隨著數據驅動的應用日益增多,數據查詢和分析的量級和時效性要求也在不斷提升,對數據庫的查詢性能提出了更高的要求。為了滿足這一需求,數據庫引擎不斷經歷創新,其中并行執行引擎是性能提升的重要手段之一,逐漸成為數據庫系統的標配特性。
Cloudberry Database(簡稱為“CBDB”或“CloudberryDB”)是面向分析和AI場景打造的下一代統一型開源數據庫,搭載了PostgreSQL 14.4內核,采用Apache License 2.0許可協議。CBDB在Postgres的基礎之上,對已有的并行執行計劃進行了大量的調整和優化,實現了顯著的性能提升。
在這次的直播中,HashData數據庫內核研發專家介紹了Postgres的并行化原理,CBDB在并行化上的優化與改進、功能特性及實踐演示。以下內容根據直播文字整理。
并行化查詢介紹
PostgreSQL在很多場景下會啟用并行執行計劃,創建多個并行工作子進程,提升查詢效率。PostgreSQL的并行化包含三個重要組件:進程本身(leader進程)、gather、workers。沒有開啟并行化的時候,進程自身處理所有的數據;一旦計劃器決定某個查詢或查詢中某個部分可以使用并行的時候,就會在查詢的并行化部分添加一個gather節點,將gather節點作為子查詢樹的根節點。
HashData研發團隊在對CloudberryDB實現并行化查詢時,主要對查詢執行算子、Join的實現以及存儲引擎并行化掃描等進行了調整和優化。

圖1:非并行化查詢與并行并查詢對比示例
如圖1所示,以3個節點的集群為例,在不開啟并行化進行Not in操作時,需要耗時50多秒;而在CBDB中開啟并行化查詢后,用時僅需119毫秒,效率大約提升600倍。
