目錄
- 項目介紹
- 🎯 功能展示
- 🌟 一、環境安裝
- 🎆 環境配置說明
- 📘 安裝指南說明
- 🎥 環境安裝教學視頻
- 🌟 二、數據集介紹
- 🌟 三、系統環境(框架/依賴庫)說明
- 🧱 系統環境與依賴配置說明
- 📈 模型訓練參數說明
- 🎯 基本訓練參數
- 🔁 實時數據增強策略
- 🌟 四、YOLO相關介紹
- 🎀 yolov5相關介紹
- 🎑 yolov8相關介紹
- 🎐 yolo11相關介紹
- 🌟 五、模型訓練步驟
- 🌟 六、模型評估步驟
- 🌟 七、訓練結果
- 🌟 獲取方式說明
項目介紹
本項目基于 PyQt5 構建了簡潔易用的圖形用戶界面,支持用戶選擇本地圖片或視頻進行目標檢測。系統界面美觀,交互流暢,具備良好的用戶體驗。
項目附帶完整的 Python 源碼和詳細的使用說明,適合學生進行學習或有一定 Python 基礎的開發者,參考與二次開發。您可以在文末獲取完整的代碼資源文件。
? 項目亮點
-
🔧 完整系統級項目: 包括pyqt5界面、后臺檢測邏輯、模型加載等模塊
-
🧠 支持深度學習模型擴展: 源代碼,支持個人添加改進、模型修改等
-
🚀 可用于畢(she)/課(she)/個人項目展示: 結構清晰,邏輯完整,便于演示

