本文介紹了一次排查Elasticsearch node_concurrent_recoveries 引發的性能問題的過程。
一、故障描述
1.1 故障現象
1. 業務反饋
業務部分讀請求拋出請求超時的錯誤。
2. 故障定位信息獲取
-
故障開始時間
19:30左右開始
-
故障拋出異常日志
錯誤日志拋出timeout錯誤。
-
故障之前的幾個小時業務是否有進行發版迭代。
未進行相關的發版迭代。
-
故障的時候流量是否有出現抖動和突刺情況。
內部監控平臺觀察業務側并沒有出現流量抖動和突刺情況。
-
故障之前的幾個小時Elasticsearch集群是否有出現相關的變更操作。
Elasticsearch集群沒有做任何相關的變更操作。
1.2 環境
-
Elaticsearch的版本:6.x。
-
集群規模:集群數據節點超過30+。
二、故障定位
我們都知道Elasticsearch是一個分布式的數據庫,一般情況下每一次查詢請求協調節點會將請求分別路由到具有查詢索引的各個分片的實例上,然后實例本身進行相關的query和fetch,然后將查詢結果匯總到協調節點返回給客戶端,因此存在木桶效應問題,查詢的整體性能則是取決于是查詢最慢的實例上。所以我們需要確認導致該故障是集群整體的問題還是某些實例的問題導致的。
2.1 集群還是實例的問題
1. 查看所有實例的關鍵監控指標
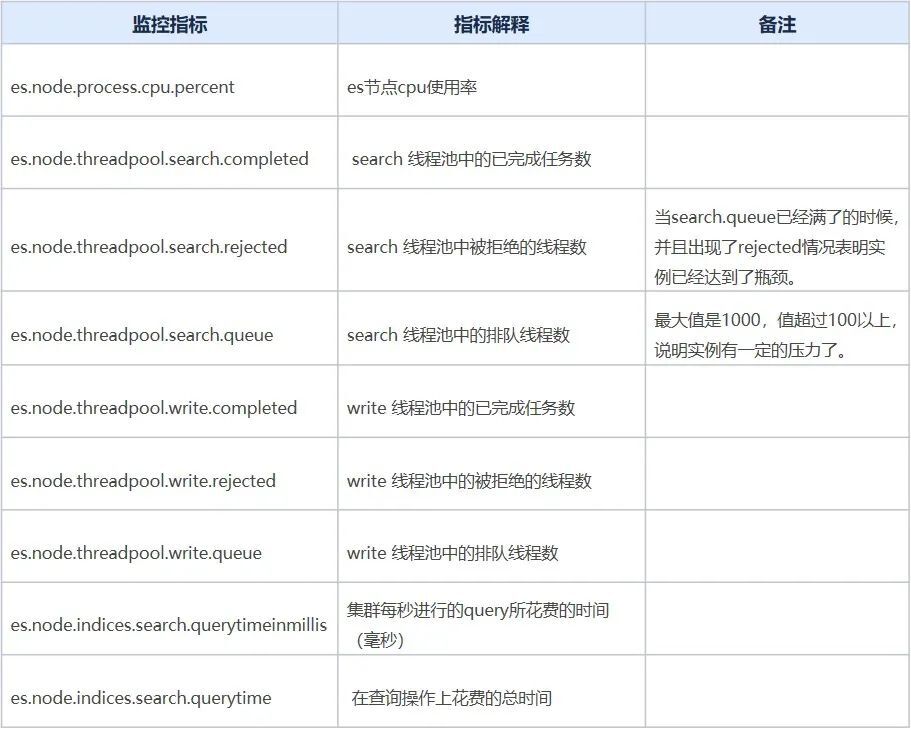
從監控圖可以很明顯的綠色監控指標代表的實例在19:30左右開始是存在異常現象,在這里我們假設該實例叫做A。
-
實例A的指標es.node.threadpool.search.queue的值長時間達到了1000,說明讀請求的隊列已經滿了。
-
實例A的指標es.node.threadpool.search.rejected的值高峰期到了100+,說明實例A無法處理來自于業務的所有請求,有部分請求是失敗的。
-
集群整體的指標es.node.threadpool.search.completed有出現增長,經過業務溝通和內部平臺監控指標的觀察,業務流量平緩,并沒有出現抖動現象,但是客戶端有進行異常重試機制,因此出現增長是因為重試導致。
-
實例A的指標es.node.threadpool.search.completed相比集群其他實例高50%以上,說明實例A上存在一個到多個熱點索引。
-
實例A的指標es.node.threadpool.cpu.percent的值有50%以上的增長。
-
可通過指標es.node.indices.search.querytime和es.node.indices.search.querytimeinmillis的趨勢可實例級別的請求耗時大致情況。
通過上面的分析,我們能給確認的是實例A是存在異常,但是導致業務請求超時是否是實例A異常導致,還需進一步分析確認。
2.2 實例異常的原因
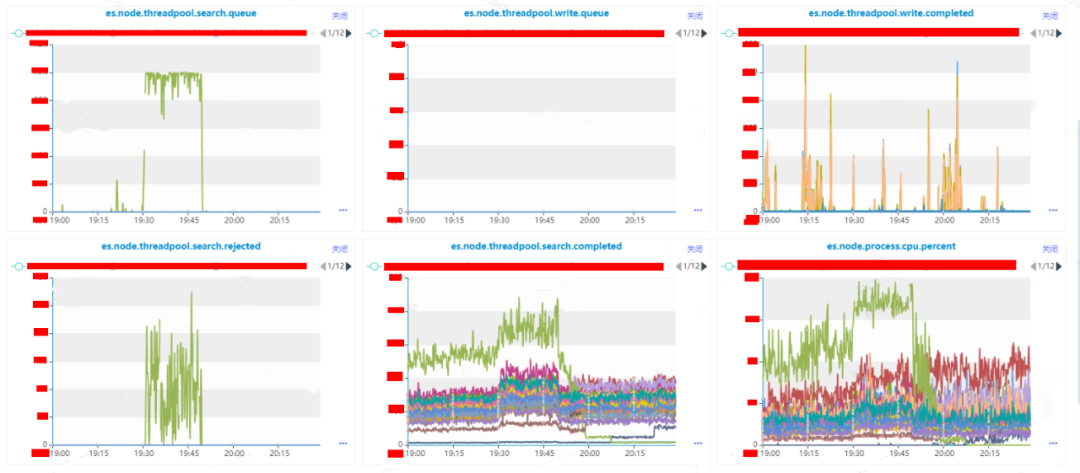
