文章目錄
- 摘要
- 1、簡介
- 2、方法
- 2.1、Multi-LeVEl ReVERsible Unit
- 2.2、可逆列架構
- 2.2.1、MACRo設計
- 2.2.2、MicRo 設計
- 2.3、中間監督
- 3、實驗部分
- 3.1、圖像分類
- 3.2、目標檢測
- 3.3、語義分割
- 3.4、與SOTA基礎模型的系統級比較
- 3.5、更多分析實驗
- 3.5.1、可逆列架構的性能提升
- 3.5.2、可逆網絡與非可逆網絡
- 3.5.3、使用中間監督的性能提升
- 3.5.4、GPU內存消耗與模型大小
- 3.5.5、卷積中核大小的消融實驗
- 4、相關工作
- 4.1、分離表示學習和部分-整體層次
- 4.2、可逆網絡
- 5、結論
- A、MICRO 設計細節
- B、概括Transformer
- B.1、視覺Transformer模型
- B.2、語言模型
- B.3 列數量的魯棒性
- C. 半標注私人收集的大型模型數據集
- C.1 數據收集和偽標簽系統
- C.2 圖像去重
- D. 更多訓練細節
- D.1 中間監督設置
- D.2 用于訓練和預訓練的超參數
- D.3 用于微調的超參數
- D.3.1、下游任務中的卷積核填充技巧
- E、功能解耦的可視化
摘要
https://arxiv.org/pdf/2212.11696v3.pdf
我們提出了一種新的神經網絡設計范式可逆列網絡(RevCol)。RevCol的主體由多個子網副本組成,這些子網之間采用多級可逆連接。這樣的架構方案賦予RevCol與傳統網絡非常不同的行為:在前向傳播過程中,RevCol中的特征在經過每一列時逐漸解糾纏,保留了列的總信息,而不是像其他網絡那樣壓縮或丟棄。我們的實驗表明,cnn風格的RevCol模型可以在圖像分類、目標檢測和語義分割等多個計算機視覺任務上取得非常有競爭力的性能,特別是在大參數預算和大數據集的情況下。例如,經過ImageNet-22K預訓練,RevColXL獲得了88.2%的ImageNet-1K準確率。給出更多的預訓練數據,我們最大的模型RevCol-H在ImageNet-1K上達到90.0%,在COCO檢測最小集上達到63.8% APbox,在ADE20k分割上達到61.0% mIoU。據我們所知,這是純(靜態)CNN模型中最好的COCO檢測和ADE20k分割結果。此外,作為一種通用的宏觀架構方式,RevCol也可以引入到變壓器或其他神經網絡中,這被證明可以提高計算機視覺和NLP任務的性能。我們在https://github.com/megvii-research/RevCol上發布代碼和模型。
1、簡介
信息瓶頸原則(IB)(Tishby等人,2000年;Tishby和Zaslavsky,2015年)統治著深度學習世界。考慮圖1(a)中的典型監督學習網絡:靠近輸入的層包含更多低級信息,而靠近輸出的特征則富含語義含義。換句話說,與目標無關的信息在逐層傳播過程中逐漸被壓縮。盡管這種學習范式在許多實際應用中取得了巨大的成功,但從特征學習的角度來看,它可能不是最佳選擇-如果學習到的特征被過度壓縮,或者學習到的語義信息與目標任務無關,特別是如果源任務和目標任務之間存在顯著的領域差距,那么下游任務可能會受到較差的性能(Zamir等人,2018年)。研究者們已經付出了巨大的努力來使學習到的特征更加普遍適用,例如通過自監督預訓練(Oord等人,2018年;Devlin等人,2018年;He等人,2022年;Xie等人,2022年)或多任務學習(Ruder,2017年;Caruana,1997年;Sener和Koltun,2018年)。

在這篇論文中,我們主要關注一種替代方法:構建一個網絡來學習解耦表示。與信息瓶頸學習不同,解耦特征學習(Desjardins等人,2012年;Bengio等人,2013年;Hinton,2021年)的目的不是提取最相關的信息,同時丟棄不太相關的信息;相反,它的目的是將任務相關概念或語義詞分別嵌入到幾個解耦的維度中。同時整個特征向量大致保持與輸入相同的信息。這與生物細胞中的機制非常相似(Hinton,2021年;Lillicrap等人,2020年)-每個細胞共享整個基因組的相同副本,但具有不同的表達強度。因此,在計算機視覺任務中,學習解耦特征也是合理的:例如,在ImageNet預訓練期間調整高級語義表示,同時其他特征維度中也應維護低級信息(例如邊緣的位置),以備下游任務(如目標檢測)的需求。
