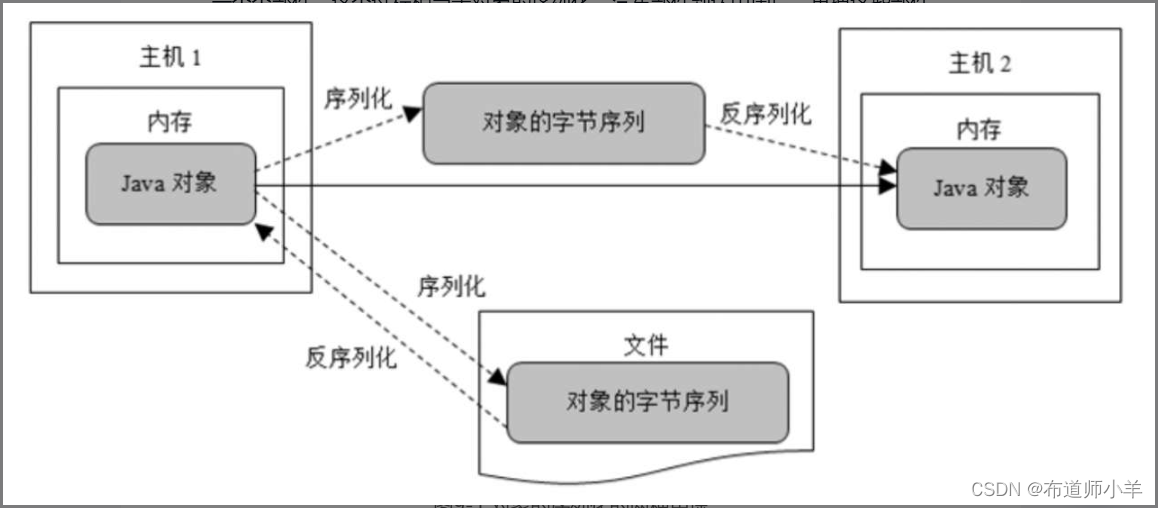
當兩個進程進行遠程通信時,彼此可以發送各種類型的數據,如文本、圖片、語音和視頻等。無論是何種類型的數據,都會以二進制序列的形式在網絡上傳送。當兩個Java進程進行遠程通信時,一個進程能否把一個Java對象發送給另一個進程呢?答案是肯定的。不過,發送方需要把這個Java對象轉換為字節序列,才能在網絡上傳送;接收方則需要把字節序列再恢復為Java對象。把Java對象轉換為字節序列的過程稱為對象的序列化;把字節序列恢復為Java對象的過程稱為對象的反序列化。
可以通過一個比喻來幫助我們形象地理解對象的序列化以及反序列化。假定要把一批新汽車(Car對象)從美國海運到中國。為了便于運輸,在美國,先把汽車拆成一個個部件,這個過程相當于對象的序列化。汽車部件到達中國后,再把這些部件組裝成汽車,這個過程相當于對象的反序列化。
當程序運行時,程序所創建的各種對象都位于內存中,當程序運行結束,這些對象就結束生命周期。如下圖所示,對象的序列化主要有兩種用途:
- (1)把對象的字節序列永久地保存到硬盤上,通常存放在一個文件中。
- (2)在網絡上傳送對象的字節序列。
1、JDK類庫中的序列化API
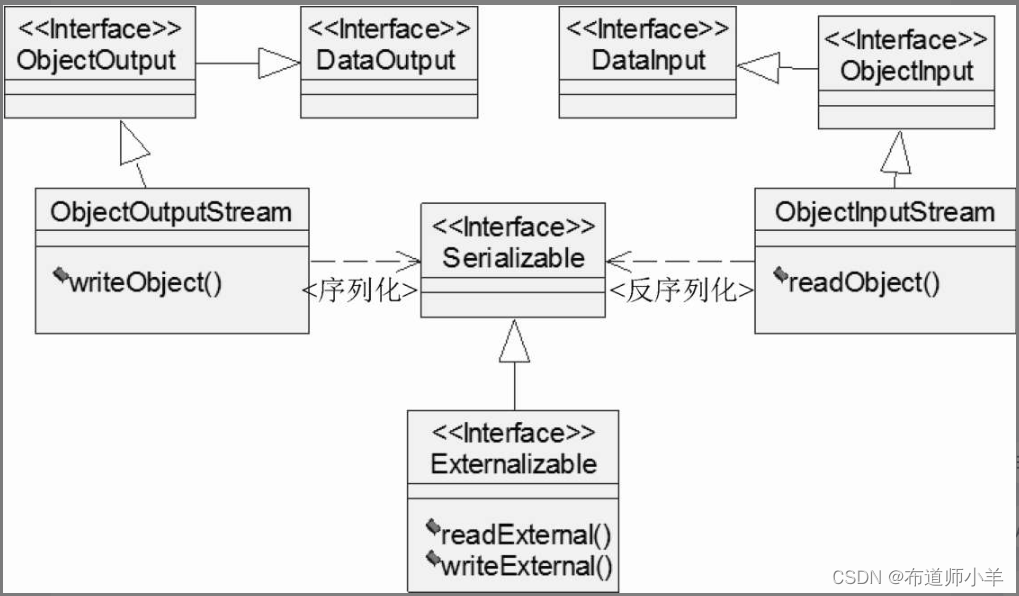
java.io.ObjectOutputStream代表對象輸出流,它的writeObject(Object obj)方法對參數指定的obj對象進行序列化,把得到的字節序列寫到一個目標輸出流中。java.io.ObjectInputStream代表對象輸入流,它的readObject()方法從一個源輸入流中讀取字節序列,再把它們反序列化成一個對象,并將其返回。
只有實現了Serializable或Externalizable接口的類的對象才能被序列化,否則ObjectOutputStream的writeObject(Object obj)方法會拋出IOException。實現Serializable或Externalizable接口的類也被稱為可序列化類。Externalizable接口繼承自Serializable接口,實現Externalizable接口的類完全由自身來控制序列化的行為,而僅實現Serializable接口的類可以采用默認的序列化方式。JDK類庫中的部分類(如String類、包裝類和Date類等)都實現了Serializable接口。
假定有一個名為Customer的類,它的對象需要序列化。如果Customer類僅僅實現了Serializable接口的類,那么將按照以下方式序列化以及反序列化Customer對象:
- ObjectOutputStream采用JDK提供的默認的序列化方式,對Customer對象的非transient類型的實例變量進行序列化。
- ObjectInputStream采用JDK提供的默認的反序列化方式,對Customer對象的非transient類型的實例變量進行反序列化。
如果Customer類不僅實現了Serializable接口,并且還定義了readObject(ObjectInputStream in)和writeObject(ObjectOuputStream out)方法,那么將按照以下方式序列化以及反序列化Customer對象:
- ObjectOutputStream調用Customer類的writeObject(ObjectOuputStream out)方法來進行序列化。
