引言
目標檢測算法的發展已經取得了長足的進步,從早期的計算機視覺方法開始,通過深度學習達到了很高的準確度。在這篇博文中,我們將一起回顧一下這些算法的發展階段以及現代目標檢測系統中使用的主要方法。
我們首先回顧早期傳統的目標檢測方法:Viola-Jones 檢測器、HOG 檢測器和基于部件(Part-based)的方法。它們在目標檢測領域發展之初得到了廣泛應用。
然后,我們逐漸轉向基于兩階段和一階段目標檢測神經網絡的更現代的深度學習目標檢測方法:RCNN、YOLO、SSD 和 CenterNet。這些方法提供了一種端到端( end-to-end)的架構,允許算法適應任何輸入數據。
博文的最后,我們以Zero-Shot目標檢測方法結束,它允許我們在無需任何神經網絡訓練的情況下搜索圖像中的任何對象,典型的Zero-Shot目標檢測方法包括:OWL-ViT、CLIP、GLIP、Segment Anything、GVT。

目標檢測概述
在本文中,我們將探討目標檢測的主題、含義、優勢以及許多有趣的地方,我們還將嘗試分析目標檢測的總體趨勢和演變。
讓我們從基礎開始:目標檢測任務可以非常簡單地表述:什么目標位于何處?
目標檢測是計算機視覺中的一項關鍵任務,其目標是識別和定位圖像中的各種對象,例如汽車、騎自行車的人和交通燈。這是通過使用坐標( x m i n x_{min} xmin?, y m i n y_{min} ymin?, x m a x x_{max} xmax?, y m a x y_{max} ymax?)定義矩形區域并將它們與分類和概率向量( p 1 p_1 p1?, p 2 p_2 p2?, ? \cdots ?, p n p_n pn?)關聯來實現的。目標檢測在實際意義上超越了圖像分類,因為它能夠檢測對象以進行后續分析、修改或分類。Stable Diffusion 和 Face Swap 等技術利用目標檢測來操縱和替換圖像中的目標或人臉。當同一類的多個目標(例如行人)重疊時,就會出現挑戰。盡管各種替代方法正在興起,但非極大值抑制(Non-Maximum Suppression,NMS)仍然是目前的通用解決方案,。
目標檢測是一項極其重要的任務,在過去約 30 年中得到了發展和改進。目標檢測算法的研發一直是一個活躍的研究領域,我們將持續觀察該領域的新趨勢和進展。目標檢測技術應用廣泛應用于各個行業,從視頻監控和自動駕駛汽車到醫藥和零售,具體來說:
- 視頻監控:檢測視頻片段中的人物及其位置,監控他們之間的距離。
- 汽車行業:利用計算機視覺來了解環境和道路安全。
- 醫學診斷:檢測圖像中的腫瘤和其他異常情況以進行分析。
- 零售:自動化貨物核算流程和檢測盜竊行為。
- 農業:監測植物健康、疾病檢測、田間分析和其他農業任務。

目標檢測路線圖
讓我們從 Roadmap 開始。本小節包含一些論文中的圖片,描述了目標檢測方法的發展。讓我們概述一下這些路線圖,重點關注一些要點。
路線圖(一般)

目標檢測自 20 世紀 80 年代以來一直在發展。1998 年,LeCun 等人引入了 LeNet-5,這是一種用于數字識別的重要 CNN 架構。這個數據集被稱為 MNIST,起源于 90 年代,此后成為評估機器學習和深度學習算法的流行基準。后來有人提出了目標檢測的要求,但當時還沒有足夠有效的方法來做到這一點。
第一個重要的方法是 Viola-Jones 或 Haar 級聯,它在當時的 PC 上能夠進行快速運算且易于使用,提供每秒數幀 (FPS) 的可接受檢測速度。
幾年后,HOG 檢測器方法作為 Viola-Jones 的替代方法被引入,主要側重于捕獲物體形狀和輪廓。
后來,使用可變形部件模型(Deformable Parts Models,DPM)的方法開始發揮作用,在目標檢測精度方面長期占據領先地位。
2012 年,第一個大型深度神經網絡出現,包括 AlexNet。盡管速度慢且計算量大,但 AlexNet 和后續模型(例如 MobileNet)的架構一直在持續得到優化。
這些模型提供了高質量的代表性圖像特征,可以很好的描述上下文并檢出各種目標。
這些方法最重要的方面之一是它們的“端到端”性質:輸入圖像經歷一系列差異化的操作,從而能夠在單個架構內進行整體處理。
路線圖(更傳統的方法)

目標檢測的發展主要經歷了兩個歷史時期:“傳統目標檢測時期(2014年之前)”和“基于深度學習的目標檢測時期(2014年后)”。
在 2014 年之前,大多數目標檢測算法都是基于手動創建的特征構建的。例如,2001年,P. Viola和M. Jones使用VJ檢測器實現了不受任何限制的實時人臉檢測。該探測器使用“滑動窗口”技術,遍歷圖像中所有可能的位置和比例,以查看是否有任何窗口包含人臉。
SIFT(尺度不變特征變換)是一種用于從圖像中提取和描述獨特特征的方法。使用傳統的計算機視覺方法,可以計算描述圖像的各種函數和特征。例如,您可以通過相鄰像素的像素值之間的差異來計算圖像梯度。這是特征提取的重要一步。此外,拉普拉斯算子可用于檢測圖像中的邊緣。SIFT 將圖像劃分為關鍵點鄰域或興趣區域,從中可以提取描述這些區域的特征。通過將這些特征與表示目標的描述符進行比較,可以識別與目標最相似的區域。通過這種方式,您可以表示該目標位于該處的概率很高。
從最簡單的層面來說,這意味著找到圖像中最相似的部分。還有哪些傳統方法?說實話,我并沒有真正研究過,因為它們幾乎都不再被使用了。如果你需要快速人臉檢測,唯一可能仍然使用的是 Haar 級聯。
路線圖(深度學習方法)