🎯 功能展示
本系統具備多個核心功能,支持圖像、視頻、攝像頭等多種輸入源的目標檢測需求:
-
🎴功能1:支持單張圖片識別
加載本地圖片進行目標識別,支持多種圖片格式(如.jpg、.png等)。 -
📁功能2:支持遍歷文件夾識別
可批量讀取指定文件夾中的所有圖像,并依次完成目標檢測任務。 -
🎫功能3:支持識別視頻文件
支持導入本地視頻文件,逐幀分析,實時顯示檢測效果。 -
📷功能4:支持攝像頭識別
直接調用筆記本/外接USB攝像頭進行實時目標檢測。(此功能識別不準,僅僅是為了有這個功能。) -
📤功能5:支持結果文件導出(.xls 格式)
自動保存檢測結果為表格文件,包含類別、位置、置信度等信息,方便后續統計與分析。 -
🔄功能6:支持切換檢測目標進行查看
可自定義選擇或切換需要檢測的目標種類,僅顯示感興趣的目標。
🎥 更多功能細節、代碼演示效果獲取請參考下方視頻演示。此視頻是必看的,里面的信息比文章要豐富,很多內容無法通過博客文字表達出來。
59-基于深度學習的麥穗計數統計系統-yolo11-彩色版界面
59-基于深度學習的麥穗計數統計系統-yolov8/yolov5-經典版界面
🌟 一、環境安裝
🎆 環境配置說明
本項目已準備好 完整的環境安裝資源包,包含:
- Python、PyCharm
- CUDA、PyTorch
- 其他依賴庫(版本已適配)
所有依賴版本均已過驗證,確保彼此兼容,可直接參考配套文檔或視頻教程一步步安裝,無需手動調試。
📘 安裝指南說明
本項目附帶的環境配置文檔及配套視頻,文檔是我在輔導上千名同學安裝環境過程中,持續整理總結而成的經驗合集,內容覆蓋:
- GPU 與 CPU 兩種版本的詳細安裝流程
- 安裝過程中常見問題匯總
- 每個問題對應的解決方案
- 實測可行的安裝順序建議與注意事項
🧩 無論你是新手還是有經驗的開發者,相信這份文檔都能為你省下大量踩坑時間!
🎥 環境安裝教學視頻
環境安裝-03GPU版
🌟 二、數據集介紹
使用數據集一部分個人標注,一部分來源網絡,已統一標注格式并完成預處理,可直接用于訓練與測試。
數據集樣式如下:
| 訓練樣例1 | 訓練樣例2 |
|---|---|
 |  |
數據集制作流程
標注數據: 使用標注工具(LabelImg)對圖像中的目標進行標注。每個目標需要標出邊界框,并且標注類別。
轉換格式: 將標注的數據轉換為YOLO格式。YOLO標注格式為每行: <x_center> <y_center> ,這些坐標是相對于圖像尺寸的比例。
分割數據集: 將數據集分為訓練集、驗證集和測試集,通常的比例是80%訓練集、10%驗證集和10%測試集。
準備標簽文件: 為每張圖片生成一個對應的標簽文件,確保標簽文件與圖片的命名一致。
調整圖像尺寸: 根據YOLO網絡要求,統一調整所有圖像的尺寸(如416x416或608x608)。
這里只是簡單大概介紹,我實際的文檔里,內容更要比這里豐富很多,保姆級的教程。這里放太多鏈接,大家容易看不到😂😂😂。
🌟 三、系統環境(框架/依賴庫)說明
以下內容是簡單的介紹,方便大家寫文章,可直接套用。
