沉淀,沉淀,再沉淀.👩🏻?💻作者:chlorine
👉上一篇:string標準庫成員函數和非成員函數(上)
目錄
🍭構造和析構的實現?
🍭 string→c類型的字符串數組
🍭operator[]類對象元素的訪問
🍭返回字符串的長度
🍭迭代器進行遍歷訪問字符串
👉增
?append() 與 push_back()
?reserve()擴容
??operator+=()復用
👉刪
?erase
👉插
?insert()
👉找
?find()
?獲得子串substr()?
🍭改變字符串長度?
🍭流插入<<流提取>>
?clear?
🍭比較字符串大小?
🍭字符串賦值?
?operator()
??swap()?
💻總代碼
🚩string.h?
🚩test.cpp
?從上一篇我們了解了string標準庫成員函數和非成員函數的了解,這一章我們繼續學習string標準庫中剩余的成員函數和非成員函數。
這一次我們模擬類實現對字符串的增刪查改,在此之前我們設定一個命名空間cl,不用std命名空間。我們可以在測試的時候與std命名空間進行對比,看是否出現問題。
#include<iostream>
#include<string>
using namespace std;namespace cl
{class string{};
}🍭構造和析構的實現?
 我們得開一個_size大小空間的字符串,進行初始化,可以選擇在函數體內賦值或者初始化列表進行初始化,為了沒有順序的思考,我們就直接在函數體內初始化吧。
我們得開一個_size大小空間的字符串,進行初始化,可以選擇在函數體內賦值或者初始化列表進行初始化,為了沒有順序的思考,我們就直接在函數體內初始化吧。
#pragma once#include<iostream>
#include<assert.h>
#include<string>
using namespace std;namespace cl
{class string{public:string(const char* str=" "){_size = strlen(str);_capacity = _size;_str = new char[_capacity + 1];memcpy(_str, str, _size + 1);}~string(){delete[] _str;_size = _capacity = 0;}private:char* _str;size_t _size;size_t _capacity;};
}🍭 string→c類型的字符串數組

c_str()就是將C++的string轉化為C的字符串數組,c_str()生成一個const char *指針,指向字符串的首地址。
const char* c_str() const{return _str;}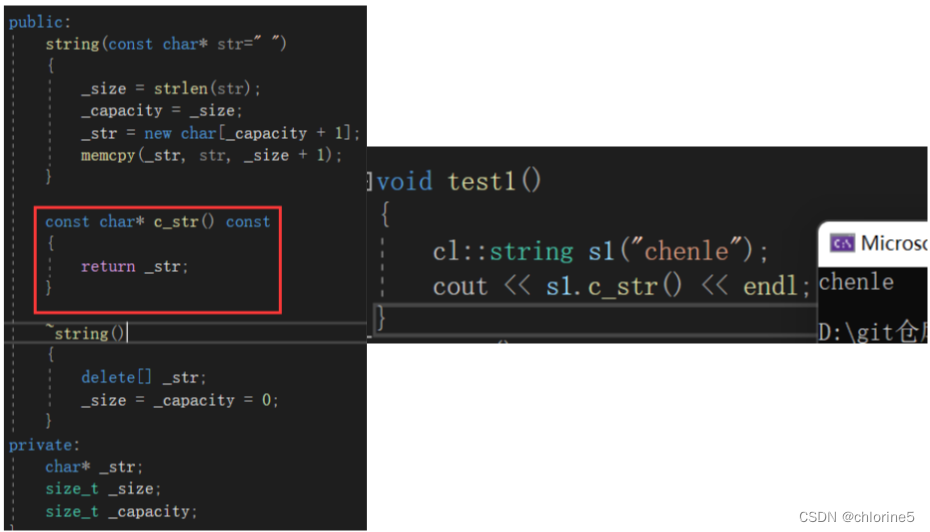
因為我們還沒寫流插入和流提取的函數,所以我們必須調用c_str()成員函數,c_str()函數返回一個指向正規C字符串的指針常量,內容與本string串相同。這是為了與C語言兼容,在C語言中沒有string類型,故必須通過string類對象的成員函數c_str()把string對象轉換成C中的字符串樣式。
🍭operator[]類對象元素的訪問

char& operator[] (size_t pos){assert(pos < _size);return _str[pos];}const char& operator[] (size_t pos) const{assert(pos < _size);return _str[pos];}
🍭返回字符串的長度

