簡介
github
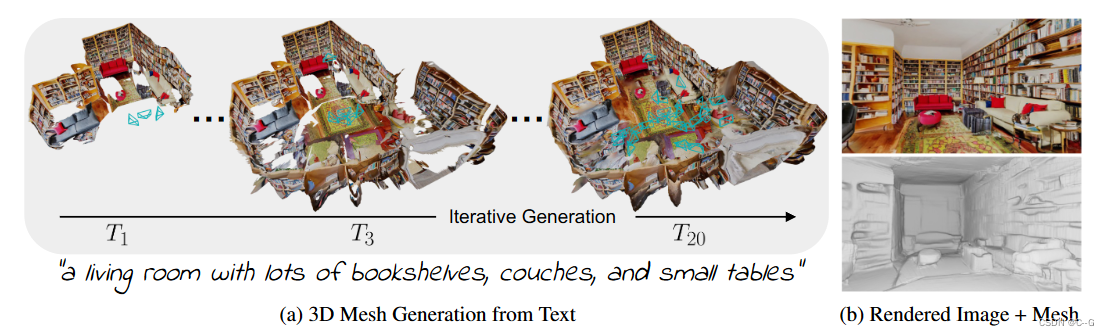
利用預訓練的2D文本到圖像模型來合成來自不同姿勢的一系列圖像。為了將這些輸出提升為一致的3D場景表示,將單目深度估計與文本條件下的繪畫模型結合起來,提出了一個連續的對齊策略,迭代地融合場景幀與現有的幾何形狀,以創建一個無縫網格
實現流程