2014年以后,隨著深度學習的出現,目標檢測開始以前所未有的速度發展。例如,2014 年,R. Girshick 等人。提出了具有CNN特征的區域(RCNN)方法,顯著提高了目標檢測的準確性。
2015 年,S. Ren 等人提出了 Faster RCNN 檢測器,這是第一個基于深度學習的 near-real-world 檢測器。Faster-RCNN 的主要貢獻是引入了Region Proposal Network (RPN),它允許人們以很小的代價獲得區域 Proposal。從R-CNN到Faster RCNN,目標檢測系統的大部分單獨模塊,例如特征提取、邊界框回歸等,已逐漸集成到單個最終學習框架中。
2017 年,T.-Y. Lin等人提出了特征金字塔網絡(Feature Pyramid Networks,FPN)。FPN 在檢測各種尺度的目標方面取得了顯著進展。通過在主 Faster R-CNN 系統中使用 FPN,無需額外調整即可在 COCO 數據集上檢測單個模型,從而獲得最佳結果。
對于 single-stage 檢測器,YOLO(You Only Look Once)是由 R. Joseph 等人在2015年提出。YOLO 速度極快:YOLO 的快速版本運行速度為每秒 155 幀。YOLO 將單個神經網絡應用于一幅完整圖像,該網絡將圖像劃分為多個區域,并同時預測每個區域的邊界框和概率。
目標檢測指標的改進
評估目標檢測算法時的一個重要方面是平均精度 (mAP) 指標。該指標衡量閾值更改時算法的精度和召回率之間的關系。在 YOLOv5 等算法中使用置信閾值可以讓你丟棄低概率的預測。在精確率和召回率之間找到平衡非常重要,這反映在 mAP 指標中。
我們詳細分析了 VOC07、VOC12 和 MS-COCO 數據集上目標檢測 mAP 的發展和改進。

- 在VOC07數據集上,目標檢測的mAP從2008年(DPM方法)的21%增加到2018年(RefineDet)的83.8%。(+62.8%)
- 在VOC12數據集上,mAP從2014年(R-CNN方法)的53.7%增加到2018年(RefineDet)的83.5%。(+29.8%)
- 在 MS-COCO 數據集上,目標檢測的 mAP 從 2015 年(Fast R-CNN 方法)的 19.7% 增加到 2021 年(Swin Transformer)的 57.7%。(+38%)
這些數據證實了近年來物體檢測領域取得的重大進展,特別是隨著深度學習的出現及其在物體檢測方法中的應用。
傳統檢測方法
自從首次積極研究人臉識別方法以來,目標檢測算法領域已經發生了許多變化。在本文中,我們將回顧自 2001 年以來該領域的發展,當前已經有了許多 基于目標的人臉檢測方法 的綜述文章。
當時,主要有兩種方法:基于圖像和基于特征。基于圖像的方法使用 SVM(支持向量機)和線性子空間方法等方法。他們還利用了 LeNet 等卷積神經網絡 (CNN),該網絡在早期圖像識別任務中發揮了重要作用。還采用了統計方法,包括高斯混合模型和基于正態分布的概率模型等技術。
盡管從研究的角度來看,其中一些方法很有趣,并且對于了解技術發展脈絡來說可能具有價值,但它們已不再用于現代目標檢測系統。相反,現代方法基于大型神經網絡,可以進行高效的圖像比較和目標識別。這些方法提供了更具代表性的結果。

Viola-Jones Detectors (2001)
其中一種算法是 Haar 級聯,也稱為 Viola-Jones 算法。

Haar 級聯算法基于一個簡單的想法:如果我們要檢測圖像中的人臉,一般來說,所有的人臉都有相似的特征,比如兩只眼睛、一個鼻子、一張嘴。例如,眼睛通常有一定的形狀,臉的底部因為陰影而變暗,拍照時可以突出臉頰和鼻子。
因此,我們可以形成一組描述這些面部特征的模板。這些模板可以是小正方形或矩形的形式。卷積運算用于將這些模板與圖像塊進行卷積以生成特征圖,隨后對其進行分析以進行目標檢測。
Haar 算法的級聯方法因其優點而被使用。作者使用boosting方法并依次應用不同的模板,這允許檢測具有很多變化的面部,例如傾斜和照明條件。在基于級聯模板順序應用不同的分類器之后,算法在每個階段做出決定,以確定是繼續將候選區域評估為人臉還是拒絕它。
因此,我們得到了一個可以快速工作的目標檢測器,并且在考慮包括訓練數據、特征選擇和應用程序上下文在內的各種因素時可以顯示出良好的結果。
HOG探測器 (2005)
方向梯度直方圖(Histogram of Oriented Gradients,HOG)算法于 2005 年發明,與深度學習圖像處理方法不同,它不使用神經網絡。
-
首先,圖像被分成8x8像素的小子圖。對于每個子圖,我們計算梯度,從而產生一組梯度值。這些值分布到具有指定數量的bins的直方圖中,以表示該子區域中的梯度分布。來自多個子區域的直方圖被連接起來形成特征向量。
-
接下來,使用直方圖均衡等過程對直方圖進行歸一化,以增強對比度并均衡圖像不同部分像素的強度幅度。這有助于改善整體視覺表現。
-
對直方圖進行歸一化后,為滑動窗口覆蓋的每個區域計算描述符,該滑動窗口以多個尺度和縱橫比在圖像上移動。通過檢查這些檢測窗口并比較從它們中提取的特征向量,可以檢測到面部等目標。經過訓練的分類器(通常是支持向量機 (SVM))用于確定感興趣的對象是否存在。
雖然這種方法可以檢測人臉,但它在檢測細粒度細節或復雜結構(例如劃痕或腦腫瘤)方面可能不那么有效,從而限制了其在此類任務中的使用。
乍一看,人們可能會建議結合考慮顏色和其他參數的更復雜的功能,事實上,進一步的研究已經探索了此類改進。例如,將 HOG 與其他特征描述符(例如顏色直方圖或類似 Haar 的特征)相結合已顯示出有潛力的結果。此外,還存在利用部分特征進行目標檢測的有效方法,例如組合多個特征描述符來查找行人或人臉等目標。盡管這些方法可能更加復雜,但它們在某些情況下已經證明了可以有效提高準確性。
總的來說,HOG 方法是檢測圖像中目標的有效方法,特別是對于人臉檢測等任務。通過利用數學方法和基于梯度的特征,它取得了良好的效果。盡管如此,對該方法的進一步研究和修改可以提高其效率和準確性。
基于部分的方法
- 基于可變形部件的模型 (2010)
- 隱式形狀模型 (2004)
基于可變形部件的模型 (Deformable Part-based Model,DPBM),由 Felzenszwalb 等人在2010年提出,是一種基于可變形狀部件概念的目標檢測方法。隱式形狀模型(Implicit Shape Model,ISM),由 Leibe 等人在2004年提出,是一種目標檢測方法,它將目標的形狀表示為一組局部特征,并使用統計方法來查找圖像中對象最可能的區域。這兩種方法都已廣泛應用于目標檢測任務,有助于提高圖像處理算法的準確性和可靠性。

