? ? ? 本文所有案例基于《SQL進階教程》實現。
?概述
????????SQL中的CASE表達式是一種通用的條件表達式,類似于其他語言中的if/else語句。它用于在SQL語句中實現條件邏輯。CASE表達式以WHEN子句開始,后面跟著一個或多個WHEN條件,每個WHEN條件后面跟著一個THEN子句。如果任何WHEN條件為真,則返回相應的THEN子句中的表達式。如果沒有任何WHEN條件為真,則可以選擇性地使用ELSE子句來指定一個默認的表達式。
CASE表達式的語法如下:
-- 簡單 CASE 表達式
CASE sexWHEN '1' THEN '男'WHEN '2' THEN '女'
ELSE '其他' END-- 搜索 CASE 表達式
CASE WHEN sex = '1' THEN '男'WHEN sex = '2' THEN '女'
ELSE '其他' END????????需要注意,在發現為真的 WHEN 子句時,CASE 表達式的真假值判斷就會中止,而剩余的 WHEN 子句會被忽略。為了避免引起不必要的混亂,使用 WHEN 子句時要注意條件的排他性。
-- 例如,這樣寫的話,結果里不會出現“第二”
CASE WHEN col_1 IN ('a', 'b') THEN '第一'WHEN col_1 IN ('a') THEN '第二'
ELSE '其他' END此外,使用 CASE 表達式的時候,還需要注意以下幾點。
- 統一各分支返回的數據類型
- 不要忘了寫 END
- 養成寫 ELSE 子句的習慣
結果轉化
????????例如,現在有一張按照“‘1:北海道’、‘2:青森’、……、‘47:沖繩’”
這種編號方式來統計都道府縣 A 人口的表,我們需要以東北、關東、九州等地區為單位來分組,并統計人口數量。具體來說,就是統計下表 PopTbl中的內容,得出如右表“統計結果”所示的結果。
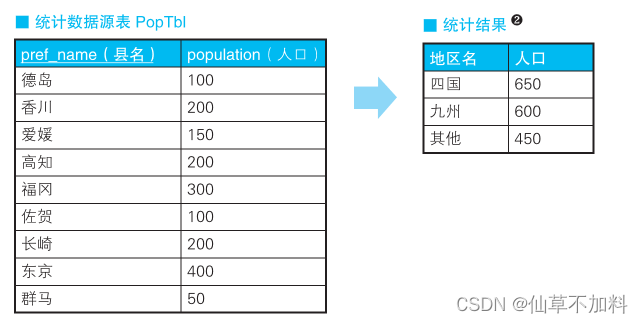
代碼如下:
SELECT CASE pref_nameWHEN '德島' THEN '四國'WHEN '香川' THEN '四國'WHEN '愛媛' THEN '四國'WHEN '高知' THEN '四國'WHEN '福岡' THEN '九州'WHEN '佐賀' THEN '九州'WHEN '長崎' THEN '九州'ELSE '其他' END AS district,SUM(population)
FROM PopTbl
-- GROUP BY 子句里引用了 SELECT 子句中定義的別名
GROUP BY district;? ? ?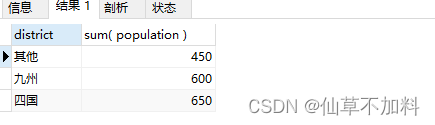
?????????使用case表達式能夠方便的將數據庫中查詢到的結果轉化為我們需要的結果,但是在本代碼中使用到的別名進行分組,這種寫法是違反標準sql的規則的。在select語句的執行流程中,group by語句會比select語句先執行,所以在group by語句中引用在select語句里定義的別稱是不被允許的。
條件統計
????????例如,我們需要往存儲各縣人口數量的表 PopTbl 里添加上“性別”列,然后求按性別、縣名匯總的人數。具體來說,就是統計表 PopTbl2 中的數據,然后求出如表“統計結果”所示的結果。
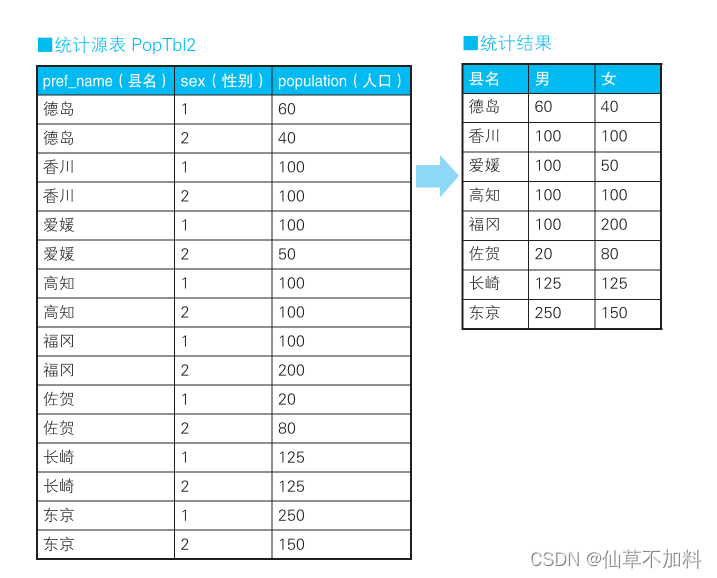
代碼如下:
SELECT pref_name,-- 男性人口SUM( CASE WHEN sex = '1' THEN population ELSE 0 END) AS cnt_m, -- 女性人口SUM( CASE WHEN sex = '2' THEN population ELSE 0 END) AS cnt_f FROM PopTbl2GROUP BY pref_name;配合check約束使用
????????假設某公司規定“女性員工的工資必須在 20 萬日元以下”,而在這個公司的人事表中,這條無理的規定是使用 CHECK 約束來描述的,代碼如下所示。
-- 代碼1
CONSTRAINT check_salary CHECK( CASE WHEN sex = '2'THEN CASE WHEN salary <= 200000THEN 1 ELSE 0 ENDELSE 1 END = 1 )-- 代碼2
CONSTRAINT check_salary CHECK( sex = '2' AND salary <= 200000 )????????代碼1表示的含義是:限制插入“如果員工的性別為女,在此基礎上判斷工資是否在20萬日元以下”的數據,如果員工不是女性,則不做限制。
????????代碼2表示的含義是:限制插入“員工必須為女性而且工資必須在20萬日元以下”的數據。
? ? ? ? 所以代碼1表示的含義才是我們所需求的,這就體現出與case與check配合的獨特性了。
在update語句進行條件分支
????????需求:以某數值型的列的當前值為判斷對象,將其更新成別的值。這里的問題是,此時UPDATE操作的條件會有多個分支。例如,我們通過下面這樣一張公司人事部的員工工資信息表 Salaries 來看一下這種情況。
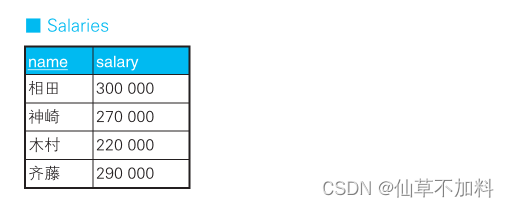
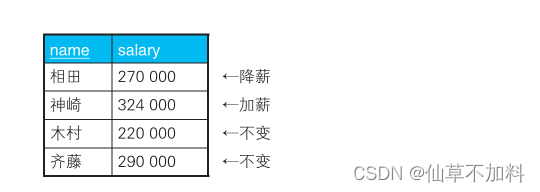
假設現在需要根據以下條件對該表的數據進行更新。
1. 對當前工資為 30 萬日元以上的員工,降薪 10%。
2. 對當前工資為 25 萬日元以上且不滿 28 萬日元的員工,加薪 20%。按照這些要求更新完的數據應該如下表所示。
代碼如下:
-- 代碼1
-- 條件 1
UPDATE SalariesSET salary = salary * 0.9WHERE salary >= 300000;
-- 條件 2
UPDATE SalariesSET salary = salary * 1.2WHERE salary >= 250000 AND salary < 280000;-- 代碼2
-- 用 CASE 表達式寫正確的更新操作
UPDATE SalariesSET salary = CASE WHEN salary >= 300000THEN salary * 0.9WHEN salary >= 250000 AND salary < 280000THEN salary * 1.2ELSE salary END;? ? ? ? ?代碼1使用了2條update語句,分別對這兩種條件進行修改,先更新工資大于30萬日元的數據,再更新25-28萬日元的數據,這就會導致第一次更新之后,相田的工資已經被更新成25-28萬日元之間了,第二次繼續更新,影響了最終結果。所以這種更新方式不可取。
? ? ? ? 代碼2使用了case條件進行更新,這種好處是只執行1次sql,效率更高,且對數據更安全。
數據匹配
????????如下所示,這里有一張資格培訓學校的課程一覽表和一張管理每個月所設課程的表。
