淺談擴散模型的有分類器引導和無分類器引導 - 知乎這篇文章主要比較一下擴散模型的引導生成的三種做法的區別。它們分別是用顯式分類器引導生成的做法,用隱式無分類器引導的做法和用CLIP計算跨模態間的損失來引導生成的做法。 Classifier-Guidance: Diffusion Mode…![]() https://zhuanlan.zhihu.com/p/582880086通俗理解Classifier Guidance 和 Classifier-Free Guidance 的擴散模型 - 知乎【當一個擴散模型訓練好了之后,如何進行條件生成,例如如何按類別生成?】一、 Classifier Guidance Diffusion2021年OpenAI在「 Diffusion Models Beat GANs on Image Synthesis」中提出Classifier Guidance,使…
https://zhuanlan.zhihu.com/p/582880086通俗理解Classifier Guidance 和 Classifier-Free Guidance 的擴散模型 - 知乎【當一個擴散模型訓練好了之后,如何進行條件生成,例如如何按類別生成?】一、 Classifier Guidance Diffusion2021年OpenAI在「 Diffusion Models Beat GANs on Image Synthesis」中提出Classifier Guidance,使…![]() https://zhuanlan.zhihu.com/p/640631667Diffusion學習筆記(五)——Conditional Control(Classifier-Guidance and Classifier-Free) - 知乎前幾篇文章都是討論無條件生成式的Diffusion模型,只能隨機采樣,無法控制模型的輸出。但很多時候,我們要求得到與指定文本信息或者與圖像信息對應的輸出(即文生圖或圖生圖),這就需要用到條件控制生成技術了。…
https://zhuanlan.zhihu.com/p/640631667Diffusion學習筆記(五)——Conditional Control(Classifier-Guidance and Classifier-Free) - 知乎前幾篇文章都是討論無條件生成式的Diffusion模型,只能隨機采樣,無法控制模型的輸出。但很多時候,我們要求得到與指定文本信息或者與圖像信息對應的輸出(即文生圖或圖生圖),這就需要用到條件控制生成技術了。…![]() https://zhuanlan.zhihu.com/p/623837604[論文理解] Classifier-Free Diffusion Guidance – sunlin-ai關于 Classifier-Free Diffusion 的論文理解
https://zhuanlan.zhihu.com/p/623837604[論文理解] Classifier-Free Diffusion Guidance – sunlin-ai關于 Classifier-Free Diffusion 的論文理解![]() https://sunlin-ai.github.io/2022/06/01/Classifier-Free-Diffusion.htmlclassifer gudiance的classifer是用于生成任務還是分類任務? - 知乎和classifier-free guidance的區別是什么?