🧱 系統環境與依賴配置說明
本項目采用 Python 3.8.10 作為開發語言,整個后臺邏輯均由 Python 編寫,主要依賴環境如下:
🎡 圖形界面框架:
- PyQt5 5.15.9:用于搭建系統圖形用戶界面,實現窗口交互與組件布局。
🧠 深度學習框架:
- torch 1.9.0+cu111:PyTorch 深度學習框架,支持 CUDA 11.1 加速,用于模型構建與推理。
- torchvision 0.10.0+cu111:用于圖像處理、數據增強及模型組件輔助。
? CUDA 與 cuDNN(GPU 加速支持):
- CUDA 11.1.1(版本號:
cuda_11.1.1_456.81):用于 GPU 加速深度學習運算。 - cuDNN 8.0.5.39(適用于 CUDA 11.1):NVIDIA 深度神經網絡庫,用于加速模型訓練與推理過程。
🧪 圖像處理與科學計算:
- opencv-python 4.7.0.72:實現圖像讀取、顯示、處理等功能。
- numpy 1.24.4:用于高效數組計算及矩陣操作。
- PIL (pillow) 9.5.0:圖像文件讀寫與基本圖像處理庫。
- matplotlib 3.7.1(可選):用于結果圖形化展示與可視化調試。
📈 模型訓練參數說明
本項目中提供了兩個訓練好的模型,均基于如下參數完成訓練。具體訓練時的設置需根據您自己的硬件配置靈活調整:
🎯 基本訓練參數
- batch size:16
- epoch:200
- imgsz(輸入尺寸):640
- 優化器:SGD
- 學習率:初始學習率
0.01,最終學習率0.0001 - 學習率衰減策略:余弦退火(Cosine Annealing)
- 激活函數:SiLU
- 損失函數:CIOU(Complete IOU)
🔁 實時數據增強策略
訓練過程中使用了多種 在線增強 方法,包括:
- HSV 色域變換
- 上下翻轉、左右翻轉
- 圖像旋轉
- Mosaic 圖像拼接增強
?? 特別說明:
以上所有增強操作均為 實時數據增強,只在訓練過程中動態生成,用作模型輸入,不會將增強后的圖像保存到本地。
這種策略具有以下優勢:
- 節省磁盤空間
- 提高訓練樣本的多樣性
- 增強模型的泛化能力
若需要可視化增強效果,可自行編寫腳本或借助工具(如 Photoshop、美圖秀秀等)生成示例圖像進行展示。
🌟 四、YOLO相關介紹
🎀 yolov5相關介紹
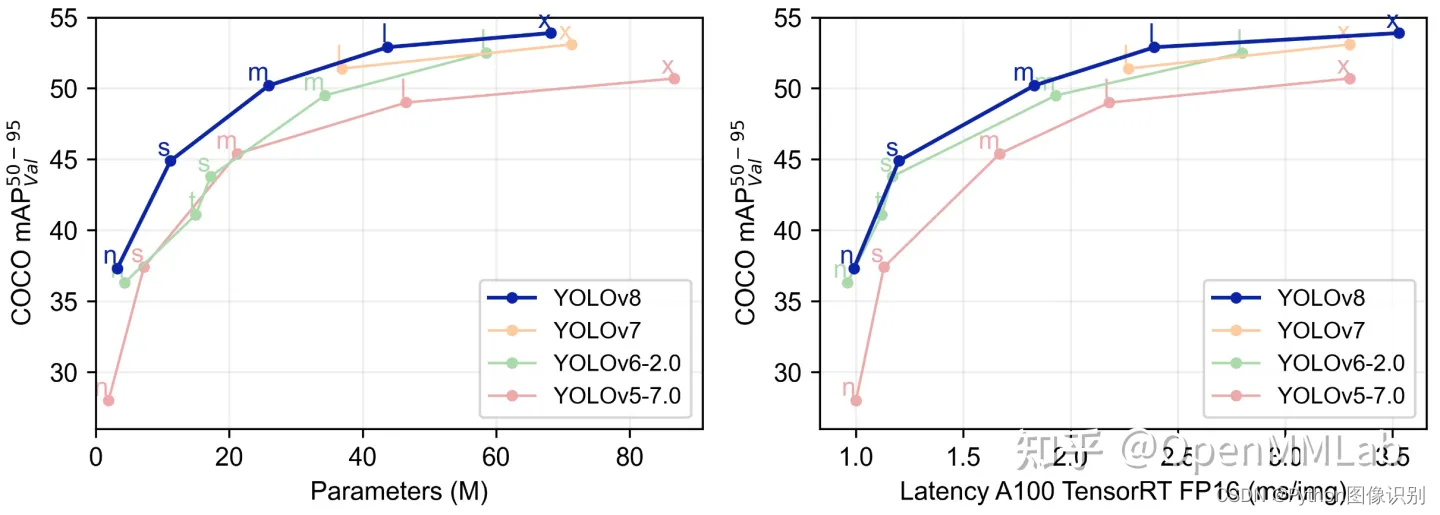
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五個版本。這個模型的結構基本一樣,不同的是deth_multiole模型深度和width_multiole模型寬度這兩個參數。就和我們買衣服的尺碼大小排序一樣,YOLOV5n網絡是YOLOV5系列中深度最小,特征圖的寬度最小的網絡。其他的三種都是在此基礎上不斷加深,不斷加寬。不過最常用的一般都是yolov5s模型。