基于深度學習的檢測方法
在任何基于深度學習的目標檢測過程開始時,我們都有一個輸入到模型的輸入圖像。該圖像可以以其原始形式進行處理或調整為固定尺寸。然后,在每個尺度上,我們搜索目標,并對結果進行平均。針對這項任務人們提出了不同的方法。

處理一張圖像或一組圖像后,它們被傳輸到模型主干(backbone)。主干網絡的任務是從圖像中提取各種特征,創建描述圖像的特征向量。有許多不同的主干模型,例如 AlexNet、VGG、ResNet、YOLO(使用 DarkNet 的修改版本作為主干)、EfficientNet、MobileNet 和 DenseNet。
獲得的特征從主干層傳遞到負責特征細化的中間層,然后再傳遞到頭部。在某些架構中,backbone和head之間可能沒有中間模塊,特征直接傳遞到head以生成最終的邊界框和類預測。總體目標是確定目標的位置和類別。
兩階段和一階段目標檢測器

目標檢測算法可以分為兩類:兩階段和一階段(two-stage and one-stage)。在兩階段算法中,骨干和頸部任務涉及創建region proposal。從圖像中提取特征并將其傳輸到一個神經網絡,該神經網絡返回一組潛在的對象位置及其置信度。或者,可以使用選擇性搜索算法來生成目標proposal。接收到的特征以及proposal被轉移到算法的后續階段/組件以進行進一步處理。
相比之下,一步算法使用一種更簡單、更快的方法。直接處理圖像,并提取特征來檢測目標,而無需顯式的proposal生成步驟。
兩階段檢測器
RCNN (2014)
我們要討論的第一個算法是R-CNN(基于區域的卷積神經網絡)。它通過采用多階段pipeline和各種組件引入了基于區域的檢測概念。我們獲取圖像輸入并生成region proposal。然后使用感興趣區域池化(ROI Pooling)操作將這些proposal 轉換為固定大小,該操作從建議區域中提取固定長度的特征向量。R-CNN 網絡由用于特征提取的卷積神經網絡 (CNN) 和全連接層組成。CNN 提取特征,后續層執行對象分類,確定對象的存在及其類別。此外,網絡還結合了邊界框回歸來細化對象周圍邊界框的坐標。

Fast RCNN (2015)
基于區域卷積神經網絡(RCNN),研究者們開發了一種稱為 Fast R-CNN 的改進算法。它比其前身更快,因為它不使用整個圖像來檢測對象,而是利用神經網絡已識別的特殊特征。與原始圖像相比,這些特征的尺寸要小得多。借助這些功能,可以生成特征圖,同時考慮到調整大小的特征圖。接下來,應用空間金字塔池化(Spatial Pyramid Pooling,SPP)從不同級別的特征圖中提取特征。這些特征被傳遞到全連接層,該層執行目標分類和細化,就像以前的架構一樣。

Faster RCNN (2015)
另一個顯著加速這一過程的改進是 Faster R-CNN。在此算法中,使用神經網絡生成region proposal。這可以實現更細粒度的處理,簡化訓練,并促進應用各種優化技術來針對不同平臺優化網絡。

FPN (2017)
我們要討論的下一個算法是特征金字塔網絡(Feature Pyramid Networks,FPN),它是 Faster R-CNN 的改進版。盡管與 Faster R-CNN 相比,它提供了更準確的結果,但特征金字塔網絡 (FPN) 保持了相似的處理速度。在 FPN 中,特征圖不再像以前那樣僅從網絡的最后一層提取,而是從圖像處理的不同階段提取。然后,使用逐元素加法通過自上而下的路徑和橫向連接來聚合這些特征,并基于生成的特征金字塔,為執行目標分類和檢測的另一個神經網絡創建初始proposal。

以上是一些典型兩階段目標檢測算法的概述。它們都有自己的優點,可以根據項目的需要來使用。
Backbones
目標檢測算法的開發是一個活躍的研究領域,該領域非常關注各種架構(例如骨干網)對檢測器的準確性和效率的影響。我們將研究主干網對兩階段探測器的影響,并討論這個問題的重要方面。

