簡介:DialoGPT是一個對話模型,由微軟基于GPT-2訓練。由于DialoGPT在對話數據上進行了預訓練,所以它比原始的GPT-2更擅長生成類似對話的文本。DialoGPT的主要目標是生成自然且連貫的對話,而不是在所有情況下都提供事實上的正確答案。此外,由于模型的預訓練數據主要是英文,因此它可能無法很好地處理中文輸入。在運行代碼之前,請確保已經安裝了Hugging Face的Transformers庫。
歷史攻略:
OpenCV合成全景圖
Python+opencv:圖像修復
flask+opencv+實時濾鏡(原圖、黑白、懷舊、素描)
flask+opencv:實時視頻直播推流平臺Demo
安裝:
pip install transformers
案例源碼:
# -*- coding: utf-8 -*-
# time: 2023/6/9 14:00
# file: test.py
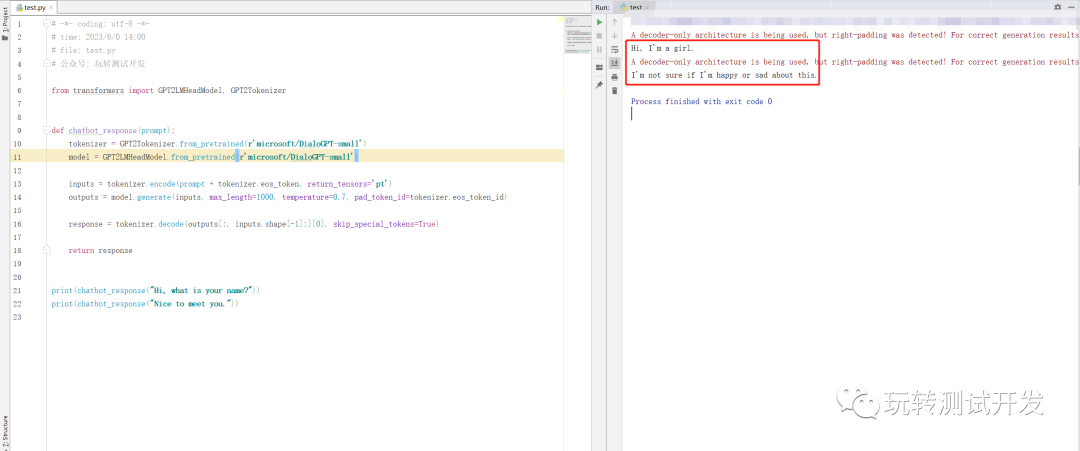
# 公眾號: 玩轉測試開發from transformers import GPT2LMHeadModel, GPT2Tokenizerdef chatbot_response(prompt):tokenizer = GPT2Tokenizer.from_pretrained('microsoft/DialoGPT-small')model = GPT2LMHeadModel.from_pretrained('microsoft/DialoGPT-small')inputs = tokenizer.encode(prompt + tokenizer.eos_token, return_tensors='pt')outputs = model.generate(inputs, max_length=1000, temperature=0.7, pad_token_id=tokenizer.eos_token_id)response = tokenizer.decode(outputs[:, inputs.shape[-1]:][0], skip_special_tokens=True)return responseprint(chatbot_response("Hi, what is your name?"))
print(chatbot_response("Nice to meet you."))
運行效果:


)











)