??本系統采用了基于深度學習的目標檢測算法YOLOv5,該算法是YOLO系列算法的較新版本,相比于YOLOv3和YOLOv4,YOLOv5在檢測精度和速度上都有很大的提升。YOLOv5算法的核心思想是將目標檢測問題轉化為一個回歸問題。此外,YOLOv5還引入了一種稱為SPP(Spatial Pyramid Pooling)的特征提取方法,這種方法可以在不增加計算量的情況下,有效地提取多尺度特征,提高檢測性能。
??在YOLOv5中,首先將輸入圖像通過骨干網絡進行特征提取,得到一系列特征圖。然后,通過對這些特征圖進行處理,將其轉化為一組檢測框和相應的類別概率分數,即每個檢測框所屬的物體類別以及該物體的置信度。YOLOv5中的特征提取網絡使用CSPNet(Cross Stage Partial Network)結構,它將輸入特征圖分為兩部分,一部分通過一系列卷積層進行處理,另一部分直接進行下采樣,最后將這兩部分特征圖進行融合。這種設計使得網絡具有更強的非線性表達能力,可以更好地處理目標檢測任務中的復雜背景和多樣化物體。

??在YOLOv5中,每個檢測框由其左上角坐標(x,y)、寬度(w)、高度(h)和置信度(confidence)組成。同時,每個檢測框還會預測C個類別的概率得分,即分類得分(ci),每個類別的得分之和等于1。因此,每個檢測框最終被表示為一個(C+5)維的向量。在訓練階段,YOLOv5使用交叉熵損失函數來優化模型。損失函數由定位損失、置信度損失和分類損失三部分組成,其中定位損失和置信度損失采用了Focal Loss和IoU Loss等優化方法,能夠有效地緩解正負樣本不平衡和目標尺寸變化等問題。
??YOLOv5網絡結構是由Input、Backbone、Neck、Prediction組成。Yolov5的Input部分是網絡的輸入端,采用Mosaic數據增強方式,對輸入數據隨機裁剪,然后進行拼接。Backbone是Yolov5提取特征的網絡部分,特征提取能力直接影響整個網絡性能。YOLOv5的Backbone相比于之前Yolov4提出了新的Focus結構。Focus結構是將圖片進行切片操作,將W(寬)、H(高)信息轉移到了通道空間中,使得在沒有丟失任何信息的情況下,進行了2倍下采樣操作。
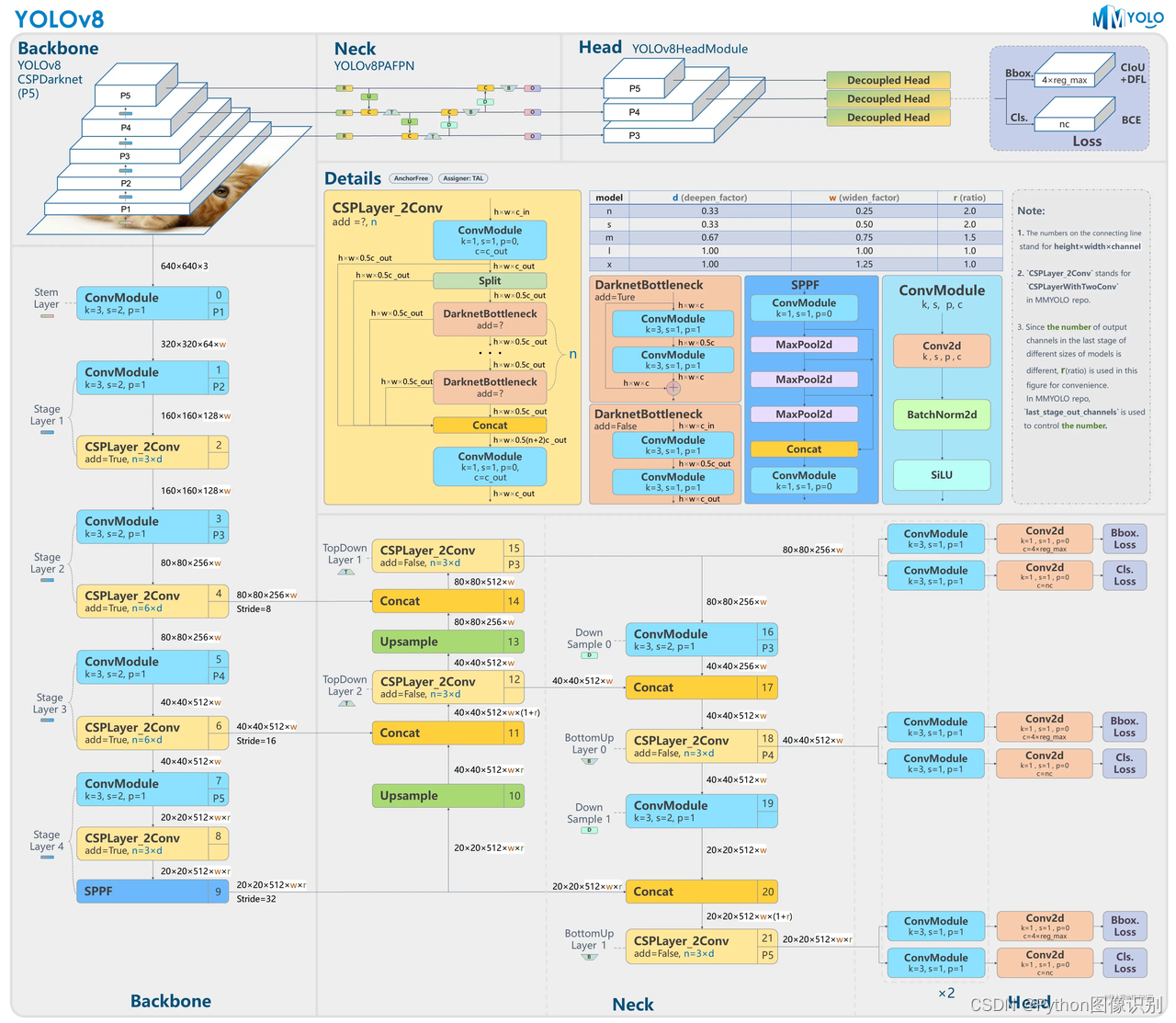
