系列文章目錄
文章目錄
- 系列文章目錄
- 前言
- 一、數據分析框架
- 二、數據分析方法
- 1.數據清洗&數據探索
- 2.數據清洗之異常值判別
- 3.數據清洗之缺失值處理
- 4.數據探索
- 5.結構優化
- 三、大數據可視化
- 1.大數據可視化概念
- 1.1 定義
- 1.2 數據可視化的意義
- 2.可視化類型和模型
- 2.1 科學可視化
- 2.2 科學可視化的研究重點
- 2.3 體可視化
- 2.4 體可視化
- 2.5 科學可視化的組成
- 2.6 信息可視化
- 3.光與視覺特性
- 3.1 光的特性
- 3.2 三基色原理
- 3.3 黑白視覺特性
- 3.4 彩色視覺特性
- 3.5 數據可視化的基本特征
- 3.6 數據可視化模型
- 3.7 數據可視化基本圖表
- 4.視覺編碼
- 4.1 視覺感知
- 4.2 數據維度
- 4.3 可視化分析方法的常用
- 5.關鍵技術
- 5.1 定義
- 5.2 可視化關鍵技術
- 5.3 渲染技術
- 總結
前言
一、數據分析框架
業務理解->數據理解->數據準備->建立模型->模型評估
二、數據分析方法
1.數據清洗&數據探索
數據探索:
- 特征描述
- 分布推斷
- 結構優化
數據清洗:
- 異常值判別
- 缺失值處理
- 數據結構統一
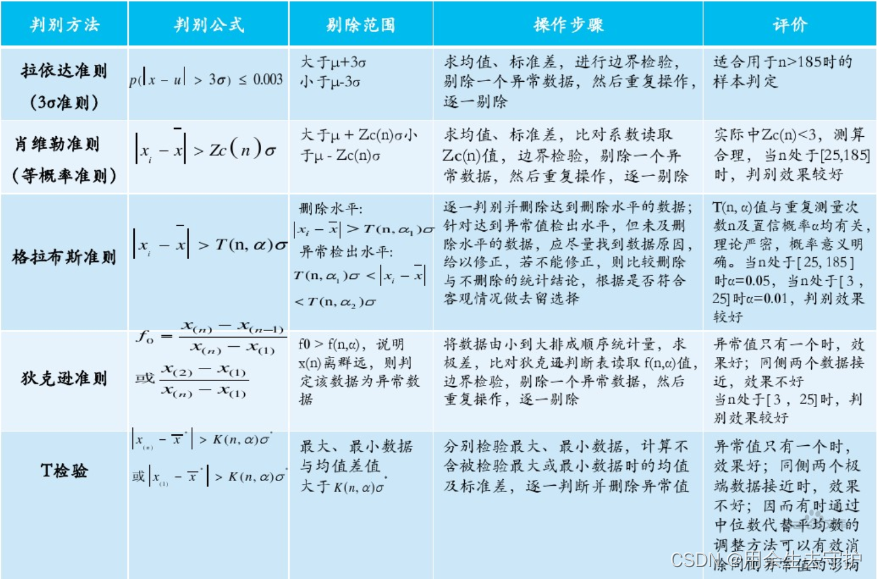
2.數據清洗之異常值判別
1、物理判別法
根據經驗客觀判別由于外界干擾、人為誤差等原因造成的數據偏離,判斷異常值
2、統計判別法
- 給定一個置信概率,并確定一個置信限,凡超過此限的誤差,就認為它不屬于隨機誤差范圍,將其視為異常值。
- 常用的方法(數據來源于同一分布,且是正態的):拉依達準則、肖維勒準則、格拉布斯準則、秋克遜準則、t檢驗。
3.數據清洗之缺失值處理
在數據缺失嚴重時,會對分析結果造成較大影響,因此對剔除的異常值以及缺失值,要采用合理的方法進行填補,常見的方法有平均值填充、K最近距離法、回歸法、極大似線估計法等
-
平均值填充
取所有對象(或與該對象具有相同決策屬性值的對象)的平均值來填充該缺失的屬性值 -
K最近距離法
先根據歇式距高或相關分析確定距高缺失數據樣本最近的K個樣本,將這K個值加權平均來估計缺失數據值 -
回歸
基于完整的數據集,走立回歸方程(模型),對于包含空值的對象,將已知屬性值代入方程來鉆計來知屬性值,以此估計值來進行填充;但當變量不是線性相關或預測變量高度相關時會導致估計偏差 -
極大似然估計
