One-to-Few Label Assignment for End-to-End Dense Detection閱讀筆記
Abstract
一對一(o2o)標簽分配對基于變換器的端到端檢測起著關鍵作用,最近已經被引入到全卷積檢測器中,用于端到端密集檢測。然而,o2o可能因為正樣本數量有限而降低特征學習效率。盡管最近的DETRs引入了額外的正樣本來緩解這個問題,但解碼器中的自注意力和交叉注意力計算限制了其在密集和全卷積檢測器中的實際應用。在這項工作中,我們提出了一種簡單而有效的一對少數(o2f)標簽分配策略,用于端到端密集檢測。除了為每個對象定義一個正錨點和多個負錨點之外,我們還定義了幾個軟錨點(soft anchor),同時充當正負樣本。這些軟錨點的正負權重在訓練過程中動態調整,使它們在訓練初期更多地貢獻于“表示學習”,在后期更多地貢獻于“重復預測移除”。以這種方式訓練的檢測器不僅可以學習強大的特征表示,還能進行端到端密集檢測。在COCO和CrowdHuman數據集上的實驗展示了o2f方案的有效性。代碼可在以下鏈接獲取:https://github.com/strongwolf/o2f。
Introduction
(僅記錄一些我認為比較重要的句子)
-
During the evolution of object detectors, one important trend is to remove the hand-crafted components to achieve end-to-end detection.
-
One hand-crafted component in object detection is the design of training samples.
- However, the performance of anchor-based detectors is sensitive to the shape and size of anchor boxes. To mitigate this issue, anchor-free [19,48] and query-based [5,8,34,61] detectors have been proposed to replace anchor boxes by anchor points and learnable positional queries, respectively.
-
Another hand-crafted component is non-maximum suppression(NMS) to remove duplicated predictions.
- Since NMS has hyperparameters to tune and introduces additional cost, NMS-free end-to-end object detection is highly desired. (由于NMS需要調整超參數并帶來額外的成本,因此非常希望實現無NMS的端到端對象檢測。)
-
With a transformer architecture, DETR [5] achieves competitive end-to-end detection performance.
- However, o2o can impede the training efficiency due to the limited number of positive samples.
-
Recent studies [7, 17, 22] on DETR try to overcome this shortcoming of o2o scheme by introducing independent query groups to increase the number of positive samples. The independency between different query groups is ensured by the self-attention computed in the decoder, which is however infeasible for FCN-based detectors.(最近的研究[7, 17, 22]嘗試通過引入獨立的查詢組來增加正樣本數量,以克服DETR中一對一(o2o)方案的這一缺點。不同查詢組之間的獨立性由解碼器中計算的自注意力來保證,但這對于基于FCN的檢測器來說是不可行的。)
-
In this paper, we aim to develop an efficient FCN-based dense detector, which is NMS-free yet end-to-end trainable.