在開啟并行化查詢時,有以下幾處變化:
- Gather Motion從3:1提升至12:1,意味著集群的每個節點上有4個進程在同時并行工作;
- Hash節點變為Parallel Hash;
- 新算子Broadcast Workers Motion 廣播每一份數據到一組并行工作的進程中的一個,避免在共享Hash表的情況下出現數據重復。
- 底層的掃描由Seq Scan變為Parallel Seq Scan。
并行掃描原理
在PostgreSQL中,數據以Heap表的形式存儲。在讀取時,通常有順序掃描(Seq Scan)、索引掃描(Index Scan)和位圖掃描(Bitmap scan)三種掃描方式。接下來,我們對以上三種掃描方式的并行化進行介紹。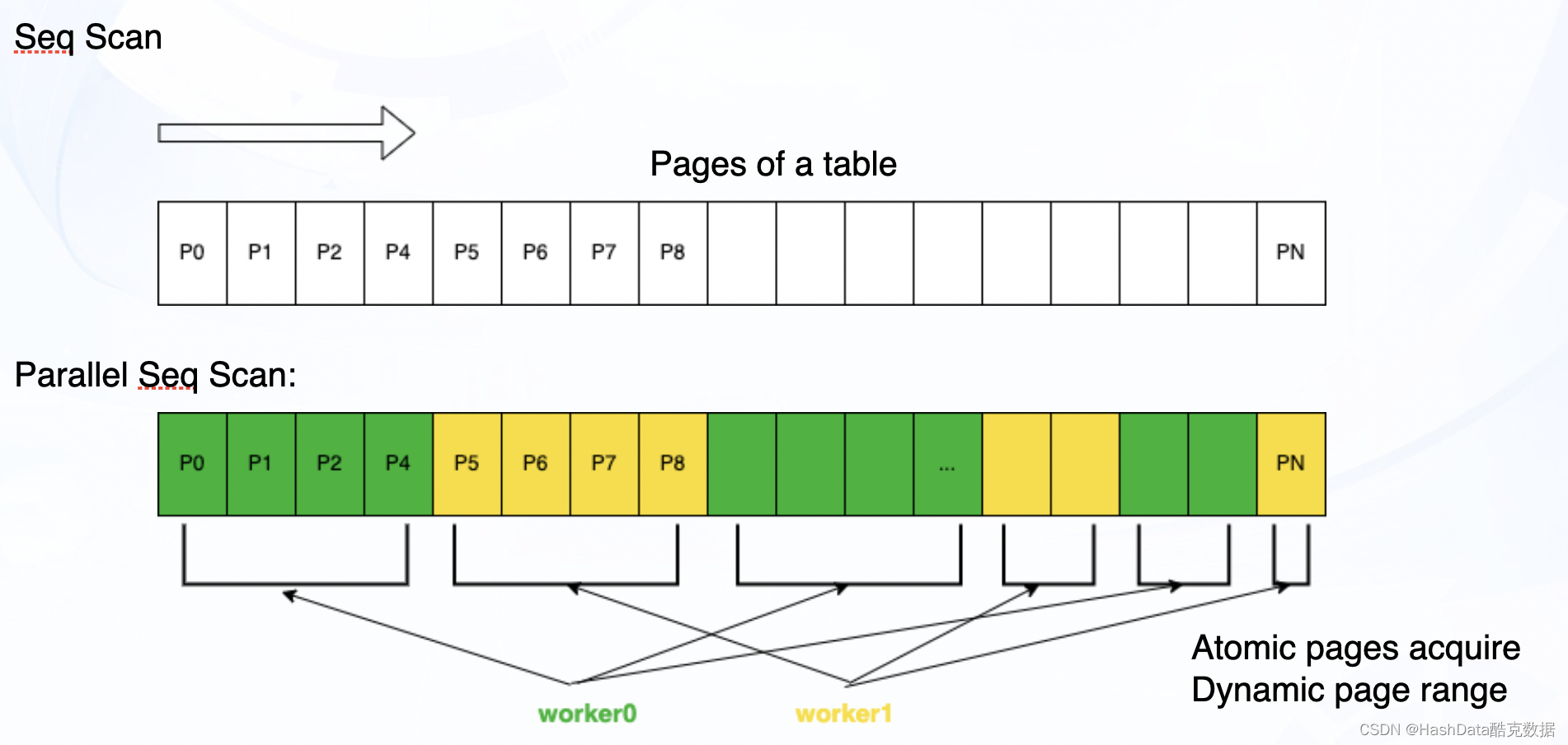
圖2:PostgreSQL Heap表并行順序掃描示意圖
如圖2所示,在并行順序掃描時,兩個子進程的快照是統一共享的。進程之間通過原子操作動態獲得每次要讀取的Page范圍,避免頻繁使用鎖從而造成瓶頸。Page的范圍并不固定,會根據數據量和讀取進度進行動態調整,使得任務盡量均分在不同進程中,避免木桶效應。

圖3:PostgreSQL 并行索引掃描示意圖
使用索引掃描并行化查詢時,子進程只需要讀取對應索引的Page,每個進程每次只讀取一個索引Page,再讀取Heap表數據;如果Page為全體可見,可以不讀取Heap表。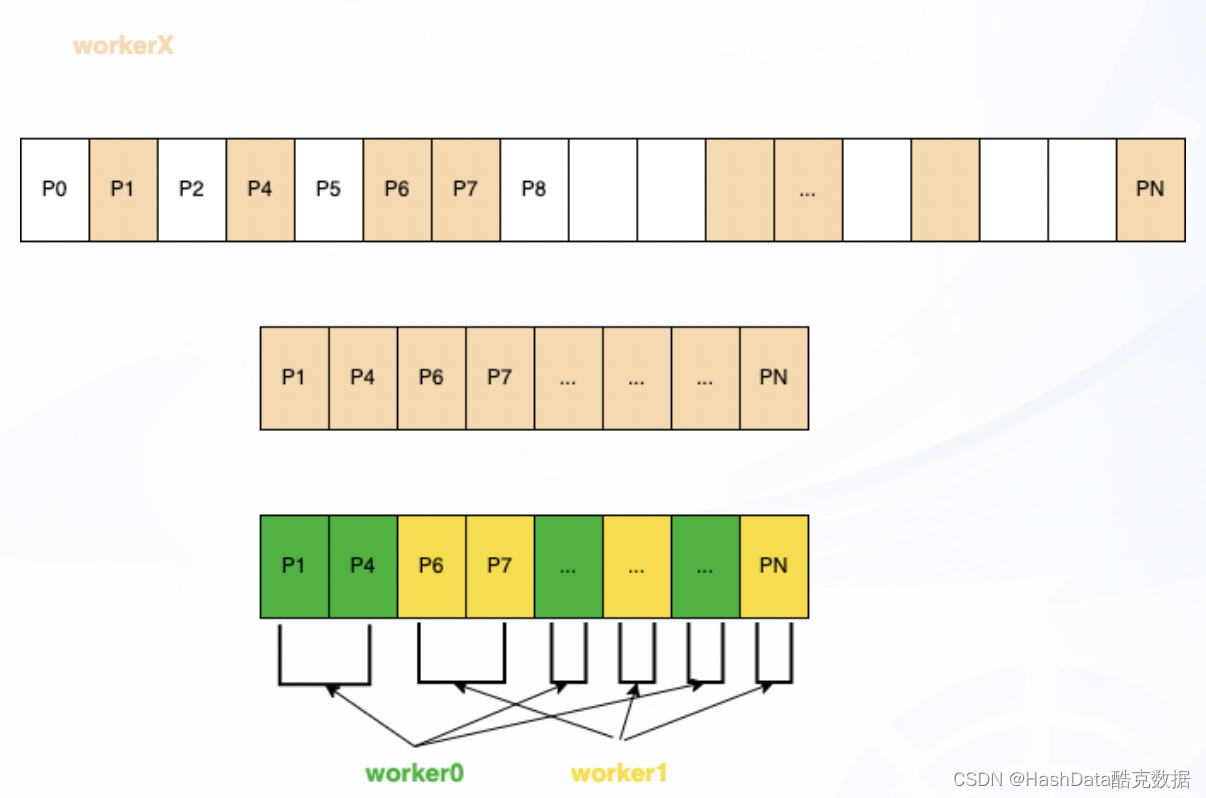
圖4:PostgreSQL 并行位圖掃描示意圖
