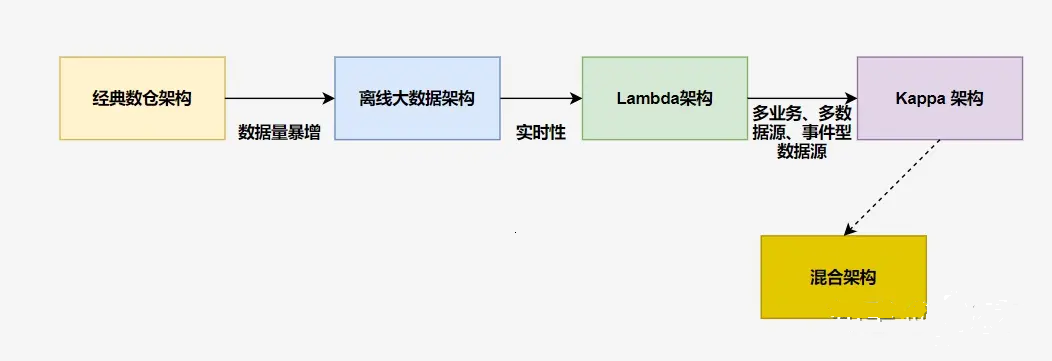
前言:我們先了解一下數據倉庫架構的演變過程。
1 、數據倉庫定義
數據倉庫是一個
面向主題的(Subject Oriented)、集成的(Integrate)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的數據集合,用于支持管理決策。
數據倉庫概念是 Inmon 于 1990 年提出并給出了完整的建設方法。隨著互聯網時代來臨,數據量暴增,開始使用?大數據工具?來替代經典數倉中的傳統工具。此時僅僅是工具的取代,架構上并沒有根本的區別,可以把這個架構叫做離線大數據架構
后來隨著業務實時性要求的不斷提高,人們開始在?離線大數據架構?基礎上加了一個加速層,使用流處理技術直接完成那些實時性要求較高的指標計算,這便是 Lambda 架構。
再后來,實時的業務越來越多,事件化的數據源也越來越多,實時處理從次要部分變成了主要部分,架構也做了相應調整,出現了以實時事件處理為核心的 Kappa 架構。
2、數據倉庫ETL
ETL全稱 Extract-Transform-Load,是企業數據應用過程中的一個數據流(pipeline)的控制技術,它是將大量的原始數據經過提取(extract)、轉換(transform)、加載(load)到目標存儲數據倉庫的過程。? ??ETL一詞較常用在數據倉庫,但其對象并不限于數據倉庫?。
ETL負責將分散的、異構數據源中的數據抽取到臨時中間層后進行清洗、轉換、集成,最后加載到數據倉庫或數據集市中。ETL 是實施數據倉庫的核心和靈魂,ETL規則的設計和實施約占整個數據倉庫搭建工作量的 60%~80%。
常見的ETL工具有Kettle,中文名稱叫水壺,該項目的概念是把各種數據放到一個壺里,然后以一種指定的格式流出。Kettle是一款國外開源的ETL工具,純java編寫,可以在Window、Linux、Unix上運行,無需安裝,數據抽取高效穩定。 Kettle這個ETL工具集,它允許你管理來自不同數據庫的數據,通過提供一個圖形化的用戶環境來描述你想做什么。Kettle中有兩種格式文件,Transformation和Job,Transformation完成針對數據的基礎轉換,Job則完成整個工作流的控制。
(1)數據提取 extract
抽取(Extract)主要要是針對各個業務系統及不同服務器的分散數據,充分理解數據定義后,規劃需要的數據源及數據定義,制定可操作的數據源,制定增量抽取和緩慢漸變的規則。
在提取階段,解決的是數據來源問題。主要有以下幾種:
-
業務數據
在我們企業運行過程中,會有一些用戶的交易數據,如用戶的購買訂單、退款退貨、用戶發布的視頻、用戶的注冊信息等等,這些都存在我們的業務數據庫里,這些數據庫通常是關系型數據庫,這是我們獲取數據的一個重要來源。 -
文件數據
還有一些數據是有文件的形式存在,比如我們服務器運行的 log,它記錄了用戶對網站的請求情況,再比如我們通過埋點收集的日志文件,記錄了用戶的交互。 -
第三方數據
通過第三方購買或者合作形式信用的數據,這些數據可以作為我們業務分析的補充數據。這些數據一般通過和第三方機構的接口(API)形式,對接傳輸過來。三方的來源、數據形式格式可能有多種多樣,就需要我們分別進行對接處理。
數據的格式和形式一般有以下幾種:
-
關系型數據庫 SQL,RDBMS
-
文件型數據庫 NoSQL
-
日志文件
-
XML/Html
-
JSON
-
CSV/TSV(flat files)
Staging Area 為緩存區,在數據加載后進行處理時,將過程中的結果暫時存放起來,有些計算需要一定的硬件資源和時間,設定緩沖區可以對 ETL 有很大有幫助。