- 我們觀察到,在一對一(o2o)方案中,將語義上類似于正樣本的模糊錨點設為完全負樣本是不合適的。相反,這些錨點可以在訓練期間同時用于計算正損失和負損失,如果損失權重設計得當,不會影響端到端的能力。基于上述觀察,我們提議為這些模糊錨點分配動態的軟分類標簽。如圖1所示,與o2o不同,后者將模糊錨點(錨點B或C)設為完全負樣本,我們將每個模糊錨點標記為部分正樣本和部分負樣本。正負標簽的程度在訓練過程中自適應調整,以保持“表示學習”和“重復預測移除”之間的良好平衡。特別是,在訓練的早期階段,我們開始以較大的正度數和較小的負度數,以便網絡能更有效地學習特征表示能力,而在后期訓練階段,我們逐漸增加模糊錨點的負度數,以指導網絡學習去除重復預測。我們將我們的方法命名為一對少數(o2f)標簽分配,因為一個對象可以有幾個軟錨點。我們將o2f LA實例化到密集檢測器FCOS中,我們在COCO [29]和CrowHuman [40]的實驗表明,它實現了與帶有NMS的檢測器相當甚至更好的性能。

Related Work
在過去的十年里,隨著深度學習技術[14, 32, 41, 49, 52, 55]的迅猛發展,對象檢測領域取得了巨大進展。現代對象檢測器大致可以分為兩種類型:基于卷積神經網絡(CNN)的檢測器[1, 3, 21, 28, 31, 36-38, 48, 50]和基于變換器的檢測器[5, 8, 30, 34, 53, 54, 61]。
2.1. 基于CNN的對象檢測器
基于CNN的檢測器可進一步劃分為兩階段檢測器和一階段檢測器。兩階段檢測器[3, 38]在第一階段生成區域提議,在第二階段細化這些提議的位置并預測類別,而一階段檢測器[28, 31]直接在卷積特征圖上預測密集錨點的類別和位置偏移。早期的檢測器大多使用預定義的錨點作為訓練樣本。由于不同數據集的適宜設置不同,必須仔細調整錨點形狀和大小的超參數。為了克服這一問題,提出了無錨點檢測器[19, 48]以簡化檢測流程。FCOS [48]和CenterNet [10]用錨點替代錨框,并直接使用這些點來回歸目標對象。CornerNet [20]首先預測對象關鍵點,然后使用關聯嵌入將它們組合成邊界框。
大多數基于CNN的檢測器在訓練過程中采用一對多(o2m)的標簽分配方案。早期的檢測器,如Faster RCNN [38]、SSD [31]和RetinaNet [28],使用IoU作為定義正負錨點的指標。FCOS限制正錨點必須在對象的某些尺度和范圍內。最近的方法[11, 18, 23, 57, 59, 60]通常考慮網絡預測的質量和分布,以更可靠地分配錨點的標簽。然而,o2m標簽分配需要一個后處理步驟,即非極大值抑制(NMS),以去除重復的預測。NMS引入了一個參數來折衷所有實例的精確度和召回率,但這對于擁擠場景尤其不理想。在本文中,我們的目標是去除基于CNN檢測器中的手工NMS步驟,實現端到端的密集檢測。
2.2. 基于Transformer的對象檢測器
作為先驅的基于Transformer的檢測器,DETR [5] 使用一套可學習的對象查詢作為與圖像特征互動的訓練候選項。它通過使用一對一的二部匹配和全局注意力機制,實現了具有競爭力的端到端檢測性能。然而,DETR在小物體上的性能較差,收斂速度慢。許多后續工作[8, 12, 35, 56]旨在改進特征圖和對象查詢之間的注意力建模機制,以提取更相關和精確的特征,提升小物體的檢測性能。最近的研究[7, 17, 22]表明,正樣本數量有限是導致DETR收斂緩慢的原因。因此,它們引入了幾個額外的解碼器來增加正樣本數量。然而,這些方法都基于稀疏候選項,其計算成本在進行密集預測時可能難以承受。與這些方法不同,我們提出了一種軟標簽分配方案,引入更多的正樣本,使得端到端密集檢測器能夠更容易地進行訓練。
One-to-Few Soft Labeling
3.1. Ambiguous Anchors

-
o2o僅選擇一個anchor作為正樣本分配為positive sample,而o2m則選取多個anchor作為Positive sample。在o2o和o2m中,除了正樣本之外的其余錨點都被定義為負樣本。
-
圖2中,紅色為certain anchor,綠色為ambiguous anchors
-
Now we have divided the anchors into three groups: one certain positive anchor, a few ambiguous anchors, and the remaining multiple negative anchors.
