前言:
針對緩存我們并不陌生,而今天所講的是使用redis作為緩存工具進行緩存數據。redis緩存是將數據保存在內存中的,而內存的珍貴性是不可否認的。所以在緩存之前,我們需要明確緩存的對象,是否有必要緩存,怎么做好緩存,怎樣避免緩存失效。
處理Redis常見問題與提高Redis緩存性能
一、Redis作為緩存常見問題及其處理方案
1)緩存穿透
根源:請求不斷的查詢一個不存在的key,緩存層和存儲層都不會命中。
解決方案:? ?
- 對接口參數進行校驗、防止出現惡意攻擊;
- 查詢不到值時,將value設置成一個標記為加入緩存中,下次再查詢就返回一個標記數而不必經過數據庫,例如查詢id為5的商品,不存在則返回一個-9999,然后在做邏輯判斷,但是需要設置一個較短的緩存有效時間,防止以后key對應的value有數據的時候仍然返回空造成錯誤。
- 使用bitmap類型定義一個可以訪問的白名單,id作為偏移量。
- 采用布隆過濾器
2)緩存擊穿
根源:緩存擊穿是指對于一些設置了過期時間的key,這些key可能在某些時間被超高并發訪問,是一種’熱點‘數據,然后在這個數據被訪問前正好key失效了,那么對這個key的查詢會全部轉到數據庫上,造成數據庫壓力增大導致卡頓崩潰的現象。
解決方案:
- 設置熱點數據永不過期;
- 加鎖,大量并發只讓一個人去查,其他人等待,直到以后釋放鎖,其他人讀取到鎖先查緩存。
3)緩存雪崩
根源:大量的熱數據key同時過期,過期之后涌入大量請求,導致請求直接訪問數據庫,驟增數據庫壓力。
解決方案:
- 設置熱點數據永不過期;
- 將緩存過期時間設置成某一段時間內的隨機數,這樣就不會同時過期;
- 分布式處理緩存,將緩存存在不同的地方
- 依賴隔離組件為后端限流熔斷并降級。比如使用Sentinel或Hystrix限流降級組件
4)緩存與數據不一致問題
1、雙寫不一致情況(修改數據更新緩存)
線程1先寫入了數據庫,這時候準備更新緩存,但是因為某原因導致出現延遲,此時線程二快速將新數據寫入數據庫,并且成功更新了緩存,完事之后線程1恢復了速度開始更新緩存,就導致了線程2是最后寫入數據的,但是緩存的內容還是舊值,從而達到雙寫不一致的錯誤場景
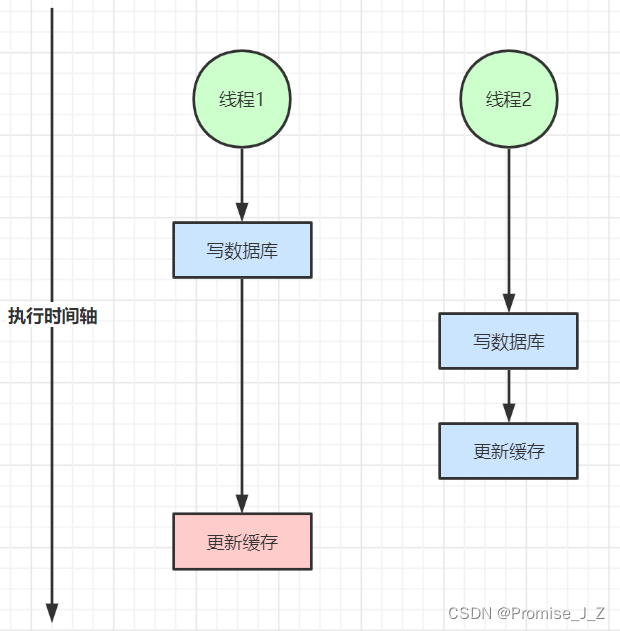
2、讀寫并發不一致(修改數據刪除緩存)
線程一先寫入數據10,并刪除了緩存,之后線程三讀取數據,發現緩存為空,于是去查詢數據庫,而此時查詢數據庫的時間較長,與此同時線程二寫入數據6,又刪除了緩存,在這之后線程三也讀成功更新了緩存,造成了數據庫的結果是6而緩存的結果是10這種錯誤情況
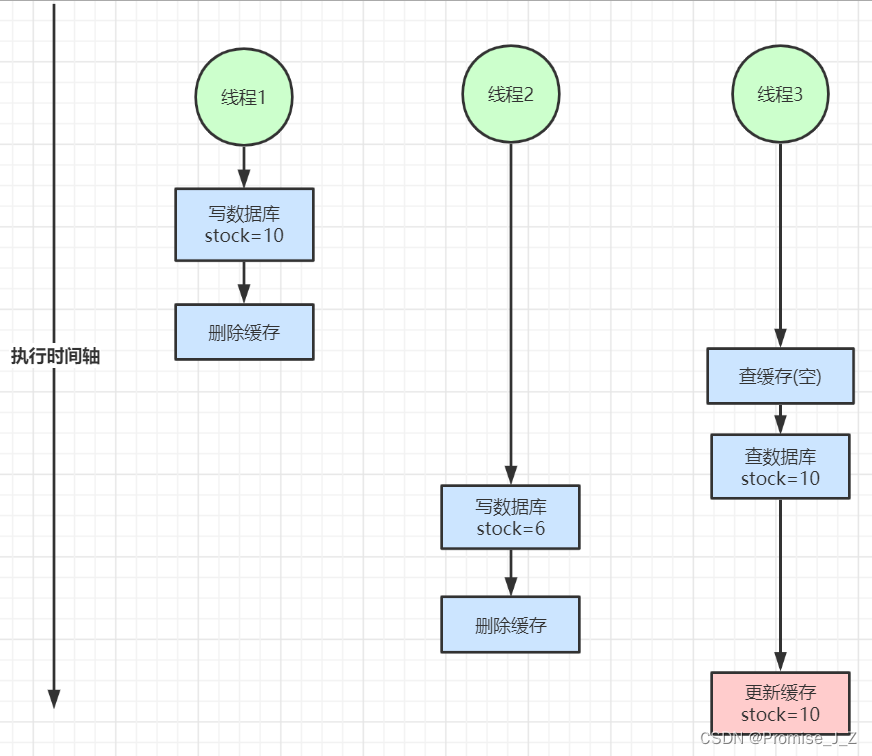
解決方案:
1、對于并發幾率很小的數據(如個人維度的訂單數據、用戶數據等),這種幾乎不用考慮這個問題,很少會發生緩存不一致,可以給緩存數據加上過期時間,每隔一段時間觸發讀的主動更新即可。
2、就算并發很高,如果業務上能容忍短時間的緩存數據不一致(如商品名稱,商品分類菜單等),緩存加上過期時間依然可以解決大部分業務對于緩存的要求。
3、如果不能容忍緩存數據不一致,可以通過加分布式讀寫鎖保證并發讀寫或寫寫的時候按順序排好隊,讀讀的時候相當于無鎖。
4、也可以用阿里開源的canal通過監聽數據庫的binlog日志及時的去修改緩存,但是引入了新的中間件,增加了系統的復雜度。
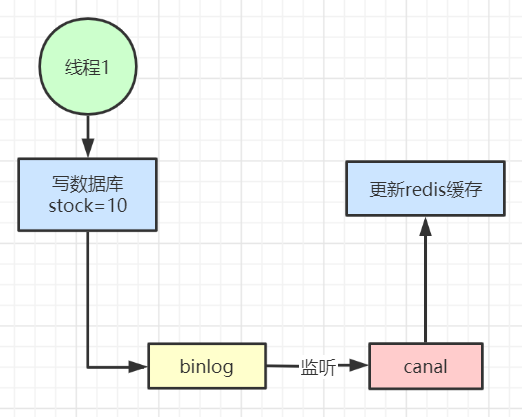
二、針對不同熱度的數據采用不同的處理方式
1)熱點數據
處理方案:
1、緩存永不過期
2、緩存讀延期功能
當命中緩存的時候,設置key的過期時間為默認時間,相當于時間設滿,設置過期時間所需要的時間是非常非常少的,對性能的影響也是微乎其微。對于熱數據的獲取可以實現無線續期的效果
2)冷門數據
處理方案:
針對冷門數據最好不進行緩存,避免內存浪費以及無意義的緩存在過期
基礎緩存代碼分析
源碼與圖示
很基礎的Redis工具類
@Component