在給定完全數據和前一次選代所得到的賽;數估計的情況下計算完全數據對應的對數!似然品教的條件期望;(E步),后用極大i化對數似然通敏以確!定參數的使,并用于;下步的選代(M步) -
多重插補法
由包含m個描補值的向量代替每一個缺失位,然后對新產生的m個數據集使用相同的方法處理,得到處理結果后,綜合結果最終得到對目標變量的估計
隨著數據量的增大,異常值和缺失值對整體分析結果的影響會逐漸變小,因此在“大數據”模式下,數據清洗可忽略異常值和缺失值的影響,而側重對數據結構合理性的分析
4.數據探索
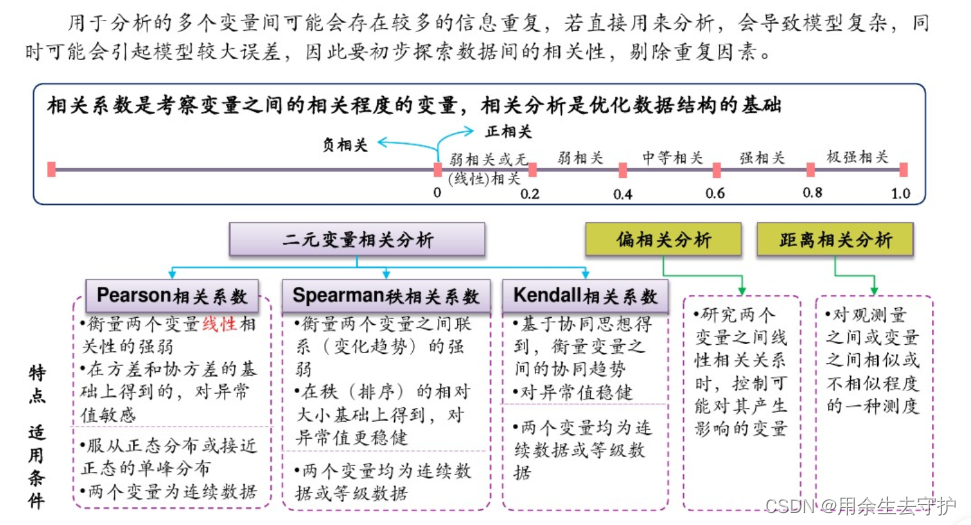
通過數據探索,初步發現數據特征、規律,為后續數據建模提供輸入依據,常見的數據探索方法有數據特征描述、相關性分析、主成分分析等。

數據特征描述:
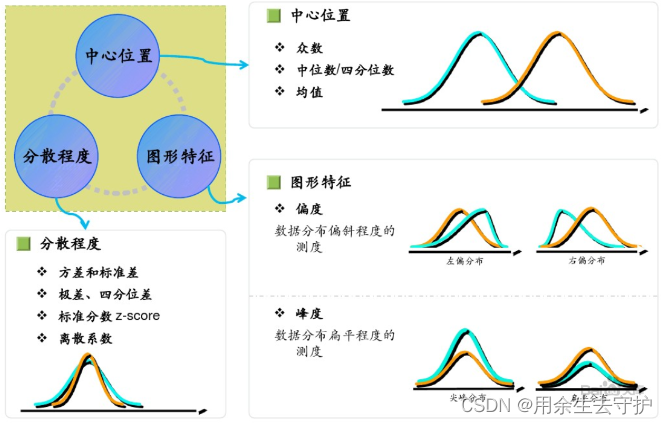
數據概率分布:
概率分布可以表述隨機變量取值的概率規律,是掌握數據變化趨勢和范圍的一個重要手段。

參數檢驗
在已知總體分布的條件下(一般要求總體服從正態分布),對一些主要的參數(均值,百分數,方差,相關系數等)進行檢驗。
例如:U檢驗、T檢驗(單樣本T檢驗,配對樣本T檢驗,兩個獨立樣本t檢驗)
| 檢驗方法名稱 | 問題類型 | 假設 | 適用條件 | 抽樣方法 |
|---|---|---|---|---|
| 單樣本T-檢驗 | 判斷一個總體平均數等于已知數 | 總體平均數等于A | 總體服從正態分布 | 從總體中抽取一個樣本 |
| F一檢驗 | 判斷兩總體方差相等 | 兩總體方差相等 | 總體服從正態分布 | 從兩個總體中各抽取一個樣本 |
| 獨立樣本T一檢驗 | 判斷兩總體平均數相等 | 兩總體平均救相等 | 總體展從正態分布,兩總體方程相等 | 從兩個總體中各物取一個樣本 |
| 配對樣本T-檢驗 | 判斷指標實驗前后平均數相等 | 指標實驗前后平均數相等 | 總體服從正態分布,兩組數據是同一實驗對象在實驗前后的測試值 | 抽取一組試驗對象,在試驗前測得試驗對象某指標的值,進行試驗后再測得試驗對象該指標的取值 |
| 二項分布假設檢驗 | 隨機抽樣實驗的成功概率的檢驗 | 總體概率等于P | 總體服從二項分布 | 從總體中抽取一個樣本 |
非參數檢驗
一般是在不知道數據分布的前提下,檢驗數據的分布情況(不考慮總體分布是否已知,常常也不是針對總體參數,而是針對總體的某些一次性假設進行檢驗)
例如:卡方檢驗,秩和檢驗,二項檢驗,游程檢驗,K-量檢驗等
| 檢驗方法名稱 | 問題類型 | 假設 |
|---|---|---|
| 卡方檢驗 | 檢測試劑觀測頻數與理論頻數之間是否存在差異 | 觀測頻數與理論頻數無差異 |