到了這一步,我們能夠非常明確實例是存在異常情況,接下來我們需要定位是什么導致實例異常。在這里我們觀察下實例所在機器的MEM.CACHED、DISK.nvme0n1.IO.UTIL、CPU.SERVER.LOADAVG.PERCORE、CPU.IDLE這些CPU、MEMMORY、DISK IO等指標。
1. CPU or IO
通過監控,我們可以很明顯的看得到,DISK.nvme0n1.IO.UTIL、CPU.SERVER.LOADAVG.PERCORE、CPU.IDLE這三個監控指標上是存在異常情況的。
DISK.nvme0n1.IO.UTIL上深紅色和深褐色指標代表的機器IO使用率存在異常,在這里我們假設深紅色的機器叫做X,深褐色的機器叫做Y。
CPU.SERVER.LOADAVG.PERCORE和CPU.IDLE這倆個反應CPU使用情況的指標上代表綠色的機器在存在異常,在這里我們假設綠色的機器叫做Z。
-
機器X的IO在故障時間之前就處于滿載情況,機器X在整個過程當中是沒有出現波動,因此可移除機器X可能導致集群受到影響。
-
機器Y的IO在故障時間之前是處于滿載情況,但是在故障期間IO使用率差不多下降到了50%,因此可移除機器Y可能導致集群受到影響。
-
機器Z的CPU使用率在在故障期間直線下降,CPU.IDLE直接下降到個位數;CPU.SERVER.LOADAVG.PERCORE(是單核CPU的平均負載,2.5表示當前負載是CPU核數*2.5)直接增長了4倍,此時整個機器幾乎都是處于阻塞的情況;DISK.nvme0n1.IO.UTIL則是從20%增長到了50%左右。其中CPU的指標是直線增長,IO的指標則是一個曲線增長。
異常實例A所在的機器是Z,目前機器Z的CPU和IO都存在增長情況,其中CPU已經到了系統的瓶頸,系統已經受到了阻塞,IO的利用率從20%增長到了50%,雖然有所增長,但是還未到達磁盤的瓶頸。
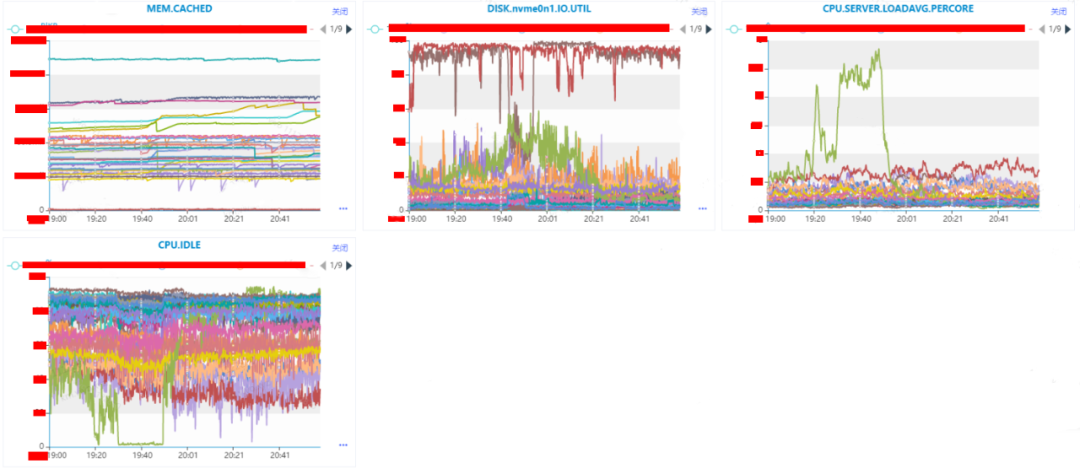
通過上面的分析,我們比較傾向于機器Z的CPU的異常導致了實例A的異常。這個時候我們需要確認是什么原因導致了機器Z的CPU異常,這個時候可通過內部監控平臺的快照查看機器Z的快照信息。
通過內部監控平臺的快照,我們可以看到PID為225543的CPU使用率是2289.66%,166819的CPU的使用率是1012.88%。需要注意的是我們機器Z的邏輯核是32C,因此我們可認為CPU機器CPU的使用率理論上最高是3200%。但是使用率CPU最高的倆個實例的值加起來已經是超過了這個值,說明CPU資源已經是完全被使用完畢了的。
通過登陸機器Z,查詢獲取得到PID為225543的進程就是實例A的elasticsearch進程。
2. 實例CPU異常的原因
其實Elasticsearch本身是有接口提供獲取實例上的熱點進程,但是當時執行接口命令的時候長時間沒有獲取到結果,因此只能從其他方案想辦法了。
獲取實例上的熱點進程:
curl -XGET /_nodes/xx.xx.xx.xx/hot_threads?pretty -s實例A的CPU使用率高一般導致這個情況原因一個是并發過高導致實例處理不過來,另外一個則是存在任務長時間占據了進程資源,導致無多余的資源處理其他的請求。所以我們首先基于這倆個情形進行分析。
(1)是否并發度過高引起實例CPU異常
從之前的分析我們可以得知業務側的流量是沒有出現突增,search.completed的增長只是因為業務重試機制導致的,因此排除并發過高的原因了,那么剩下的就只有存在長任務的原因了。
(2)是否長任務導致實例CPU異常
根據_cat/tasks查看當前正在執行的任務,默認會根據時間進行排序,任務running時間越長,那么就會排到最前面,上面我們得知異常的實例只有A,因此我們可以只匹配實例A上的任務信息。
curl -XGET '/_cat/tasks?v&s=store' -s | grep A一般情況下大部分任務都是在秒級以下,若是出現任務執行已超過秒級或者分鐘級的任務,那么這個肯定就是屬于長任務。
(3)什么長任務比較多
根據接口可以看得到耗時較長的都是relocate任務,這個時候使用查看接口/_cat/shards查看分片遷移信息,并且并發任務還很多,持續時間相較于其他任務來說很長。
curl -XGET '/_cat/shards?v&s=store' -s | grep A由于當時是優先恢復業務,因此沒有截圖,最后只能從監控獲取得到這個時間是有進行relocate分片的遷移操作:
-
es.node.indices.segment.count:實例級別segment的個數。
-
es.cluster.relocatingshards:集群級別正在進行relocate的分片數量。
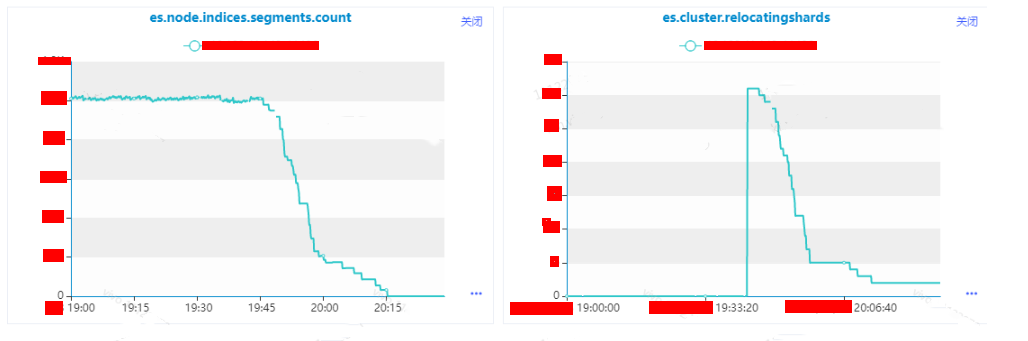
(4)什么原因導致了分片遷移變多
?根據日常的運維,一般出現分片遷移的情況有:
-
實例故障。
-
人工進行分片遷移或者節點剔除。
-
磁盤使用率達到了高水平位。
根據后續的定位,可以排除實例故障和人工操作這倆項,那么進一步定位是否由于磁盤高水平位導致的。
查看實例級別的監控:
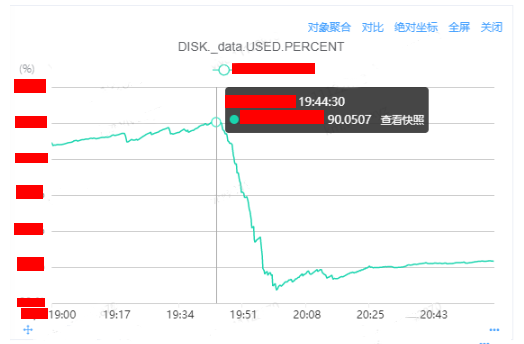
查看master的日志:
[xxxx-xx-xxT19:43:28,389][WARN ][o.e.c.r.a.DiskThresholdMonitor] [master] high disk watermark [90%] exceeded on [ZcphiDnnStCYQXqnc_3Exg][A][/xxxx/data/nodes/0] free: xxxgb[9.9%], shards will be relocated away from this node