size_t size() const{return _size;}
🍭迭代器進行遍歷訪問字符串
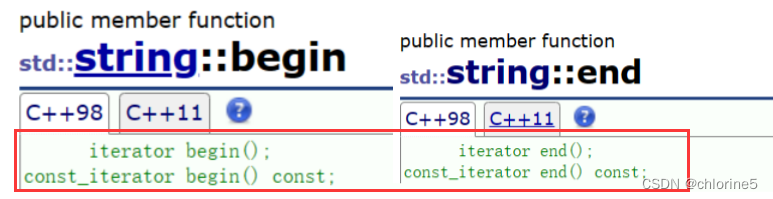
typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}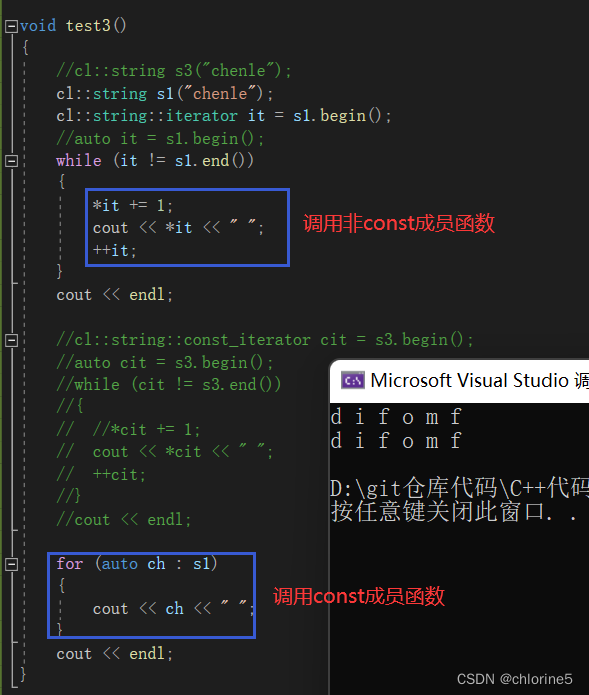
大家可以通過調試深入了解一下即可。?
現在我們進入類中字符串的增刪查改函數的操作
👉增
?append() 與 push_back()