| K-S檢驗 | 檢測實際觀測頻數與理論頻數之間是否存在差異 | 服從正態分布 |
| 游程檢驗 | 檢測一組觀測值是否有明顯變化趨勢 | 無明顯變化趨勢 |
| 二項分布假設檢驗 | 通過樣本數據檢驗樣本的總體是否服從指定的概率為P的二項分布 | 服從二項分布 |
結論:
- 參數檢驗是針對參數做的假設,非參數檢驗是針對總體分布情況做的假設。
- 二者的根本區別在于參數檢驗要利用到總體的信息,以總體分布和樣本信息對總體參數作出推斷;非參數檢驗不需要利用總體的信息。
5.結構優化
三、大數據可視化
1.大數據可視化概念
1.1 定義
數據:聚焦于數據的采集、清理、預處理、分析、挖掘
圖形:聚焦于解決對光學圖像進行接收,提取信息、加工變換模式識別及存儲顯示
可視化:聚焦于解決將數據轉換成圖形,并進行交互處理
數據空間:是由n維屬性和m個元素組成的數據集所構成的多維信息空間
數據開發:是指利用一定的算法和工具對數據進行定量的推演和計算
數據分析:指對多維數據進行切片、塊、旋轉等動作剖析數據,從而能多角度側面觀察數據
數據可視化:是指將大型數據集中的數據以圖形形式表示,并利用數據分析和開發工具發現其中未知信息的處理過程
數據可視化根據可視化原理不同可劃分為幾何技術、面向像素技術、基于圖標的技術、基于層次的技術、基于圖像的技術、和分布式技術等
1.2 數據可視化的意義
- 視覺是人類獲得信息的最主要途徑
- 能幫助我們提高理解和處理數據的效率
- 可以在小空間中展示大規模數據
- 在工業4.0、智能交通、人工智能、其它
2.可視化類型和模型
2.1 科學可視化
科學可視化最初稱為“科學計算中的可視化”,(Visualzation In Scientific Computing,VISC),運用計算機圖形學和圖像處理的研究成果創建視覺圖像,替代數字;
2.2 科學可視化的研究重點
- 判斷可視化對象的類別,進行可視化表現
- 將研究對象以最接近真實的效果繪制,用視覺、觸覺等交互方式理解和研究
2.3 體可視化
體可視化研究對象主要是體數據,即三維數據,其繪制技術包括等值面的抽取技術,直接體繪制
流場可視化,運用計算機圖形學和圖像學技術,將流場數據轉換為二維或三維–計算流體力學的手段
大規模數據可視化-高效快捷
2.4 體可視化
- 顏色映射方法
- 等值線方法-等值線的疏密程度判斷現象的數量變化趨勢
- 立體圖法和層次分割法
- 矢量數據場和直接法和流線法-通過記錄坐標的方式盡可能將地理實體的空間位置表現出來
2.5 科學可視化的組成
可視化流水線模型
模擬->預處理->映射->繪制->解釋
