【深度學習】AlexNet網絡實現貓狗分類
AlexNet簡介
AlexNet是一種卷積神經網絡(Convolutional Neural Network,CNN)模型,它在2012年的ImageNet圖像分類挑戰賽中取得了重大突破,引發了深度學習在計算機視覺領域的熱潮。下面是對AlexNet模型和CNN模型的關系以及原理的解釋:
- AlexNet模型是一種CNN模型:
-
AlexNet是一種典型的卷積神經網絡模型,它由多個卷積層、池化層和全連接層組成,通過這些層的堆疊和組合來提取圖像的特征并進行分類。
-
CNN模型的原理:
-
CNN是一種專門用于處理具有網格結構的數據(如圖像)的深度學習模型。它通過卷積層和池化層來提取圖像的局部特征,并通過全連接層進行分類。
-
卷積層通過卷積操作對輸入圖像進行特征提取,通過滑動一個卷積核(filter)在圖像上進行局部特征的提取,生成特征圖(feature map)。
-
池化層通過降采樣操作減小特征圖的尺寸,并保留主要的特征信息。
-
全連接層將池化層輸出的特征圖轉換為一維向量,并通過全連接神經網絡進行分類。
3.AlexNet模型的原理:
- AlexNet模型是由Alex Krizhevsky等人提出的,它在CNN模型的基礎上進行了一些創新和改進。
- AlexNet模型的網絡結構包括多個卷積層、池化層和全連接層,其中使用了ReLU激活函數來增強非線性特性。
4.AlexNet模型的特點包括:
-
使用多個卷積層和池化層進行特征提取,通過堆疊多個卷積層來逐漸提取更高級別的特征。
-
使用了局部響應歸一化(Local Response Normalization)層來增強模型的泛化能力。
-
使用了Dropout層來減少過擬合。
-
使用了大規模的訓練數據和數據增強技術來提高模型的性能。
-
AlexNet模型在ImageNet圖像分類挑戰賽中取得了顯著的成績,為后續的深度學習模型的發展奠定了基礎。
總結來說,AlexNet模型是一種經典的CNN模型,它通過卷積層、池化層和全連接層來提取圖像的特征并進行分類。AlexNet模型在深度學習的發展中起到了重要的作用,對后續的CNN模型設計和圖像分類任務產生了深遠的影響。
代碼:
1.導入所需的庫:
torch:PyTorch庫,用于構建和訓練神經網絡模型。
torch.nn:PyTorch的神經網絡模塊,包含了構建神經網絡所需的類和函數。
torch.optim:PyTorch的優化器模塊,包含了各種優化算法。
torchvision.transforms:PyTorch的圖像轉換模塊,用于對圖像進行預處理。
warnings:Python的警告模塊,用于忽略警告信息。
torch.utils.data:PyTorch的數據加載模塊,用于加載和處理數據。
torchvision.datasets:PyTorch的數據集模塊,包含了常用的圖像數據集。
torchvision.models:PyTorch的預訓練模型模塊,包含了一些經典的神經網絡模型。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import warnings
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision.models import alexnet
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
2.數據預處理并加載數據:
# 檢查是否有可用的GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
#cuda顯卡warnings.filterwarnings("ignore")# 數據預處理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加載訓練數據和測試數據
train_dataset = ImageFolder("dataset/train", transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_dataset = ImageFolder("dataset/test", transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
通過torch.cuda.is_available()函數判斷是否有可用的GPU,并將設備設置為’cuda’或’cpu’。
使用torchvision.transforms.Compose函數定義了一系列的圖像轉換操作,包括調整大小、轉換為張量、歸一化等。
使用torchvision.datasets.ImageFolder類加載訓練數據集和測試數據集,并應用之前定義的數據預處理操作。
使用torch.utils.data.DataLoader類將數據集包裝成可迭代的數據加載器,設置批量大小和是否打亂數據。
3.定義AlexNet模型:
# 定義AlexNet模型
class AlexNet(nn.Module):def __init__(self, num_classes=2):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((6, 6))self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xmodel = AlexNet()# 將模型移動到GPU上
