前言:在大數據處理領域,兩種突出的數據架構已成為處理大量數據的流行選擇:Lambda 架構和 Kappa 架構。這些架構為實時處理和批處理提供了強大的技術解決方案,使組織能夠從其數據中獲得有價值的見解。隨著互聯網時代來臨,數據量暴增,開始使用大數據工具來替代經典數倉中的傳統工具。此時僅僅是工具的取代,架構上并沒有根本的區別,可以把這個架構叫做離線大數據架構。后來隨著業務實時性要求的不斷提高,人們開始在離線大數據架構?基礎上加了一個加速層,使用流處理技術直接完成那些實時性要求較高的指標計算,這便是 Lambda 架構。再后來,實時的業務越來越多,事件化的數據源也越來越多,實時處理從次要部分變成了主要部分,架構也做了相應調整,出現了以實時事件處理為核心的 Kappa 架構。
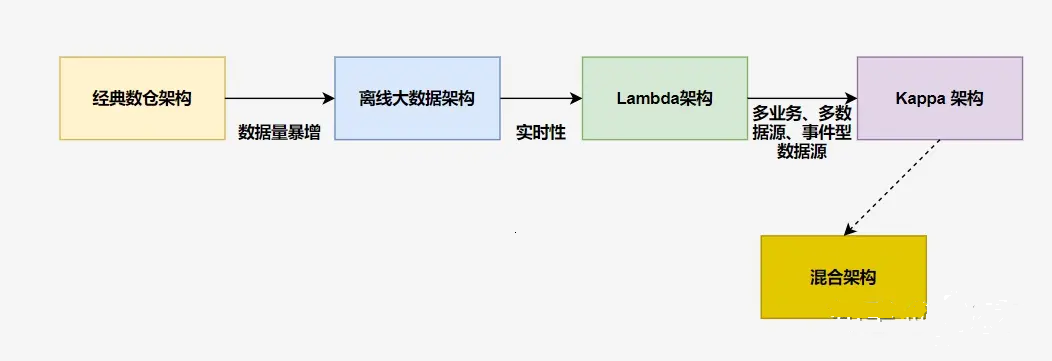
1 、Lambda 架構(融合批處理和實時處理)
Lambda 架構解決了將實時處理和批處理相結合以有效處理大數據工作負載的挑戰。它采用混合方法,利用批處理和流處理來提供準確和最新的見解。Lambda 架構的核心是不可變數據的概念。所有傳入的數據都以僅追加的方式捕獲和存儲,從而創建未更改的歷史記錄。
隨著大數據應用的發展,人們逐漸對系統的實時性提出了要求,為了計算一些實時指標,就在原來離線數倉的基礎上增加了一個實時計算的鏈路,并對數據源做流式改造(即把數據發送到消息隊列),實時計算去訂閱消息隊列,直接完成指標增量的計算,推送到下游的數據服務中去,由數據服務層完成離線&實時結果的合并。
Lambda 架構(Lambda Architecture)是由 Twitter 工程師南森·馬茨(Nathan Marz)提出的大數據處理架構。這一架構的提出基于馬茨在 BackType 和 Twitter 上的分布式數據處理系統的經驗。
Lambda 架構使開發人員能夠構建大規模分布式數據處理系統。它具有很好的靈活性和可擴展性,也對硬件故障和人為失誤有很好的容錯性。
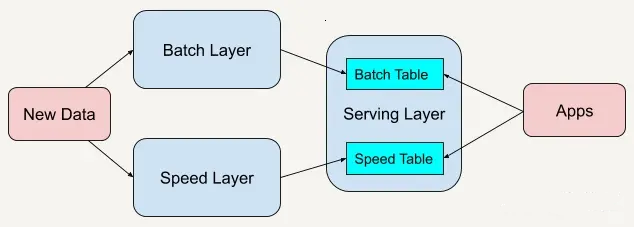