2.6 信息可視化
信息可視化是1989年斯圖爾特卡德、約克·麥金利和喬治·羅伯遜提出的,利用計算機將非空間數據的信息對象的特征值抽取、轉換、映射、高度抽象與整合,用圖形、圖像、動畫等方式表示信息對象內容特征和語義的過程;
3.光與視覺特性
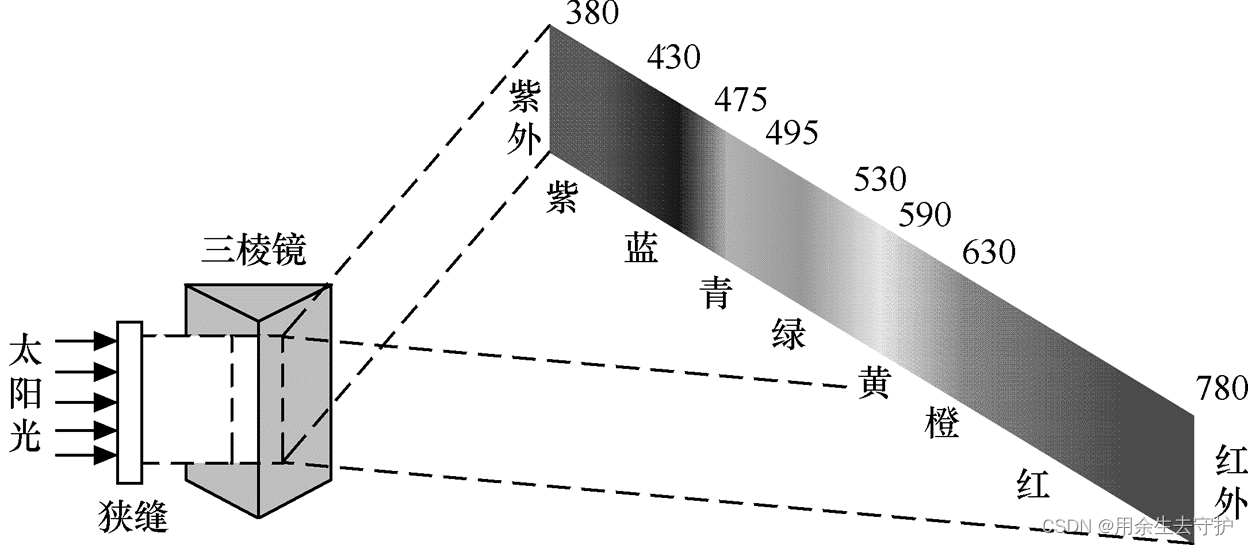
3.1 光的特性
可見光的波長由780nm到380nm變化時,人眼的感覺依次是紅橙黃綠青藍紫;
3.2 三基色原理
三基色原理是根據色度學中著名的格拉茲曼法則和配色實驗總結出來的。
自然界中幾乎所有的彩色都由3種線性無關的色光按一定比例混配得到,合成的彩色亮度由3種色光的亮度之和決定,色度由3種色光所占的比例決定;
線性無關是指3種色光必須相互獨立,其中任何一種色光都不能由其他兩種色光混配得到;
- 人的視覺只能分辨顏色的三種變化,即亮度、色調和色飽和度;
- 任何彩色均可以由3中線性無關的彩色混合得到,稱為三基色;
- 合成彩色光的亮度等于三基色分量亮度之和,即符合亮度相加定律;
- 光譜組成成分不同的光在視覺上可能具有相同的顏色外貌,即相同的彩色感覺;
- 在由兩個成分組成的混合色中,如果一個成分連續變化,混合色也連續變化;
補色律:每種顏色都有一個相應的補色;
中間色律:任何兩個非補色的色光相混合,可產生出它們兩個色調之間的新的中間色調;
3.3 黑白視覺特性
- 視敏特性:指人眼對不同波長和光具有不同的靈敏度,即輻射功率相同的各色光具有不同的亮度感覺。在相同的輻射功率條件下,人眼感到最亮的是黃綠光,最暗的是紅光和紫光;

- 亮度感覺:亮度感覺不僅僅取決于景物給出的亮度值,還與周圍的平均亮度有關,是一個主觀量;
- 人眼感光適應性:適應性是指隨著外界光的強弱變化,人眼能自動調節感光靈敏度的特性;
- 亮度視覺范圍:與環境亮度有關
- 亮度可見度閾值:人眼對亮度變化的分辨力是有限的,人眼無法區分非常微弱的亮度變化。通常用亮度極差來表示人眼剛剛能感覺到的兩者的差異
- 人眼視覺的掩蓋效應:如果是在空間和時間上不均勻的背景中,測量可見度閾值,可見度閾值就會增大,即人員會喪失分辨一些亮度的能力;
- 對比度:把景物或重現圖像最大亮度和最小亮度的比值稱為對比度;
- 亮度層次:畫面最大亮度與最小亮度之間可分辨的亮度極差數稱為亮度層次或灰度層次;
- 視覺惰性:人眼的視覺有惰性,這種惰性現象稱為視覺殘留;
- 閃爍:觀察者觀察按時間重復的亮度脈沖,當脈沖重復頻率不夠高時,人眼就有一亮一暗的感覺
- 視角:觀看景物時,景物大小對眼睛形成的張角