這里需要寫個擴容函數reserve()
?reserve()擴容

void reserve(size_t n = 0){if (n > _capacity){char* tmp = new char[n + 1];//開辟一個n個空間memcpy(tmp, _str, _size + 1);//將_str里面字符拷貝給tmpdelete[] _str;//銷毀_str_str = tmp;//然后將tmp字符串賦值給_str_capacity = n;}}//增加字符void push_back(char c){if (_size == _capacity){//2倍擴容reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = c;++_size;_str[_size] = '\0';}//增加字符串
void append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){// 至少擴容到_size + lenreserve(_size + len);}memcpy(_str + _size, str, len + 1);_size += len;}??operator+=()復用
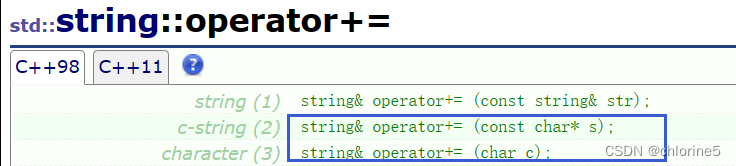
string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}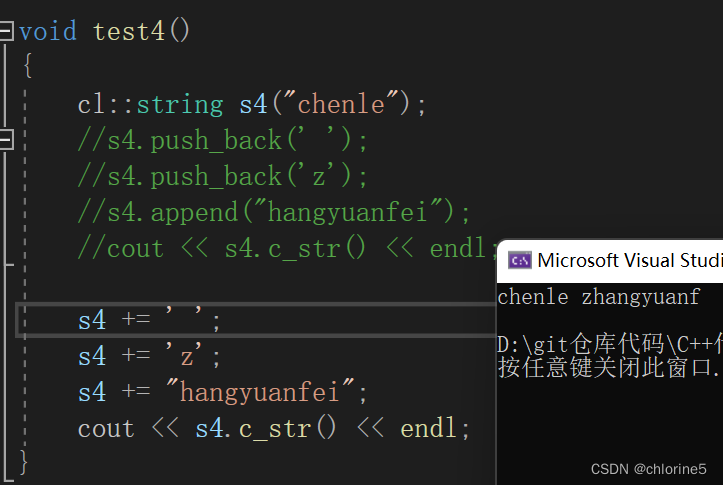
👉刪
?erase
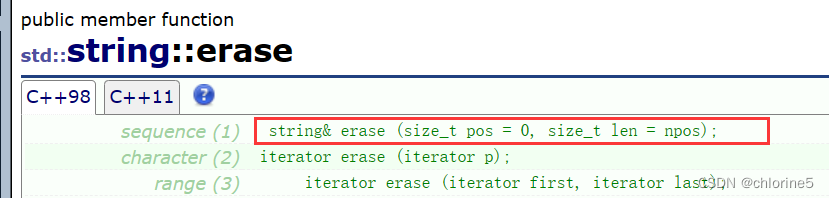
//刪void erase(size_t pos = 0, size_t len = npos)//刪除從pos開始的len長度{assert(pos <= _size);//刪的結束位置>=截至位置就直接給最后截至位置結束if (len == npos || pos + len >= _size){_str[pos] = '\0';//直接給pos位置置'\0'_size = pos;_str[_size] = '\0';}else//刪除的結束位置<size,那么就得給end后面的值賦值給pos開始之后的{size_t end = pos + len;while (end <= _size){_str[pos++] = _str[end++];}_size -= len;}}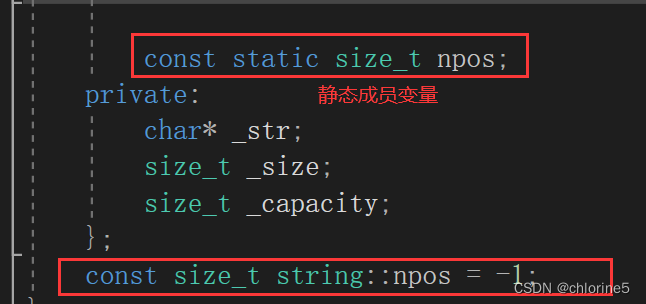
👉插
?insert()

void insert(size_t pos, size_t n, char ch)//在pos位置插入n個字符{assert(pos <= _size);//如果大于容量,就擴容if (_size + n > _capacity){reserve(_size + n);}//end所在的地方在字符串位置int end = _size;while (end >= (int)pos){_str[end + n] = _str[end];--end;}for (size_t i = 0; i < n; i++){_str[pos + i] = ch;}_size += n;}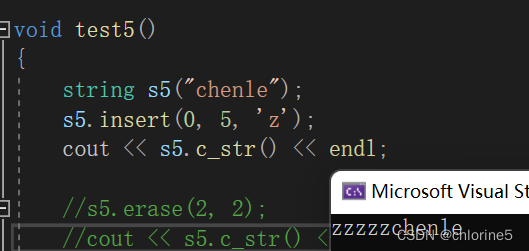
👉找
?find()

size_t find(char ch, size_t pos = 0)//從pos位置找到字符ch{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;}size_t find(const char* str, size_t pos = 0)//從pos位置找到字符串str{assert(pos < _size);const char* ptr = strstr(_str + pos, str);if (ptr){return ptr - _str;}else{return npos;}}
?獲得子串substr()?