🎑 yolov8相關介紹
YOLOv8 是一個 SOTA 模型,它建立在以前 YOLO 版本的成功基礎上,并引入了新的功能和改進,以進一步提升性能和靈活性。具體創新包括一個新的骨干網絡、一個新的 Ancher-Free 檢測頭和一個新的損失函數,可以在從 CPU 到 GPU 的各種硬件平臺上運行。
不過 ultralytics 并沒有直接將開源庫命名為 YOLOv8,而是直接使用 ultralytics 這個詞,原因是 ultralytics 將這個庫定位為算法框架,而非某一個特定算法,一個主要特點是可擴展性。其希望這個庫不僅僅能夠用于 YOLO 系列模型,而是能夠支持非 YOLO 模型以及分類分割姿態估計等各類任務。
總而言之,ultralytics 開源庫的兩個主要優點是:
-
融合眾多當前 SOTA 技術于一體
-
未來將支持其他 YOLO 系列以及 YOLO 之外的更多算法
網絡結構如下:
🎐 yolo11相關介紹
YOLO11 是Ultralytics YOLO 系列實時物體檢測器的最新版本,以尖端的精度、速度和效率重新定義了可能性。基于先前 YOLO 版本的令人印象深刻的進步,YOLO11 在架構和訓練方法方面引入了重大改進,使其成為各種計算機視覺任務的多功能選擇。
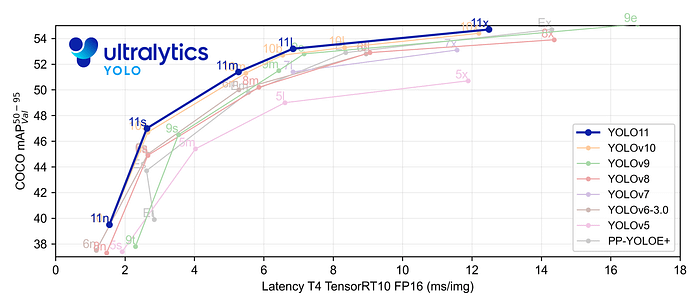
Key Features 主要特點:
- 增強的特征提取:YOLO11采用改進的主干和頸部架構,增強了特征提取能力,以實現更精確的目標檢測和復雜任務性能。
- 針對效率和速度進行優化:YOLO11 引入了精致的架構設計和優化的訓練管道,提供更快的處理速度并保持準確性和性能之間的最佳平衡。
- 使用更少的參數獲得更高的精度:隨著模型設計的進步,YOLO11m 在 COCO 數據集上實現了更高的平均精度(mAP),同時使用的參數比 YOLOv8m 少 22%,從而在不影響精度的情況下提高計算效率。
- 跨環境適應性:YOLO11可以無縫部署在各種環境中,包括邊緣設備、云平臺以及支持NVIDIA GPU的系統,確保最大的靈活性。
- 支持的任務范圍廣泛:無論是對象檢測、實例分割、圖像分類、姿態估計還是定向對象檢測 (OBB),YOLO11 旨在應對各種計算機視覺挑戰。

