????? 網絡爬蟲是一種自動化的網頁數據抓取技術,廣泛用于數據挖掘、信息搜集和互聯網研究等領域。Python作為一種強大的編程語言,擁有豐富的庫支持網絡爬蟲的開發。本文將為你詳細介紹如何在你的計算機上安裝Python網絡爬蟲環境。
一、安裝python開發環境
進去官網www.python.org
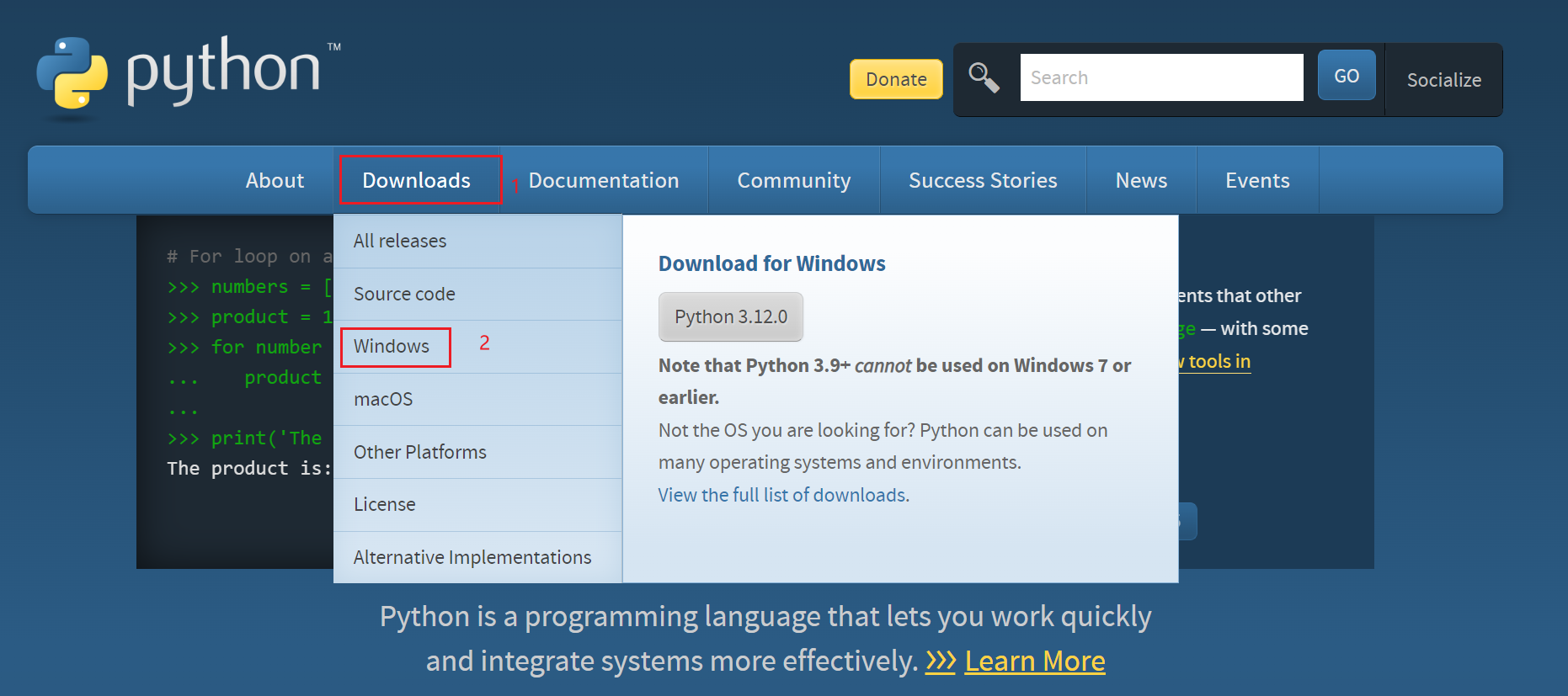
選擇相應的python版本下載

雙擊下載的安裝包
勾選即把python路徑添加到環境變量中(不勾選的話在 doc命令窗口使用不了python指令)


安裝完成后 WIN鍵+R 輸入CDM 然后在DOC命令行輸入python顯示如下信息說明安裝成功了
輸入exit()退出

二、安裝對應的庫
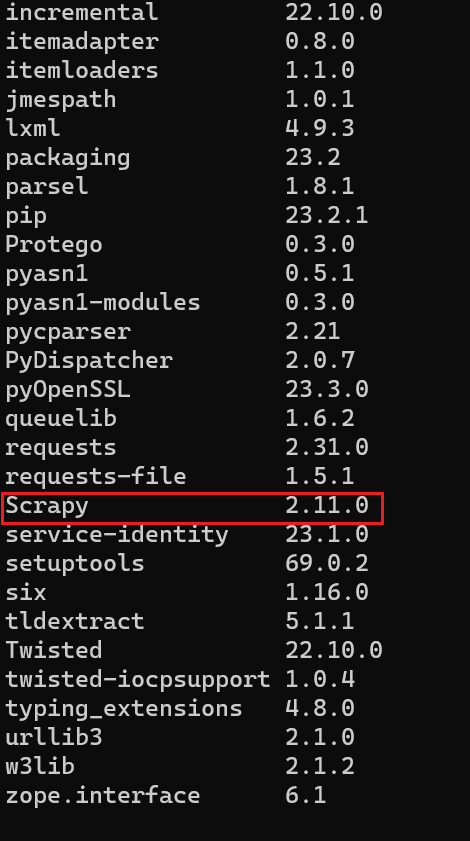
1、安裝Scrapy框架(一個快速高級的爬蟲框架)
-i表示下載庫的地址(使用的是國內清華鏡像源,快)
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple

輸入 pip list? 查看
2、安裝Jupyter(一個開源的交互式計算環境)
pip install? jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple

3、登錄Jupyter
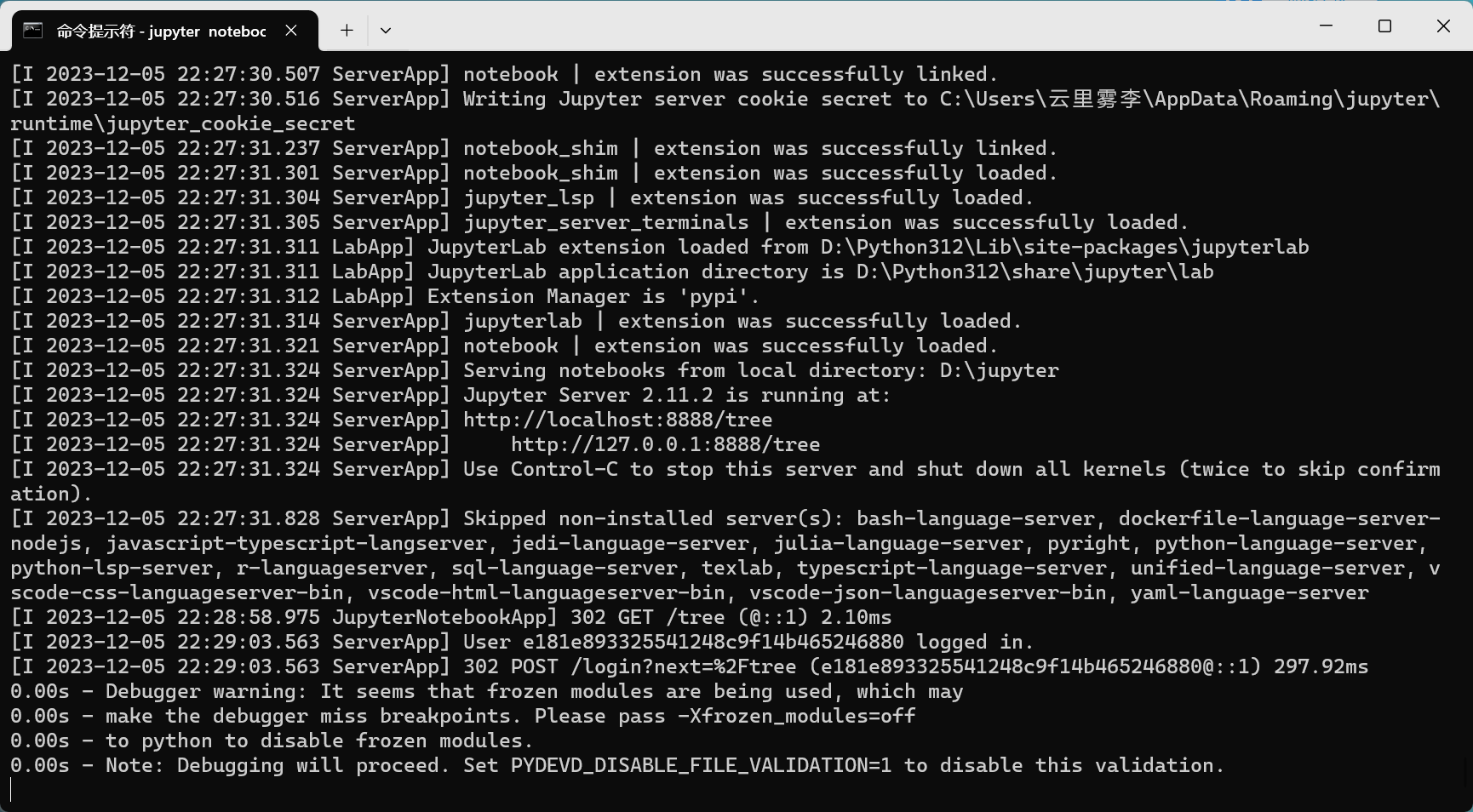
①在Doc命令窗口 輸入? jupyter notebook

②網頁中輸入下面網址http://localhost:8888/tree

③剛才打開的Doc界面千萬不要關閉(不然就默認退出了jupyter了),需要doc窗口就新開一個。
結語
??? Python網絡爬蟲的環境搭建相對簡單,但網絡爬蟲的開發涉及許多技術細節。在進行爬蟲開發時,你應當遵守目標網站的robots.txt規則,并尊重網站的版權和隱私政策。此外,合理控制爬取頻率以避免對網站服務器造成不必要的負擔。祝你在Python網絡爬蟲的世界中探索愉快!


 報錯 ValueError: Invalid format string)







----讀取融合算法輸出的四元數)

切換主題色)



案例教程)