public class RedisUtil {@Autowiredprivate RedisTemplate redisTemplate;public void set(String key, Object value) {redisTemplate.opsForValue().set(key, value);}public void set(String key, Object value, long timeout, TimeUnit unit) {redisTemplate.opsForValue().set(key, value, timeout, unit);}public boolean setIfAbsent(String key, Object value, long timeout, TimeUnit unit) {return redisTemplate.opsForValue().setIfAbsent(key, value, timeout, unit);}public <T> T get(String key, Class<?> T) {return (T) redisTemplate.opsForValue().get(key);}public String get(String key) {return (String) redisTemplate.opsForValue().get(key);}public Long decr(String key) {return redisTemplate.opsForValue().decrement(key);}public Long decr(String key, long delta) {return redisTemplate.opsForValue().decrement(key, delta);}public Long incr(String key) {return redisTemplate.opsForValue().increment(key);}public Long incr(String key, long delta) {return redisTemplate.opsForValue().increment(key, delta);}public void expire(String key, long time, TimeUnit unit) {redisTemplate.expire(key, time, unit);}}代碼:
@Service
public class ProductService {@Autowiredprivate ProductDao productDao;@Autowiredprivate RedisUtil redisUtil;@Autowiredprivate Redisson redisson;public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;public static final String EMPTY_CACHE = "{}";public static final String LOCK_PRODUCT_HOT_CACHE_PREFIX = "lock:product:hot_cache:";public static final String LOCK_PRODUCT_UPDATE_PREFIX = "lock:product:update:";//新增數據@Transactionalpublic Product create(Product product) {Product productResult = productDao.create(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);return productResult;}//修改數據@Transactionalpublic Product update(Product product) {Product productResult = null;RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId());RLock writeLock = readWriteLock.writeLock();writeLock.lock();try {productResult = productDao.update(product);redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),genProductCacheTimeout(), TimeUnit.SECONDS);} finally {writeLock.unlock();}return productResult;}//讀數據方法public Product get(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;//讀取緩存中的數據,具體方法實現看源碼 