圖1(b)概述了我們的主要思想:可逆列網絡(RevCol),該思想深受GLOM(Hinton,2021)的啟發。我們的網絡由N個子網絡(稱為列)組成,每個列的結構相同(然而其權重不一定相同),每個列接收輸入的副本并生成預測。因此,多級嵌入,即從低級到高度語義表示,都存儲在每個列中。此外,引入可逆變換將多級特征從第i列傳播到第(i+1)列而不損失信息。在傳播過程中,由于復雜性和非線性增加,所有特征級別的質量有望逐漸提高。因此,最后一列(圖1(b)中的Col N)預測輸入的最終解耦表示。
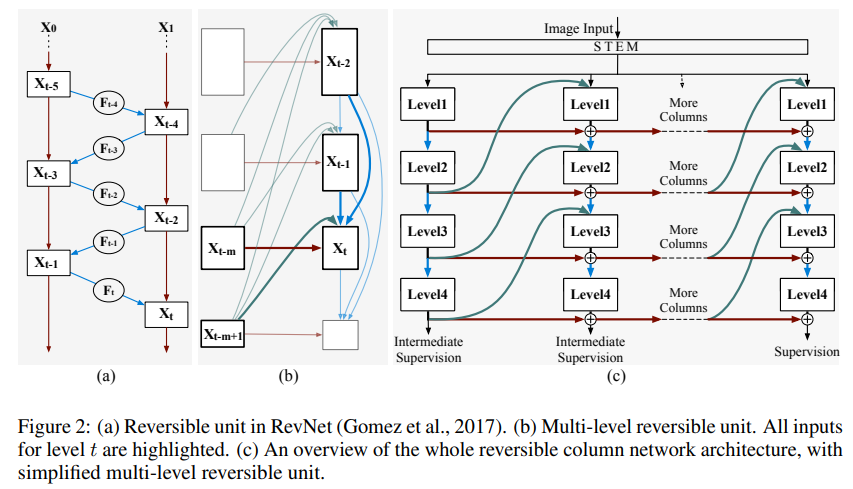
在RevCol中,我們的一個關鍵貢獻是設計相鄰列之間的可逆變換。這個概念借鑒了可逆網絡家族(Chang等人,2018年;Gomez等人,2017年;Jacobsen等人,2018年;Mangalam等人,2022年);然而,傳統的可逆結構,如RevNets(Gomez等人,2017年)(圖2(a))通常有兩個缺點:第一,可逆塊內的特征圖被限制為具有相同的形狀;第二,RevNets中的最后兩個特征圖由于可逆性質而必須同時包含低級和高級信息,這可能很難優化,這與IB原則相沖突。在本文中,我們通過引入一個新型可逆多級融合模塊克服了這些缺點。詳情請參見第2部分。
我們構建了一系列基于CNN的RevCol模型,并在不同的復雜度預算下對其進行評估,用于主流計算機視覺任務,如ImageNet分類、COCO目標檢測和實例分割,以及ADE20K語義分割。我們的模型在性能上可與先進的CNN或視覺Transformer(如ConvNeXt(Liu等人,2022b)和Swin(Liu等人,2021))相媲美,甚至更勝一籌。例如,經過ImageNet-22K預訓練后,我們的RevCol-XL模型在ImageNet-1K上實現了88.2%的準確率,而無需使用Transformer或大型卷積核(Ding等人,2022b;Liu等人,2022b;Han等人,2021)。更重要的是,我們發現RevCol可以很好地擴展到大型模型和大型數據集。給定一個更大的私有預訓練數據集,我們的最大模型RevCol-H在ImageNet-1K分類上獲得了90.0%的準確率,在COCO檢測minival集上獲得了63.8%的APbox,在ADE20K分割上獲得了61.0%的mIoU。據我們所知,它是這些任務上最好的可逆模型,也是COCO和ADE20K上最好的純CNN模型,這兩個任務只涉及靜態核而不涉及動態卷積(Dai等人,2017;Ma等人,2020)。在附錄中,我們進一步證明RevCol可以與Transformers(Dosovitskiy等人,2020;Devlin等人,2018)一起使用,并在計算機視覺和NLP任務上獲得改進的結果。最后,與RevNets(Gomez等人,2017)類似,RevCol也具有可逆性節省內存的優勢,這對于大型模型的訓練尤其重要。
與先前作品的關系。盡管我們關于特征解耦的初步想法來自GLOM(Hinton,2021),但在RevCol中有很多簡化和修改。例如,GLOM建議使用對比輔助損失來避免特征崩潰。對比訓練方法需要額外的正負樣本對,這很復雜且不穩定。在RevCol中,列之間的可逆變換提供了信息無損傳播的自然方式。至于其他多尺度網格狀架構,如HRNets(Wang等人,2020)、DEQ模型(Bai等人,2020)和FPNs(Lin等人,2017;Tan等人,2020),這些模型的設計目的是融合多尺度特征而不是學習解耦表示;因此,一般來說,它們仍然遵循圖1(a)的模式——既沒有多個入口/出口也沒有可逆結構。基于這些網格狀網絡拓撲,基于NAS的工作(Ding等人,2021;Wu等人,2021;Liu等人,2019;Ghiasi等人,2019)針對特定數據集搜索網絡架構的優化拓撲。然而,RevCol架構并不僅限于特定任務或數據集。由于其可逆性質,我們的方法保持了無損信息傳播,并且不僅有利于預訓練,也有利于其他下游任務。最近,RevBiFPN(Chiley等人,2022)提出了FPN的可逆變體,該變體進一步用在了HRNet類似的架構中。盡管我們的RevCol與RevBiFPN有相似的多尺度可逆變換思想,但我們的工作是獨立完成的,它源于特征解耦的不同動機,并且具有更簡單的架構(例如無需可逆上采樣塔)和更高的性能。我們在第3部分比較了這些模型中的一些。
2、方法