為了根據特征生成準確的目標proposal,必須具有高質量的特征,以便你可以在圖像中找到目標。選擇合適的主干架構對檢測器的準確性有重大影響。例如,MobileNet、Inception 和 ResNet 等流行架構表現出不同的效率和準確性特征。
提取器特征的準確性可以通過使用合適的損失函數在具有Groundtruth邊界框的目標檢測數據集上訓練backbone來評估。架構的頭部通常會被修改或增強額外的層以實現目標檢測。
由于與其他組件的相互依賴,在 Faster R-CNN 架構中訓練主干可能具有挑戰性。在這種情況下,神經網絡組件,包括主干網絡、Region proposal網絡和目標檢測頭,是聯合訓練的。
首先,神經網絡組件,包括特征提取器,是聯合訓練的。特征提取器在特征提取后不會凍結,并且會與其他組件一起繼續進行微調。
Faster R-CNN 的一個有趣的特點是它的兩階段學習過程,首先訓練Region Proposal網絡(RPN),然后訓練目標檢測頭。
目前,訓練一階段目標檢測算法,如 YOLO(You Only Look Once)或 SSD(Single Shot MultiBox Detector),已經大大簡化,因為它們是一次性訓練的,但它們仍然有自己的細微差別。
一階段檢測器
YOLO (2015)
YOLO(You Only Look Once)是一階段檢測器之一。雖然下面的簡單示意圖沒有完全描述算法的內部工作原理,但它有助于理解一般概念。
圖像被劃分為單元格網格,其中網格的大小是可配置的。每個單元格都包含用于目標檢測的特征。
主要思想是 YOLO 預測每個單元中多個目標的邊界框和類概率,而無需假設每個單元中最多有 2 個目標。

SSD (2015)
另一種一階段檢測器是 SSD(Single Shot MultiBox Detector),它是一種單級檢測器,其工作原理是將不同層的特征聚合到最終的分類器和回歸器中。

RetinaNet (2017)
RetinaNet 是另一個重要的一階段檢測器,它聚合有關上下文和紋理特征的信息,以實現目標定位的高精度。它還利用焦點損失函數(focal loss function)和特征金字塔網絡(FPN)。

CenterNet (2019)
2019 年發布的 CenterNet 架構是另一個值得一提的一階段解決方案。

形成此類網格的最初想法面臨著挑戰,特別是在處理包含數千個目標的大型衛星圖像時。CenterNet 沒有定義邊界框,而是為每個目標分配一個中心點。這允許使用中心點結合預測的偏移量進行目標檢測和計數,以生成包圍目標的邊界框。CenterNet的一個顯著特點是使用Hourglass Backbone,它能夠實現多尺度信息融合并增強模型捕獲上下文信息的能力。在Hourglass Backbone之后,CenterNet執行關鍵點評估和檢測。
目標檢測器按類劃分
目標檢測算法的統一、高效開發是計算機視覺領域的熱門話題。如今,目標檢測器算法有多種變體,其方法和結果各不相同。其中之一是基于anchor的兩階段檢測器,它基于兩個階段的檢測。該方法使用錨點來proposal區域,然后分析這些區域以識別目標。

另一種選擇是無錨(anchor-free)檢測器,它提供了一種無錨方法來進行目標檢測。他們使用其他策略來識別有目標的區域。新的、有前途的領域之一是使用基于Transformer的目標檢測器。這些基于 Visual Transformer 的算法于 2019 年出現,精度很高。然而,由于未針對某些平臺進行優化,它們在性能和計算能力方面存在局限性。盡管如此,這些算法的積極研究和優化已經在進行中。
基于Transformer的檢測器
現在我想提請你注意基于Transformer的目標檢測器的功能。例如,他們不使用非極大值抑制,我們稍后會討論這種方法。

基于 Transformer 的目標檢測器是一種使用 Visual Transformer 架構的算法。Visual Transformer 使用基于注意力機制的Transformer。注意力機制首次在2017年由 Vaswani 等人發表的Transformer 模型論文《Attention is All You Need》中引入,徹底顛覆了序列轉換任務。
Transformer 具有重復塊,主要基于自注意力機制,使其能夠捕獲輸入序列中不同位置之間的依賴關系。
這使得transformers成為文本處理中的強大工具,例如文本理解和文本生成。在文本處理領域取得成功之后,transformers也被用于計算機視覺領域,特別是目標檢測器。
視覺數據的處理方法是將圖像分成塊,然后使用transformers處理這些塊。與卷積網絡相比,這種方法極大地簡化了圖像處理。圖像塊被展平并被視為向量序列,由transformers依次處理。其輸出可用于各種任務,包括目標檢測。為了有效地處理向量,位置嵌入用于通過添加表示元素相對位置的位置編碼向量來將位置信息合并到向量中。
DETR (2020)
DETR 是一種端到端目標檢測模型,無需使用非極大值抑制即可直接預測圖像中對象的邊界框和類標簽。訓練此類算法需要使用有標注的訓練數據和適當的損失函數來優化模型的參數。

SWIN Transformer (2021)
2021年,引入SWIN(Shifted Windows)架構。SWIN Transformer背后的想法非常簡單。它使用 Visual Transformer 技術,將輸入圖像分割成patches,但 SWIN Transformer 主干類似于特征金字塔網絡。

SWIN 轉換器不是單獨處理每個patch,而是將輸入圖像劃分為patch網格,每個patch都有固定的大小,并在將它們組合成一個大特征向量之前獨立處理它們。這種方法增強了模型對空間關系的理解,改善了對象定位和分割結果。更新后的 SWIN Transformer v2 展示了在各種任務(例如目標檢測和實例分割)中改進的性能。
非極大值抑制 (NMS)