https://sunlin-ai.github.io/2022/06/01/Classifier-Free-Diffusion.htmlclassifer gudiance的classifer是用于生成任務還是分類任務? - 知乎和classifier-free guidance的區別是什么?![]() https://www.zhihu.com/question/607447662擴散模型引導生成的三種做法:1.classifier guidance,顯式分類器引導生成;2.classifier-free guidance隱式無分類器引導生成;3.clip計算跨模態間的損失引導生成。其中第1種和第2種可以描述為:1.classifier guidance是無條件輸入+classifier指導;2.classifier-free guidance是條件輸入+無條件輸入。可以對應到gan上,gan也有條件gan和非條件gan,gan里面大多數還是非條件gan,比如stylegan,非條件在特定領域訓一波,比如人臉還是很有用的,條件gan,按照我之前的經驗,效果有待商榷。擴散模型中,非條件的基本就是ddpm等這種生圖算法,文生圖就屬于條件diffusion,那么文本這類condition在訓練時如何引導就涉及到了classifier guidance這類方法,gan中比較簡單,基本上是把類別的embedding直接拼到采樣的隨機噪聲中,而diffusion model中要設計如何處理text embedding的問題,如何是cfg的話,就是條件輸入+無條件輸入,就是隨機drop text embedding這種方式。
https://www.zhihu.com/question/607447662擴散模型引導生成的三種做法:1.classifier guidance,顯式分類器引導生成;2.classifier-free guidance隱式無分類器引導生成;3.clip計算跨模態間的損失引導生成。其中第1種和第2種可以描述為:1.classifier guidance是無條件輸入+classifier指導;2.classifier-free guidance是條件輸入+無條件輸入。可以對應到gan上,gan也有條件gan和非條件gan,gan里面大多數還是非條件gan,比如stylegan,非條件在特定領域訓一波,比如人臉還是很有用的,條件gan,按照我之前的經驗,效果有待商榷。擴散模型中,非條件的基本就是ddpm等這種生圖算法,文生圖就屬于條件diffusion,那么文本這類condition在訓練時如何引導就涉及到了classifier guidance這類方法,gan中比較簡單,基本上是把類別的embedding直接拼到采樣的隨機噪聲中,而diffusion model中要設計如何處理text embedding的問題,如何是cfg的話,就是條件輸入+無條件輸入,就是隨機drop text embedding這種方式。
1.classifier guidance 顯式分類器引導生成
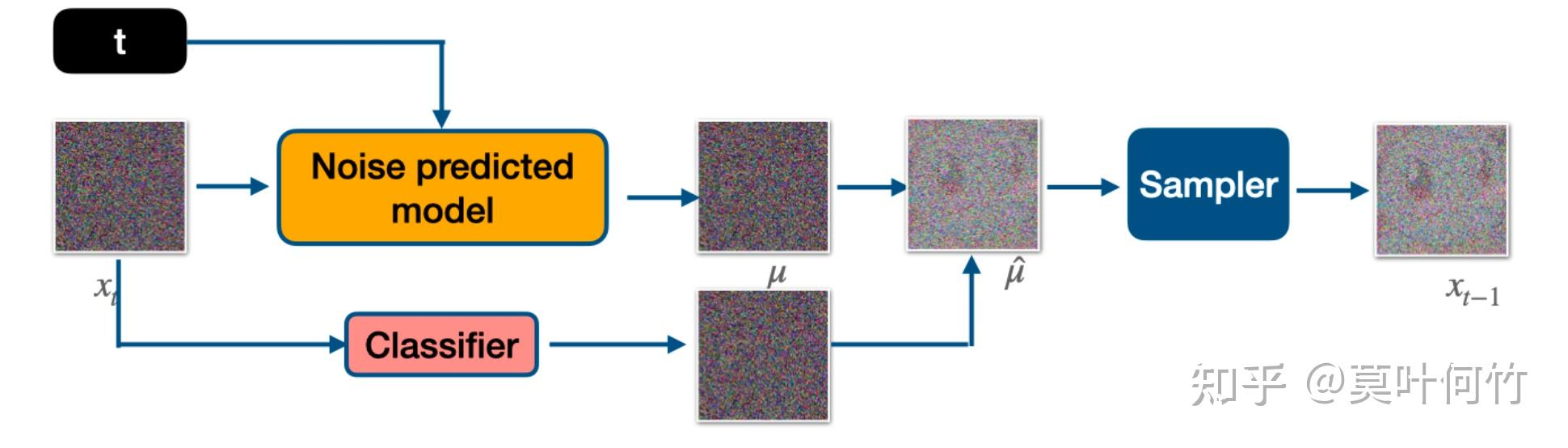
也叫事后修改,即給定一個訓練好的無條件diffusion模型,再進行條件控制輸出。擴散模型的前向擴散過程和后向去噪過程都可以用一個隨機微分方程表示,其中后向去噪時,可以通過一個神經網絡來擬合當前輸入關于原數據分布的梯度,來將一個先驗分布(如高斯分布)里采樣出的點逐漸推進到數據分布里。后向生成可以看成是一個馬爾科夫蒙特卡洛采樣過程,其中每一步的轉移方程都是沿著往數據分布的梯度方向邁進,且該方向由神經網絡的輸出來擬合。DDPM里擴散網絡預測的噪聲實際上是往數據分布的轉移梯度。