在本節中,我們介紹了Reversible Column Networks (RevCol)的設計細節。圖1(b)展示了頂層架構。請注意,對于RevCol中的每個列,為了簡單起見,我們直接重用現有的結構,例如ConvNeXt(Liu等人,2022b)。因此,在以下子部分中,我們主要關注如何建立列之間的可逆連接。此外,我們在每個列的頂部引入了一個即插即用的中間監督,這進一步提高了訓練收斂速度和特征質量。
2.1、Multi-LeVEl ReVERsible Unit
在我們的網絡中,可逆變換在不損失信息的情況下在特征解耦中起著關鍵作用。其見解來自Reversible Neural Networks (Dinh等人,2014;Chang等人,2018;Gomez等人,2017;Jacobsen等人,2018;Mangalam等人,2022)。其中,我們首先回顧一下最具代表性的作品RevNet(Gomez等人,2017)。如圖2(a)所示,RevNet首先將輸入x分成兩組,$ x_{0} 和 和 和x_{1}$ 。然后在后面的塊中,例如塊t,它采用兩個前塊的輸出 x t ? 1 x_{t-1} xt?1? 和 x t ? 2 x_{t-2} xt?2? 作為輸入并生成輸出x t 。塊t的映射是可逆的,即x t-2 可以由兩個后塊 x t ? 1 x_{t-1} xt?1? 和 x t x_{t} xt? 重建。正式地,前向和反向計算遵循方程:
Forward?:? x t = F t ( x t ? 1 ) + γ x t ? 2 Inverse? : x t ? 2 = γ ? 1 [ x t ? F t ( x t ? 1 ) ] , (1) \begin{array}{l} \text { Forward : } x_{t}=\boldsymbol{F}_{t}\left(x_{t-1}\right)+\gamma x_{t-2} \\ \text { Inverse }: x_{t-2}=\gamma^{-1}\left[x_{t}-\boldsymbol{F}_{t}\left(x_{t-1}\right)\right], \end{array} \tag{1} ?Forward?:?xt?=Ft?(xt?1?)+γxt?2??Inverse?:xt?2?=γ?1[xt??Ft?(xt?1?)],?(1)
其中 F t \boldsymbol{F}_{t} Ft?表示類似于標準ResNets中殘差函數的任意非線性運算;\gamma是一個簡單的可逆操作(例如,channel-wise縮放),其逆表示為 γ ? 1 \gamma^{-1} γ?1。如引言所述,上述公式對特征維度的約束太強,即 x t 、 x t + 2 、 x t + 4 、 x t + 4 x_{t}、x_{t+2}、x_{t+4}、x_{t+4} xt?、xt+2?、xt+4?、xt+4?必須是相等大小的,這在架構設計上不靈活。這就是為什么RevNets (Gomez et al., 2017)在可逆單元之間引入了一些不可逆的下采樣塊,因此整個網絡不是完全可逆的。更重要的是,我們發現沒有明確的方法可以直接使用Eq. 1來橋接圖1 (b)中的列。
為了解決這個問題,我們將方程1推廣為以下形式:
Forward?:? x t = F t ( x t ? 1 , x t ? 2 , … , x t ? m + 1 ) + γ x t ? m Inverse? : x t ? m = γ ? 1 [ x t ? F t ( x t ? 1 , x t ? 2 , … , x t ? m + 1 ) ] , \begin{array}{l} \text { Forward : } x_{t}=\boldsymbol{F}_{t}\left(x_{t-1}, x_{t-2}, \ldots, x_{t-m+1}\right)+\gamma x_{t-m} \\ \text { Inverse }: x_{t-m}=\gamma^{-1}\left[x_{t}-\boldsymbol{F}_{t}\left(x_{t-1}, x_{t-2}, \ldots, x_{t-m+1}\right)\right], \end{array} ?Forward?:?xt?=Ft?(xt?1?,xt?2?,…,xt?m+1?)+γxt?m??Inverse?:xt?m?=γ?1[xt??Ft?(xt?1?,xt?2?,…,xt?m+1?)],?