并行位圖掃描在建立底層索引的Page范圍時,只有一個進程,按照索引信息(CTID)進行順序掃描。與PostgreSQL使用leader進程不同的是,CBDB在并行化查詢時,會通過競爭的方式選擇一個X進程,X進程負責建立位圖,之后多個workers競爭讀取數據。
圖5:CloudberryDB AO表并行化查詢示意圖
除了Heap表之外,CBDB還引入了AO表,用來專門存儲以追加方式插入的元組。如圖5所示,AO表的并行掃描是通過原子操作獲取Segfiles,讓各個進程通過競爭的方式讀取數據。
并行Join實現
并行能力的優化需要從多方面來實現,僅憑優化掃描方式能實現的性能提升有限,Join的并行化改造是另一個重要方向。
在PG中有三種Join,分別為Nestloop Join、Merge Join和Hash Join,CBDB對上述三種Join均實現了并行化。此外,一大特色是增加了共享內表的Hash Join(Parallel-aware Hash Join)。
Parallel-aware Hash Join與Hash Join相似,區別在于前者是可以共享的,進程之間相互協作共同建立共享的Hash內表。
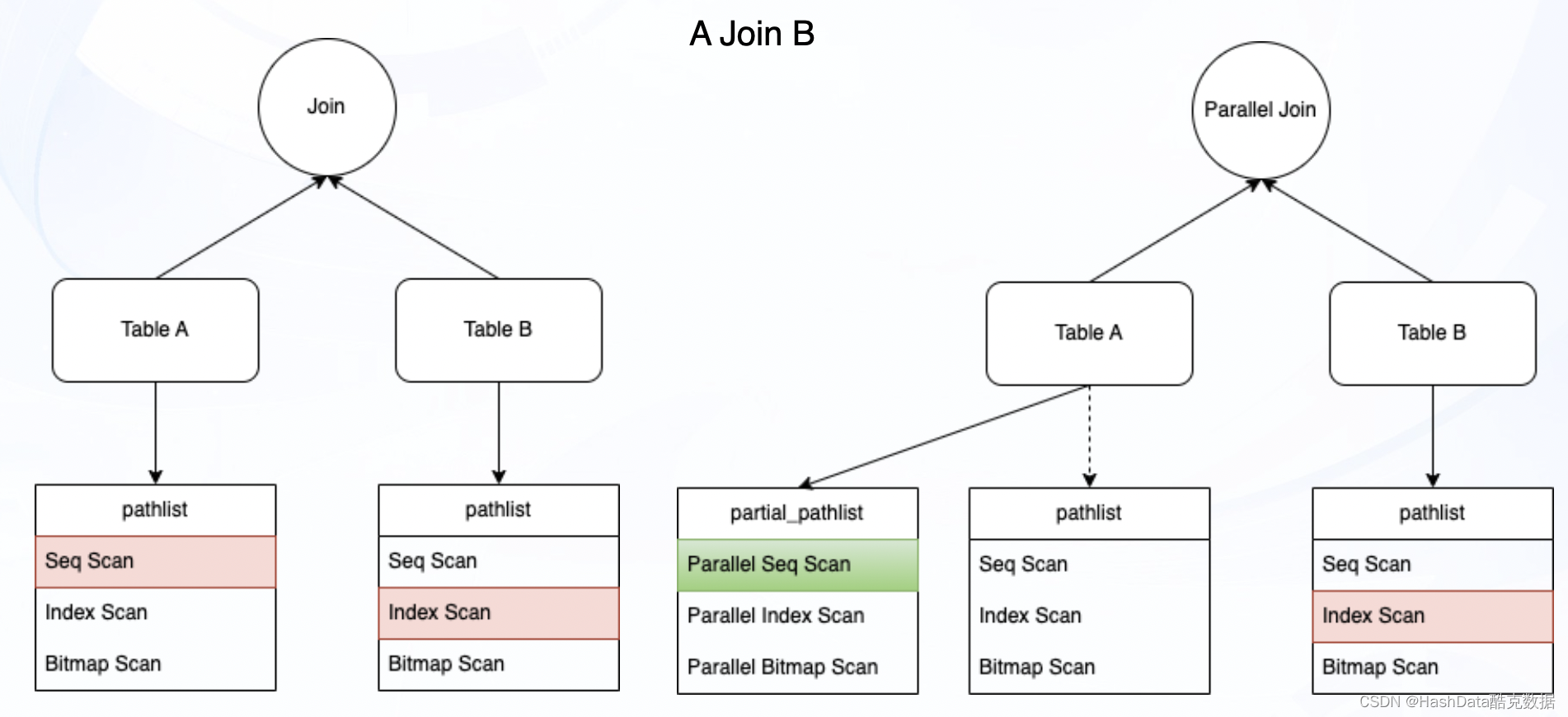
圖6:Build a Join并行化實現流程示意圖
如圖6所示,在PG非并行的情況下,構建Join時從目標對象(Table A、Table B)各選取一條綜合代價最低的執行路徑,合成Join relations路徑。在開啟并行化后,會在上述情況下增加一條并行化最佳路徑,與非并行化路徑構建Join。
數據分布并行化
在Greenplum 中,數據分布有Partitioned、Replicated、Bottleneck三種情況,它們之間可以通過Motion改變Locus的屬性進行互相轉化,實現數據重分布,CBDB也沿用了這一特性。