Lambda 架構總共由三層系統組成:批處理層(Batch Layer),速度處理層(Speed Layer),以及用于響應查詢的服務層(Serving Layer)。
-
批處理層?:在批處理層中,以面向批處理的方式處理大量歷史數據。數據從數據源引入、轉換并存儲在批處理系統(如 Apache Hadoop 或 Apache Spark)中。然后,轉換后的數據將存儲在批處理服務層中,在該圖層中對其進行索引并使其可查詢。
-
速度處理層?:速度層處理實時數據處理。它近乎實時地處理傳入的數據流并生成增量更新。然后將這些更新與批處理圖層的結果合并,以提供統一的數據視圖。速度層通常利用流處理框架,如Apache Storm或Apache Flink。速度層?通過提供最新數據的實時視圖來最小化延遲。速度層所生成的數據視圖可能不如批處理層最終生成的視圖那樣準確或完整,但它們幾乎在收到數據后立即可用。而當同樣的數據在批處理層處理完成后,在速度層的數據就可以被替代掉了。
-
服務層:服務層用作查詢和可視化數據的訪問點。它結合了批處理層和速度層的結果,并提供一致的數據視圖。像Apache HBase或Apache Cassandra這樣的技術通常用于存儲和提供該層中的數據。服務層:服務層用作查詢和可視化數據的訪問點。它結合了批處理層和速度層的結果,并提供一致的數據視圖。像Apache HBase或Apache Cassandra這樣的技術通常用于存儲和提供該層中的數據。
Lambda 架構優點:
它通過跨多個層使用復制的數據來提供容錯能力,從而確保數據可用性和彈性。該體系結構還支持可擴展的處理,因為每一層都可以獨立擴展以處理不斷增加的工作負載。此外,批處理和實時處理的分離允許有效的資源利用,因為批處理計算可以在更大的時間窗口上執行。
Lambda 架構缺點:
雖然 Lambda 架構使用起來十分靈活,并且可以適用于很多的應用場景,但在實際應用的時候,Lambda 架構也存在著一些不足,主要表現在它的維護很復雜。
(1)同樣的需求需要開發兩套一樣的代碼:這是 Lambda 架構最大的問題,兩套代碼不僅僅意味著開發困難(同樣的需求,一個在批處理引擎上實現,一個在流處理引擎上實現,還要分別構造數據測試保證兩者結果一致),后期維護更加困難,比如需求變更后需要分別更改兩套代碼,獨立測試結果,且兩個作業需要同步上線。