getProductFromCacheproduct = getProductFromCache(productCacheKey);if (product != null) {//此處需要和前端進行約定,如果對象的ID為空,則需要提示商品不存在return product;}//DCL 如果存在很高的并發量,導致競爭鎖耗時過程可以采用定時阻塞的型式//需要精確預估執行完后面代碼所需要的時候,然后將該值設置為過期時間,時間一過線程就可以繼續執行RLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId);hotCacheLock.lock();try {//再次嘗試從緩存中獲取數據,避免其他線程已經讀取過db而這邊線程又重復讀取product = getProductFromCache(productCacheKey);if (product != null) {return product;}//從數據庫中讀取數據product = productDao.get(productId);//讀取到的數據不為空,則將數據存入redis中。if (product != null) {redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);} else {//當數據為空,則存入一個特俗字符,代表空數據,避免緩存穿透//針對特俗key使用較短的過期時間,可以避免短時間黑客反復攻擊,看能避免長時間造成的內存浪費redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);}} finally {hotCacheLock.unlock();}return product;}//從緩存中讀取數據private Product getProductFromCache(String productCacheKey) {Product product = null;String productStr = redisUtil.get(productCacheKey);if (!StringUtils.isEmpty(productStr)) {if (EMPTY_CACHE.equals(productStr)) {//未查詢到數據,需要設置一個空對象返回,并設置較短的過期時間redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);return new Product();}//如果真是查詢到數據,設置讀延期product = JSON.parseObject(productStr, Product.class);redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //讀延期}return product;}//設置較長的過期時間private Integer genProductCacheTimeout() {return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60;}//設置較短的過期時間private Integer genEmptyCacheTimeout() {return 60 + new Random().nextInt(30);}}良好的Redis使用習慣
一、鍵值設計
1)key名設計
- (1)【建議】: 可讀性和可管理性
以業務名(或數據庫名)為前綴(防止key沖突),用冒號分隔,比如業務名:表名:id
trade:order:1
- (2)【建議】:簡潔性
保證語義的前提下,控制key的長度,當key較多時,內存占用也不容忽視,例如:
user:{uid}:friends:messages:{mid} 簡化為 u:{uid}:fr:m:{mid}
- (3)【強制】:不要包含特殊字符
反例:包含空格、換行、單雙引號以及其他轉義字符
2)?value設計
(1)【強制】:拒絕bigkey(防止網卡流量、慢查詢)
在Redis中,一個字符串最大512MB,一個二級數據結構(例如hash、list、set、zset)可以存儲大約40億個(2^32-1)個元素,但實際中如果下面兩種情況,我就會認為它是bigkey。
- 字符串類型:它的big體現在單個value值很大,一般認為超過10KB就是bigkey。