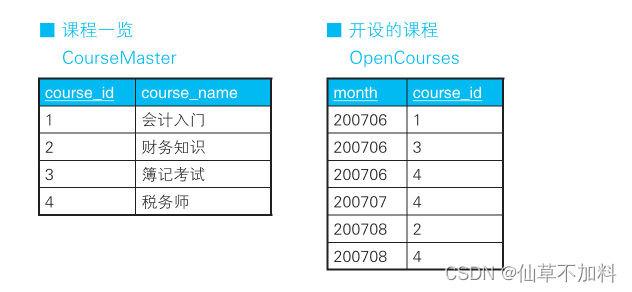
我們要用這兩張表來生成下面這樣的交叉表,以便于一目了然地知道每個月開設的課程。
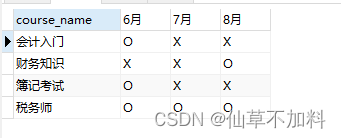
代碼如下:
-- 表的匹配 :使用 IN 謂詞
SELECT course_name,CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200706) THEN '○' ELSE '×' END AS "6 月",CASE WHEN course_id IN (SELECT course_id FROM OpenCoursesWHERE month = 200707) THEN '○' ELSE '×' END AS "7 月",CASE WHEN course_id IN (SELECT course_id FROM OpenCoursesWHERE month = 200708) THEN '○' ELSE '×' END AS "8 月"FROM CourseMaster;-- 表的匹配 :使用 EXISTS 謂詞
SELECT CM.course_name,CASE WHEN EXISTS(SELECT course_id FROM OpenCourses OCWHERE month = 200706 AND OC.course_id = CM.course_id) THEN '○'ELSE '×' END AS "6 月",CASE WHEN EXISTS(SELECT course_id FROM OpenCourses OCWHERE month = 200707 AND OC.course_id = CM.course_id) THEN '○'ELSE '×' END AS "7 月",CASE WHEN EXISTS(SELECT course_id FROM OpenCourses OCWHERE month = 200708 AND OC.course_id = CM.course_id) THEN '○'ELSE '×' END AS "8 月"FROM CourseMaster CM;?????????這樣的查詢沒有進行聚合,因此也不需要排序,月份增加的時候僅修改 SELECT 子句就可以了,擴展性比較好。
????????無論使用 IN 還是 EXISTS,得到的結果是一樣的,但從性能方面來說,EXISTS 更好。通過 EXISTS 進行的子查詢能夠用到“month, course_id”這樣的主鍵索引,因此尤其是當表 OpenCourses 里數據比較多的時候更有優勢。
使用聚合函數
????????假設這里有一張顯示了學生及其加入的社團的一覽表。如表 StudentClub 所示,這張表的主鍵是“學號、社團 ID”,存儲了學生和社團之間多對多的關系。

????????有的學生同時加入了多個社團(如學號為 100、200 的學生),有的學生只加入了某一個社團(如學號為 300、400、500 的學生)。對于加入了多個社團的學生,我們通過將其“主社團標志”列設置為 Y 或者 N 來表明哪一個社團是他的主社團;對于只加入了一個社團的學生,我們將其“主社團標志”列設置為 N。
????????接下來,我們按照下面的條件查詢這張表里的數據。
1. 獲取只加入了一個社團的學生的社團 ID。
2. 獲取加入了多個社團的學生的主社團 ID。?
