
深度學習自然語言處理 原創
作者: Xnhyacinth
在自然語言處理(NLP)領域,如何有效地進行無監督域自適應(Unsupervised Domain Adaptation, UDA) 一直是研究的熱點和挑戰。無監督域自適應的目標是在目標域無標簽的情況下,將源域的知識遷移到目標域,以提高模型在新領域的泛化能力。近年來,隨著大規模預訓練語言模型的出現,情境學習(In-Context Learning) 作為一種新興的學習方法,已經在各種NLP任務中取得了顯著的成果。然而,在實際應用場景中,我們經常面臨一個問題:源領域的演示數據并不總是一目了然。這就導致了需要進行跨領域的上下文學習的問題。此外,LLMs在未知和陌生領域中仍然面臨著一些挑戰,尤其是在長尾知識方面。同時在無監督域自適應任務中,如何充分利用情境學習的優勢進行知識遷移仍然是一個開放性問題。
本文旨在探討如何在無監督域自適應場景下,通過檢索增強的情境學習(Retrieval-Augmented In-Context Learning) 實現知識遷移。具體來說,作者提出了一種名為Domain Adaptive In-Context Learning (DAICL) 的框架,該框架通過檢索目標域的相似示例作為上下文,幫助模型學習目標域的分布和任務特征。全面研究了上下文學習對于領域轉移問題的有效性,并展示了與基線模型相比取得的顯著改進。
接下來就讓我們一起看看作者是如何實現檢索增強情境學習的知識遷移!

論文: Adapt in Contexts: Retrieval-Augmented Domain Adaptation via In-Context Learning
地址: https://arxiv.org/pdf/2311.11551.pdf
前言
在自然語言處理領域,大型語言模型(LLMs)通過其強大的能力在各種任務上取得了顯著的成功。然而,當面臨跨領域的情景時,LLMs仍面臨著挑戰,由于目標域標簽不可用,在實際場景中通常缺乏域內演示。從其他領域獲取帶標簽的示例可能會遭受巨大的句法和語義領域變化。此外,LLMs很容易產生不可預測的輸出, 而且LLMs在未知和陌生領域的長尾知識上仍然存在局限性。因此亟需有效的適應策略,將語言模型的知識從標記的源域轉移到未標記的目標域,稱為無監督域適應(UDA)。UDA 旨在調整模型,從標記的源樣本和未標記的目標樣本中學習與領域無關的特征。
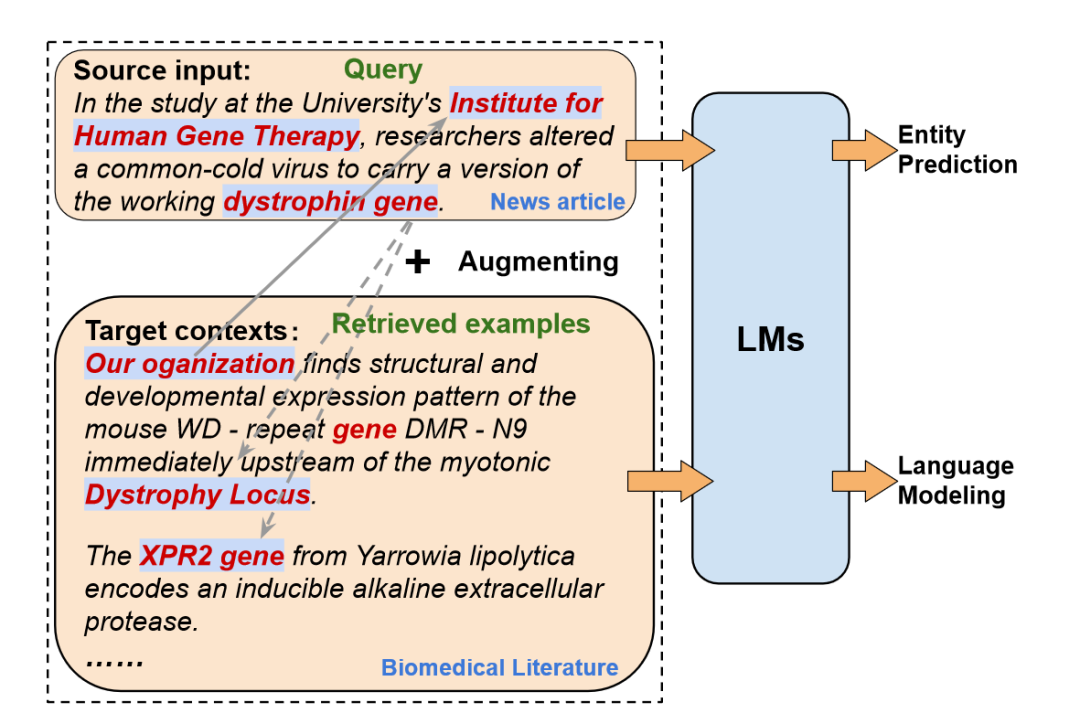