[xxxx-xx-xxT19:43:28,389][INFO ][o.e.c.r.a.DiskThresholdMonitor] [$B] rerouting shards: [high disk watermark exceeded on one or more nodes]根據監控和日志能夠進一步確認是磁盤使用率達到了高水平位從而導致的遷移問題。
(5)確認引起磁盤上漲的實例
通過內部監控平臺的DB監控,查看機器級別上所有實例的監控指標
es.instance.data_size:
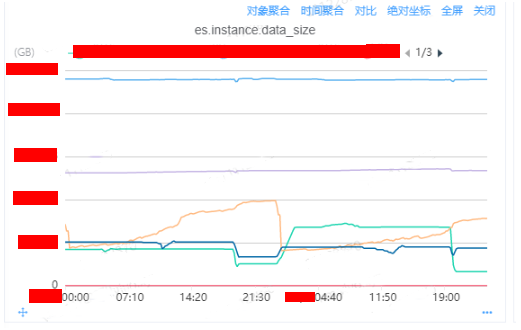
通過監控我們分析可以得到淺黃色、深藍色、淺綠色三個實例是存在較大的磁盤數據量大小的增長情況,可以比較明顯導出磁盤增長到90%的原因是淺黃色線代表的實例導致的原因。
2.3 根因分析
針對實例A磁盤波動情況進行分析:
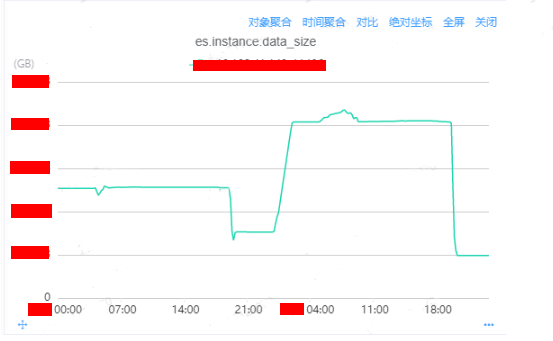
查看這個監控圖,你會發現存在異常:
-
磁盤數據量的下降和上升并不是一個緩慢的曲線。
-
2023-02-07 19:20左右也發生過磁盤下降的情況。
出現磁盤的下降和趨勢一次性比較多的情況,根據以往的經驗存在:
-
大規模的刷數據。
-
relocate的分片是一個大分片。
-
relocate并發數比較大。
第一個排除了,大規模的刷數據只會導致數據上升,并不會出現數據下降的情況,因此要么就是大分片,要么就是并發較大。
查看是否存在大分片:
# curl -XGET '/_cat/shards?v&s=store' -s | tail
index_name 4 r STARTED 10366880 23.2gb
index_name 4 p STARTED 10366880 23.2gb
index_name 0 r STARTED 10366301 23.2gb
index_name 0 p STARTED 10366301 23.2gb
index_name 3 p STARTED 10347791 23.3gb
index_name 3 r STARTED 10347791 23.3gb
index_name 2 p STARTED 10342674 23.3gb
index_name 2 r STARTED 10342674 23.3gb
index_name 1 r STARTED 10328206 23.4gb
index_name 1 p STARTED 10328206 23.4gb查看是否存在重定向并發數較大:
# curl -XGET '/_cluster/settings?pretty'
{
... ..."transient" : {"cluster" : {"routing" : {"allocation" : {"node_concurrent_recoveries" : "5","enable" : "all"}}}}