其中m是指遞歸的階數(m≥2)。顯然,這種擴展仍然是可逆的。然后我們將每m個特征圖分成一組:(x1,x2,…,xm),(xm+1,xm+2,…,x2m),…給定任何一組內的特征,我們可以很容易地根據方程2遞歸計算其他組的特征。與原始形式相比,方程2具有以下兩個優點:
- 如果m相對較大,則對特征圖大小的約束大大放寬。請注意,方程1并不要求每個組內的特征圖大小相等;這樣的約束只存在于組之間。因此,我們可以使用不同形狀的張量來表示不同語義級別或不同分辨率的特征。
- 方程2可以很容易地與現有網絡架構合作,即使后者不是可逆的。例如,我們可以將標準ResNet中的m個特征圖分配給表示組 ( x t , x t + 1 , … , x t + m ? 1 ) \left(x_{t}, x_{t+1}, \ldots, x_{t+m-1}\right) (xt?,xt+1?,…,xt+m?1?)中的特征圖,這仍然與方程2兼容,因為ResNet可以被視為 ( F t , F t + 1 , … , F t + m ? 1 ) \left(\boldsymbol{F}_{t}, \boldsymbol{F}_{t+1}, \ldots, \boldsymbol{F}_{t+m-1}\right) (Ft?,Ft+1?,…,Ft+m?1?)的一部分。因此,整個網絡仍然是可逆的。
因此,我們可以將方程2重新組織成多列形式,如圖2(b)所示。每一列由一個組內的m個特征圖以及它們所屬的母網絡組成。我們將其命名為多級可逆單元,它是我們RevCol的基本組件,如圖1(b)所示。
2.2、可逆列架構
2.2.1、MACRo設計
如引言中所述(參見圖1(b)),我們的網絡Rev Col由多個具有可逆連接的子網絡組成,以執行特征解糾纏。圖2(c)詳細說明了體系結構的設計。遵循最近模型(Dosovitskiy等人,2020;Liu等人,2022b)的常見做法,首先將輸入圖像通過一個patch embedding模塊拆分成不重疊的補丁。之后,將補丁饋送到每個子網絡(列)。列可以用任何傳統的單列架構實現,例如ViT(Dosovitskiy等人,2020)或ConvNeXt(Liu等人,2022b)。我們從每個列中提取四個級別的特征圖,以傳播列之間的信息;例如,如果列是由廣泛使用的層次網絡實現的(Liu等人,2021;He等人,2016;Liu等人,2022b),則我們可以簡單地從每個階段的輸出中提取多分辨率特征。對于分類任務,我們僅使用最后一列的最后一級(第4級)的特征圖以獲取豐富的語義信息。對于其他下游任務,如目標檢測和語義分割,我們使用最后一列中所有四個級別的特征圖,因為它們同時包含低級和語義信息。
為了實現列之間的可逆連接,我們采用了方程2中提出的多級可逆單元,但以一種簡化的方式:我們不是為每個非線性操作 F t ( ? ) \boldsymbol{F}_{t}(\cdot) Ft?(?)采用(m-1)個輸入,而是僅采用當前列的1個低級特征x_{t-1}和前一列的1個高級特征 x t ? m + 1 x_{t-m+1} xt?m+1?作為輸入。這種簡化并不破壞可逆屬性。我們發現,更多的輸入只能帶來很小的精度提升,但會消耗大量的GPU資源。因此,方程2被簡化為:
Forward?:? x t = F t ( x t ? 1 , x t ? m + 1 ) + γ x t ? m Inverse? : x t ? m = γ ? 1 [ x t ? F t ( x t ? 1 , x t ? m + 1 ) ] . \begin{array}{l} \text { Forward : } x_{t}=\boldsymbol{F}_{t}\left(x_{t-1}, x_{t-m+1}\right)+\gamma x_{t-m} \\ \text { Inverse }: x_{t-m}=\gamma^{-1}\left[x_{t}-\boldsymbol{F}_{t}\left(x_{t-1}, x_{t-m+1}\right)\right] . \end{array} ?Forward?:?xt?=Ft?(xt?1?,xt?m+1?)+γxt?m??Inverse?:xt?m?=γ?1[xt??Ft?(xt?1?,xt?m+1?)].?