為了解決這些問題,本文提出了一種基于上下文學習的無監督領域適應(Unsupervised Domain Adaptation, UDA)方法,旨在將LLMs從源領域成功適應到目標領域,無需任何目標標簽。從目標未標記語料庫中檢索類似的示例作為源查詢的上下文,并通過連接源查詢和目標上下文作為輸入提示來執行自適應上下文學習。如上圖所示,對于來自源域的每個輸入,將其上下文與從目標未標記域檢索到的語義相似的文本組合起來,以豐富語義并減少表面形式的域差異。然后,模型將學習源輸入和目標上下文的任務區分。
方法
該研究提出了一種名為Domain Adaptive In-Context Learning (DAICL)的框架,通過檢索目標域的相似示例作為上下文,幫助模型學習目標域的分布和任務特征,使LLMs同時學習目標領域分布和判別性任務信號。具體來說,對于給定的源域數據和目標域數據,首先使用檢索模型(如SimCSE)在目標域中檢索與源域數據相似的示例。然后,將檢索到的示例作為上下文,與源域數據一起作為輸入,進行情境學習。通過這種方式,模型可以在目標域的上下文中學習任務特征,同時適應目標域的數據分布。主要分為以下幾個部分:
檢索目標域相似示例:首先,在目標域中檢索與源域數據相似的示例。這一步的目的是找到能夠代表目標域特征的示例,以便模型能夠在目標域的上下文中學習任務特征。檢索方法可以采用現有的密集檢索模型,如SimCSE。
構建上下文:將檢索到的目標域相似示例與源域數據一起作為輸入,形成上下文。這樣,模型可以在目標域的上下文中學習任務特征,同時適應目標域的數據分布。
情境學習:在構建的上下文上進行情境學習。這里采用了兩種任務損失函數:(1)上下文任務損失,用于學習任務特征,預測標簽值y;(2)上下文語言建模損失,用于學習目標域的分布。通過優化這兩個損失函數,模型可以在目標域中實現知識遷移。
模型訓練:根據所使用的模型架構(如編碼器,解碼器模型),設計相應的prompting策略和訓練策略。對于編碼器模型,可以采用提示詞(prompt)策略,將源域數據和檢索到的目標域示例拼接在一起作為輸入;對于解碼器模型,可以直接將檢索到的目標域示例作為輸入,進行自回歸學習。
模型評估:在目標域的測試數據上評估模型性能。通過比較不同方法在命名實體識別(NER)和情感分析(SA)等任務上的結果,驗證DAICL框架的有效性。
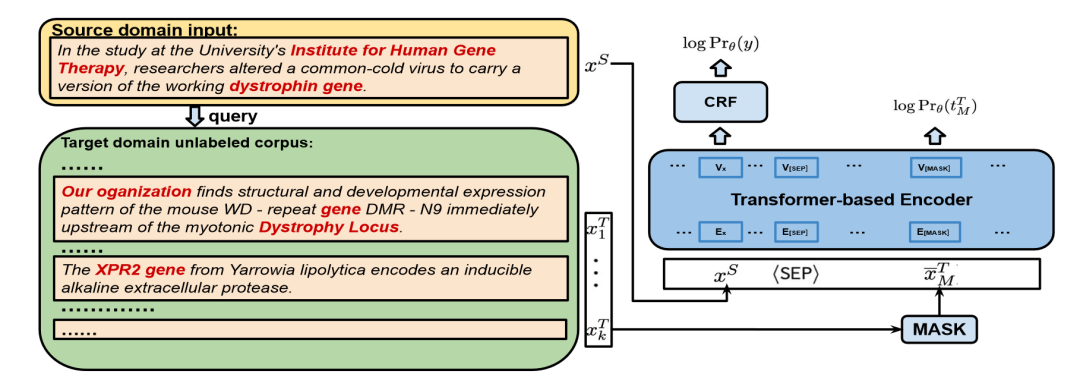