string substr(size_t pos = 0, size_t len = npos)//從pos位置開始的len個字符的字串{assert(pos < _size);size_t n = len;if (len == npos || pos + len > _size){n = _size - pos;//子串長度}string tmp;//創建一個字串tmptmp.reserve(n);//字串的容量for (size_t i = pos; i < pos + n; i++){tmp += _str[i];//賦值}return tmp;}我們還是用這段代碼來測試。?
這里涉及了拷貝構造。
string(const string& s){_str = new char[s._capacity + 1];memcpy(_str, s._str, s._size + 1);_size = s._size;_capacity = s._capacity;}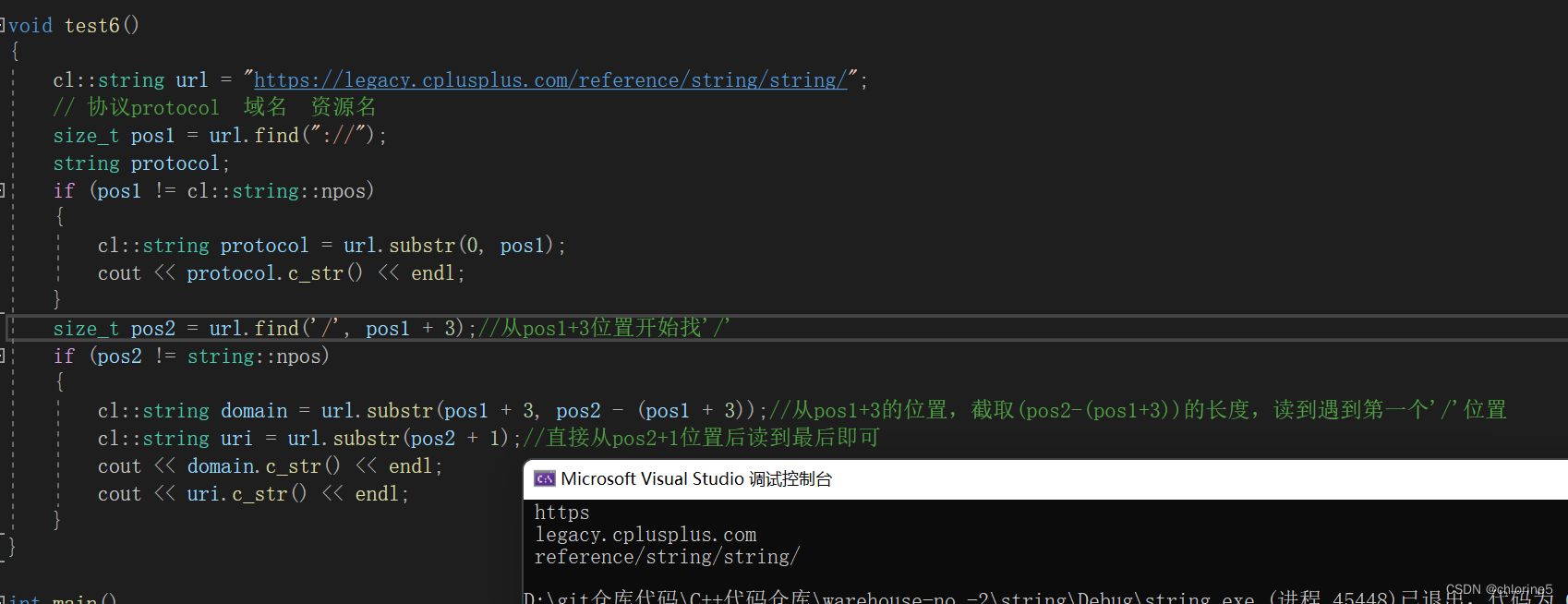
🍭改變字符串長度?

void resize(size_t n, char c = '\0'){if (n < _size){_size = n;_str[n] = '\0';}else{reserve(n);for (size_t i = _size; i < n; i++){_str[i] = c;}_size = n;_str[_size] = '\0';}}
🍭流插入<<流提取>>
我們在類外。

ostream& operator<<(ostream& out, const string& s){/*for (size_t i = 0; i < s.size(); i++){out << s[i];}*/for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){s.clear();char ch = in.get();// 處理前緩沖區前面的空格或者換行while (ch == ' ' && ch == '\n'){ch = in.get();//如果是空格和換行,直接跳過讀下一個}//給定一個局部數組127.為了防止過多的開空間如果string對象的容量大char buff[128];int i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 127){//如果i=127那么就將buff[127]置'\0'buff[127] = '\0';s += buff;i = 0;//將i置0重新開始}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;}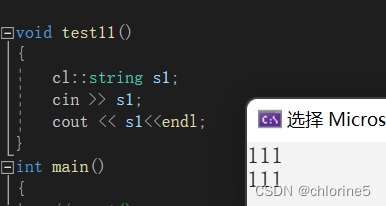 ?
?
?clear?