- 非字符串類型:哈希、列表、集合、有序集合,它們的big體現在元素個數太多。
一般來說,string類型控制在10KB以內,hash、list、set、zset元素個數不要超過5000。
反例:一個包含200萬個元素的list。
非字符串的bigkey,不要使用del刪除,使用hscan、sscan、zscan方式漸進式刪除,同時要注意防止bigkey過期時間自動刪除問題(例如一個200萬的zset設置1小時過期,會觸發del操作,造成阻塞)
bigkey的危害:
1.導致redis阻塞
2.網絡擁塞
bigkey也就意味著每次獲取要產生的網絡流量較大,假[[設一個bigkey為1MB,客戶端每秒訪問量為1000,那么每秒產生1000MB的流量,對于普通的千兆網卡(按照字節算是128MB/s)的服務器來說簡直是滅頂之災,而且一般服務器會采用單機多實例的方式來部署,也就是說一個bigkey可能會對其他實例也造成影響,其后果不堪設想。
3.過期刪除
有個bigkey,它安分守己(只執行簡單的命令,例如hget、lpop、zscore等),但它設置了過期時間,當它過期后,會被刪除,如果沒有使用Redis 4.0的過期異步刪除(lazyfree-lazy-expire yes),就會存在阻塞Redis的可能性。
bigkey的產生:
一般來說,bigkey的產生都是由于程序設計不當,或者對于數據規模預料不清楚造成的,來看幾個例子:
(1) 社交類:粉絲列表,如果某些明星或者大v不精心設計下,必是bigkey。
(2) 統計類:例如按天存儲某項功能或者網站的用戶集合,除非沒幾個人用,否則必是bigkey。
(3) 緩存類:將數據從數據庫load出來序列化放到Redis里,這個方式非常常用,但有兩個地方需要注意,第一,是不是有必要把所有字段都緩存;第二,有沒有相關關聯的數據,有的同學為了圖方便把相關數據都存一個key下,產生bigkey。
優化bigkey
1. 拆
- big list: list1、list2、...listN
- big hash:可以講數據分段存儲,比如一個大的key,假設存了1百萬的用戶數據,可以拆分成200個key,每個key下面存放5000個用戶數據
- ?如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出來(例如有時候僅僅需要hmget,而不是hgetall),刪除也是一樣,盡量使用優雅的方式來處理。
(2)【推薦】:選擇適合的數據類型。
例如:實體類型(要合理控制和使用數據結構,但也要注意節省內存和性能之間的平衡)
反例:
set user:1:name tom set user:1:age 19 set user:1:favor football
正例:
hmset user:1 name tom age 19 favor football
(3)【推薦】:控制key的生命周期,redis不是垃圾桶。
建議使用expire設置過期時間(條件允許可以打散過期時間,防止集中過期)。
二、命令使用
1.?O(N)命令關注N的數量
例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明確N的值。有遍歷的需求可以使用hscan、sscan、zscan代替。
2.:禁用命令
禁止線上使用keys、flushall、flushdb等,通過redis的rename機制禁掉命令,或者使用scan的方式漸進式處理。
3.合理使用select
redis的多數據庫較弱,使用數字進行區分,很多客戶端支持較差,同時多業務用多數據庫實際還是單線程處理,會有干擾。
4.使用批量操作提高效率
原生命令:例如mget、mset。 非原生命令:可以使用pipeline提高效率。
但要注意控制一次批量操作的元素個數(例如500以內,實際也和元素字節數有關)。
注意兩者不同:
1. 原生命令是原子操作,pipeline是非原子操作。 2. pipeline可以打包不同的命令,原生命令做不到 3. pipeline需要客戶端和服務端同時支持。
5.Redis事務功能較弱,不建議過多使用,可以用lua替代
三、客戶端處理
1.避免多個應用使用一個Redis實例
正例:不相干的業務拆分,公共數據做服務化。
2.使用帶有連接池的數據庫,可以有效控制連接,同時提高效率,標準使用方式:
1 JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