如上圖所示, 顯示了 NER 任務上僅編碼器模型的訓練過程概述,MLM 目標會鼓勵編碼器學習與源域無法區分的目標分布。對于任務學習目標,在源輸入上使用平均匯聚(average pooling) 作為情感分析任務的預測機制,而在語言模型特征之上使用附加的條件隨機場(CRF)層進行命名實體識別任務的標記級別分類。
對于僅解碼器架構,包括僅推理和微調兩種范式,下圖圖為帶有推理提示的示例,在給定目標測試查詢的情況下從源標記數據集中搜索輸入標簽對。虛線框包含從源檢索的演示。

對于微調設置下,利用lora用更少的計算資源微調更大的 LM,微調數據示例形式為,如下所示:

實驗設置
為了評估DAICL方法的有效性,該研究在命名實體識別(NER)和情感分析(SA)任務上進行了廣泛的實驗。實驗采用了多種源域和目標域的組合,涵蓋了新聞、社交媒體、金融和生物醫學等領域。CoNLL-03(英語新聞)作為源域數據集,目標域數據集包括:金融(FIN)、社交媒體(WNUT-16、WNUT-17)、生物醫學(BC2GM、BioNLP09、BC5CDR) 對于情感分析(SA)任務,使用了亞馬遜評論數據集,涵蓋了四個領域:書籍(BK)、電子產品(E)、美容(BT)和音樂(M)。
本文對比了多種基線方法,包括無監督域自適應的傳統方法(如Pseudo-labeling和對抗訓練)、基于檢索的LM方法(如REALM和RAG)和情境學習方法(如In-context learning)。在實驗中,將不同的LLMs架構與提出的In-Context Learning方法進行對比,并評估其在領域適應中的性能。對于評估指標,NER任務使用了F1分數,SA任務使用了準確率acc。
結果分析
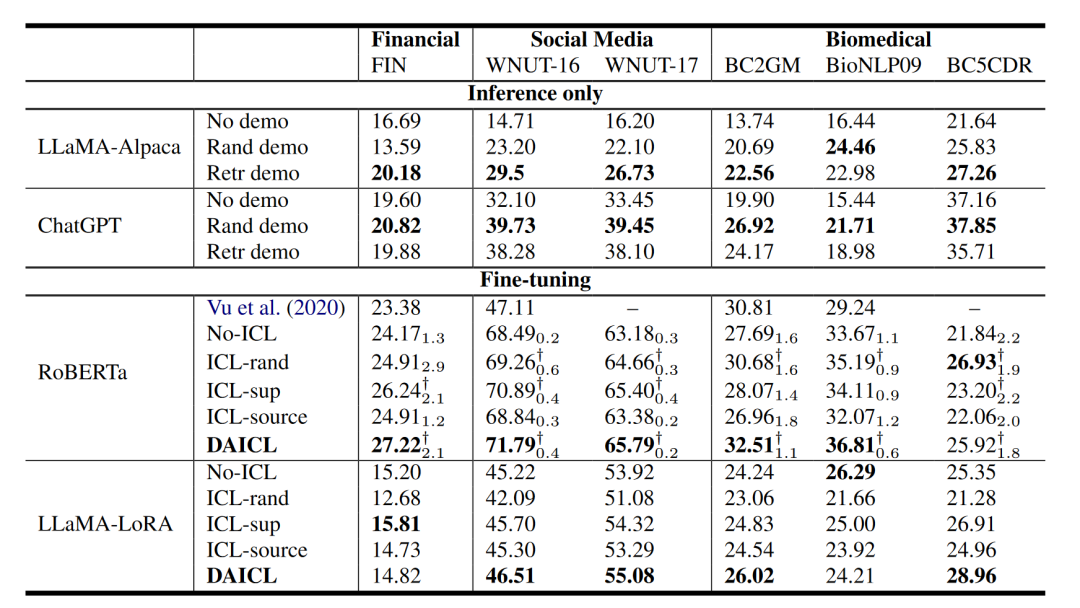
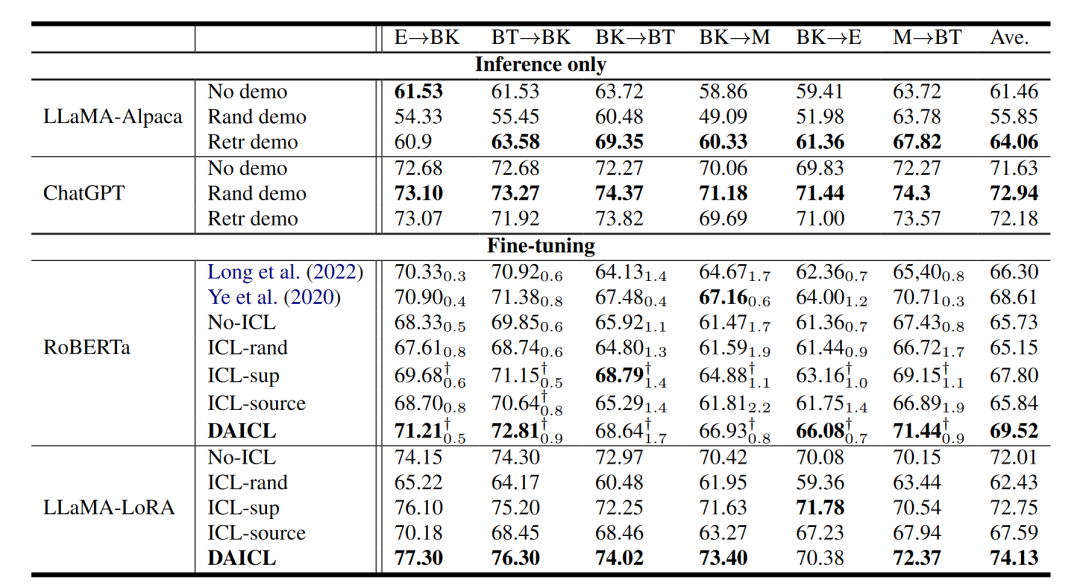
由以上兩個任務的性能對比表可知,DAICL 同時學習兩個目標,在大多數適應場景中都大大超過了基線。從 ICL-sup 的結果來看,我們發現僅使用任務目標進行訓練對 UDA 略有幫助。正如前面所討論的,好處源于利用目標上下文的任務判別能力。通過將 DAICL 與 ICL-sup 和 ICL-source 進行比較,可以發現所提出的上下文適應策略通過同時聯合學習任務信號和語言建模來增強領域適應。