與傳統的架構相比,我們的RevCol的宏設計具有以下三個屬性或優勢:
特征解糾纏。在RevCol中,每個列的最低級別保持低級特征,因為它靠近輸入,而最后一列的最高級別具有高度語義性,因為它直接連接到監督。因此,在列之間的(無損)傳播過程中,不同級別的信息逐漸被解糾纏-一些特征圖變得越來越語義化,一些保持低級。詳細的分析在附錄E中給出。該屬性帶來了許多潛在的優勢,例如對同時依賴于高級和低級特征的下游任務更加靈活。我們認為可逆連接在解糾纏機制中起著關鍵作用-一些之前的工作如HRNet(Wang等人,2020)涉及多級特征融合,但沒有可逆連接,這可能會導致信息損失,并在我們的實驗中導致性能不佳(參見第3.5.2節)。
節省內存。傳統網絡的訓練需要大量的內存足跡來存儲前向傳播過程中的激活,以滿足梯度計算的需求。而在我們的RevCol中,由于列之間的連接是顯式可逆的,因此在反向傳播過程中,我們可以從最后一列到第一列重建所需的激活,這意味著我們只需要在訓練過程中維護一個列的激活。在Section 3.5.4中,我們證明RevCol大約只需要\mathcal{O}(1)的額外內存,隨著列數的增加。
大型模型的新縮放因子。在RevCol體系結構中,列數作為除深度(塊數)和寬度(每個塊的通道數)之外的一個新維度添加到普通單列CNN或ViT中。在一定范圍內,增加列數與增加寬度和深度具有類似的收益。
2.2.2、MicRo 設計
我們默認使用ConvNeXt塊(Liu等人,2022b)來實現我們網絡中的每個列;其他架構,如transformer,也是適用的(詳見附錄B)。為了使ConvNeXt與我們的宏架構兼容,我們對它進行了一些修改:
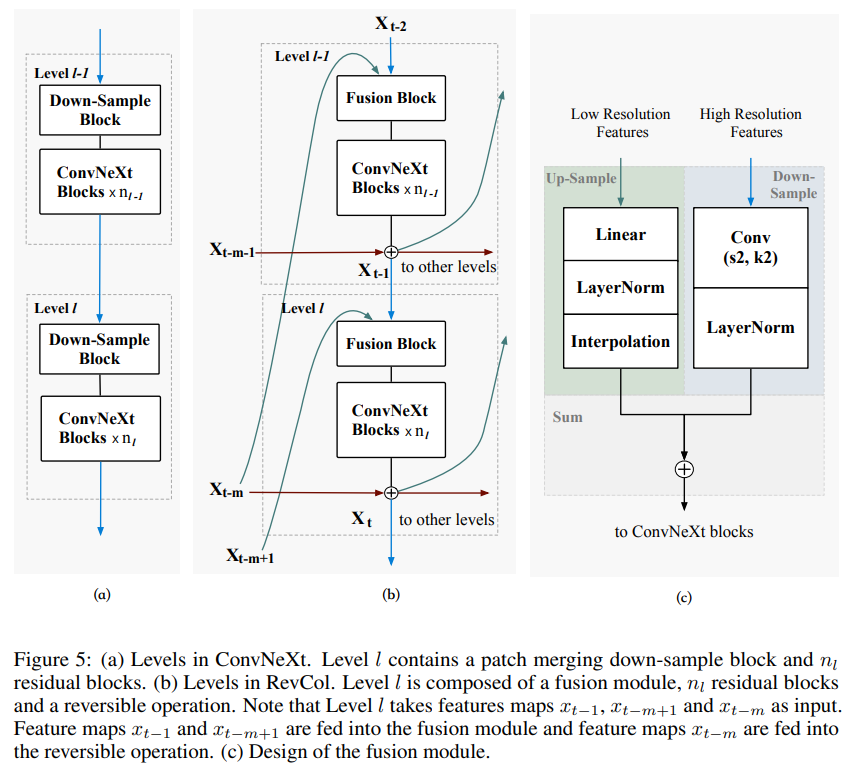
Fusion模塊。如圖5所示,在原始ConvNeXt的每個級別中,輸入首先在patch-merging塊中被下采樣。然后,輸出通過一堆殘差塊。在RevCol中,我們引入了一個融合模塊來融合來自當前列和前一列的特征映射(參見圖2(c)中的綠色和藍色連接)。我們對原始ConvNeXt中的patch-merging塊進行了修改,將LayerNorm放在patch-merging卷積之后,而不是之前。patch-merging卷積的通道數加倍。我們還引入了一個上采樣塊,該塊由線性通道映射層、LayerNorm歸一化和特征圖插值層組成。我們將線性通道映射層中的通道數減半。這兩個塊的輸出相加,然后傳遞給殘差塊。