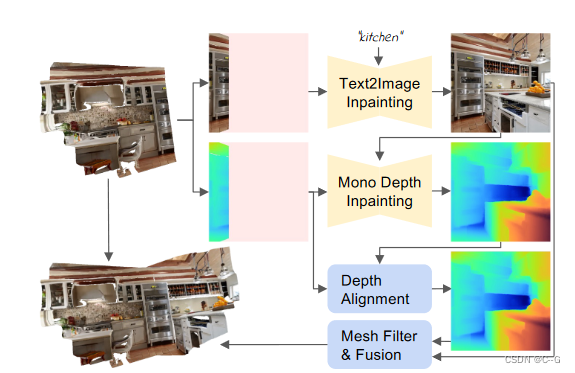
Iterative 3D Scene Generation
隨著時間的推移而生成場景表示網格 M = ( V , C , S ) M=(V,C,S) M=(V,C,S),V——頂點,C——頂點顏色,S——面集合,輸入的文本prompts { P t } t = 1 T \{P_t\}^T_{t=1} {Pt?}t=1T?,相機位姿 { E t } t = 1 T \{ E_t \}^T_{t=1} {Et?}t=1T?,遵循渲染-精煉-重復模式,對于第 t 代的每一步,首先從一個新的視點渲染當前場景
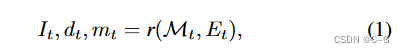
r 是沒有陰影的經典柵格化函數, I t I_t It?\是渲染的圖像, d t d_t dt? 是渲染的深度, M t M_t Mt? 圖像空間掩碼標記沒有觀察到內容的像素
使用文本到圖像模型
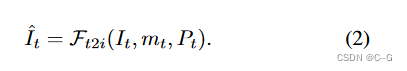
在深度對齊中應用單目深度估計器 F d F_d Fd? b來繪制未觀察到的深度
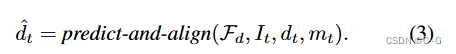
利用融合方案將新內容 { I ^ t , d ^ t , m t } \{ \hat{I}_t,\hat{d}_t,m_t \} {I^t?,d^t?,mt?} 與現有網格結合起來
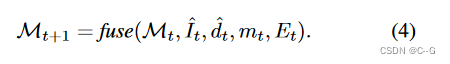
Depth Alignment Step
要正確地結合新舊內容,就必須使新舊內容保持一致。換句話說,場景中類似的區域,如墻壁或家具,應該放置在相似的深度
直接使用預測深度進行反向投影會導致3D幾何結構中的硬切割和不連續,因為后續視點之間的深度尺度不一致
應用兩階段的深度對齊方法,使用預訓練的深度網絡(Irondepth: Iterative refinement of single-view depth using surface normal and its uncertainty),將圖像中已知部分的真實深度d作為輸入,并將預測結果與之對齊 d ^ p = F d ( I , d ) \hat{d}_p=F_d(I,d) d^p?=Fd?(I,d)
(Infinite nature: Perpetual view generation of natural scenes from a single image) 優化尺度和位移參數,在最小二乘意義上對齊預測和呈現的差異來改進結果
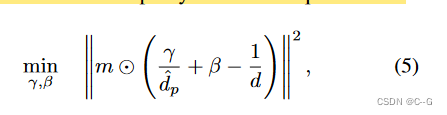
通過 m 屏蔽掉未觀察到的像素,提取對齊深度 d ^ = ( y d ^ p + β ) ? 1 \hat{d}=(\frac{y}{\hat{d}_p}+\beta)^{-1} d^=(d^p?y?+β)?1,在蒙版邊緣應用5 × 5高斯核來平滑 d ^ \hat{d} d^
Mesh Fusion Step
在每一次迭代中插入新的內容 { I ^ t , d ^ t , m t } \{ \hat{I}_t,\hat{d}_t,m_t \} {I^t?,d^t?,mt?} 到場景中,將圖像空間像素反向投影到世界空間點云中
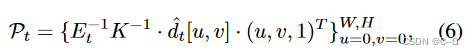
K ∈ R 3 x 3 K \in R^{3 x 3} K∈R3x3 是相機位姿參數,W,H是圖像寬高。使用簡單的三角測量,將圖像中的每四個相鄰像素{(u, v), (u+1, v), (u, v+1), (u+1, v+1)}形成兩個三角形。
估計的深度是有噪聲的,這種簡單的三角測量會產生拉伸的3D幾何形狀。
使用兩個過濾器來去除拉伸的面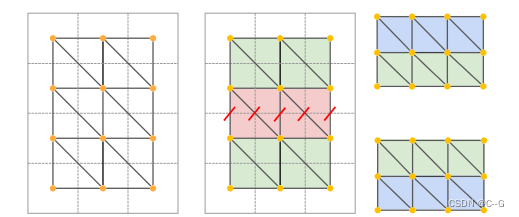
首先,根據邊長對面進行過濾。如果任意面邊緣的歐幾里得距離大于閾值 δ 邊緣,則刪除該面。其次,根據表面法線與觀看方向之間的夾角對面進行過濾
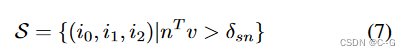
S 是面集合, i 0 , i 1 , i 2 i_0,i_1,i_2 i0?,i1?,i2? 為三角形的頂點指數, δ s n \delta_{sn} δsn?為閾值, m ∈ R 3 m \in R^3 m∈R3 是歸一化法線, v ∈ R 3 v \in R^3 v∈R3 為世界空間中從相機中心到三角形起始平均像素位置的歸一化視角方向,這是避免了從圖像中相對較少的像素為網格的大區域創建紋理
最后將新生成的網格補丁和現有的幾何形狀融合在一起,所有從像素中反向投影到繪制蒙版 m t m_t mt? 中的面都與相鄰的面縫合在一起,這些面已經是網格的一部分,在 m t m_t mt? 的所有邊緣上繼續三角剖分方案,但使用 m t m_t mt? 的現有頂點位置來創建相應的面
Two-Stage Viewpoint Selection
一種兩階段的視點選擇策略,該策略從最優位置采樣每個下一個攝像機姿態,并隨后細化空區域
Generation Stage
如果每個軌跡都從一個具有大多數未觀察區域的視點開始,那么生成效果最好。這會生成下一個塊的輪廓,同時仍然連接到場景的其余部分
將攝像機位置 T 0 ∈ R 3 T_0∈R^3 T0?∈R3 沿注視方向 L ∈ R 3 L∈R^3 L∈R3 進行均勻的平移: T i + 1 = T i ? 0.3 L T_{i+1}=T_i?0.3L Ti+1?=Ti??0.3L,如果平均渲染深度大于0.1,就停止,或者在10步后丟棄相機,這避免了視圖過于接近現有的幾何形狀
創建封閉的房間布局,通過選擇以圓周運動生成下一個塊的軌跡,大致以原點為中心。發現,通過相應地設計文本提示,可以阻止文本到圖像生成器在不需要的區域生成家具。例如,對于看著地板或天花板的姿勢,我們分別選擇只包含單詞“地板”或“天花板”的文本提示
Completion Stage
由于場景是實時生成的,所以網格中包含了沒有被任何相機觀察到的孔,通過采樣額外的姿勢后驗完成場景
將場景體素化為密集的均勻單元,在每個單元中隨機取樣,丟棄那些與現有幾何太接近的,為每個單元格選擇一個姿態,以查看大多數未觀察到的像素,根據所有選擇的相機姿勢繪制場景
清理繪制蒙版很重要,因為文本到圖像生成器可以為大的連接區域生成更好的結果
首先使用經典的繪制算法繪制小的孔,并擴大剩余的孔,移除所有落在擴展區域并且接近渲染深度的面,對場景網格進行泊松曲面重建。這將在完井后關閉任何剩余的井眼,并平滑不連續性。結果是生成的場景的水密網格,可以用經典的柵格化渲染
Result


Limitations
方法允許從任意文本提示生成3D房間幾何形狀,這些文本提示非常詳細并且包含一致的幾何形狀。然而,方法在某些條件下仍然可能失敗。首先,閾值方案可能無法檢測到所有拉伸的區域,這可能導致剩余的扭曲。此外,一些孔在第二階段后可能仍未完全完井,這導致在應用泊松重建后出現過平滑區域。場景表示不分解光線中的材料,光線會在陰影或明亮的燈中烘烤,這是由擴散模型產生的。
 setInterval())

)








)

:鏈表)