- 分辨力:當與人眼相隔一定距離的兩個黑點靠近到一定程度時,人眼就分辨不出有兩個黑點的存在,而只感覺到是連在一起的一個點,這種現象表明人眼分辨景物細節的能力是有一定極限的;
3.4 彩色視覺特性
- 辨色能力:亮度、色調和飽和度稱為彩色的三要素。人眼對不同波長的譜色光有不同的色調感覺。人眼的彩色視覺的辨色能力共有3000-4000種。人眼對彩色感覺具有非單一性。顏色感覺相同,光譜組成可以不同;
- 彩色細節分辨力:畫面最大亮度和最小亮度之間可以分辨的亮度極差數稱為亮度層次或灰度層次。人眼對彩色細節的分辨力對比黑白細節的分辨力要低。只有對黑白細節分辨力的1/3~1/5
- 混色特性:包括時間混色,空間混色和雙眼混色等
3.5 數據可視化的基本特征
- 易懂性
- 必然性
- 多維性
- 片面性
- 專業性
3.6 數據可視化模型
可視化流水線
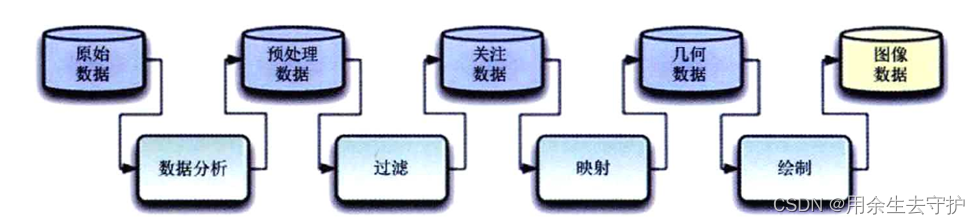
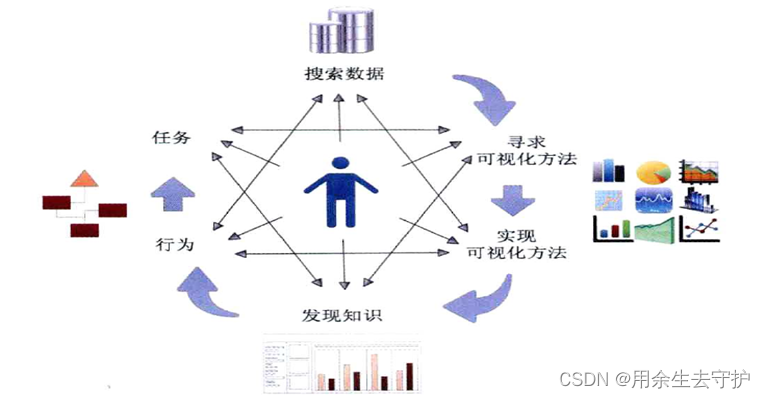
循環模型
3.7 數據可視化基本圖表
- 原始數據繪圖用于可視化原始數據的屬性值,直觀呈現數據特征,其代表性方法包括:數據軌跡、柱狀圖、折線圖、直方圖、餅圖、等值線圖、散點圖、氣泡圖、維恩圖、熱力圖和雷達圖等;
- 簡單統計值標繪:盒須圖
- 多視圖協調關聯
4.視覺編碼
4.1 視覺感知
視覺感知是指客觀事物通過人的視覺器官在人腦中形成的直接反映;
視覺通道:用于控制幾何標記的展示特性,包括標記的位置、大小、形狀、方向、色調、飽和度、亮度等
4.2 數據維度
基于任務分類的數據類型(TTT,data Type by Task Taxonomy)。
七類:一維線性數據、二維數據、三維數據、多維數據、時態數據、樹形數據和網狀數據;
4.3 可視化分析方法的常用
- 主成分分析(Principal Component Analysis ,PCA)是一種利用線性映射來進行數據降維的方法,同時去除數據相關性,以最大限度保持原始數據的方差信息,從而進行有效的特征提取;
- 聚類分析:
系統聚類分析:將變量由多變少的一種方法,先將距離最小的變量歸為一類,再將其合并,合并后將新類計算相互間的距離,再將距離最小的新類合并,直到所有的變量歸為一類為止。距離的定義有最短距離法、最長距離法、中心法、類平均法、中間距離法、離差平和法;
動態聚類法:動態聚類先設定好數值K,然后將所有樣本分成K類作為聚核,再計算每個樣本到聚核的距離,與聚核距離最小的樣本歸為一類,這樣樣本被分為K類;
5.關鍵技術
5.1 定義
- 數據空間:是由n維屬性和m個元素組成的數據集所構成的多維信息空間;