核大小。在RevCol中,我們將原始ConvNeXt(Liu等人,2022b)中的 7 × 7 7 \times 7 7×7卷積修改為 3 × 3 3 \times 3 3×3,主要是為了加速訓練。增加核大小可以獲得更高的準確性,但不會很多,部分原因是我們的多列設計擴大了有效感受野。有關更多詳細信息,請參閱第3.5.5節。
可逆操作 γ \gamma γ。我們采用可學習的可逆通道縮放作為可逆操作 γ \gamma γ,以保持網絡穩定。每次在式3的前向傳播中,特征的幅度都會增大,這會使訓練過程不穩定。使用可學習的縮放可以抑制特征的幅度。在訓練期間,我們截斷了 γ \gamma γ的絕對值,使其永遠不會小于 1 e ? 3 1 e^{-3} 1e?3,因為當 γ \gamma γ太小時,數值誤差可能在反向計算中變得很大。
2.3、中間監督
盡管多級可逆單元能夠在列迭代過程中保持信息,但下采樣塊仍然可以丟棄列內的信息。前面幾列末尾的特征太接近最終輸出,因為可逆連接只進行縮放和求和。這種信息丟失會導致性能下降。類似的問題在使用深層監督方法(Lee等人,2015;Szegedy等人,2015)時也會發生。
為了緩解信息崩潰的問題,我們提出了一種中間監督方法,該方法在前面幾列中添加了額外的監督。對于前面幾列中的特征,我們希望盡可能保持特征與輸入圖像之間的互信息,這樣網絡在列內部丟棄的信息就會更少。考慮到RevCol逐漸分離語義和低級信息,提取和利用與任務相關的信息可以進一步提高性能。因此,我們需要最大化特征和預測之間互信息的下界。
受Wang等人(2021)的啟發,我們在最后一級特征(第4級)中添加了兩個輔助頭。一個是解碼器(He等人,2022),它重構輸入圖像,另一個是線性分類器。線性分類器可以按常規分類方式用交叉熵損失進行訓練。解碼器的參數通過最小化二元交叉熵重構損失進行優化。與常用的L1和L2損失相比,將重構的對數和輸入圖像的分布解釋為比特概率(伯努利)輸出更平滑的值,這使得它更兼容交叉熵損失。
對于某一列的中間監督,復合損失是上述兩種損失的加權總和。需要注意的是,監督頭可能不會添加到所有列中。對于所有變體的RevCol,我們通過經驗將復合損失的數量設置為4(例如,對于8列的RevCol,監督頭添加在第2、4和6列以及第8列)。
總損失 L \mathbf{L} L是所有復合損失的總和:
L = ∑ i = 1 n ( α i L B C E + β i L C E ) \boldsymbol{L}=\sum_{i=1}^{n}\left(\alpha_{i} \mathcal{L}_{\mathrm{BCE}}+\beta_{i} \mathcal{L}_{\mathrm{CE}}\right) L=i=1∑n?(αi?LBCE?+βi?LCE?)