圖7:CBDB數據分布特性示意圖
在CBDB構建Join的時候,可以通過改變Locus進行數據相容。在轉化過程中遵循兩個原則:
- 在Join時,要保證數據不重復、不丟失;
- 要選擇代價最小的方式。
與Greenplum 不同的是,CBDB在開啟并行化之后,新建了三個新的Locus 并行模式,實現不同的數據分布:HashedWorkers、SegmentGeneralWorkers和ReplicatedWorkers。 HashedWorkers Locus表示數據分布在同一組進程之間是隨機的,但是合并后數據分布變成Hashed Locus。同理,SegmentGeneralWorkers 和ReplicatedWorkers也代表了數據在進程間隨機,合并后滿足各自的分布狀態。
此外,CBDB還實現了并行刷新物化視圖、并行Create Table AS、多階段并行化Aggregation/Limit等。通過以上諸多并行優化措施后,CBDB性能得到大幅度的提升,在特定場景下甚至可以實現千百倍的查詢效率提升,支持企業海量數據的復雜分析需求。
圖8:CBDB并行化性能曲線圖
并行化查詢是CBDB在研發立項之初就確定的產品方向,我們希望能夠通過多線程并行執行來充分釋放現代多核大內存的硬件能力,降低包括IO以及CPU計算在內的處理時間,實現響應時間的大幅下降,更好地提升用戶使用體驗和業務敏捷度。



![[動態規劃及遞歸記憶搜索法]1.鋼條切割問題](http://pic.xiahunao.cn/[動態規劃及遞歸記憶搜索法]1.鋼條切割問題)
)

-求曲線在某一點處的法矢和切矢)


環境搭建)







)