-
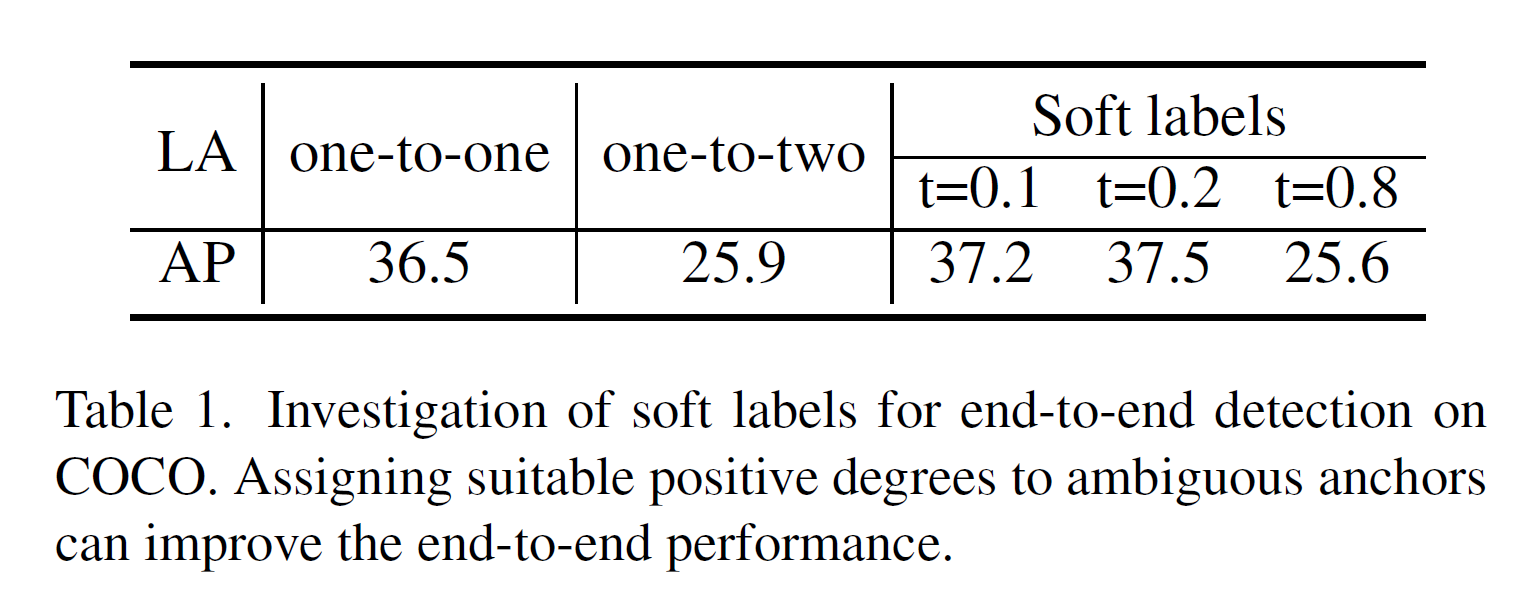
第一個選項是將一對一(o2o)改為一對二,為每個實例增加一個正樣本。第二個選項是為每個模糊錨點分配一個軟標簽t,其中0 ≤ t ≤ 1表示其正樣本程度,因此1 ? t是其負樣本程度。我們定義正錨點和負錨點的分類損失分別為?log§和?log(1 ? p),其中p是預測的分類得分。那么第二個選項的分類損失將是?t × log§ ? (1 ? t) × log(1 ? p)。在COCO數據集上的檢測結果如表1所示,我們可以看到,即使只增加一個正樣本,一對二的標簽分配方案也會顯著降低性能。相比之下,為模糊錨點分配合適的軟標簽可以有效提高端到端性能。(軟標簽分配的細節將在后面的章節中討論。)
- 上述結果表明,使一個模糊錨點同時具有正負屬性可能是有效實現端到端密集檢測的一個可行方案。因此,我們提出了一種一對少數(o2f)標簽分配策略,它選擇一個確定的錨點作為完全正樣本,幾個模糊錨點同時作為正負樣本,其余錨點作為負樣本。模糊錨點的正負程度在訓練過程中動態調整,使得網絡既能保持強大的特征表征能力,又能實現端到端檢測能力。
3.2. Selection of Certain Positive Anchor
在我們的方法中,每個實例都將選定一個確定的正錨點。之前基于一對一(o2o)的檢測器都使用一個預測感知的選擇度量,考慮了分類和回歸的成本來選擇唯一的正樣本。我們遵循這一原則,并將分類得分和IoU整合進確定錨點的選擇度量中,其定義為:
S i , j = 1 [ i ∈ Ω j ] × p i , c j 1 ? α × IoU ( b i , b j ) α , S_{i,j} = \mathbb{1}[i \in \Omega_j] \times p_{i,c_j}^{1-\alpha} \times \text{IoU}(b_i, b_j)^\alpha, Si,j?=1[i∈Ωj?]×pi,cj?1?α?×IoU(bi?,bj?)α,
其中 S_{i,j} 表示錨點i和實例j之間的匹配得分,c_j 是實例j的類別標簽,p_{i,c_j} 是錨點i屬于類別 c_j 的預測分類得分,b_i 是錨點i的預測邊界框坐標,b_j 表示實例j的坐標,而 \alpha 控制分類和回歸的重要程度。當錨點i的中心點在實例j的中心區域 \Omega_j 內時,空間指示器 1[i \in \Omega_j] 輸出1;否則輸出0。這種空間先驗在基于o2o和o2m的方法中被普遍使用,因為觀察到實例中心區域的錨點更有可能是正樣本。
