1.簡介
學習深度學習必看CLIP!論文鏈接arxiv.org/pdf/2103.00020v1.pdf。
簡單來說就是傳統的分類任務被用來預測指定的類別,有監督訓練限制了模型的通用性和可用性,并且需要帶有標簽的數據來訓練,該篇論文就想直接從原始文本中學習圖像特征,具體就是從網絡上采集大量的帶有文字描述的圖片,同時向網絡輸入原始文字和圖像,網絡來學習他們之間的關系。預測時通過輸入一句話就能判斷圖像是否與其匹配了,具有很強的泛化性能。這就是zero shot,不用數據集中任何一張圖片,就能夠達到ResNet-50的精度。
2.方法
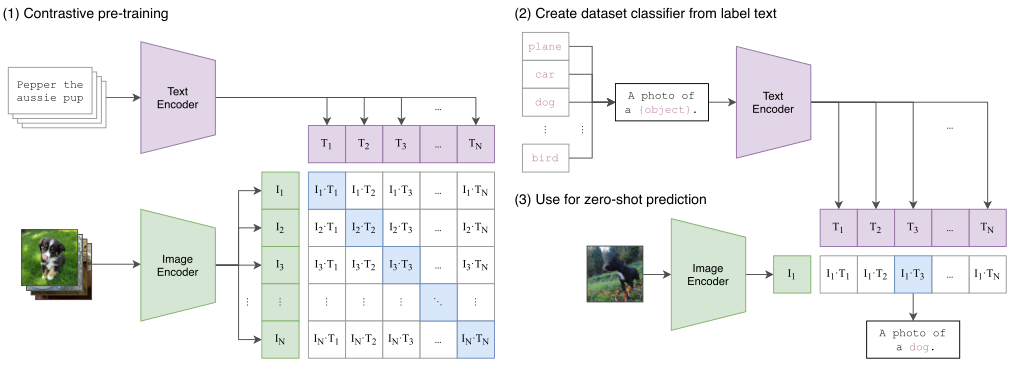
方法的核心思想是從自然語言的監督中學習感知。這種方法其實一點都不新,之前也有人做過,只不過之前的方法描述的很混淆,并且數據規模不大。那么為什么非要用自然語言監督的方法來訓練一個視覺模型呢?第一個就是說你不需要再去標注數據了,直接從網上下載圖像和文字的配對就行了,減少了很多的工作量。第二個就是將圖片和文字綁定到了一起,模型學習的就是一個多模態的特征了。這樣就很容易去做zero-shot的遷移任務了。
該方法不需要之前的那種黃金標簽,而是從互聯網上的大量文本中學習。與大多數無監督或自監督學習方法相比,從自然語言中學習也有重要的優勢,因為它不僅“只是”學習表征,而且還將該表征與語言聯系起來,從而實現靈活的零遷移。
2.1構建數據集
構建了一個新的數據集,其中包含4億對(圖像,文本)對,這些數據來自互聯網上各種公開可用的資源。
2.2選擇有效的預訓練方法
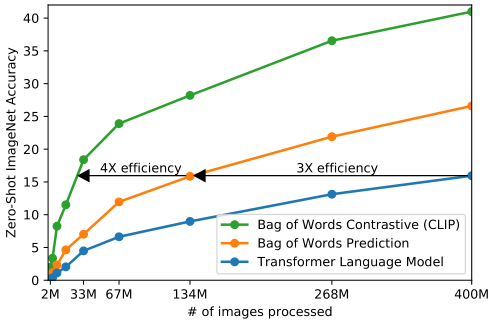
一開始作者選用了VirTex的方法,圖像用CNN,文本用transformer來進行,CNN用來預測圖像對應的文本,但是由于一個圖像對應的描述實在是太多了,所以這樣預訓練的效果很差,于是作者決定用對比學習的方法來進行預訓練。
從上圖我們可以發現,藍色的線是類似gpt的方法,基于transformer去做預測性的任務,逐字逐句的去預測文本。橘黃色的線是去預測已經全局化抽象成特征的文本(bag of words prediction)。可以發現訓練效率提高了三倍。綠色的線是用對比學習的方法來判斷圖像和文本是否配對,這樣效率是最高的。

上圖是CLIP訓練的一個偽代碼。首先是兩個編碼器,用來對圖像和文本進行編碼。圖像的編碼器可以用ResNet或者ViT,文本的編碼器可以用CBOW和Text Transformer。然后對提取的兩個特征歸一化并求一個余弦相似度,然后做一個交叉熵的損失函數來預訓練網絡。


GA-BP遺傳算法優化BP神經網絡的多維分類預測)






,Javaee項目,springboot項目。)





的柵格路徑規劃,輸出做短路徑圖和適應度曲線)



)