}發現參數cluster.allocation.node_concurrent_recoveries設置成了5,我們看下官方針對這個參數的解釋:Cluster Level Shard Allocation | Elasticsearch Guide [6.3] | Elastic
大致意思是同一個時間允許多個的分片可以并發的進行relocate或者recovery,我們就按照較大的分片數量20G*5,差不多就是100G左右,這個就解釋了為什么data_size的增長和下降短時間內非常大的數據量的原因了。
到目前為止,我們能夠確認的是因為分片遷移的問題消耗了實例A很大的CPU資源,從而導致實例A的CPU指標非常的高。
三、解決方案
基于上面的分析,我們假設由于實例A的異常導致集群整的異常;基于這種假設,我們嘗試將實例A剔除集群,觀察集群和業務的請求是否能夠恢復。
3.1 猜想驗證
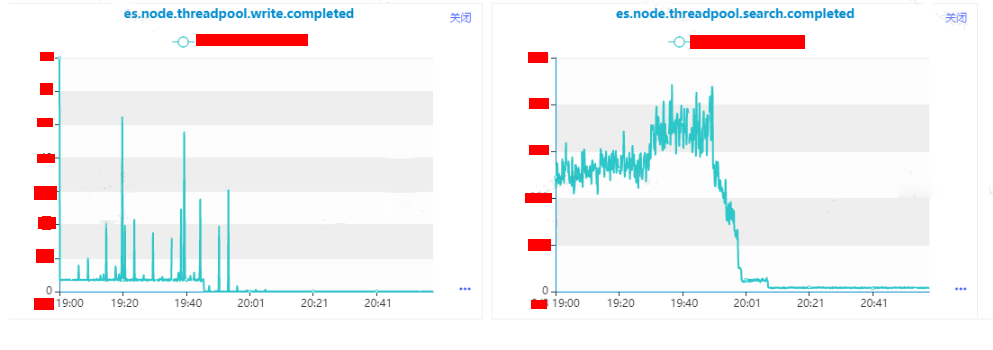
將實例的分片遷移到其他的實例上,執行以下命令之后,可以明顯的發現實例上的請求基本上下降為零了,并且業務反饋超時也在逐步的減少,基于這個情況驗證了我們的猜想,是實例A的異常導致了業務的請求超時的情況。
curl -XPUT /_cluster/settings?pretty -H 'Content-Type:application/json' -d '{"transient":{"cluster.routing.allocation.exclude._ip": "xx.xx.xx.xx"}
}'
3.2 根本解決
猜想驗證確認之后,那我們現在基于實例A的CPU的異常結果進行相關的優化:
修改參數cluster.routing.allocation.node_concurrent_recoveries
-
該參數默認值是2,一般是不建議修改這個參數,但是有需要快速遷移要求的業務可以動態修改這個參數,建議不要太激進,開啟之后需要觀察實例、機器級別的CPU、磁盤IO、網絡IO的情況。
修改參數cluster.routing.use_adaptive_replica_selection
-
開啟該參數之后,業務針對分片的讀取會根據請求的耗時的響應情況選擇下次請求是選擇主分片還是副分片。
-
6.3.2版本默認是關閉了該參數,業務默認會輪詢查詢主副分片,這在部分實例異常的情況會影響集群的整體性能。針對生產環境、單機多實例混合部署的情況下,建議開啟該參數,對集群的性能有一定的提高。
-
7.x的版本默認是開啟了這個參數。
curl -XPUT /_cluster/settings?pretty -H 'Content-Type:application/json' -d '{"transient":{"cluster.routing.allocation.node_concurrent_recoveries": 2,"cluster.routing.use_adaptive_replica_selection":true }
}'直接擴容或者遷移實例也是比較合適的。
四、總結