n 表示復合損失的總數。損失函數 L B C E \mathcal{L}_{\mathrm{BCE}} LBCE?和 L C E \mathcal{L}_{\mathrm{CE}} LCE?分別表示BCE損失和CE損失。\alpha_{i}和\beta_{i}的值隨著復合損失數量的增加而線性改變。當復合損失被添加到前面的列時,我們使用較大的 α i \alpha_{i} αi?值和較小的 β i \beta_{i} βi?值來保持 I ( h , x ) I(\boldsymbol{h}, x) I(h,x)。在后面的列中,\alpha_{i}的值會減小,而 β i \beta_{i} βi?的值會增加,這有助于提高性能。
3、實驗部分
我們構建了不同的RevCol變體,包括RevCol-T/S/B/L,使其與Swin transformers和ConvNeXts的復雜度相當。我們還構建了一個更大的RevCol-XL和RevCol-H來測試擴展能力。這些變體采用不同的通道維度C、每個列的塊數B和列數COL。這些模型變體的配置超參數如下:
- RevCol-T: C=(64,128,256,512), B=(2,2,4,2), COL=4
- RevCol-S: C=(64,128,256,512), B=(2,2,4,2), COL=8
- RevCol-B: C=(72,144,288,576), B=(1,1,3,2), COL=16
- RevCol-L: C=(128,256,512,1024), B=(1,2,6,2), COL=8
- RevCol-XL: C=(224,448,896,1792), B=(1,2,6,2), COL=8
- RevCol-H: C=(360,720,1440,2880), B=(1,2,6,2), COL=8
我們在ImageNet數據集上進行圖像分類(Deng et al., 2009;Ridnik et al., 2021)。我們還在常用的MS-COCO (Lin et al., 2014)和ADE20k (Zhou et al., 2017b)數據集上對下游目標檢測任務和語義分割任務進行了模型測試。訓練和微調設置請參見附錄d。此外,我們展示了帶有transformer的RevCol在視覺和語言任務上的性能(見附錄B)。
3.1、圖像分類
在ImageNet(1.28M圖像)數據集上,我們對RevCol進行了300個訓練周期的訓練,并采用了中間監督。超參數、數據增強和正則化策略遵循Liu等人(2022b)的方法。我們還使用更大的ImageNet-22K數據集(Ridnik等人,2021)對模型進行了預訓練,該數據集包含14.2百萬個圖像。
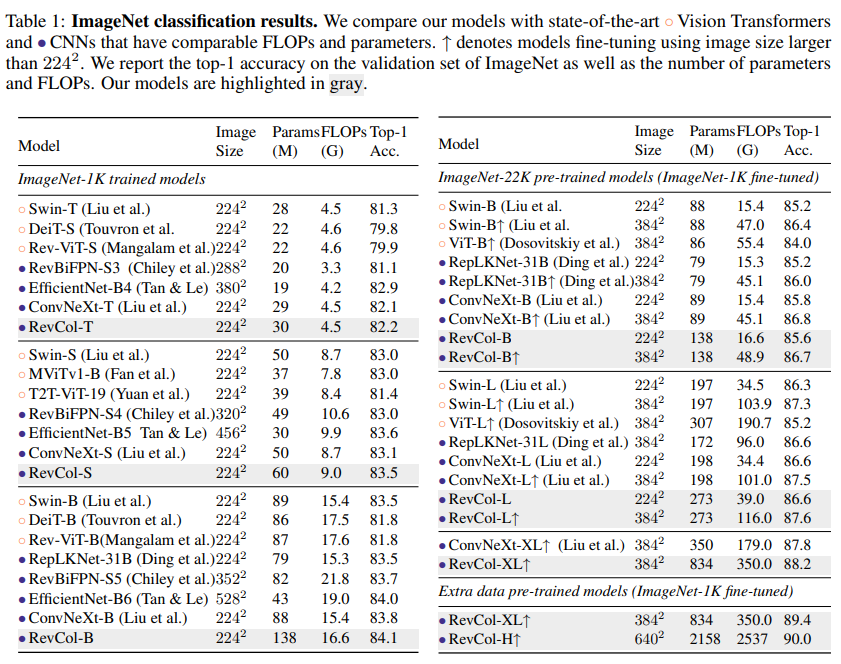