🌟 五、模型訓練步驟
以下操作步驟,每年我都會更新,所以下方操作步驟可跳過,可以去我文檔里查看最新的操作步驟。
-
使用pycharm打開代碼,找到
train.py打開,示例截圖如下:

-
修改
model_yaml的值,根據自己的實際情況修改,想要訓練yolov5s模型 就 修改為model_yaml = yaml_yolov5s, 訓練 添加SE注意力機制的模型就修改為model_yaml = yaml_yolov5_SE -
修改
data_path數據集路徑,我這里默認指定的是traindata.yaml文件,如果訓練我提供的數據,可以不用改 -
修改
model.train()中的參數,按照自己的需求和電腦硬件的情況更改# 文檔中對參數有詳細的說明 model.train(data=data_path, # 數據集imgsz=640, # 訓練圖片大小epochs=200, # 訓練的輪次batch=2, # 訓練batchworkers=0, # 加載數據線程數device='0', # 使用顯卡optimizer='SGD', # 優化器project='runs/train', # 模型保存路徑name=name, # 模型保存命名) -
修改
traindata.yaml文件, 打開traindata.yaml文件,如下所示:

在這里,只需修改 path 的值,其他的都不用改動(仔細看上面的黃色字體),我提供的數據集默認都是到yolo文件夾,設置到 yolo 這一級即可,修改完后,返回train.py中,執行train.py。 -
打開
train.py,右鍵執行。

-
出現如下類似的界面代表開始訓練了

-
訓練完后的模型保存在runs/train文件夾下

🌟 六、模型評估步驟
以下操作步驟,每年我都會更新,,所以下方操作步驟可跳過,可以去我文檔里查看最新的操作步驟。
-
打開
val.py文件,如下圖所示:

-
修改
model_pt的值,是自己想要評估的模型路徑 -
修改
data_path,根據自己的實際情況修改,具體如何修改,查看上方模型訓練中的修改步驟 -
修改
model.val()中的參數,按照自己的需求和電腦硬件的情況更改model.val(data=data_path, # 數據集路徑imgsz=300, # 圖片大小,要和訓練時一樣batch=4, # batchworkers=0, # 加載數據線程數conf=0.001, # 設置檢測的最小置信度閾值。置信度低于此閾值的檢測將被丟棄。iou=0.6, # 設置非最大抑制 (NMS) 的交叉重疊 (IoU) 閾值。有助于減少重復檢測。device='0', # 使用顯卡project='runs/val', # 保存路徑name='exp', # 保存命名) -
修改完后,即可執行程序,出現如下截圖,代表成功(下圖是示例,具體輸出結果以自己的實際項目為準。)