SELECT std_id,CASE WHEN COUNT(*) = 1 -- 只加入了一個社團的學生THEN MAX(club_id)ELSE MAX(CASE WHEN main_club_flg = 'Y'THEN club_idELSE NULL END)END AS main_clubFROM StudentClubGROUP BY std_id;
????????使用CASE 表達式表示了“只加入了一個社團還是加入了多個社團”這樣的條件分支。如果只加入一個社團就獲取社團id,如果加入多個社團就獲取主社團id。
總結
- 在 GROUP BY 子句里使用 CASE 表達式,可以靈活地選擇作為聚合的單位的編號或等級。這一點在進行非定制化統計時能發揮巨大的威力。
- 在聚合函數中使用 CASE 表達式,可以輕松地將行結構的數據轉換成列結構的數據。
- 相反,聚合函數也可以嵌套進 CASE 表達式里使用。
- 相比依賴于具體數據庫的函數,CASE 表達式有更強大的表達能力和更好的可移植性。
- 正因為 CASE 表達式是一種表達式而不是語句,才有了這諸多優點。
練習題
1.用 SQL 從多行數據里選出最大值或最小值很容易——通過 GROUP BY子句對合適的列進行聚合操作,并使用 MAX 或 MIN 聚合函數就可以求出。那么,從多列數據里選出最大值該怎么做呢?
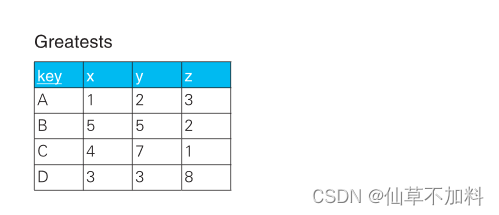
代碼如下:
select gkey, case when x > y then (case when x > z then x else z end) else (case when y > z then y else z end) end as greatest
from greatests 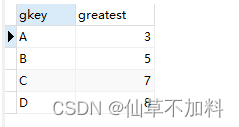
2.使用正文中的表 PopTbl2 作為樣本數據,練習一下把行結構的數據轉換為列結構的數據吧。這次請生成下面這樣的表頭里帶有匯總和再揭的二維表。

代碼如下:
select case sex when 1 then '男' else '女' end as '性別',sum(population) as '全國',sum(case when pref_name = '德島' then population else 0 end) as '德島',sum(case when pref_name = '香川' then population else 0 end) as '香川',sum(case when pref_name = '愛媛' then population else 0 end) as '愛媛',sum(case when pref_name = '高知' then population else 0 end) as '高知',sum(case when pref_name in ('德島','香川','愛媛','高知') then population else 0 end) as '四國(再揭)'
from poptbl2
group by sex
3.對練習題 1?里用過的表 Greatests 正常執行 SELECT key FROM Greatests ORDER BY key;? ? 這個查詢后,結果會按照 key 這一列值的字母表順序顯示出來。
那么,請思考一個查詢語句,使得結果按照 B-A-D-C 這樣的指定順序進行排列。
代碼如下:
SELECT gkey
FROM Greatests
ORDER BY case gkey when 'B' then 1when 'A' then 2when 'D' then 3when 'C' then 4else null end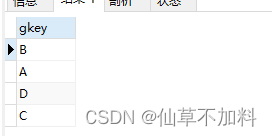
)


 CloudberryDB 并行化查詢之路)



![[動態規劃及遞歸記憶搜索法]1.鋼條切割問題](http://pic.xiahunao.cn/[動態規劃及遞歸記憶搜索法]1.鋼條切割問題)
)

-求曲線在某一點處的法矢和切矢)


環境搭建)