錨點可以根據度量 ( S_{i,j} ) 進行降序排序。之前的研究通常將正錨點選擇問題構建為一個二分匹配問題,并使用匈牙利算法解決。為了簡化,在本研究中,我們直接為每個實例選擇得分最高的錨點作為確定的正錨點。
3.3. Label Assignment for Ambiguous Anchors
除了確定的正錨點之外,我們根據得分 S i , j S_{i,j} Si,j?選擇排名前K的錨點作為模糊錨點,因為它們與確定的正錨點有相似的語義上下文。為了減少重復預測的可能性,我們為這些模糊錨點分配動態軟標簽。假設我們訓練網絡N個周期,在第j個周期中,每個模糊錨點i的分類損失定義為:
l i j = ? t i j × log ? ( p i ) ? ( 1 ? t i j ) × log ? ( 1 ? p i ) l_i^j = -t_i^j \times \log(p_i) - (1 - t_i^j) \times \log(1 - p_i) lij?=?tij?×log(pi?)?(1?tij?)×log(1?pi?)
除了確定的正錨點,我們基于得分 (S_{i,j}) 選擇排名前K的錨點作為模糊錨點,因為它們與確定的正錨點有相似的語義環境。為了降低重復預測的可能性,我們為這些模糊錨點分配動態軟標簽。假設我們訓練網絡進行N個周期,每個模糊錨點i在第j個周期的分類損失定義為:
l i j = ? t i j × log ? ( p i ) ? ( 1 ? t i j ) × log ? ( 1 ? p i ) , l_i^j = -t_i^j \times \log(p_i) - (1 - t_i^j) \times \log(1 - p_i), lij?=?tij?×log(pi?)?(1?tij?)×log(1?pi?), (隨著epochs的增加, l i j l_i^j lij?逐漸的就只等于 ? ( 1 ? t i j ) × log ? ( 1 ? p i ) - (1 - t_i^j) \times \log(1 - p_i) ?(1?tij?)×log(1?pi?))