void clear(){_str[0] = '\0';_size = 0;}
🍭比較字符串大小?
//bool operator<(const string& s)//{// size_t s1 = 0;// size_t s2 = 0;// //先判斷字符對應的ascii碼值是否小于// while (s1 < _size && s2 < s._size)// {// if (_str[s1] < s._str[s2])// {// return true;// }// else if(_str[s1]>s._str[s2])// {// return false;// }// else// {// s1++;// s2++;// }// }// //結束循環之后說明有下面三種情況// "hello" "hello" false"helloxx" "hello" false"hello" "helloxx" true// return _size < s._size;//}bool operator<(const string& s)const{//先判斷字符的asscii值int ret = memcmp(_str, s._str, _size < s._size ? _size : s._size);//字符相等然后現在判斷長度問題//"hello" "hello" false"helloxx" "hello" false"hello" "helloxx" truereturn ret == 0 ? _size < s._size : ret < 0;}bool operator==(const string& s)const{return _size == s._size&& memcmp(_str, s._str, _size < s._size ? _size : s._size) == 0;}bool operator<=(const string& s)const{return (*this < s) || (*this == s);}bool operator>(const string& s)const{return !(*this <= s);}bool operator>=(const string& s)const{return (*this > s) || (*this == s);}bool operator!=(const string& s) const{return !(*this == s);}
🍭字符串賦值?
?operator()
傳統寫法:?
// s1 = s3//string& operator=(const string& s)//{// if (this != &s)// {// char* tmp = new char[s._capacity + 1];//創建新的字符串對象// memcpy(tmp, s._str, s._size+1);//然后拷貝// delete[] _str;//銷毀_str// _str = tmp;//將tmp賦值給_str// _size = s._size;//內置類型的值賦值給// _capacity = s._capacity;// }// return *this;//}??swap()?

