目錄
為什么要訓練自己的模型
SD模型微調方法
準備素材
1 確定要訓練的LoRA類型
2 圖片收集
3 圖片預處理
4 圖片標注
安裝Koyha_ss
訓練lora
1.準備參數和環境
2.啟動訓練
使用模型
1 拷貝訓練過的lora模型
2 啟動SD WebUI進行圖像生成
為什么要訓練自己的模型
訓練自己的模型可以在現有模型的基礎上,讓AI懂得如何更精確生成/生成特定的風格、概念、角色、姿勢、對象。
比如,你下載了一個人物的大模型checkpoint,但是你想生成特點的人物,比如迪麗熱巴,AI大模型是不知道迪麗熱巴長什么樣子的,這個使用lora就派上用場了。
要注意的是,對于一些基礎東西,比如長頭發、短頭發、黑色頭發、棕色頭發,這些AI 都是知道的,lora并不是做這個的。
SD模型微調方法
主要有 4 種方式:Dreambooth, LoRA(Low-Rank Adaptation of Large Language Models), Textual Inversion, Hypernetworks。它們的區別大致如下:
- Textual Inversion?(也稱為 Embedding),它實際上并沒有修改原始的 Diffusion 模型, 而是通過深度學習找到了和你想要的形象一致的角色形象特征參數,通過這個小模型保存下來。這意味著,如果原模型里面這方面的訓練缺失的,其實你很難通過嵌入讓它“學會”,它并不能教會 Diffusion 模型渲染其沒有見過的圖像內容。
- Dreambooth?是對整個神經網絡所有層權重進行調整,會將輸入的圖像訓練進 Stable Diffusion 模型,它的本質是先復制了源模型,在源模型的基礎上做了微調(fine tunning)并獨立形成了一個新模型,在它的基本上可以做任何事情。缺點是,訓練它需要大量 VRAM, 目前經過調優后可以在 16GB 顯存下完成訓練。
- LoRA?也是使用少量圖片,但是它是訓練單獨的特定網絡層的權重,是向原有的模型中插入新的網絡層,這樣就避免了去修改原有的模型參數,從而避免將整個模型進行拷貝的情況,同時其也優化了插入層的參數量,最終實現了一種很輕量化的模型調校方法, LoRA 生成的模型較小,訓練速度快, 推理時需要 LoRA 模型+基礎模型,LoRA 模型會替換基礎模型的特定網絡層,所以它的效果會依賴基礎模型。
- Hypernetworks?的訓練原理與 LoRA 差不多,目前其并沒有官方的文檔說明,與 LoRA 不同的是,Hypernetwork 是一個單獨的神經網絡模型,該模型用于輸出可以插入到原始 Diffusion 模型的中間層。 因此通過訓練,我們將得到一個新的神經網絡模型,該模型能夠向原始 Diffusion 模型中插入合適的中間層及對應的參數,從而使輸出圖像與輸入指令之間產生關聯關系。
總兒言之,就訓練時間與實用度而言,目前訓練LoRA性價比更高,也是當前主流的訓練方法。
準備素材
1 確定要訓練的LoRA類型
首先需要確定訓練什么類型的Lora,類型可以有風格,概念,角色,姿勢,對象等。本文以人物風格為例,講解如何訓練人物風格的LoRA模型。
2 圖片收集
對于訓練人物風格的LoRA,圖片收集的標準大致為:
- 數量幾十張即可
- 分辨率適中,勿收集極小圖像
- 數據集需要統一的主題和風格的內容,圖片不宜有復雜背景以及其他無關人物
- 圖像人物盡量多角度,多表情,多姿勢
- 凸顯面部的圖像數量比例稍微大點,全身照的圖片數量比例稍微小點
(補充)圖片收集的渠道:
一般情況下,首先會想到去Google的圖片中進行搜索,但有時候搜索到的圖片分辨率較小,且質量也不是很高。這里Post其他博主推薦的一些圖片的網站,僅供參考:
- 堆糖:https://www.duitang.com
- 花瓣:https://huaban.com
- pinterest:https://www.pinterest.com
優質訓練集定義如下
- 至少15張圖片,每張圖片的訓練步數不少于100
- 照片人像要求多角度,特別是臉部特寫(盡量高分辨率),多角度,多表情,不同燈光效果,不同姿勢等
- 圖片構圖盡量簡單,避免復雜的其他因素干擾
- 可以單張臉部特寫+單張服裝按比例組成的一組照片
- 減少重復或高度相似的圖片,避免造成過擬合
- 建議多個角度、表情,以臉為主,全身的圖幾張就好,這樣訓練效果最好
3 圖片預處理
這里主要介紹對于圖像分辨率方面的預處理。有些人也說,不用裁剪了,讓AI自己去適配。
收集的圖片在分辨率方面盡量大一些,但也不要太大。如果收集到的圖片過小,可以使用超分辨率重建的方式將圖片的方式擴大;然后將所有圖片都裁剪成512x512像素大小(雖然SD2.x支持了768x768的輸入,但考慮到顯存限制,這里選擇裁剪到512x512)。
對于超分辨率重建,可以使用SD WebUI中Extra頁面中進行分辨率放大。詳情請參考:https://ivonblog.com/posts/stable-diffusion-webui-manuals/zh-cn/features/upscalers/
對于裁剪到固定尺寸,現提供如下的裁剪方法:
- birme站點批量裁剪后批量下載,優勢是可以自定義選取
- 使用SD WebUI自動裁切,或是手動裁切。詳情請參考:https://ivonblog.com/posts/stable-diffusion-webui-manuals/zh-cn/training/prepare-training-dataset/
4 圖片標注
這里圖片標注是對每張訓練圖片加以文字的描述,并保存為與圖片同名的txt格式文本。
我們將使用神經網絡來為我們完成艱苦的工作,而不是自己費力地為每個圖片進行標注。這里用到的是一個名為BLIP的圖像標注模型。模型的標注并不完美,但后面經過人工的微調也足以滿足我們的目的。
標注工具可以使用SD WebUI中自帶的圖像標注功能。詳細使用請參考:https://ivonblog.com/posts/stable-diffusion-webui-manuals/zh-cn/training/prepare-training-dataset/中的預先給圖片上提示詞章節。
也可以使用一個工具:BooruDatasetTagManager
圖片標注完成之后,會在圖像文件夾里生成與圖片同名的txt文件。點擊打開txt文件,將覺得無關,多余的特征都給刪除掉。
強調:
每個txt中記得加上關鍵標記,如我這里是訓練迪麗熱巴,那我都加上關鍵詞dlrb,后面使用這個來觸發lora
至此,訓練數據集準備完成。
安裝Koyha_ss
目前網上有很多訓練LoRA的項目
1.koyha_ss_GUI:https://github.com/bmaltais/kohya_ss
2.LoRA_Easy_Training_Scripts:https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
3.秋葉大佬的:https://github.com/Akegarasu/lora-scripts
本文介紹的是koyha_SS_Gui,windows的安裝
這個安裝簡單,照著git步驟來就可以了,目前代碼中默認torch是支持cuda118的,這個需要注意自己的顯卡了。
1.git clone https://github.com/bmaltais/kohya_ss.git
2.cd kohya_ss
3..\setup.bat
#選擇1,進行安裝安裝過程可能報錯,哈哈,一步步來解決。
運行:
gui.ps1 --listen 127.0.0.1 --server_port 7861 --inbrowser --share訓練lora
1.準備參數和環境
需要配置以下三個目錄:
- image:存放訓練集
- log:存放日志文件
- model:存放訓練過的模型
首先在image文件夾中新建一個名為100_{{name}}的文件夾,100用來表示單張圖片訓練100次。然后將之前標注好的訓練數據都放入名為100的文件夾中。
由于之前準備的訓練數據集是真人風格的,故這里可以選擇真人風格的基座大模型:chilloutmix_NiPrunedFp32Fix.safetensors
詳細的配置如下:


隨后配置訓練參數:

系統提供了很多可以調節的參數,比如batchsize,learning rate, optimizer等等。大家可以根據自己實際情況進行配置。
2.啟動訓練
當路徑以及訓練參數都配置好之后,點擊入下圖所示的啟動按鈕即可啟動訓練。訓練的日志可在終端中查看。

使用模型
1 拷貝訓練過的lora模型
當訓練并測試完LoRA之后,就可以與基座大模型結合在一起進行特定風格的使用了。在使用之前需要先把訓練過的LoRA模型拷貝到SD WebUI對應的保存LoRA模型的文件夾中,對應的路徑為stable-diffusion-webui/models/Lora。
2 啟動SD WebUI進行圖像生成
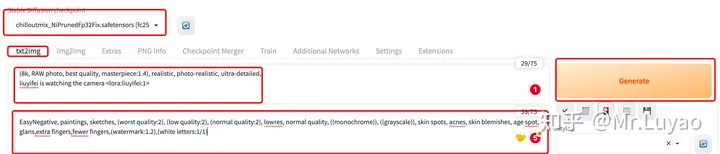
1. 啟動SD WebUI界面,首先選擇基座大模型,由于本示例是寫實風,故這里選擇寫實風的基座大模型:chilloutmix_NiPrunedFp32Fix.safetensors
2. 輸入正向prompt,并在最后輸入 <lora:訓練的模型名稱:權重> 來調用訓練過的LoRA模型。這里記得加入dlrb,關鍵詞
3. 輸入反向prompt
4. 設定超參
5. Generate
即可使用訓練過的LoRA模型進行特定任務的圖像生成。
復制:全流程講解如何使用Kohya_ss自定義訓練LoRA - 知乎?,加入自己的理解和排版










![隊列排序:給定序列a,每次操作將a[1]移動到 從右往左第一個嚴格小于a[1]的元素的下一個位置,求能否使序列有序,若可以,求最少操作次數](http://pic.xiahunao.cn/隊列排序:給定序列a,每次操作將a[1]移動到 從右往左第一個嚴格小于a[1]的元素的下一個位置,求能否使序列有序,若可以,求最少操作次數)



)