其中 (p_i) 是錨點i的預測分類得分,(t_i^j) 和 (1 - t_i^j) 分別是該錨點在第j個周期的正負程度(即,損失權重)。(t_i^j) 的動態定義為:
t i j = p i max ? k p k × T j , t_i^j = \frac{p_i}{\max_k p_k} \times T_j, tij?=maxk?pk?pi??×Tj?,
T j = T m i n ? T m a x N ? 1 × j + T m a x , T_j = \frac{T_{min} - T_{max}}{N - 1} \times j + T_{max}, Tj?=N?1Tmin??Tmax??×j+Tmax?,
其中 (T_j) 是一個隨時間變化的變量,它在第j個周期為所有樣本分配相同的值,(T_{max}) 和 (T_{min}) 控制模糊錨點在第一個周期和最后一個周期的degree。我們將損失權重與分類得分呈正相關,考慮到預測得分較高的錨點應該更多地貢獻于正信號。直接使用 ( p_i ) 作為權重會使得在難樣本上的訓練變得不穩定,因為這些樣本的預測得分遠小于簡單樣本的得分。因此,我們使用 ( p_i ) 與最大得分的比率來規范化不同樣本的權重至同一尺度。動態調整 ( T_j ) 是很重要的,因為它在不同的訓練階段控制著“特征學習”與“重復預測移除”之間的平衡。
在訓練的早期階段,我們設置 (T_j) 相對較大,以引入更多的正監督信號以進行表示學習,從而使網絡能夠迅速收斂到一個穩健的特征表示空間。隨著訓練的進行,我們逐漸減少模糊錨點的正度,以便網絡學會去除重復的預測。
3.4. Network Structure
我們將提出的一對少數(o2f)標簽分配策略應用到FCOS上,這是一個典型的全卷積密集檢測器。網絡結構如圖3所示。檢測頭由兩個平行的卷積分支組成,每個特征金字塔網絡(FPN)層的輸出都連接一個分支。一個分支預測大小為 ( H × W × C H \times W \times C H×W×C) 的得分圖,其中 (C) 是數據集中的類別數,(H) 和 (W) 分別是特征圖的高度和寬度。另一個分支預測大小為 ( H × W × 4 H \times W \times 4 H×W×4) 的位置偏移圖和大小為 ( H × W × 1 H \times W \times 1 H×W×1) 的中心度圖。我們按照之前的工作將中心度圖與分類得分圖相乘,作為最終的分類-交并比聯合得分。
"Centerness map"是FCOS(Fully Convolutional One-Stage Object Detector)中用于提高檢測性能的一個概念。它是一個得分,用來表示一個位置相對于其目標邊界框中心的偏離程度。這個得分用于在非極大抑制(NMS)過程中下調低質量邊界框的權重,以抑制這些低質量的檢測結果。"Centerness"得分是通過與邊界框回歸分支平行的一個分支(只有一層)來預測的,這個簡單而有效的"centerness"分支能夠顯著提高檢測性能,而計算時間的增加微不足道
對于每個實例,我們選擇一個確定的正錨點和 (K) 個模糊錨點。其余的錨點被設置為負樣本。分類分支的訓練目標為每個實例定義如下:
L c l s = B C E ( p c , 1 ) + ∑ i ∈ A B C E ( p i , t i ) + ∑ i ∈ B F L ( p i , 0 ) L_{cls} = BCE(p_c, 1) + \sum_{i \in A} BCE(p_i, t_i) + \sum_{i \in B} FL(p_i, 0) Lcls?=BCE(pc?,1)+∑i∈A?BCE(pi?,ti?)+∑i∈B?FL(pi?,0)
其中 (p_c) 是單個確定錨點的分類得分,(A) 和 (B) 分別代表模糊錨點和負錨點的集合。BCE表示二元交叉熵損失,FL表示焦點損失。回歸損失定義為:
L r e g = ∑ i ∈ B G I o U ( b i , b g t ) L_{reg} = \sum_{i \in B} GIoU(b_i, b_{gt}) Lreg?=∑i∈B?GIoU(bi?,bgt?)
其中GIoU損失是基于廣義交并比的位置損失,(b_i) 是錨點 (i) 的預測位置,(b_{gt}) 是與錨點 (i) 對應的GT對象的位置。請注意,我們對正錨點和模糊錨點都應用了回歸損失。
![[動態規劃及遞歸記憶搜索法]1.鋼條切割問題](http://pic.xiahunao.cn/[動態規劃及遞歸記憶搜索法]1.鋼條切割問題)
)

-求曲線在某一點處的法矢和切矢)


環境搭建)







)




)