現代寫法:?
//倆個對象進行交換,要將倆個對象的內置類型成員變量都得交換void swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//string& operator=(const string& s)//{// if (*this != s)// {// string tmp(s);// //this->swap(tmp);// swap(tmp);// }// return *this;//}string& operator=(string& s){//s1=s3swap(s);return *this;}💻總代碼
🚩string.h?
#pragma once#pragma once
#include<assert.h>
#include<string.h>
#include<iostream>
using namespace std;
namespace cl
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}//初始化//可以初始化列表//也可以函數體內賦值(這里更推薦后者)string(const char* str = ""){_size = strlen(str);_capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}const char* c_str() const{return _str;}const char& operator[] (size_t pos) const{assert(pos < _size);return _str[pos];}char& operator[] (size_t pos){assert(pos < _size);return _str[pos];}size_t size() const{return _size;}// s1 = s3//string& operator=(const string& s)//{// if (this != &s)// {// char* tmp = new char[s._capacity + 1];//創建新的字符串對象// memcpy(tmp, s._str, s._size+1);//然后拷貝// delete[] _str;//銷毀_str// _str = tmp;//將tmp賦值給_str// _size = s._size;//內置類型的值賦值給// _capacity = s._capacity;// }// return *this;//}//倆個對象進行交換,要將倆個對象的內置類型成員變量都得交換void swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//string& operator=(const string& s)//{// if (*this != s)// {// string tmp(s);// //this->swap(tmp);// swap(tmp);// }// return *this;//}string& operator=(string& s){//s1=s3swap(s);return *this;}void clear(){_str[0] = '\0';_size = 0;}~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}void reserve(size_t n = 0){if (n > _capacity){char* tmp = new char[n + 1];//開辟一個n個空間memcpy(tmp, _str, _size + 1);//將_str拷貝給tmpdelete[] _str;//銷毀_str_str = tmp;//然后將tmp字符串賦值給_str_capacity = n;}}void push_back(char c){if (_size == _capacity){//2倍擴容reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = c;++_size;_str[_size] = '\0';}void append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){// 至少擴容到_size + lenreserve(_size + len);}memcpy(_str + _size, str, len + 1);_size += len;}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}void insert(size_t pos, size_t n, char ch)//在pos位置插入n個字符{assert(pos <= _size);//如果大于容量,就擴容if (_size + n > _capacity){reserve(_size + n);}//end所在的地方在字符串位置int end = _size;while (end >= (int)pos){_str[end + n] = _str[end];--end;}for (size_t i = 0; i < n; i++){_str[pos + i] = ch;}_size += n;}void erase(size_t pos = 0, size_t len = npos)//刪除從pos開始的len長度{assert(pos <= _size);if (len == npos || pos + len >= _size){_str[pos] = '\0';//直接給pos位置置'\0'_size = pos;_str[_size] = '\0';}else{size_t end = pos + len;while (end <= _size){_str[pos++] = _str[end++];}_size -= len;}}size_t find(char ch, size_t pos = 0)//從pos位置找到字符ch{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;}size_t find(const char* str, size_t pos = 0){assert(pos < _size);const char* ptr = strstr(_str + pos, str);if (ptr){return ptr - _str;}else{return npos;}}string(const string& s){_str = new char[s._capacity + 1];memcpy(_str, s._str, s._size + 1);_size = s._size;_capacity = s._capacity;}string substr(size_t pos = 0, size_t len = npos)//從pos位置開始的len個字符的字串{assert(pos < _size);size_t n = len;if (len == npos || pos + len > _size){n = _size - pos;//子串長度}string tmp;//創建一個字串tmptmp.reserve(n);//字串的容量for (size_t i = pos; i < pos + n; i++){tmp += _str[i];//賦值}return tmp;}void resize(size_t n, char c = '\0'){if (n < _size){_size = n;_str[n] = '\0';}else{reserve(n);for (size_t i = _size; i < n; i++){_str[i] = c;}_size = n;_str[_size] = '\0';}}//bool operator<(const string& s)//{// size_t s1 = 0;// size_t s2 = 0;// //先判斷字符對應的ascii碼值是否小于// while (s1 < _size && s2 < s._size)// {// if (_str[s1] < s._str[s2])// {// return true;// }// else if(_str[s1]>s._str[s2])// {// return false;// }// else// {// s1++;// s2++;// }// }// //結束循環之后說明有下面三種情況// "hello" "hello" false"helloxx" "hello" false"hello" "helloxx" true// return _size < s._size;//}bool operator<(const string& s)const{//先判斷字符的asscii值int ret = memcmp(_str, s._str, _size < s._size ? _size : s._size);//字符相等然后現在判斷長度問題//"hello" "hello" false"helloxx" "hello" false"hello" "helloxx" truereturn ret == 0 ? _size < s._size : ret < 0;}bool operator==(const string& s)const{return _size == s._size&& memcmp(_str, s._str, _size < s._size ? _size : s._size) == 0;}bool operator<=(const string& s)const{return (*this < s) || (*this == s);}bool operator>(const string& s)const{return !(*this <= s);}bool operator>=(const string& s)const{return (*this > s) || (*this == s);}bool operator!=(const string& s) const{return !(*this == s);}const static size_t npos;private:char* _str;size_t _size;size_t _capacity;};const size_t string::npos = -1;ostream& operator<<(ostream& out, const string& s){/*for (size_t i = 0; i < s.size(); i++){out << s[i];}*/for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){s.clear();char ch = in.get();// 處理前緩沖區前面的空格或者換行while (ch == ' ' && ch == '\n'){ch = in.get();//如果是空格和換行,直接跳過讀下一個}//給定一個局部數組127.為了防止過多的開空間如果string對象的容量大char buff[128];int i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 127){//如果i=127那么就將buff[127]置'\0'buff[127] = '\0';s += buff;i = 0;//將i置0重新開始}ch = in.get();}if (i != 0){buff[i] = '\0';s += buff;}return in;}
};🚩test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
#include<iostream>
#include<string>
//構造函數
void test1()
{cl::string s1("chenle");cout << s1.c_str() << endl;cl::string s2;cout << s2.c_str() << endl;
}
//operator[]
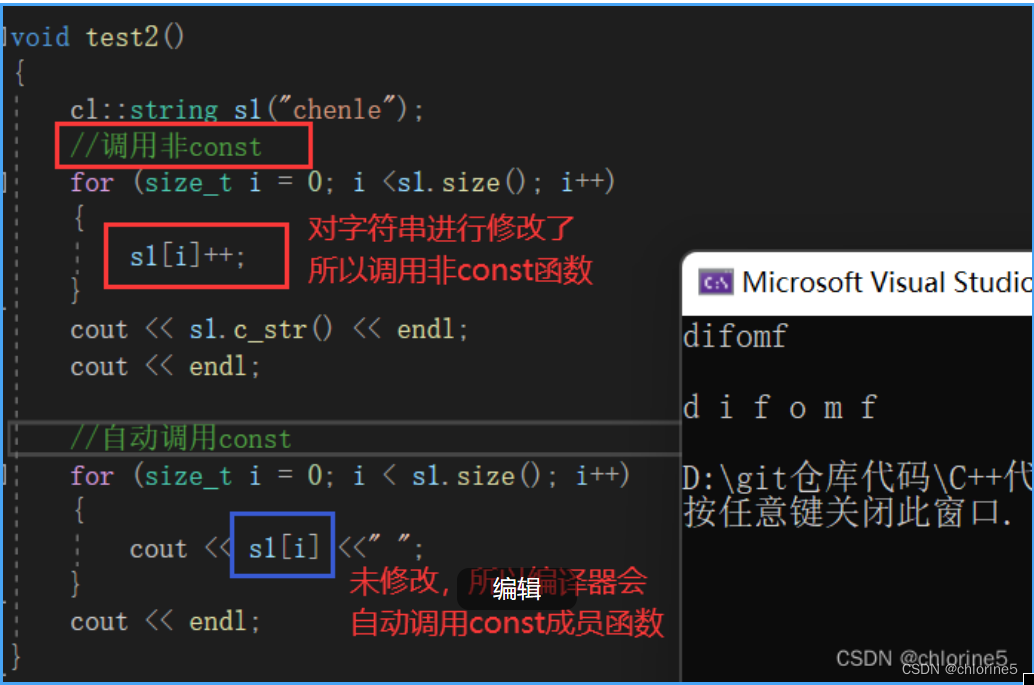
void test2()
{cl::string s1("chenle");//調用constfor (size_t i = 0; i < s1.size(); i++){s1[i]++;}cout << s1.c_str() << endl;cout << endl;//自動調用非constfor (size_t i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;