微調有益于UDA,在 NER 實驗中,ChatGPT 的性能非常低,但微調更小的 RoBERTa 模型可以在大多數適應場景中實現最先進的分數。在 SA 實驗中,使用更少的可訓練參數 (1.7M) 微調 LLaMA 優于所有其他方法。因此,我們假設雖然法學碩士具有很強的泛化能力,但他們不能解決所有領域的問題。對于UDA來說,設計一個有效的適配策略還是有好處的。
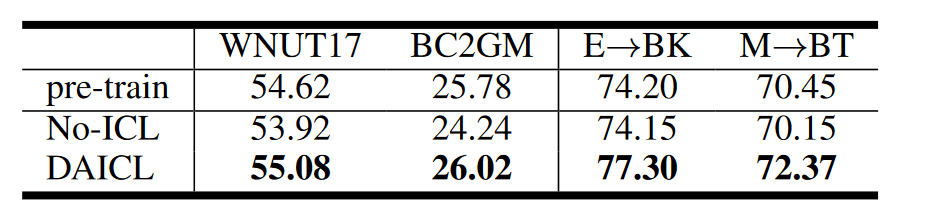
最后作者也對比了自適應ICL和自適應預訓練,自適應 ICL 在執行任務預測時將源輸入與目標上下文混合,而自適應預訓練只需要源輸入;自適應ICL同時學習兩個損失。為了比較這兩種方法,在 LLaMA-LoRA 上進行了實驗以執行自適應預訓練。在第一階段,使用目標未標記文本預訓練 LoRA 權重。第二階段,從上一階段獲得的LoRA檢查點開始,通過任務監督繼續對其進行微調。使用相同的羊Alpaca模板,但不提供說明性上下文。結果見上表,可以觀察到,與 NoICL 相比,預訓練對 SA 任務帶來的收益很小,可以推測 SA 數據集中的域差距比 NER 數據集中的域差距更小。從而得出結論所提出的自適應 ICL 策略優于自適應預訓練,這可能歸因于自適應 ICL 下的僅解碼器模型可以學習具有示范上下文的兩個目標。
總結
本文提出了一種名為Domain Adaptive In-Context Learning (DAICL)的框架,用于實現無監督域自適應(UDA)。該框架通過檢索目標域的相似示例作為上下文,結合任務損失和領域適應損失進行情境學習,以實現知識遷移。實驗采用了多個源域和目標域的數據集,包括命名實體識別(NER)和情感分析(SA)任務。與多種基線方法相比,DAICL在多種跨域場景下均取得了顯著的性能提升,證明了其有效性。
盡管本文的方法在領域自適應上取得了令人滿意的結果,但仍有一些可以進一步探索和改進的方向。首先,可以進一步研究不同的上下文學習策略,以進一步提高語言模型的領域適應能力。其次,可以考慮在不同任務和領域之間進行聯合訓練,以進一步提升模型的泛化性能。此外,還可以探索如何將上下文學習與其他領域自適應技術(如對抗訓練)相結合,以進一步改進模型的適應性和抗干擾能力;可以考慮將多個任務同時進行無監督域自適應,以提高模型的泛化能力和適應性。通過在這些方向進行探索和改進,未來研究有望進一步提高無監督域自適應方法的性能,為實際應用提供更有效的解決方案。
備注:昵稱-學校/公司-方向/會議(eg.ACL),進入技術/投稿群

id:DLNLPer,記得備注呦







)







之二)