2 jedisPoolConfig.setMaxTotal(5);
3 jedisPoolConfig.setMaxIdle(2);
4 jedisPoolConfig.setTestOnBorrow(true);
5
6 JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.0.60", 6379, 3000, null);
7
8 Jedis jedis = null;
9 try {
10 jedis = jedisPool.getResource();
11 //具體的命令
12 jedis.executeCommand()
13 } catch (Exception e) {
14 logger.error("op key {} error: " + e.getMessage(), key, e);
15 } finally {
16 //注意這里不是關閉連接,在JedisPool模式下,Jedis會被歸還給資源池。
17 if (jedis != null)
18 jedis.close();
19 }連接池參數含義:
序號
參數名
含義
默認值
使用建議
1
maxTotal
資源池中最大連接數
8
設置建議見下面
2
maxIdle
資源池允許最大空閑的連接數
8
設置建議見下面
3
minIdle
資源池確保最少空閑的連接數
0
設置建議見下面
4
blockWhenExhausted
當資源池用盡后,調用者是否要等待。只有當為true時,下面的maxWaitMillis才會生效
true
建議使用默認值
5
maxWaitMillis
當資源池連接用盡后,調用者的最大等待時間(單位為毫秒)
-1:表示永不超時
不建議使用默認值
6
testOnBorrow
向資源池借用連接時是否做連接有效性檢測(ping),無效連接會被移除
false
業務量很大時候建議設置為false(多一次ping的開銷)。
7
testOnReturn
向資源池歸還連接時是否做連接有效性檢測(ping),無效連接會被移除
false
業務量很大時候建議設置為false(多一次ping的開銷)。
8
jmxEnabled
是否開啟jmx監控,可用于監控
true
建議開啟,但應用本身也要開啟
優化建議:
1)maxTotal:最大連接數,早期的版本叫maxActive
實際上這個是一個很難回答的問題,考慮的因素比較多:
- 業務希望Redis并發量
- 客戶端執行命令時間
- Redis資源:例如 nodes(例如應用個數) * maxTotal 是不能超過redis的最大連接數maxclients。
- 資源開銷:例如雖然希望控制空閑連接(連接池此刻可馬上使用的連接),但是不希望因為連接池的頻繁釋放創建連接造成不必靠開銷。
以一個例子說明,假設:
- 一次命令時間(borrow|return resource + Jedis執行命令(含網絡) )的平均耗時約為1ms,一個連接的QPS大約是1000
- 業務期望的QPS是50000
那么理論上需要的資源池大小是50000 / 1000 = 50個。但事實上這是個理論值,還要考慮到要比理論值預留一些資源,通常來講maxTotal可以比理論值大一些。
但這個值不是越大越好,一方面連接太多占用客戶端和服務端資源,另一方面對于Redis這種高QPS的服務器,一個大命令的阻塞即使設置再大資源池仍然會無濟于事。
2)maxIdle和minIdle
maxIdle實際上才是業務需要的最大連接數,maxTotal是為了給出余量,所以maxIdle不要設置過小,否則會有new Jedis(新連接)開銷。
連接池的最佳性能是maxTotal = maxIdle,這樣就避免連接池伸縮帶來的性能干擾。但是如果并發量不大或者maxTotal設置過高,會導致不必要的連接資源浪費。一般推薦maxIdle可以設置為按上面的業務期望QPS計算出來的理論連接數,maxTotal可以再放大一倍。
minIdle(最小空閑連接數),與其說是最小空閑連接數,不如說是"至少需要保持的空閑連接數",在使用連接的過程中,如果連接數超過了minIdle,那么繼續建立連接,如果超過了maxIdle,當超過的連接執行完業務后會慢慢被移出連接池釋放掉。
如果系統啟動完馬上就會有很多的請求過來,那么可以給redis連接池做預熱,比如快速的創建一些redis連接,執行簡單命令,類似ping(),快速的將連接池里的空閑連接提升到minIdle的數量。
連接池預熱示例代碼:
List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle()); 2 3 for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) { 4 Jedis jedis = null; 5 try { 6 jedis = pool.getResource(); 7 minIdleJedisList.add(jedis); 8 jedis.ping(); 9 } catch (Exception e) { 10 logger.error(e.getMessage(), e); 11 } finally { 12 //注意,這里不能馬上close將連接還回連接池,否則最后連接池里只會建立1個連接。。 13 //jedis.close(); 14 } 15 } 16 //統一將預熱的連接還回連接池 17 for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) { 18 Jedis jedis = null; 19 try { 20 jedis = minIdleJedisList.get(i); 21 //將連接歸還回連接池 22 jedis.close(); 23 } catch (Exception e) { 24 logger.error(e.getMessage(), e); 25 } finally { 26 } 27 }總之,要根據實際系統的QPS和調用redis客戶端的規模整體評估每個節點所使用的連接池大小。
3.高并發下建議客戶端添加熔斷功能(例如sentinel、hystrix)
4.設置合理的密碼,如有必要可以使用SSL加密訪問
5.Redis對于過期鍵有三種清除策略:
- 被動刪除:當讀/寫一個已經過期的key時,會觸發惰性刪除策略,直接刪除掉這個過期key
- 主動刪除:由于惰性刪除策略無法保證冷數據被及時刪掉,所以Redis會定期(默認每100ms)主動淘汰一批已過期的key,這里的一批只是部分過期key,所以可能會出現部分key已經過期但還沒有被清理掉的情況,導致內存并沒有被釋放
- 當前已用內存超過maxmemory限定時,觸發主動清理策略
主動清理策略在Redis 4.0 之前一共實現了 6 種內存淘汰策略,在 4.0 之后,又增加了 2 種策略,總共8種:
a) 針對設置了過期時間的key做處理:
- volatile-ttl:在篩選時,會針對設置了過期時間的鍵值對,根據過期時間的先后進行刪除,越早過期的越先被刪除。
- volatile-random:就像它的名稱一樣,在設置了過期時間的鍵值對中,進行隨機刪除。
- volatile-lru:會使用 LRU 算法篩選設置了過期時間的鍵值對刪除。
- volatile-lfu:會使用 LFU 算法篩選設置了過期時間的鍵值對刪除。
b) 針對所有的key做處理:
- allkeys-random:從所有鍵值對中隨機選擇并刪除數據。
- allkeys-lru:使用 LRU 算法在所有數據中進行篩選刪除。
- allkeys-lfu:使用 LFU 算法在所有數據中進行篩選刪除。
c) 不處理:
- noeviction:不會剔除任何數據,拒絕所有寫入操作并返回客戶端錯誤信息"(error) OOM command not allowed when used memory",此時Redis只響應讀操作。
LRU 算法(Least?Recently?Used,最近最少使用)
淘汰很久沒被訪問過的數據,以最近一次訪問時間作為參考。
LFU 算法(Least?Frequently?Used,最不經常使用)
淘汰最近一段時間被訪問次數最少的數據,以次數作為參考。
當存在熱點數據時,LRU的效率很好,但偶發性的、周期性的批量操作會導致LRU命中率急劇下降,緩存污染情況比較嚴重。這時使用LFU可能更好點。
根據自身業務類型,配置好maxmemory-policy(默認是noeviction),推薦使用volatile-lru。如果不設置最大內存,當 Redis 內存超出物理內存限制時,內存的數據會開始和磁盤產生頻繁的交換 (swap),會讓 Redis 的性能急劇下降。
當Redis運行在主從模式時,只有主結點才會執行過期刪除策略,然后把刪除操作”del key”同步到從結點刪除數據。


真題解析#中國電子學會#全國青少年軟件編程等級考試)





2003-2022年)
)
)






)