}void test3()
{//cl::string s3("chenle");cl::string s1("chenle");cl::string::iterator it = s1.begin();//auto it = s1.begin();while (it != s1.end()){*it += 1;cout << *it << " ";++it;}cout << endl;//cl::string::const_iterator cit = s3.begin();//auto cit = s3.begin();//while (cit != s3.end())//{// //*cit += 1;// cout << *cit << " ";// ++cit;//}//cout << endl;for (auto ch : s1){cout << ch << " ";}cout << endl;
}void test4()
{cl::string s4("chenle");//s4.push_back(' ');//s4.push_back('z');//s4.append("hangyuanfei");//cout << s4.c_str() << endl;s4 += ' ';s4 += 'z';s4 += "hangyuanfei";cout << s4.c_str() << endl;
}void test5()
{string s5("chenle");//s5.insert(0, 5, 'z');cout << s5.c_str() << endl;s5.erase(2, 5);cout << s5.c_str() << endl;
}
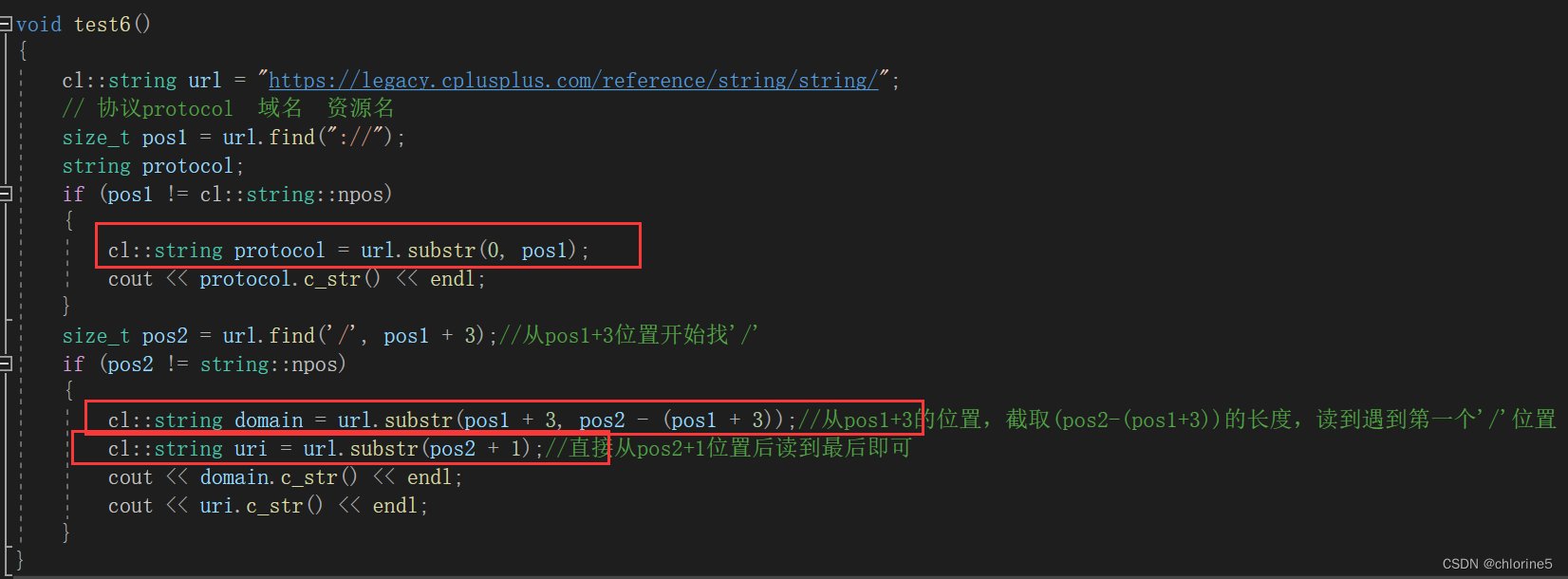
void test6()
{cl::string url = "https://legacy.cplusplus.com/reference/string/string/";// 協議protocol 域名 資源名size_t pos1 = url.find("://");string protocol;if (pos1 != cl::string::npos){cl::string protocol = url.substr(0, pos1);cout << protocol.c_str() << endl;}size_t pos2 = url.find('/', pos1 + 3);//從pos1+3位置開始找'/'if (pos2 != string::npos){cl::string domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));//從pos1+3的位置,截取(pos2-(pos1+3))的長度,讀到遇到第一個'/'位置cl::string uri = url.substr(pos2 + 1);//直接從pos2+1位置后讀到最后即可cout << domain.c_str() << endl;cout << uri.c_str() << endl;}
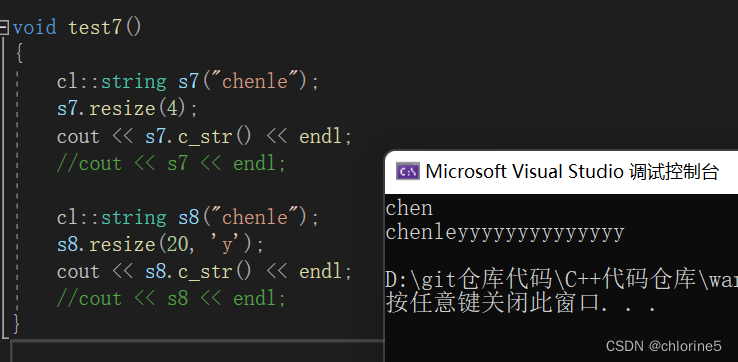
}void test7()
{cl::string s7("chenle");s7.resize(4);cout << s7.c_str() << endl;//cout << s7 << endl;cl::string s8("chenle");s8.resize(20, 'y');cout << s8.c_str() << endl;//cout << s8 << endl;
}void test8()
{cl::string s8("chenlelelelle");s8 += '\0';s8 += "zzzzzz";cout << s8.c_str() << endl;cout << s8 << endl;cl::string copy(s8);cout << s8 << endl;cout << copy << endl;s8 += "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";cout << s8 << endl;}void test9()
{//string s1("bb");//string s2("aaa");//cout << (s1 < s2) << endl;cl::string s1("hello");cl::string s2("hello");cout << (s1 < s2) << endl;cout << (s1 > s2) << endl;cout << (s1 == s2) << endl << endl;cl::string s3("hello");cl::string s4("helloxxx");cout << (s3 < s4) << endl;cout << (s3 > s4) << endl;cout << (s3 == s4) << endl << endl;cl::string s5("helloxxx");cl::string s6("hello");cout << (s5 < s6) << endl;cout << (s5 > s6) << endl;cout << (s5 == s6) << endl << endl;
}void test10()
{cl::string s1("chenle");cl::string s2(s1);//拷貝構造cout << s1.c_str() << endl;cout << s2.c_str() << endl;cl::string s3("xxxxxxxxxxxxx");s1 = s3;//賦值cout << s1.c_str() << endl;cout << s3.c_str() << endl;
}void test11()
{cl::string s1;cin >> s1;cout << s1;}int main()
{//test1();//test2();//test3();//test4();//test5();//test6();//test7();//test8();//test9();//test10();test11();return 0;
}?
沉淀,沉淀,再沉淀。





)

 - Hello World)






)



)