model = model.to(device)
創建一個繼承自torch.nn.Module的子類AlexNet,其中包含了AlexNet模型的網絡結構和前向傳播方法。
網絡結構包括卷積層、ReLU激活函數、最大池化層和全連接層。
通過self.features定義了卷積層和池化層的結構,通過self.classifier定義了全連接層的結構。
前向傳播方法將輸入數據經過卷積層、池化層、全連接層等操作,得到輸出結果。
創建一個AlexNet模型的實例對象model。
使用model.to(device)將模型移動到之前檢查的可用設備上。
4.定義損失函數和優化器:
# 定義損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
定義交叉熵損失函數nn.CrossEntropyLoss()。
定義隨機梯度下降優化器optim.SGD,設置學習率和動量。
5.定義學習率調度器:
# 定義學習率調度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
使用optim.lr_scheduler.StepLR定義學習率調度器,設置學習率衰減的步長和衰減因子。
6.訓練模型:
# 訓練模型
epochs = 10 # 修改為您想要的訓練輪數
train_loss_list = []
train_acc_list = []
test_acc_list = []
for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for images, labels in train_loader:images = images.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()train_accuracy = correct / totaltrain_loss = running_loss / len(train_loader)train_loss_list.append(train_loss)train_acc_list.append(train_accuracy)# 測試模型correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()test_accuracy = correct / totaltest_acc_list.append(test_accuracy)print("Epoch {} - Training loss: {:.4f} - Training accuracy: {:.4f} - Test accuracy: {:.4f}".format(epoch, train_loss, train_accuracy, test_accuracy))# 更新學習率scheduler.step()
使用range(epochs)循環進行指定輪數的訓練。
在每個epoch中,遍歷訓練數據集,將數據移動到設備上,通過前向傳播計算輸出,計算損失并進行反向傳播和優化。
計算訓練集的準確率和損失,并將其記錄在列表中。
在每個epoch結束后,使用測試數據集評估模型的準確率,并將其記錄在列表中。
打印每個epoch的訓練損失、訓練準確率和測試準確率。
使用學習率調度器更新學習率。
7.保存模型:
# 保存模型
torch.save(model.state_dict(), "alexnet.pth")
8.加載預訓練的模型參數:
model.load_state_dict(torch.load('alexnet.pth'))
9.將模型移動到CPU上進行預測:
model = model.to('cpu')
10.可視化預測結果:
examples = enumerate(test_loader)
_, (imgs, _) = next(examples)fig = plt.figure()
# for i in range(len(imgs)):
for i in range(20):img = imgs[i].numpy()img = img.transpose(1, 2, 0)img = (img + 1) / 2with torch.no_grad():output = model(torch.unsqueeze(imgs[i], 0))_, predicted = torch.max(output.data, 1)if predicted.item() == 0:pre_value = "狗"else:pre_value = "貓"plt.subplot(6, 5, i + 1)###########################plt.tight_layout()plt.imshow(img)plt.title("預測值: {}".format(pre_value))plt.xticks([])plt.yticks([])plt.show()
從測試數據集中獲取一批圖像數據。
對每個圖像進行預測,并將預測結果和圖像可視化展示出來。
運行結果:
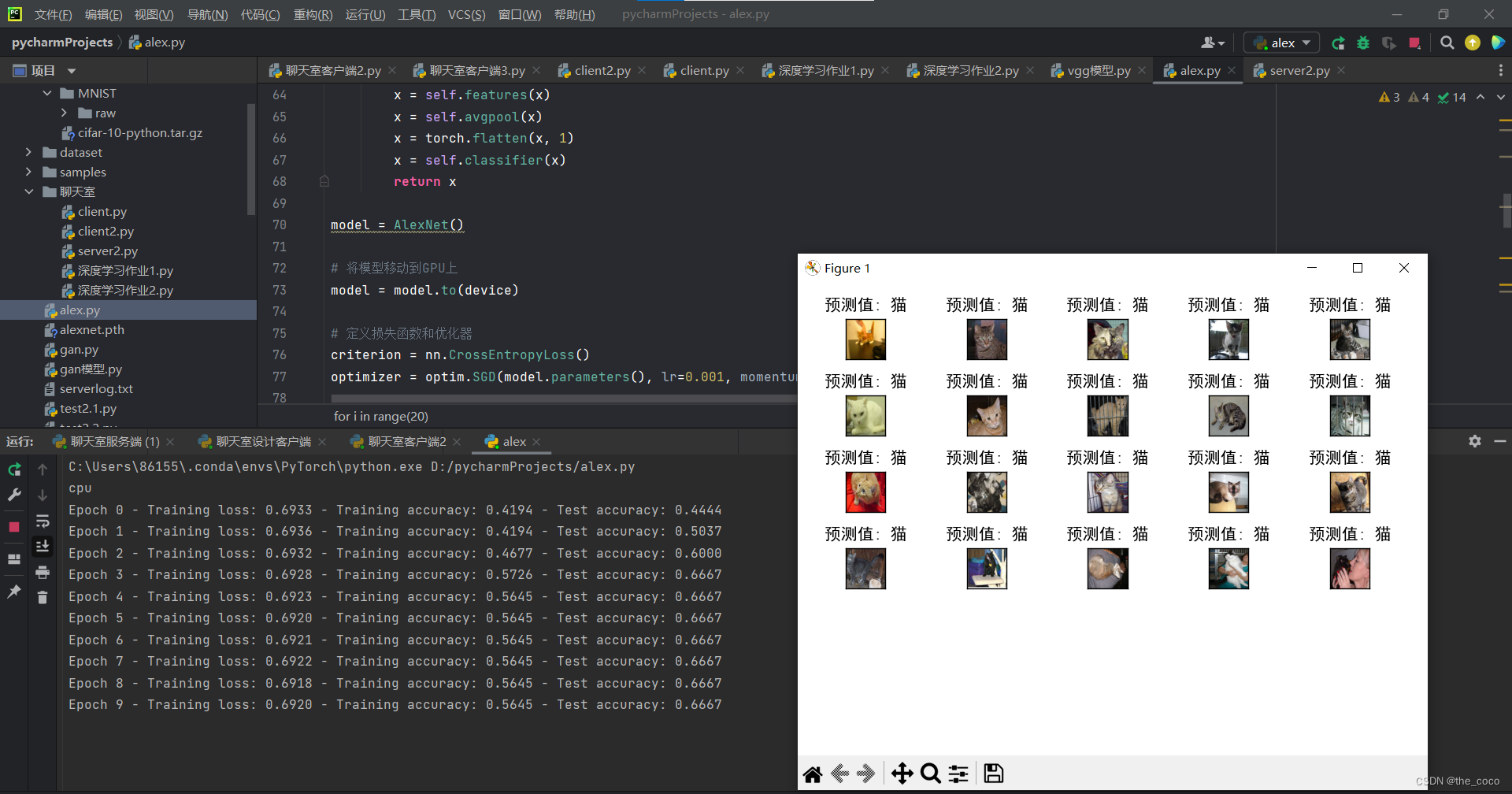 注:數據集可以更換為自己的數據集
注:數據集可以更換為自己的數據集