提取是把多種多樣的原格式數據抽象出來,形成統一的數據格式先放入緩存區,不會直接進入數據倉庫,等待下一步轉換操作。
(2)數據轉換 transform
轉換 transform主要為了將數據清洗后的數據轉換成數據倉庫所需要的數據:來源于不同源系統的同一數據字段的數據字典或者數據格式可能不一樣(比如A表中叫id,B表中叫ids),在數據倉庫中需要給它們提供統一的數據字典和格式,對數據內容進行歸一化;另一方面,數據倉庫所需要的某些字段的內容可能是源系統所不具備的,而是需要根據源系統中多個字段的內容共同確定。
這個階段是ETL的核心環節,也是最復雜的環節。它的主要目標是將抽取到的各種數據,進行數據的清洗、格式的轉換、缺失值填補、剔除重復等操作,最終得到一份格式統一、高度結構化、數據質量高、兼容性好的數據,為后續的分析決策提供可靠的數據支持。
根據我們的商業需要,我們用一些規則、方法進行數據處理。一般常見的轉換操作有:
-
篩選:篩選部分數據,或者部分字段,提取一部分有用的數據
-
清理:主要是針對源數據庫中出現的二義性、重復、不完整、違反業務或邏輯規則等問題的數據進行統一的處理,即清洗掉不符合業務或者沒用的的數據。比如通過編寫hive或者MR清洗字段中長度不符合要求的數據。缺失值填充、默認值設定、枚舉映射等,如將一些編碼轉為可識別的符號,比如省份代碼 sh 轉為「上海」
-
合并:將多個屬性合并在一起
-
格式轉換:,如原數據是一下個時間戳(timestamp),我們為了方便后續分析轉換為時間格式,指定時區
-
拆分:將單個屬性值拆分為多個屬性值,如原為一個郵編,拆分解析成省份、城市等多個字段
-
排序:按期望的數據順序進行排列
-
計算:如原數據為年齡,用當前年份減去年齡同,取得出生年份
原則:
-
建數倉時盡量保留原始數據,支持多樣需求
-
為特定報表時盡量取所需要的數據
(3)數據加載 load
數據加載 load主要是將經過轉換的數據裝載到數據倉庫里面,以方便給數據集市提供。通常的做法是,將處理好的數據寫成特定格式(如parquet、csv等)的文件,然后再把文件掛載到指定的表分區上。也有些表的數據量很小,不會采用分區表,而是直接生成最終的數據表。
數據的加載方式一般有以下兩種重要類型:
-
全量加載(Full load / Bulk load)
-
增量加載(Incremental load / Refresh load)
全量一般是第一次進行數據加載,這個過程比較長,也有種情況是業務數據存在歷史全量數據不停更新的情況,這種情況無論何時都需要全量加載。還有一種情況會追溯一定的時間周期內的數據進行加載,如此業務30天之前的數據不會有再任何變化。
增加加載最為常見,一般一日加載一次,加載上一日數據,也有一周或者一月加載一次的。
加載數據是數據進入數據倉庫的最后一步,加載是依賴提取和轉換的,因此,加載數據是一個完整的 ETL 過程,這個過程需要大量的數據流轉加工時間,而且是周期性重復的工作,所以一般由系統自動完成,執行時間為業務一個最小周期——日(實時數倉會選擇更小的時間粒度,如10分鐘一次),同時選擇業務量小的凌晨進行。
備注:
-
一些小型的數據項目、數據報表也伴隨著完整的 etl 過程
-
有時需要實時的 ETL,如推薦、金融反欺詐、反垃圾
3、數據倉庫分層模型
數倉分層模式是數據倉庫設計中一個十分重要的環節,良好的分層設計能夠讓整個數據體系更容易被理解和使用。
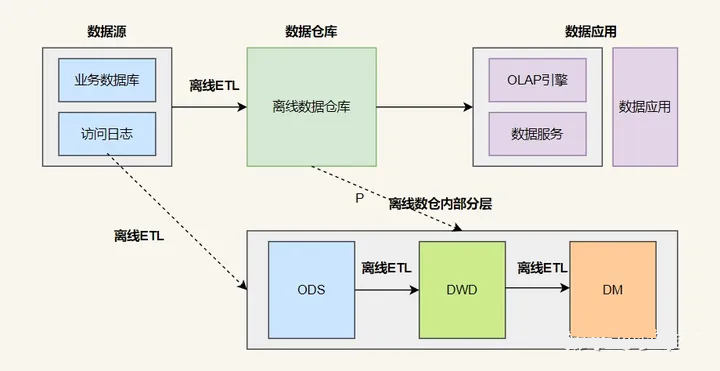
數據倉庫從模型層面分為三層:
ODS,操作數據層,保存原始數據;
DWD,數據倉庫明細層,根據主題定義好事實與維度表,保存最細粒度的事實數據;
DM,數據集市/輕度匯總層,在 DWD 層的基礎之上根據不同的業務需求做輕度匯總;
如果要細分,分為4層:

-
ODS 層: Operation Data Store,數據準備區,貼源層。直接接入源數據的:業務庫、埋點日志、消息隊列等。 -
DWD 層:? Data Warehouse Details,數據明細層,屬于業務層和數據倉庫層的隔離層,保持和 ODS 層相同顆粒度。進行數據清洗和規范化操作,去空值/臟數據、離群值等。 -
DWS 層:??Data warehouse service,數據服務層,在 DWM 的基礎上,整合匯總一個主題的數據服務層。匯總結果一般為寬表,用于 OLAP、數據分發等。 -
ADS 層:? Application data service, 數據應用層。其主要功能是保存結果數據,為外部系統提供查詢接口,基于數據倉庫的數據為企業提供增值應用,并將數據倉庫的數據應用于企業決策、報表、分析、控制等領域。ADS層通常采用OLAP(Online Analytical Processing)技術,用于快速訪問和查詢數據。ADS層一般包括多個寬表,用于支持與企業應用有關的查詢、分析、報告、控制、決策等操作。這些寬表一般可以通過BI工具或自定義應用程序查詢和訪問,以滿足企業的各種數據需求。為了提高訪問和查詢速度,ADS層通常使用數據索引、緩存和預聚合等技術。有時為了更好地管理和維護數據倉庫,可以將ADS層從數據倉庫中獨立出去,成為一個獨立的數據集市層(Data Mart)。數據集市層專門為某一特定業務需求而建立,可以基于某一個特定的主題或者某個業務領域建模,以滿足該領域的數據分析和查詢需求。
數倉分層模型的優點:
-
劃清層次結構:每一個數據分層都有它的作用域,這樣我們在使用表的時候能更方便地定位和理解。
-
數據血緣追蹤:簡單來講可以這樣理解,我們最終給下游是直接能使用的業務表,但是它的來源有很多,如果有一張來源表出問題了,我們希望能夠快速準確地定位到問題,并清楚它的危害范圍。
-
減少重復開發:規范數據分層,開發一些通用的中間層數據,能夠減少極大的重復計算。
-
把復雜問題簡單化。將一個復雜的任務分解成多個步驟來完成,每一層只處理單一的步驟,比較簡單和容易理解。而且便于維護數據的準確性,當數據出現問題之后,可以不用修復所有的數據,只需要從有問題的步驟開始修復。
-
屏蔽原始數據的異常。屏蔽業務的影響,不必改一次業務就需要重新接入數據。
4、數據中臺的內容
數據中臺是一套可持續“讓企業的數據用起來”的機制,一種戰略選擇和組織形式,是依據企業特有的業務模式和組織架構,通過有形的產品和實施方法論支撐,構建一套持續不斷把數據變成資產并服務于業務的機制。
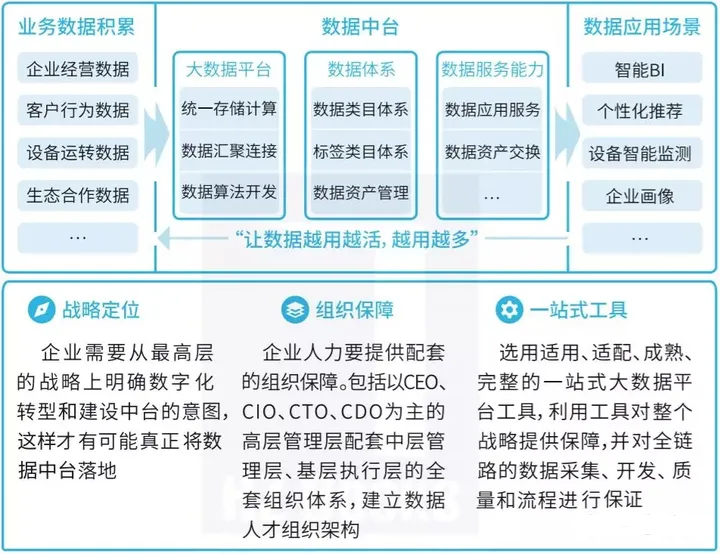
數據中臺包含的內容很多,對應到具體工作中的話,它可以包含下面的這些內容:
-
系統架構:以Hadoop、Spark等組件為中心的架構體系
-
數據架構:頂層設計,主題域劃分,分層設計,ODS-DW-ADS
-
數據建模:維度建模,業務過程-確定粒度-維度-事實表
-
數據管理:資產管理,元數據管理、質量管理、主數據管理、數據標準、數據安全管理
-
輔助系統:調度系統、ETL系統、監控系統
-
數據服務:數據門戶、機器學習數據挖掘、數據查詢、分析、報表系統、可視化系統、數據交換分享下載
參考鏈接:
從ODS到ADS,詳解數倉分層!





)


 on i.MX RT1060 EVK - 3 “編譯 NXP i.MX RT1060”( 完 ))

】解線性代數方程組的迭代法(一):向量、矩陣范數與譜半徑【理論到程序】)




)
)