生成符合原數據分布的點,可以通過逐步往該網絡的預測梯度方向行走來獲得最終數據點。但是這樣的無條件生成是無法做到條件生成的,2021年openai在diffusion models beat gans on image synthesis中提出classifier guidance,使得擴散模型能夠按類別生成。將條件生成對輸入的對數梯度用貝葉斯拆解一下:

想要獲得數據分布里在條件約束下的數據點時,實際只要在往數據方向的梯度方向上再額外添加一個分類器的梯度方向即可。classifier guidance需要訓練噪聲數據版本的classifier網絡,推理是每一步都需要額外計算classifier的梯度。

多了y關于x的梯度,這個就是classifier guidance。其中logp(y|x)是classifier。

在DDIM中,噪聲估計加上分類器引導的梯度。可以把stable diffusion的預訓練模型拿來用,text設置為空,根據它訓練一個classifier,實現類別指導生成。
2.classifier-free guidance?
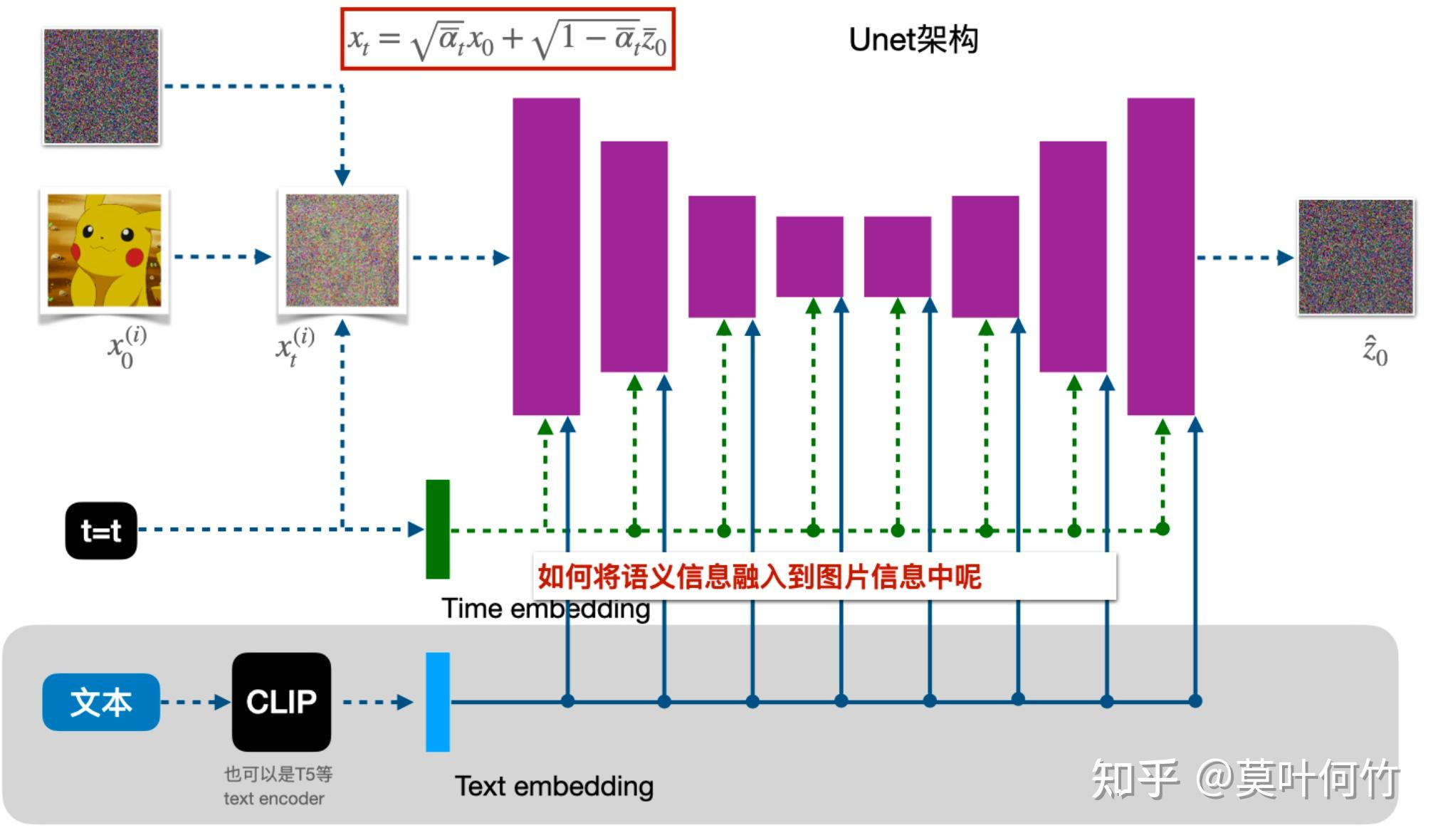
也叫事前修改,即直接將條件y加入到訓練過程中。classifier guidance使用顯式的分類器有幾個問題:1.需要額外訓練一個噪聲版本的圖像分類器;2.該分類器的質量會影響類別生成的效果;3.通過梯度更新圖像會導致對抗攻擊效應,生成圖像可能會通過人眼不可察覺的細節欺騙分類器,實際上并沒有按條件生成。谷歌2022年提出classifier-free guidance,可以通過調節引導權重,控制生成圖像的逼真性和多樣性的平衡,dalle2、imagen、glide和stable dffusion等都是以classifier-free guidance為基礎進行訓練和推理。classifier-free guidance是通過一個隱式分類器來替代顯式分類器,而無需直接計算顯式分類器及其梯度。分類器的梯度可以用條件生成概率和無條件生成概率表示:

新的生成過程不再依賴顯式的classifier,訓練時,classifier-free guidance需要訓練兩個模型,一個是無條件生成模型(DDPM),一個是條件生成模型,這兩個模型可以用一個模型表示,訓練時只需要在無條件生成時將條件向量置為零即可。推理時,最終結果可以由條件生成和無條件生成的線性外推獲得,生成效果可以由引導系數調節,控制樣本生成的逼真性和多樣性。
classifier-free guidance一方面大大減輕了條件生成的訓練代價,無需訓練額外的分類器,只需要在訓練時進行隨機drop out condition來同時訓練兩個目標,另一方面,這樣的條件生成并不是以一個類似于對抗攻擊的方式進行。上面的采樣式子,實際上是另個梯度的差值所形成的。在訓練時同時算了e(xt,t,y)和e(xt,t),然后計算差值就到了加條件的目的。
在stable-diffusion-webui中,negative prompt實際上就用了無分類器引導的公式,將無條件生成轉成不想要的提示的條件生成。
既然網絡可以接受條件輸入,輸出不就自然是根據條件引導生成的結果,為什么還要用無條件的結果?并不是在生成網絡加個條件輸入就是條件生成,條件生成可理解為條件概率問題,cfg是根據隱分類器推導成線性外插的形式。classifier-guidance是每一步要訓練一個分類器引導;classifier-free guidance不用訓練分類器,只要在訓練條件生成模型時,給一個空條件,然后使用真實條件引導+空條件引導來更好的控制條件生成。
stable diffusion在訓練過程中,采用classifier-free guidance,就是在訓練條件擴散模型的同時也訓練一個無條件擴散模型,同時在采樣階段將條件控制下預測的噪聲和無條件控制下的預測噪聲組合在一起來確定最終的噪聲。
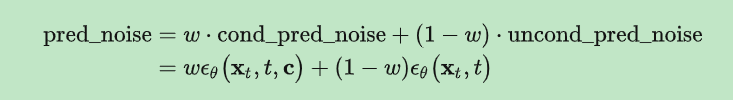
這里w是guidance scale,當w越大時,condition起的作用越大,即生成的圖像和輸入文本一致,cfg實現很簡單,在訓練過程中,只需要以一定概率(比如10%)隨機drop掉text即可,我們可以將text置為空字符串。
3.clip損失引導生成
通過使擴散生成的圖像和目標文本的多模態clip損失盡可能小來達到目的。



問題的提出)














)