目標檢測的關鍵步驟之一是非極大值抑制(NMS)算法,該算法用于組合重疊的邊界框并獲得一個最終結果。
讓我們想象一下我們使用 YOLO 算法進行物體檢測的情況。處理圖像后,YOLO 返回 4 個邊界框。然而,事實證明所有這些邊界框都是重疊的。當選擇這些邊界框中的哪一個應該被認為是正確的時,就會出現問題。每個邊界框只能覆蓋對象的某個部分,但我們對整個對象及其確切位置感興趣。
目標檢測算法的發展經歷了幾個階段。Viola Jones 和 Haar 檢測器使用了一種稱為“貪婪選擇”的方法,但它并不是非極大值抑制 (NMS) 算法的具體組成部分。這種方法的想法是選擇所有重疊邊界框中最大的作為正確結果。然而,這種方法在檢測精度方面存在局限性。
另一種常見的技術是“邊界框聚合”。在此階段,所有邊界框根據特定原則進行組合,例如對邊界框中心的坐標進行平均或選擇最大或最小覆蓋值。特定方法的選擇取決于手頭的任務。
一般來說,目標是使用所有邊界框,同時通過聚合它們來保留信息。然而,應該記住,這種方法也有其缺點,特別是在使用不準確的邊界框時,可能會影響最終結果。
非極大值抑制 (NMS) 是在對象檢測模型生成邊界框預測后作為后處理步驟執行的。NMS 過濾掉多余的邊界框,僅選擇最有信心且不重疊的框作為最終輸出。
還有一些不依賴于最大抑制的無 NMS 檢測器,例如 DETR。這些檢測器立即返回每個單獨目標的邊界框,從而減少檢測后額外步驟的需要。例如,CenterNet 是一個返回關鍵點的簡單架構,無需 NMS。每個對象都由一個關鍵點和定義邊界矩形的距離寬度表示。
(Zero|One|Few)-Shot Object Detection
在目標檢測算法的開發中,我們正在慢慢轉向few、one、zero-shot的目標檢測的主題。在本節中,我們將較少關注技術細節,而更多地關注更高層次,提供如何執行零樣本目標檢測的想法的簡單描述。
多模態