在本次故障,是由于集群參數配置不正確,導致集群的一個實例出現異常從而導致了業務的請求異常。但是在我們在進行故障分析的時候,不能僅僅只是局限于數據庫側,需要基于整個請求鏈路的分析,從業務側、網絡、數據庫三個方面進行分析:
-
業務側:需確認業務的所在的機器的CPU、網絡和磁盤IO、內存是否使用正常,是否有出現資源爭用的情況;確認JVM的gc情況,確認是否是因為gc阻塞導致了請求阻塞;確認流量是否有出現增長,導致Elasticsearch的瓶頸。
-
網絡側:需確認是否有網絡抖動的情況。
-
數據庫側:確認是Elasticsearch是否是基于集群級別還是基于實例級別的異常;確認集群的整體請求量是否有出現突增的情況;確認異常的實例的機器是否有出現CPU、網絡和磁盤IO、內存的使用情況。
確認哪方面的具體故障之后,就可以進一步的分析導致故障的原因。
參數控制:
Elasticsearch本身也有一些參數在磁盤使用率達到一定的情況下來控制分片的分配策略,默認該策略是開啟的,其中比較重要的參數:
-
cluster.routing.allocation.disk.threshold_enabled:默認值是true,開啟磁盤分分配決策程序。
-
cluster.routing.allocation.disk.watermark.low:默認值85%,磁盤使用低水位線。達到該水位線之后,集群默認不會將分片分配達到該水平線的機器的實例上,但是新創建的索引的主分片可以被分配上去,副分片則不允許。
-
cluster.routing.allocation.disk.watermark.high:默認值90%,磁盤使用高水位線。達到該水位線之后,集群會觸發分片的遷移操作,將磁盤使用率超過90%實例上的分片遷移到其他分片上。
-
cluster.routing.allocation.disk.watermark.high:默認值95%。磁盤使用率超過95%之后,集群會設置所有的索引開啟參數read_only_allow_delete,此時索引是只允許search和delete請求。
補充:
一旦一臺機器上的磁盤使用率超過了90%,那么這臺機器上所有的ES實例所在的集群都會發起分片的遷移操作,那么同一時間發起并發的最大可能是:ES實例數*cluster.routing.allocation.node_concurrent_recoveries,這個也會導致機器的CPU、IO等機器資源進一步被消耗,從而所在的實例性能會更差,從而導致路由到機器上實例的分片的性能會更差。
一旦一臺機器上磁盤使用率超過95%,那么這臺機器上所有的實例所在的集群都會開啟集群級別的參數read_only_allow_delete,此時不僅僅是一個集群,而是一個或者多個集群都無法寫入,只能進行search和delete。
文章轉載自:vivo互聯網技術
原文鏈接:https://www.cnblogs.com/vivotech/p/17851197.html

)
漢化教程)




問題的提出)