(2)資源占用增多:同樣的邏輯計算兩次,整體資源占用會增多(多出實時計算這部分)
2 、Kappa 架構(簡化實時處理)
Kappa 架構通過專注于流處理,提供了 Lambda 架構的簡化替代方案。它包含不可變數據流的概念,無需維護單獨的批處理層。Kappa流行的主要原因在于Kafka和Flink的興起。Kafka不僅起到消息隊列的作用,也可以保存更長時間的歷史數據,以替代Lambda架構中批處理層數據倉庫部分。
Lambda 架構雖然滿足了實時的需求,但帶來了更多的開發與運維工作,其架構背景是流處理引擎還不完善,流處理的結果只作為臨時的、近似的值提供參考。后來隨著 Flink 等流處理引擎的出現,流處理技術很成熟了,這時為了解決兩套代碼的問題,LickedIn 的 Jay Kreps 提出了 Kappa 架構。Kappa 架構可以認為是 Lambda 架構的簡化版(只要移除 lambda 架構中的批處理部分即可)。在 Kappa 架構中,需求修改或歷史數據重新處理都通過上游重放完成。Kappa 架構最大的問題是流式重新處理歷史的吞吐能力會低于批處理,但這個可以通過增加計算資源來彌補。
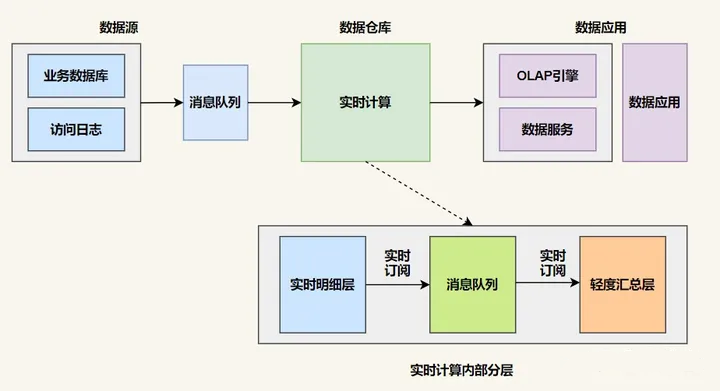
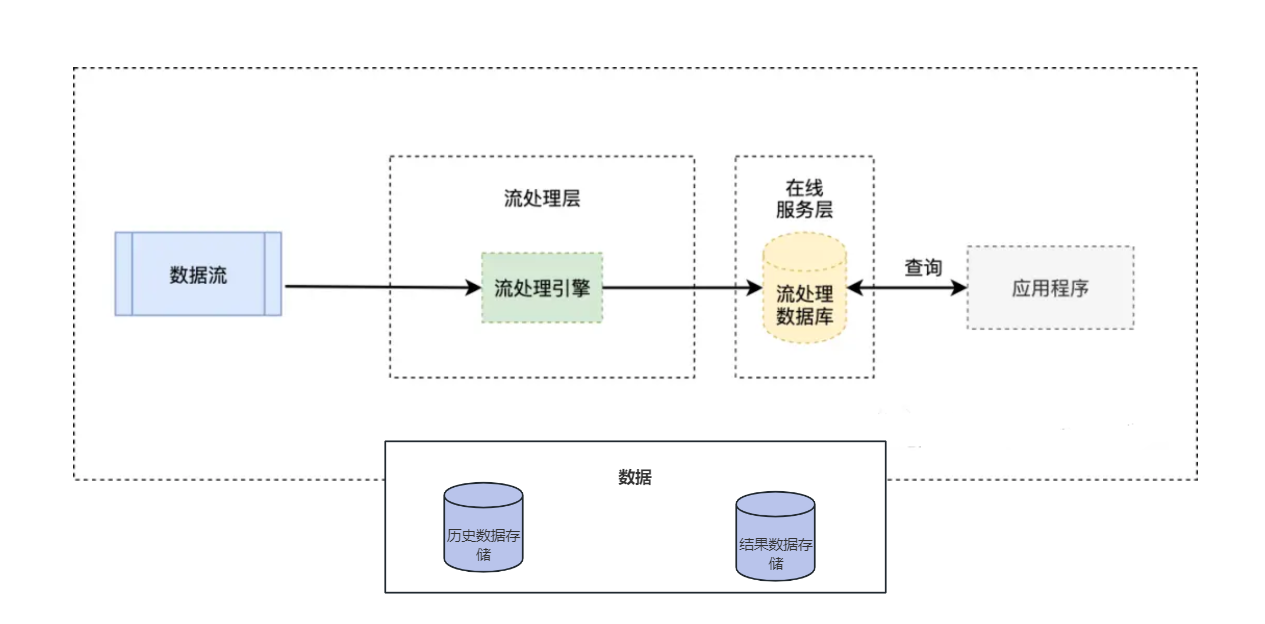
在 Kappa 架構中,所有數據都作為無限的事件流引入和處理。數據流經系統并進行實時處理,從而實現近乎即時的洞察力。Kappa 架構的核心組件包括:
-
流引入:從各種源連續引入數據并存儲在事件日志中,例如 Apache Kafka。事件日志充當持久、容錯的存儲機制,可保留事件的完整歷史記錄。
-
流處理:流處理層使用事件日志中的數據,應用實時計算,并生成所需的輸出。像Apache Kafka Streams或Apache Flink這樣的技術可用于處理和分析。
-
輸出服務:處理后的數據可通過各種輸出通道訪問,例如實時儀表板、API 或數據接收器,以供進一步分析或使用。