這種情況下的關鍵概念是多模態,這意味著神經網絡可以同時理解多種類型的數據。例如,可以是圖像和文本、圖像和聲音、文本和聲音的組合,甚至可以是圖像、文本和聲音同時存在。
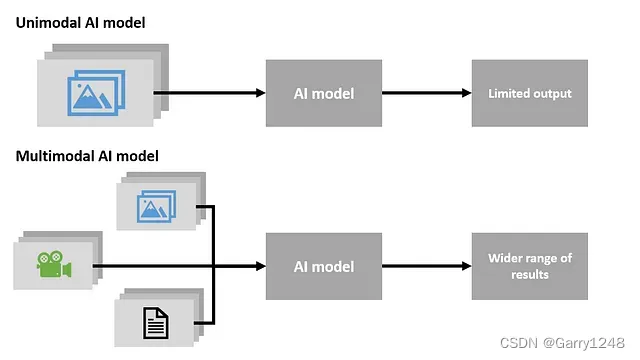
在這種方法中,我們有多個輸入信號,每個信號都由相應的模塊處理。在我們的例子中,這包括一個用于文本處理的單獨模塊、一個用于圖像處理的單獨模塊和一個用于音頻處理的單獨模塊。這些模塊形成一個從頭到尾工作的單一神經網絡,稱為端到端架構。
接下來,使用融合模塊。它們可能有不同的名稱,但它們執行相同的功能——它們組合圖像、文本和音頻特征并對它們執行某些操作。例如,他們可能會尋找與文本特征向量最相似的圖像特征向量。這和CLIP架構的原理類似,我們稍后會講到。
CLIP (2021)
CLIP添加了圖像-文本連接來理解圖像的內容。
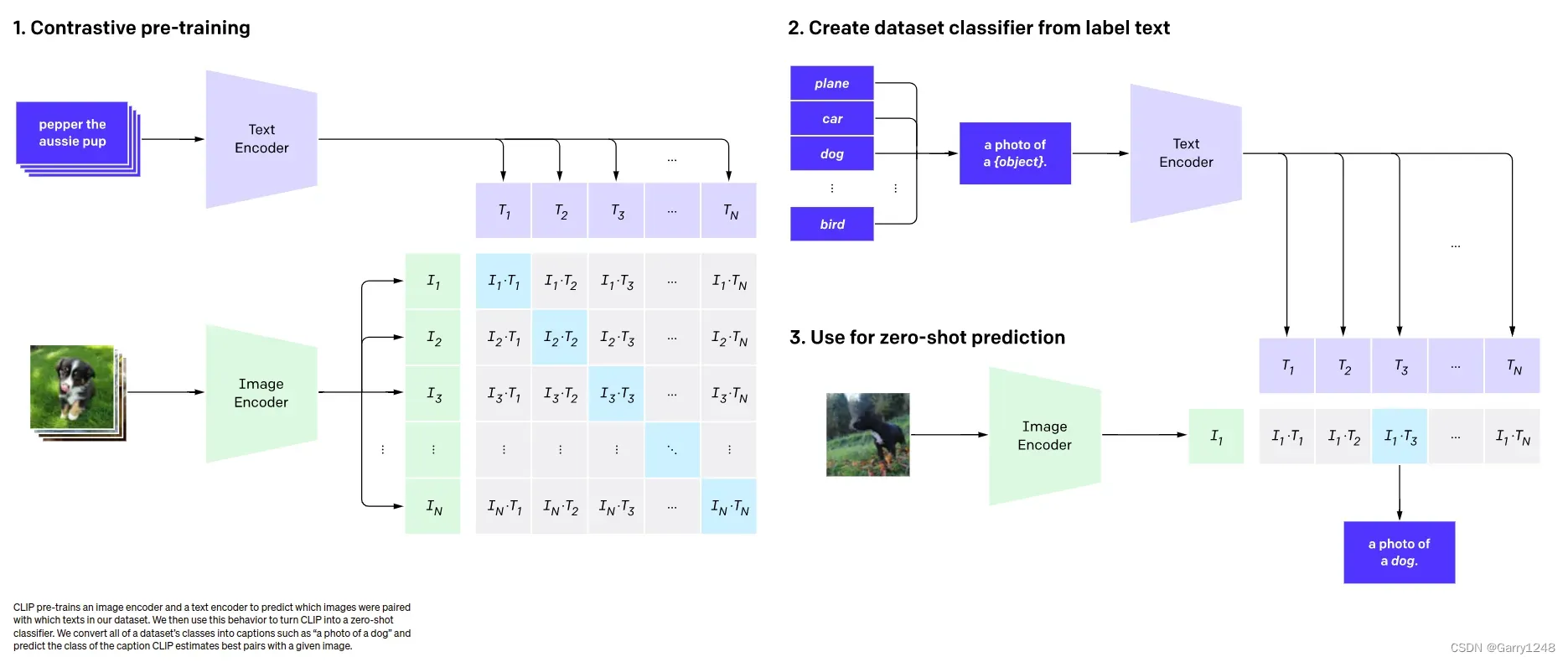
CLIP 是一項革命性的發展。CLIP 背后的主要思想是它在圖像和文本之間建立聯系,以更好地理解圖像的上下文。CLIP 使用兩種模型——TextEncoder 和 ImageEncoder。這些模型中的每一個都將數據轉換為向量格式。
CLIP 在由文本-圖像對組成的數據集上進行訓練,每對都包含文本描述和相應的圖像。在訓練過程中,模型嘗試找到 TextEncoder 和 ImageEncoder 參數,以便使得文本和圖像獲得的向量彼此相似。目標是讓其他文本描述的向量與目標圖像向量不同。
當使用 CLIP 進行零樣本目標檢測時,我們可以提供圖像以及與我們想要在圖像中查找的對象相關的單詞或短語列表。例如,如果我們有一張狗的圖像,我們可以使用 TextEncoder 創建一個帶有文本“狗的照片”的向量。然后,我們將該向量與為單詞或短語列表中的每個文本獲得的向量進行比較。與圖像向量距離最小的文本表示與圖像對應的對象。
因此,我們可以使用 CLIP 對圖像中的目標進行分類,即使無需在包含目標的特定數據集上單獨訓練模型。這種方法為在目標檢測領域應用 CLIP 開辟了廣泛的可能性,我們可以利用文本和圖像之間的關系來查找圖像中的對象。
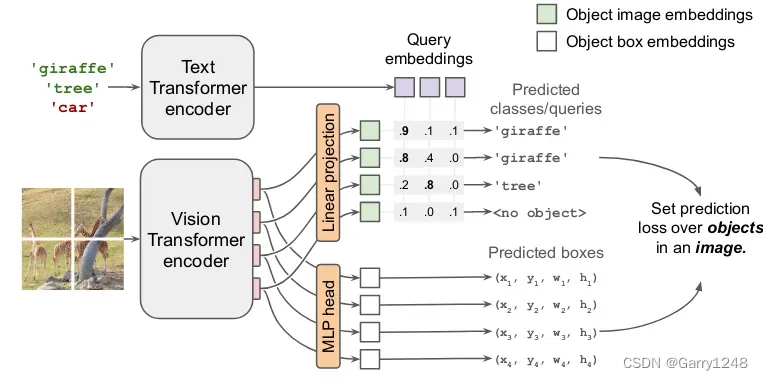
OWL-ViT (2022)
OWL-ViT 添加圖像級patches來了解目標的位置。

2022 年,研究者引入了一種新的多模態架構 OWL-ViT,用于目標檢測。該網絡可在 Hugging Face 平臺上使用,引起了研究和實踐社區的極大興趣。其基本思想是創建圖像和文本的嵌入,然后比較這些嵌入。圖像通過 Vision Transformer 進行處理,生成一組嵌入。然后,Vision Transformer 將自注意力和前饋網絡應用于這些嵌入。盡管某些步驟可能看起來令人困惑,但實際上它們有助于提高模型的質量。
最后,在訓練階段,使用對比損失函數來鼓勵相應的圖像-文本對具有相似的嵌入,而不對應的圖像-文本對具有不同的嵌入。該模型預測邊界框以及特定文本嵌入應用于特定對象的概率。
應該注意的是,目標檢測的準確性可能是有限的。原始模型的作者使用了基于二分匹配損失在帶有目標檢測數據集的預訓練模型進行微調的過程。此過程有助于提高檢測到的邊界框的質量。有關此過程的更多信息如下圖所示。
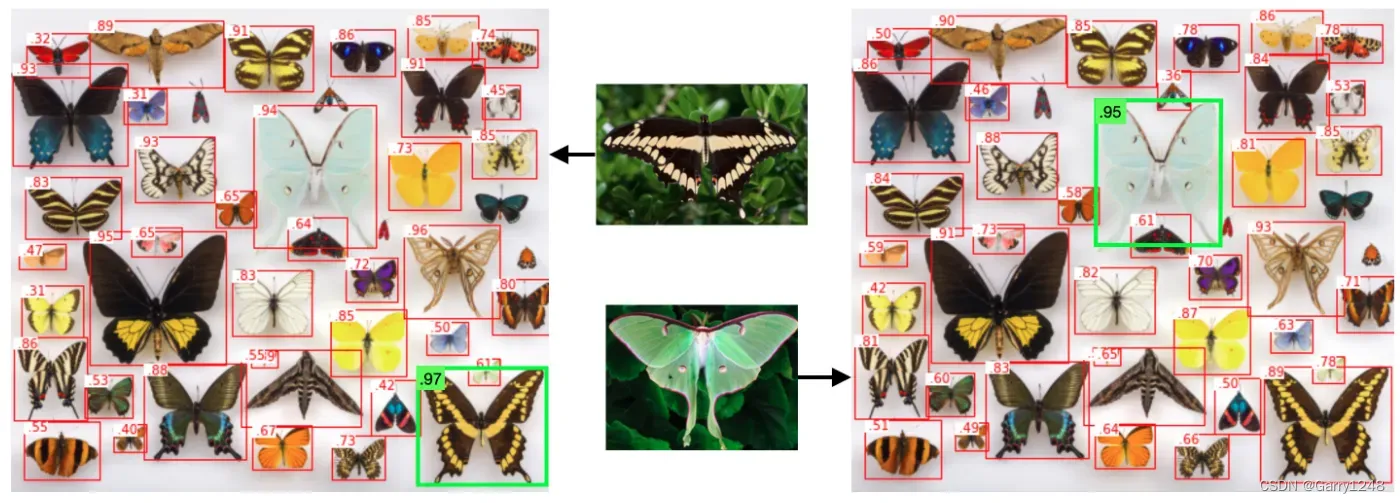
現在讓我們看看這個多模態模型的額外特征。除了文本之外,您還可以使用圖像作為模板。例如,如果您有一張蝴蝶的照片,您可以將其用作搜索查詢并查找類似的圖像。該模型能夠根據共同屬性分析文本和圖像。
GLIP (2022)
GLIP 添加了單詞級別的理解,以根據提示的語義查找對象。