完整代碼:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import warnings
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision.models import alexnet
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽# 檢查是否有可用的GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
#cuda顯卡warnings.filterwarnings("ignore")# 數據預處理
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加載訓練數據和測試數據
train_dataset = ImageFolder("dataset/train", transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_dataset = ImageFolder("dataset/test", transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)# 定義AlexNet模型
class AlexNet(nn.Module):def __init__(self, num_classes=2):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((6, 6))self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xmodel = AlexNet()# 將模型移動到GPU上
model = model.to(device)# 定義損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# 定義學習率調度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)# 訓練模型
epochs = 10 # 修改為您想要的訓練輪數
train_loss_list = []
train_acc_list = []
test_acc_list = []
for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for images, labels in train_loader:images = images.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()train_accuracy = correct / totaltrain_loss = running_loss / len(train_loader)train_loss_list.append(train_loss)train_acc_list.append(train_accuracy)# 測試模型correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()test_accuracy = correct / totaltest_acc_list.append(test_accuracy)print("Epoch {} - Training loss: {:.4f} - Training accuracy: {:.4f} - Test accuracy: {:.4f}".format(epoch, train_loss, train_accuracy, test_accuracy))# 更新學習率scheduler.step()# 保存模型
torch.save(model.state_dict(), "alexnet.pth")# 加載預訓練的模型參數
model.load_state_dict(torch.load('alexnet.pth'))# 將模型移動到CPU上進行預測
model = model.to('cpu')examples = enumerate(test_loader)
_, (imgs, _) = next(examples)fig = plt.figure()
# for i in range(len(imgs)):
for i in range(20):img = imgs[i].numpy()img = img.transpose(1, 2, 0)img = (img + 1) / 2with torch.no_grad():output = model(torch.unsqueeze(imgs[i], 0))_, predicted = torch.max(output.data, 1)if predicted.item() == 0:pre_value = "狗"else:pre_value = "貓"plt.subplot(6, 5, i + 1)###########################plt.tight_layout()plt.imshow(img)plt.title("預測值: {}".format(pre_value))plt.xticks([])plt.yticks([])plt.show()


)









)
)