- 數據開發:是指利用一定的算法和工具對數據進行定量的推演和計算;
- 數據分析:是指對多維數據進行切片、塊、旋轉等動作剖析數據,從而多角度觀察;
- 數據可視化:利用數據分析和開發工具發現其中未知信息的處理過程;
5.2 可視化關鍵技術
- 數據信息的符號表達技術
- 數據表達模型技術
- 數據交互技術
- 數據渲染技術
- 可視化設計與開發模型
5.3 渲染技術
渲染的功能是把三維坐標系中的場景顯示出來。在計算機中,三維世界是由坐標系和坐標系的點構成的,還包括物體的材質、紋理、光照等信息。渲染是完成從數據到顯示的過程,主要存在三種渲染技術:深度緩存技術、光線跟蹤技術和輻射度技術。
1、基于CPU渲染
- 早期的渲染都是基于CPU來完成,但由于當時圖形化技術沒有達到真實感繪制的效果,所以依靠單線程CPU運行計算的速度也是能達到要求;
- 現在的渲染方式多采用多核CPU和GPU結合的方式,多核CPU對渲染速度的提升影響極大。幾乎所有的CPU渲染軟件都能對CPU的多線程實現良好的支持,也就是說,核心線程數量越多,渲染的效率越高;
2、基于GPU的渲染
- GPU是能夠從硬件上支持多邊形轉換與光源處理的顯示芯片,其作用是計算多邊形的3D位置和處理動態光線效果,也可以稱為"幾何處理"
3、集群渲染技術
集群渲染是指一組計算機通過通信協議連接在一起的計算機群,能夠將工作負載從一個超載的計算機遷移到集群中。目標是使用主流的硬件設備組成網格計算能力,達到超級計算機的性能。典型的超級計算機廠商有IBM、SGI、以及一些科研組織。
集群計算機通常分為SMP和MPP兩種
- SMP(symmetric multiprocessing,對稱處理),計算機的I/O總線,多處理器,內存等所有的控制都運行在一個操作系統中(Unix、Linux)
- MPP(massively parallel processing,大規模并行處理):每個處理器都有屬于自己的操作系統,通過通信協議連接,可以同時處理同一程序的不同部分。
集群渲染技術優點:
- 多顆多核處理器的密集式服務器渲染節點將計算能力發揮極致
- 滿足高速帶寬的任務分發管理中心
- 支持多應用,需要復雜運算的場景統一部署
- 兼容多操作系統,多軟件
- 實時監控渲染動態,隨時調整任務
- 數據共享,易操作,易管理
- 穩定性,安全的數據與足夠的網絡帶寬環境
- 單機具備升級空間,系統具備擴容性
4、云渲染:由客戶端處理的圖形渲染轉移至服務器端;
總結
分享:
石上偈
無材可去補蒼天,枉入紅塵若許年;
此系身前身后事,倩誰記去做奇傳?




之二)











)