GLIP (2022) 更進一步,提供對圖像的洞察以區分其語義。讓我們用一個例子來說明這一點。假設我們有一個關于一個拿著吹風機、戴著眼鏡的女人的句子。與此同時,我們看到一張圖像,顯示該女子戴著吹風機和眼鏡。GLIP 將對象檢測重新表述為短語基礎。通過接受圖像和文本提示作為輸入,它可以識別諸如人、吹風機等實體。
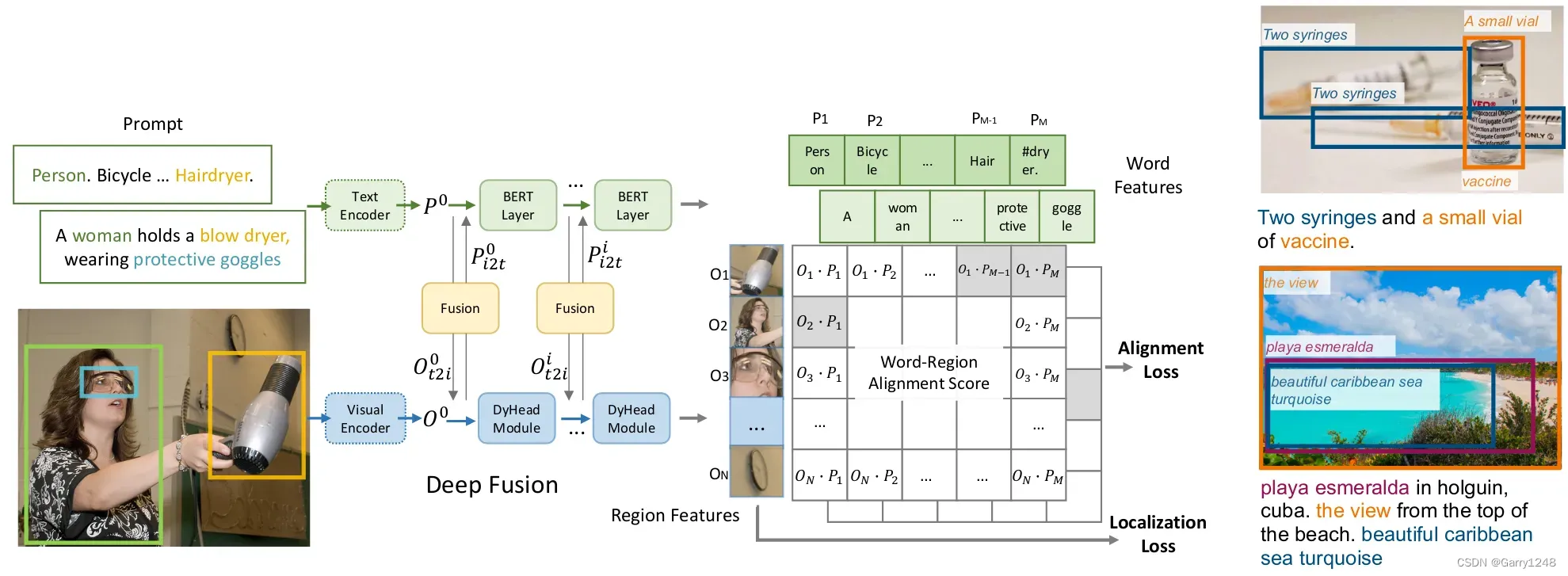
該技術提供了一種根據圖像與文本提示的語義對應關系來查找圖像中的目標的新方法。現在,我們不僅要識別目標,還要將文本的各個部分與圖像的組成部分關聯起來。
即使您只提供目標的名稱,例如“Stingray”,GLIP 也能夠找到它,但精度可能較低。但是,如果您添加描述,例如“比目魚”,它將提供額外的上下文并幫助你了解你正在尋找的內容。值得注意的是,在使用 ChatGPT 和現代零樣本目標檢測方法時,“提示工程”非常重要。

