前言
異構編程開發,在高性能編程中有重要的,筆者本次只簡單介紹下,如何搭建簡單的開發環境,可以供有需要的小伙伴們開發測試使用
一、獲取opencl的sdk庫
1.使用cuda庫
若本機有Nvidia的顯卡,在安裝cuda庫后,可以直接在安裝目錄下找到對應庫文件
CUDA下載地址:CUDA Toolkit - Free Tools and Training | NVIDIA Developer


本地版的包比較大,網絡版的需要安裝時聯網下載
建議直接安裝最新版本,并在安裝前刪除的版本
注:需要先安裝顯卡驅動
安裝完成后,可以直接在安裝目錄下找到庫文件,以下是64位庫、32位庫、include文件



2.使用opencl-sdk預編譯庫
可以到opencl官網上,直接下載已經編譯好的預編譯庫
下載地址:Releases · KhronosGroup/OpenCL-SDK · GitHub
筆者寫文檔時,最新發布日期是2023.04.17
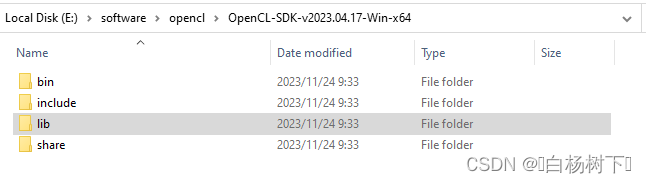
下載后,直接解壓就可以得到庫文件和include文件 ,如下圖所示
二、編寫cmake文件
set(include_paths# "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.3/include"{opencl_dir}/OpenCL-SDK-v2023.04.17-Win-x64/include)set(link_paths#"C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.3/lib/x64"{opencl_dir}/OpenCL-SDK-v2023.04.17-Win-x64/lib
)set(link_libsOpenCL.lib
)add_executable(opencltestmain.cpp
)target_include_directories(opencltest PRIVATE${include_paths}
)target_link_directories(opencltest PRIVATE${link_paths}
)target_link_libraries(opencltest${link_libs}
)
cmake文件比較簡單,就是直接引入對應opencl庫
要注意一點,CUDA的默認安裝目錄有空格,需要把整個目錄放入引號中
三、運行示例
const int N = 1024; // 矩陣大小
const size_t size = N * N * sizeof(float);
int main() {// 初始化輸入矩陣float* A = new float[N * N];float* B = new float[N * N];for (int i = 0; i < N * N; i++) {A[i] = 1.0f;B[i] = 2.0f;}// 初始化OpenCL環境cl_platform_id platform;clGetPlatformIDs(1, &platform, NULL);cl_device_id device;clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL);cl_command_queue queue = clCreateCommandQueueWithProperties(context, device, 0, NULL);// 創建OpenCL內存緩沖區cl_mem bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, NULL);cl_mem bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY, size, NULL, NULL);cl_mem bufferC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, size, NULL, NULL);// 將輸入數據傳輸到OpenCL緩沖區clEnqueueWriteBuffer(queue, bufferA, CL_TRUE, 0, size, A, 0, NULL, NULL);clEnqueueWriteBuffer(queue, bufferB, CL_TRUE, 0, size, B, 0, NULL, NULL);// 創建OpenCL程序對象const char* source = "__kernel void add_matrices(__global const float* A, __global const float* B, __global float* C) { int id = get_global_id(0); C[id] = A[id] + B[id]; }";cl_program program = clCreateProgramWithSource(context, 1, &source, NULL, NULL);clBuildProgram(program, 1, &device, NULL, NULL, NULL);cl_kernel kernel = clCreateKernel(program, "add_matrices", NULL);// 設置OpenCL內核參數clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA);clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB);clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC);// 啟動內核size_t globalWorkSize[2] = { N, N };clEnqueueNDRangeKernel(queue, kernel, 2, NULL, globalWorkSize, NULL, 0, NULL, NULL);// 讀取結果數據clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, size, A, 0, NULL, NULL);// 清理OpenCL資源clReleaseMemObject(bufferA);clReleaseMemObject(bufferB);clReleaseMemObject(bufferC);clReleaseProgram(program);clReleaseKernel(kernel);clReleaseCommandQueue(queue);clReleaseContext(context);// 打印結果std::cout << "Result: " << A[0] << std::endl;delete[] A;delete[] B;int a;std::cin >> a;return 0;
}整個程序比較簡單,若是運行正常,可以直接打印出結果
注:運行前,需要安裝好對應的顯卡驅動
后記
本文件是使用最簡單的方法搭建opencl開發環境
筆者沒有AMD顯卡的設備,所以未測試相關
若本地是使用的intel集成顯卡,使用官方的sdk,也可以找到對應的設備
android系統,筆者未來得及測試,若不想自己編譯庫,需要自己在android設備上查找下opencl庫,目錄可能是在/system/vendor/lib/libOpenCL.so。若未找到,可能不支持。若有時間,筆者需要另寫一篇文檔記錄下
由于不同廠家是獨立實現的,具體運行時,可能有些結果會有出入,需要具體測試;若不是使用官方的sdk,一個廠家的庫,可能只能檢測到自家設備。
使用廠家的庫,經常也會缺少部分封閉庫,如C++封裝庫







)

)

 擴展函數和運算符重載)

五種最新算法(SWO、COA、LSO、GRO、LO)求解無人機路徑規劃MATLAB)
)




