key)plt.savefig(plot_path)print(f"Saved plots to {ckpt_dir}")這個函數用于繪制訓練過程中的損失曲線以及其他指標的曲線。它接受以下參數:
train_history:包含訓練過程中損失和其他指標的歷史記錄。validation_history:包含驗證過程中損失和其他指標的歷史記錄。num_epochs:總的訓練周期數。ckpt_dir:檢查點文件的保存目錄。seed:用于隨機種子的值。
該函數的主要功能是遍歷 train_history 和 validation_history 中的指標,并為每個指標創建一個繪圖,其中包括訓練集和驗證集的曲線。具體步驟如下:
-
對于每個指標(如損失、準確率等),創建一個繪圖并設置其標題。
-
從
train_history和validation_history中提取相應指標的值,并分別繪制訓練集和驗證集的曲線。 -
將繪圖保存到指定的文件路徑(使用隨機種子和指標名稱命名文件)。
-
最后,輸出已保存繪圖的信息。
這個函數的作用是幫助可視化訓練過程中的指標變化,以便更好地理解模型的訓練效果。
?
if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--eval", action="store_true")parser.add_argument("--onscreen_render", action="store_true")parser.add_argument("--ckpt_dir", action="store", type=str, help="ckpt_dir", required=True)parser.add_argument("--policy_class",action="store",type=str,help="policy_class, capitalize",required=True,)parser.add_argument("--task_name", action="store", type=str, help="task_name", required=True)parser.add_argument("--batch_size", action="store", type=int, help="batch_size", required=True)parser.add_argument("--seed", action="store", type=int, help="seed", required=True)parser.add_argument("--num_epochs", action="store", type=int, help="num_epochs", required=True)parser.add_argument("--lr", action="store", type=float, help="lr", required=True)# for ACTparser.add_argument("--kl_weight", action="store", type=int, help="KL Weight", required=False)parser.add_argument("--chunk_size", action="store", type=int, help="chunk_size", required=False)parser.add_argument("--hidden_dim", action="store", type=int, help="hidden_dim", required=False)parser.add_argument("--dim_feedforward",action="store",type=int,help="dim_feedforward",required=False,)parser.add_argument("--temporal_agg", action="store_true")# for waypointsparser.add_argument("--use_waypoint", action="store_true")parser.add_argument("--constant_waypoint",action="store",type=int,help="constant_waypoint",required=False,)main(vars(parser.parse_args()))這段代碼是一個入口點,用于執行訓練和評估操作。它首先解析命令行參數,然后根據這些參數執行不同的操作。以下是每個參數的簡要說明:
--eval:是否執行評估操作(可選參數)。--onscreen_render:是否進行屏幕渲染(可選參數)。--ckpt_dir:檢查點文件的保存目錄(必需參數)。--policy_class:策略類別,首字母大寫(必需參數)。--task_name:任務名稱(必需參數)。--batch_size:批處理大小(必需參數)。--seed:隨機種子(必需參數)。--num_epochs:訓練周期數(必需參數)。--lr:學習率(必需參數)。
接下來是一些與特定策略(如ACT策略)和路點(waypoints)相關的可選參數,以及一些用于控制訓練過程的參數。最后,它調用了 main 函數,并傳遞解析后的參數作為參數。根據參數的不同組合,代碼將執行訓練或評估操作,具體操作由 main 函數中的邏輯決定。





 報錯 ValueError: Invalid format string)







----讀取融合算法輸出的四元數)

切換主題色)



案例教程)