Kappa架構有幾個優點。通過專注于流處理,它簡化了整體系統設計并降低了操作復雜性。該架構提供低延遲處理,因為數據近乎實時地處理,無需批量計算。它還在數據一致性方面提供了簡單性,因為不需要同步和合并來自不同層的數據。
但是,在采用 Kappa 架構時需要牢記一些注意事項。由于所有數據都是實時處理的,因此如果沒有額外的組件或流程,就沒有對批處理或歷史分析的固有支持。在處理某些需要分析大型歷史數據集的用例時,此限制可能會帶來挑戰。此外,對連續流處理的依賴引入了對流處理框架的性能和可伸縮性的依賴。
Kappa 架構的重新處理過程:
重新處理是人們對 Kappa 架構最擔心的點,但實際上并不復雜:
(1)選擇一個具有重放功能的、能夠保存歷史數據并支持多消費者的消息隊列,根據需求設置歷史數據保存的時長,比如 Kafka,可以保存全部歷史數據。
(2)當某個或某些指標有重新處理的需求時,按照新邏輯寫一個新作業,然后從上游消息隊列的最開始重新消費,把結果寫到一個新的下游表中。
(3)當新作業趕上進度后,應用切換數據源,讀取 2 中產生的新結果表。
(4)停止老的作業,刪除老的結果表。
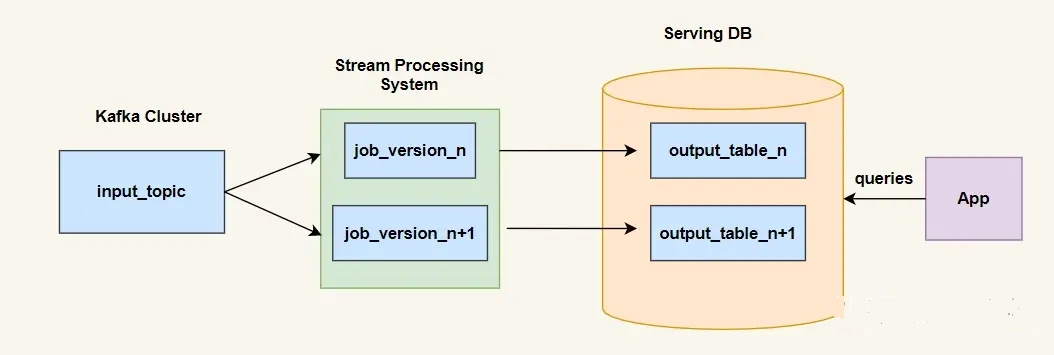
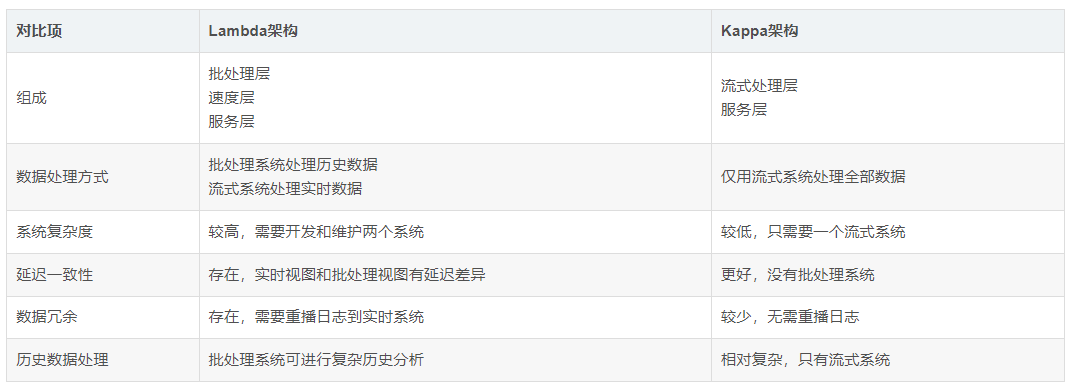
3、Lambda 架構與 Kappa 架構的對比
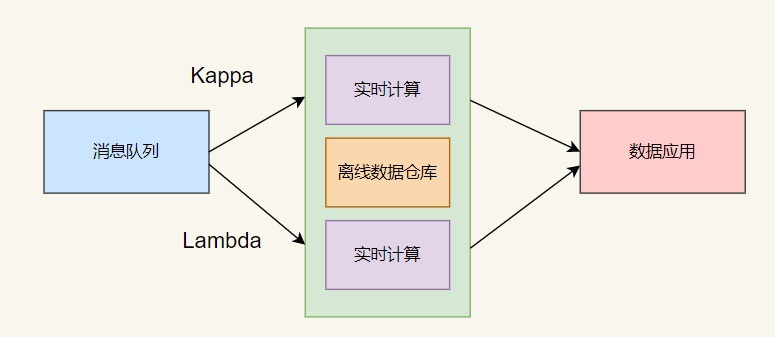
(1)在真實的場景中,很多時候并不是完全規范的?Lambda?架構或?Kappa?架構,可以是兩者的混合,比如大部分實時指標使用?Kappa?架構完成計算,少量關鍵指標(比如金額相關)使用?Lambda?架構用批處理重新計算,增加一次校對過程。
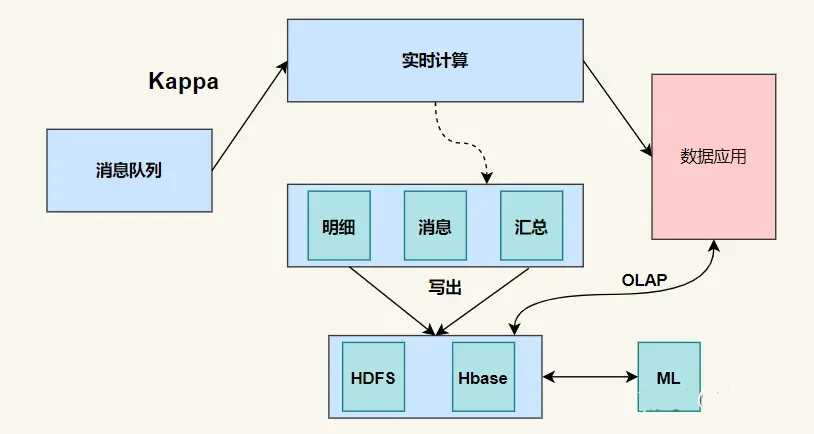
(2)Kappa?架構并不是中間結果完全不落地,現在很多大數據系統都需要支持機器學習(離線訓練),所以實時中間結果需要落地對應的存儲引擎供機器學習使用,另外有時候還需要對明細數據查詢,這種場景也需要把實時明細層寫出到對應的引擎中。
總結:
Lambda架構通過批處理層和速度層的組合,兼顧了低延遲和復雜分析,但系統較復雜,存在數據冗余和延遲不一致問題。