-
評估后的文件全部保存在在
runs/val/exp...文件夾下

🌟 七、訓練結果
模型訓練完成后,所有相關文件(包括權重文件、訓練日志、評估結果等)均統一保存在代碼工程的weights文件夾下,便于后續模型部署與復用。文件夾內包含訓練過程中生成的所有最優權重(best.pt)及最終權重(last.pt),整體結構清晰,可直接用于推理或二次訓練。
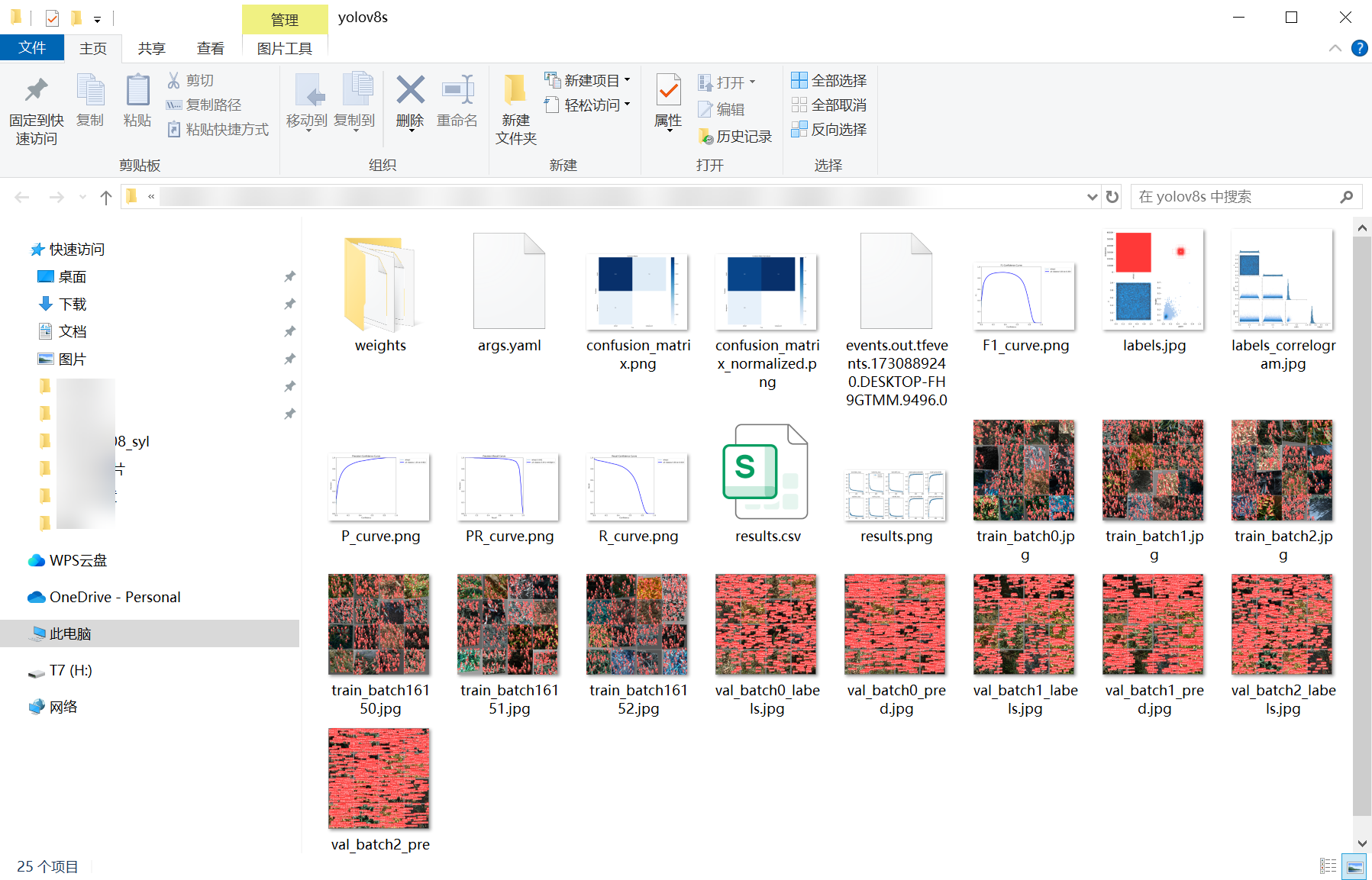
訓練的曲線圖:
訓練過程中,模型的關鍵指標(如損失值、精度、召回率等)變化曲線已自動記錄并可視化。從曲線中可以清晰觀察到:
- 訓練集與驗證集的損失值(Loss)隨迭代次數增加逐步下降并趨于穩定,表明模型有效學習到數據特征;
- 核心評估指標(如 mAP@0.5、準確率)在訓練后期逐步收斂,驗證集性能與訓練集保持一致,無明顯過擬合現象;
- 通過對比不同階段的指標變化,可直觀判斷模型收斂速度與穩定性,為參數調優提供參考。

評估的結果示例圖:
為更直觀展示模型性能,選取val中具有代表性的樣本進行可視化評估,涵蓋不同場景、不同目標密度及復雜背景下的檢測 / 分類效果:
| 評估示例圖1 | 評估示例圖2 |
|---|---|
 |  |
🌟 獲取方式說明
這是一套完整的資源,經過往屆學長學姐檢驗過,是OK的項目,我這里就不做過多的介紹了,說的太多了,大家容易看不到。如果想要獲取源碼進行學習,可觀看一下前面 功能展示 章節的視頻演示。如有疑問,也可通過下方的名片或者留言進行交流,一起學習、進步。
💡 溫馨提示:資源僅用于學習交流,請勿用于商業用途,感謝理解與支持!
















 函數用戶使用手冊)
)