- ObjectInputStream調用Customer類的readObject(ObjectInputStream in)方法來進行反序列化。
如果Customer類實現了Externalizable接口,那么Customer類必須實現readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法。在這種情況下,將按照以下方式序列化以及反序列化Customer對象:
- ObjectOutputStream調用Customer類的writeExternal(ObjectOutput out)方法來進行序列化。
- ObjectInputStream先通過Customer類的不帶參數的構造方法創建一個Customer對象,然后調用它的readExternal(ObjectInput int)方法來進行反序列化。
下圖是序列化API的類框圖:
2、 實現Serializable接口
bjectOuputStream只能對實現了Serializable接口的類的對象進行序列化。在默認情況下,ObjectOuputStream按照默認方式序列化,這種序列化方式僅僅對一個對象的非transient類型的實例變量進行序列化,而不會序列化對象的transient(transient是一個修飾符,用于標記一個實例變量不參與序列化過程)類型的實例變量,也不會序列化靜態變量。
下面的Customer1類中,定義了一些靜態變量、非transient類型的實例變量,以及transient類型的實例變量。
import java.io.Serializable;/*** @title Customer* @description 測試* @author: yangyongbing* @date: 2023/12/8 15:30*/
public class Customer implements Serializable {// 用于計算Customer對象的數目private static int count;private static final int MAX_COUNT=1000;private String name;private transient String password;static {System.out.println("調用Customer類的靜態代碼塊");}public Customer() {System.out.println("調用Customer類的不帶參數的構造方法");count++;}public Customer(String name, String password) {System.out.println("調用Customer類的帶參數的構造方法");this.name = name;this.password = password;count++;}@Overridepublic String toString() {return "count=" +count+" MAX_COUNT="+MAX_COUNT+" name=" + name+" password=" + password;}public static void main(String[] args) {Customer customer = new Customer();System.out.println(customer);}
}先運行命令“java SimpleServer Customer”,再運行命令“java SimpleClient”。SimpleServer端的打印結果如下。