Kappa架構只通過流式系統實現所有處理,簡化了架構,但歷史數據分析相對復雜,需要流式系統保證精確一次語義。
兩者都有各自的優缺點,需要根據具體場景進行技術選型和設計權衡。
4、Lambda 架構與 Kappa 架構的技術選型
在 Lambda 和 Kappa 架構之間做出決定時,應考慮以下幾個因素:
-
數據特征:考慮數據的性質和處理要求。如果應用案例需要實時和歷史分析,則 Lambda 架構可能更適合。另一方面,如果主要關注實時處理和低延遲見解,那么 Kappa 架構可能更合適。
-
系統復雜性:評估與在 Lambda 架構中管理多個處理管道相關的復雜性與 Kappa 架構中單個流處理管道的簡單性。考慮組織的資源、專業知識以及實施和維護所需的工作量級別。
-
可伸縮性和性能:評估系統的可伸縮性要求。這兩種體系結構都可以水平擴展,但特定的技術選擇和實現細節可能會影響性能。考慮希望處理的數據量、速度和種類,并選擇能夠滿足可擴展性需求的體系結構。
-
數據一致性:檢查應用程序的一致性要求。Lambda 架構提供了用于處理批處理層和速度層之間數據一致性的內置機制。在 Kappa 架構中,由于沒有批處理層,因此簡化了數據一致性,但在處理無序事件或延遲到達時可能需要額外的考慮因素。
-
操作注意事項:評估每個體系結構的操作方面,例如部署、監視和容錯。考慮所選體系結構的工具、庫和社區支持的可用性。
總之,Lambda 和 Kappa 架構都為處理大數據工作負載提供了強大的解決方案。Lambda 架構結合了批處理和實時處理的優勢,提供了一段時間內數據的全面視圖。另一方面,Kappa 架構通過專注于實時處理來簡化系統設計,提供低延遲的洞察力。通過仔細考慮數據和應用程序的特定要求和特征,可以選擇最適合您的需求的體系結構,并使組織能夠從大數據中獲得有意義的見解。
??參考鏈接:
一文讀懂Kappa和Lambda架構-36氪
實時數倉之 Kappa 架構與 Lambda 架構(建議收藏!) - 知乎
Lambda 架構 vs Kappa 架構-CSDN博客

、redis主從復制)

