Segment Anything (2023)
Segment Anything (SAM) 添加masks來查看對象的像素級位置。
該算法于 2023 年推出,不僅可以檢測圖像中的對象,還可以通過在像素級別應用mask來分割它們。
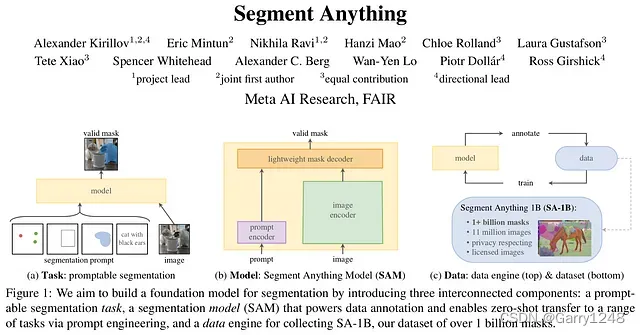
Segment Anything 的主要功能之一是它使用圖像和提示編碼器來創建整體圖像嵌入,可用于根據提示分割圖像。這些提示可以是空間提示、文本提示或兩者的組合。例如,您可以輸入“人”作為文本提示,算法將努力分割圖像中與人相關的所有對象。
這不僅可以讓你分割圖像中的不同區域,還可以了解場景的布局和內容。使用算法生成的分割掩碼,在適當的后處理步驟的情況下,人們可以潛在地執行諸如計算對象實例數量之類的任務。

GVT (2023)
Good Visual Tokenizers (GVT) 是一種新的多模態大型語言模型 (MLLM),涉及visual tokenizer,并通過適當的預訓練方法進行了優化。該tokenizer有助于理解視覺數據的語義和細粒度方面。
GVT 添加了大語言模型的使用來研究帶有文本的圖像。

GVT 在大型語言模型中引入了優化的visual tokenizer,可以對圖像以及相關文本進行更全面的研究。雖然將這些算法應用于醫學圖像等特定領域可能需要額外的研究,但 GVT 已經在涉及視覺問答、image caption和細粒度視覺理解任務(例如目標計數和多類識別)的任務中展示了卓越的性能。
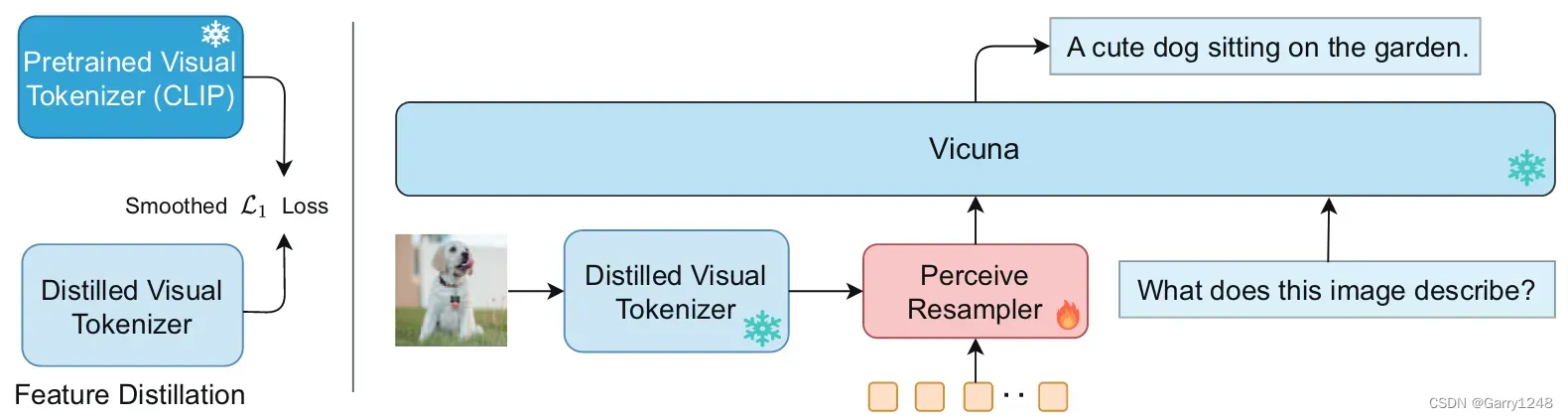
將文本和圖像集成到一個模型中可以擴展數據理解和處理能力。通過使用上述算法,可以在解決以前需要復雜算法和大量數據的各種任務方面取得重大進展。
總結一下零樣本目標檢測:
- CLIP添加了圖像-文本連接來理解圖像的內容。
- OWL-ViT 添加圖像級補丁來了解對象的位置。
- GLIP 添加了單詞級別的理解,以根據提示的語義查找對象。
- SAM 添加掩模來查看對象的像素級位置。
- GVT 添加了大語言模型的使用來研究帶有文本的圖像。
結論
總之,從計算機視覺的早期到當前最先進的深度學習技術,目標檢測算法的演變是一段非凡的旅程。我們已經從 Viola-Jones 檢測器和 HOG 檢測器等傳統方法過渡到 RCNN、YOLO、SSD 和 CenterNet 等更先進的方法,這些方法引入了端到端架構以提高適應性。然而,最具突破性的飛躍是零樣本目標檢測方法,如 OWL-ViT、GLIP、Segment Anything 和 GVT。這些創新技術使我們能夠檢測圖像中的物體,而無需進行大量的神經網絡訓練,從而開啟了物體檢測領域的新時代。
本博文譯自Andrii Polukhin 的系列博文。






)


 on i.MX RT1060 EVK - 3 “編譯 NXP i.MX RT1060”( 完 ))

】解線性代數方程組的迭代法(一):向量、矩陣范數與譜半徑【理論到程序】)




)
)