SimpleClient端的打印結果如下:

從以上打印結果可以看出,當ObjectOutputStream按照默認方式序列化時,Customer對象的靜態變量count,以及transient類型的實例變量password沒有被序列化。
當ObjectInputStream按照默認方式反序列化時,有以下特點:
- 如果在內存中對象所屬的類還沒有被加載,那么會先加載并初始化這個類。如果在classpath中不存在相應的類文件,那么會拋出ClassNotFoundException。從SimpleClient端的打印結果可以看出,客戶端加載并初始化了Customer類,在初始化時,把靜態常量MAX_COUNT初始化為1000,并且把靜態變量count初始化為0,此外還調用了Customer類的靜態代碼塊。
- 在反序列化時不會調用類的任何構造方法。
如果一個實例變量被transient修飾符修飾,那么默認的序列化方式不會對它序列化。根據這一特點,可以用transient修飾符來修飾以下類型的實例變量。
(1)實例變量不代表對象的固有的內部數據,僅僅代表具有一定邏輯含義的臨時數據。例如,假定Customer類有firstName、lastName和fullName等屬性:

Customer類的fullName實例變量可以不必被序列化,因為知道了firstName和lastName變量的值,就可以由它們推導出fullName實例變量的值。
(2)實例變量表示一些比較敏感的信息(比如銀行賬戶的口令),出于安全方面的原因,不希望對其序列化。
(3)實例變量需要按照用戶自定義的方式序列化,比如經過加密后再序列化。在這種情況下,可以把實例變量定義為transient類型,然后在writeObject()方法中對其序列化
2.1、序列化對象圖
類與類之間可能存在關聯關系。例如下列中的Customer2類與Order2類之間存在一對多的雙向關聯關系。

SimpleServer類的main()方法中,以下代碼創建了一個Customer2對象和兩個Order2對象,并且建立了它們的關聯關系:

下圖顯示了在內存中,以上代碼創建的3個對象之間的關聯關系:
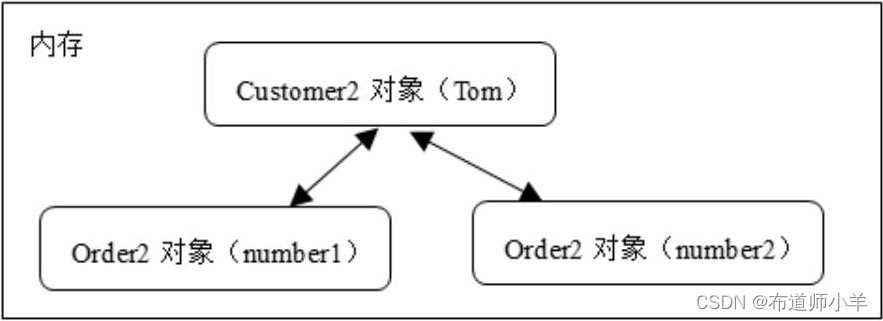
當通過ObjectOutputStream對象的writeObject(customer)方法序列化Customer2對象時,會不會序列化與它關聯的Order2對象呢?答案是肯定的。在默認方式下,對象輸出流會對整個對象圖進行序列化。當程序執行writeObject(customer)方法時,該方法不僅序列化Customer2對象,還會把兩個與它關聯的Order2對象也序列化。當通過ObjectInputStream對象的readObject()方法反序列化Customer2對象,實際上會對整個對象圖反序列化。
先運行命令“java SimpleServer Customer2”,再運行命令“java SimpleClient”。SimpleServer服務器會把由一個Customer2對象和兩個Order2對象構成的對象圖發送給SimpleClient。SimpleClient端的打印結果如下:

按照默認方式序列化對象A時,到底會序列化由哪些對象構成的對象圖呢?如下圖所示:
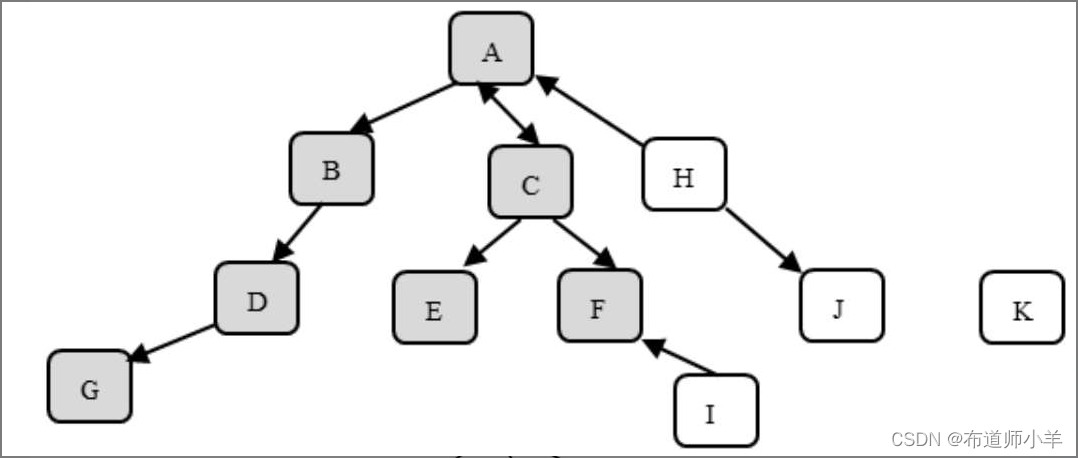
從對象A到對象B之間的箭頭表示從對象A到對象B有關聯關系,或者說,對象A持有對象B的引用,或者說,在內存中可以從對象A導航到對象B。序列化對象A時,實際上會序列化對象A,以及所有可以從對象A直接或間接導航到的對象。因此序列化對象A時,實際上在對象圖中被序列化的對象包括:對象A、對象B、對象C、對象D、對象E、對象F和對象G。
2.2、控制序列化的行為
如果用戶希望控制類的序列化行為,那么可以在可序列化類中提供以下形式的writeObject()方法和readObject()方法:

當ObjectOutputStream對一個Customer對象進行序列化時,如果該Customer對象具有writeObject()方法,那么就會執行這一方法,否則就按默認方式序列化。在ObjectOutputStream的defaultWriteObject()方法中指定了默認的序列化操作。
在Customer對象的writeObject()方法中,可以先調用ObjectOutputStream的defaultWriteObject()方法,使得對象輸出流先執行默認的序列化操作。
當ObjectInputStream對一個Customer對象進行反序列化時,如果該Customer對象具有readObject()方法,那么就會執行這一方法,否則就按默認方式反序列化。在ObjectInputStream的defaultReadObject()方法中指定了默認的反序列化操作。
在Customer對象的readObject()方法中,可以先調用ObjectInputStream的defaultReadObject()方法,使得對象輸入流先執行默認的反序列化操作。
值得注意的是,以上writeObject()方法和readObject()方法并不是在java.io.Serializable接口中被定義的。當一個軟件系統希望擴展第三方提供的Java類庫(比如JDK類庫)的功能時,最常見的方式是實現第三方類庫的一些接口,或創建類庫中抽象類的子類。但是以上writeObject()方法和readObject()方法并不是在java.io.Serializable接口中被定義的。JDK類庫的設計人員沒有把這兩個方法放在Serializable接口中,這樣做的優點如下所述:
- (1)不必公開這兩個方法的訪問權限,以便封裝序列化的細節。如果把這兩個方法放在Serializable接口中,就必須定義為public類型。
- (2)不必強迫用戶定義的可序列化類實現這兩個方法。如果把這兩個方法放在Serializable接口中,它的實現類就必須實現這些方法,否則就只能聲明為抽象類。
在以下情況下,可以考慮采用用戶自定義的序列化方式,從而控制序列化的行為:
- (1)確保序列化的安全性,對敏感的信息加密后再序列化,在反序列化時則需要解密。
- (2)確保對象的成員變量符合正確的約束條件。
- (3)優化序列化的性能。
- (4)便于更好地封裝類的內部數據結構,確保類的接口不會被類的內部實現所束縛。
2.3、readResolve()方法在單例類中的運用
單例類指僅有一個實例的類。在系統中具有唯一性的組件可作為單例類,這種類的實例通常會占用較多的內存,或者實例的初始化過程比較冗長,因此隨意創建這些類的實例會影響系統的性能。
下面的GlobalConfig類就是個單例類,它用來存放軟件系統的配置信息。這些配置信息本來存放在配置文件中,在GlobalConfig類的構造方法中,會從配置文件中讀取配置信息,把它存放在properties屬性中:

無論是采用默認方式,還是采用用戶自定義的方式,反序列化都會創建一個新的對象。在以上GlobalConfig類的main()方法中,in.readObject()方法會返回一個新的GlobalConfig對象,運行以上程序,打印結果如下.

由此可見,反序列化打破了單例類只能有一個實例的約定。為了避免這一問題,可以在GlobalConfig類中再增加一個readResolve()方法:

如果一個類提供了readResolve()方法,那么在執行反序列化操作時,先按照默認方式或者用戶自定義的方式進行反序列化,最后再調用readResolve()方法,該方法返回的對象為反序列化的最終結果。
提示:readResolve()方法用來重新指定反序列化得到的對象,與此對應,Java序列化規范還允許在可序列化類中定義一個writeReplace()方法,用來重新指定被序列化的對象。writeReplace()方法返回一個Object類型的對象,這個返回對象才是真正要被序列化的對象。writeReplace()方法的訪問權限也可以是private、默認或protected級別。
3、實現Externalizable接口
Externalizable接口繼承自Serializable接口。如果一個類實現了Externalizable接口,那么將完全由這個類控制自身的序列化行為。Externalizable接口中聲明了兩個方法:

writeExternal()方法負責序列化操作,readExternal()方法負責反序列化操作。在對實現了Externalizable接口的類的對象進行反序列化時,會先調用類的不帶參數的構造方法,這是有別于默認反序列化方式的。
注意:一個類如果實現了Externalizable接口,那么它必須具有public類型的不帶參數的構造方法,否則這個類無法反序列化。
4、可序列化類的不同版本的序列化兼容性
假定Customer5類有兩個版本1.0和2.0,如果要把基于1.0的序列化數據反序列化為2.0的Customer5對象,或者把基于2.0的序列化數據反序列化為1.0的Customer5對象,那么會出現什么情況呢?如果可以成功地反序列化,則意味著不同版本之間對序列化兼容,反之,則意味著不同版本之間對序列化不兼容。
凡是實現Serializable接口的類都有一個表示序列化版本標識符的靜態常量:
private static final long serialVersionUID;
以上serialVersionUID的取值是Java運行時環境根據類的內部細節自動生成的。如果對類的源代碼做了修改,再重新編譯,那么新生成的類文件的serialVersionUID的取值有可能也會發生變化。
在Customer5類的1.0版本中,具有name和age屬性:

而在Customer5類的2.0版本中,刪除了age屬性,并且增加了isMarried屬性:
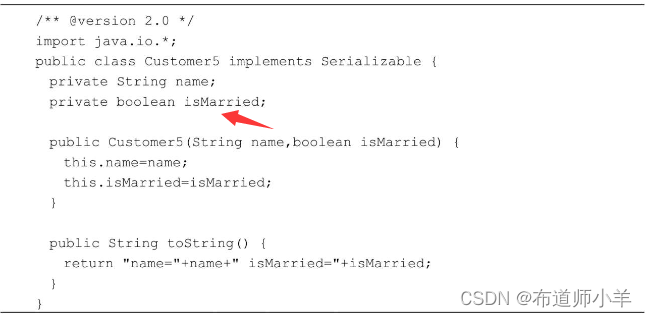
分別對以上兩個類編譯,把它們的類文件分別放在server和client目錄下,此外把SimpleServer和SimpleClient的類文件也分別拷貝到server和client目錄下,如下圖所示:
JDK安裝好以后,在它的bin目錄下有一個serialver.exe程序,用于查看實現了Serializable接口的類的serialVersionUID。在server目錄下運行命令“serialver Customer5”,打印結果如下:
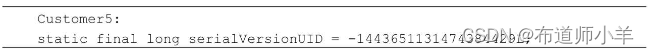
client目錄下運行命令“serialver Customer5”,打印結果如下:
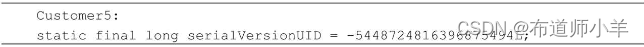
由此可見,Customer5類的兩個版本有著不同的serialVersionUID。
先在server目錄下運行命令“java SimpleServer Customer5”,然后在client目錄下運行命令“java SimpleClient”。SimpleServer按照Customer5類的1.0版本對一個Customer5對象進行序列化,而SimpleClient按照Customer5類的2.0版本進行反序列化,由于兩個類的版本不一樣,SimpleClient在執行反序列化操作時,會拋出以下異常:

類的serialVersionUID的默認值依賴于Java編譯器的實現,對于同一個類,用不同的Java編譯器編譯,有可能會導致不同的serialVersionUID,也有可能相同。為了提高serialVersionUID的獨立性和確定性,強烈建議在一個可序列化類中顯式地定義serialVersionUID,為它賦予明確的值。顯式定義serialVersionUID有兩種用途:
- (1)在某些場合,希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有相同的serialVersionUID。
- (2)在某些場合,不希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有不同的serialVersionUID。
(2)在某些場合,不希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有不同的serialVersionUID。
用serialVersionUID來控制序列化兼容性的能力是很有限的。當一個類的不同版本的serialVersionUID相同時,仍然有可能出現序列化不兼容的情況。因為序列化兼容性不僅取決于serialVersionUID,還取決于類的不同版本的實現細節和序列化細節。所以需要前面介紹的各種方法,來手工控制序列化以及反序列化的行為,從而保證不同版本之間的兼容性。
5、總結
如果采用默認的序列化方式,只要讓一個類實現Serializable接口,它的實例就可以被序列化了。盡管讓一個類變為可序列化很容易,似乎不會給程序員增加很多編程負擔,仍然要謹慎地考慮是否要讓一個類實現Serializable接口,因為給可序列化類進行版本升級時,需要測試序列化兼容性,這種測試工作量與“可序列化類的數目”與“版本數”的乘積成正比。通常,專門為繼承而設計的類應該盡量不要實現Serializable接口,因為一旦父類實現了Serializable接口,所有子類也都變為可序列化的了,這大大增加了為這些類進行升級時測試序列化兼容性的工作量。
默認的序列化方式盡管方便,但是有以下不足之處:
- (1)直接對對象的不易對外公開的敏感數據進行序列化,這是不安全的。
- (2)不會檢查對象的成員變量是否符合正確的約束條件。
- (3)默認的序列化方式需要對對象圖進行遞歸遍歷,如果對象圖很復雜,會消耗很多空間和時間,甚至引起Java虛擬機的堆棧溢出。
- (4)使類的接口被類的內部實現所束縛,制約類的升級與維護。
為了克服默認序列化方式的不足之處,可以采用以下兩種方式控制序列化的行為:
- (1)可序列化類不僅實現Serializable接口,并且提供private類型的writeObject()和readObject()方法,由這兩個方法負責序列化和反序列化。
- (2)可序列化類不僅實現Externalizable接口,并且實現writeExternal()和readExternal()方法,由這兩個方法負責序列化和反序列化。這種可序列化類必須提供public類型的不帶參數的構造方法,因為反序列化操作會先調用類的不帶參數的構造方法。
)












)

)