在表1中,我們將RevCol變體與常見的最近Transformer和CNN在ImageNet-1k驗證集上進行比較。我們的模型在具有相似復雜性的情況下優于大量的普通單列CNN和Transformer。例如,RevCol-S達到83.5%的Top-1準確率,比ConvNeXt-S高出0.4個點。當使用更大的ImageNet-22K數據集進行預訓練時,RevCol-XL達到88.2%的Top-1準確率。由于RevCol在分類預訓練中保留了一些與任務無關的低級別信息,放寬參數和FLOPs的約束并擴大數據集大小可以進一步提高我們模型的性能。為了進一步測試大型數據集的擴展效果,我們構建了一個168百萬個圖像的半標記數據集(參見附錄C)。通過額外的數據預訓練和ImageNet-1k微調,我們的RevCol-H達到90.0%的Top-1準確率。我們的結果進一步證明,使用RevCol,CNN模型也可以分享大型模型和大量數據預訓練的紅利。
3.2、目標檢測
我們在目標檢測任務上對所提出的RevCol進行了評估。實驗使用級聯掩模R-CNN (Cai & Vasconcelos, 2019)框架在MS-COCO數據集上進行。我們還使用HTC++ (Chen et al., 2019)和DINO (Zhang et al., 2022a)框架微調了我們最大的模型RevCol-H。
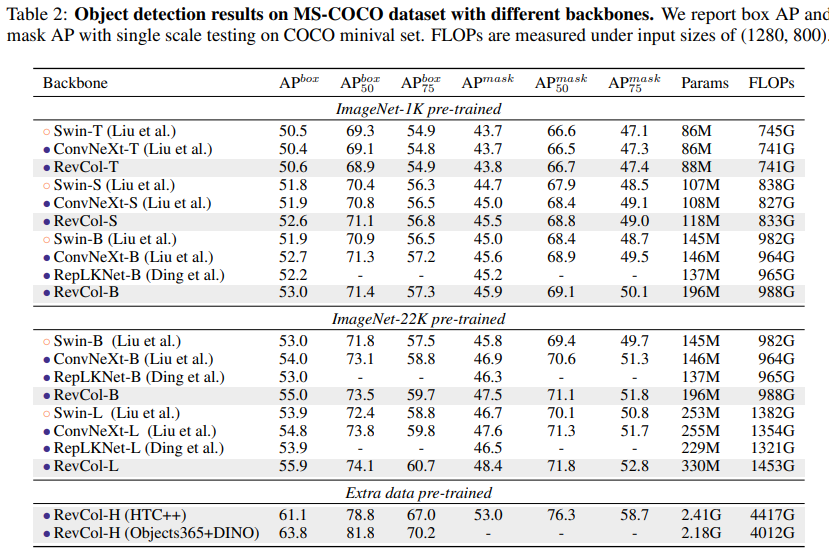
在表2中,我們將APbox和APmask與COCO驗證集上的Swin/ConvNeXt進行比較,發現RevCol模型在類似計算復雜性的情況下優于其他同類模型。預訓練中保留的信息有助于RevCol模型在下游任務中取得更好的結果。當模型大小增加時,這種優勢變得更加明顯。在Objects365(Shao等人,2019)數據集和DINO(Zhang等人,2022a)框架下進行微調后,我們最大的模型RevCol-H在COCO檢測小型驗證集上實現了63.8%的APbox。
3.3、語義分割
我們還使用UperNet(Xiao等人,2018)框架評估了RevCol主干在ADE20K語義分割任務上的表現。在下游微調過程中,我們沒有使用中間監督。為了進一步探索我們模型的能力并達到領先的表現,我們采用了最近的分割框架Mask2Former(Cheng等人,2022),并采用了相同的訓練設置。
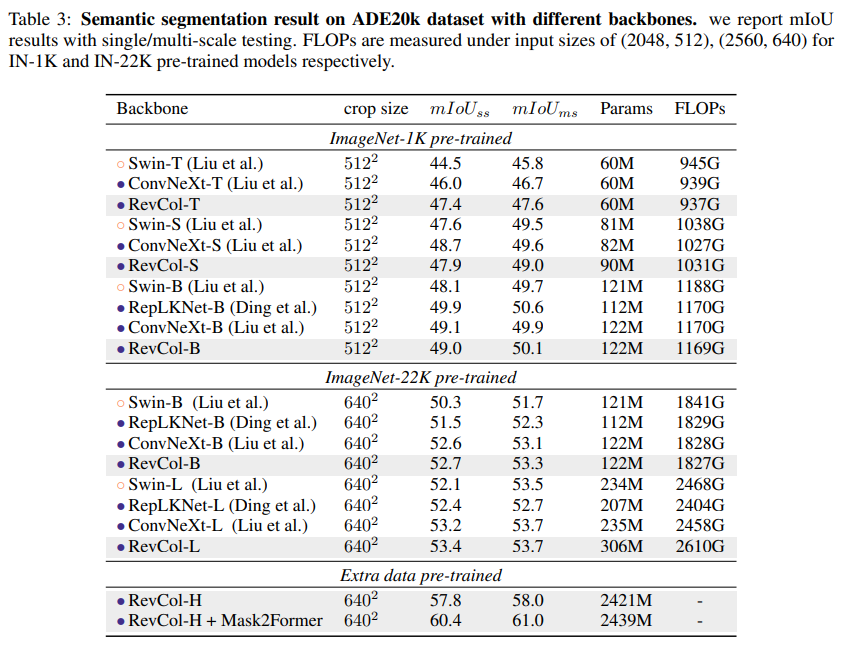
在Tab. 3中,我們報告了驗證集單尺度測試和多尺度翻轉測試的mIoU。RevCol模型可以在不同模型容量上實現有競爭力的性能,進一步驗證了我們架構設計的有效性。值得注意的是,當使用Mask2Former檢測器和額外的預訓練數據時,RevCol-H達到了61.0%的mIoU,這表明它在大規模視覺應用中具有可行的可擴展性。
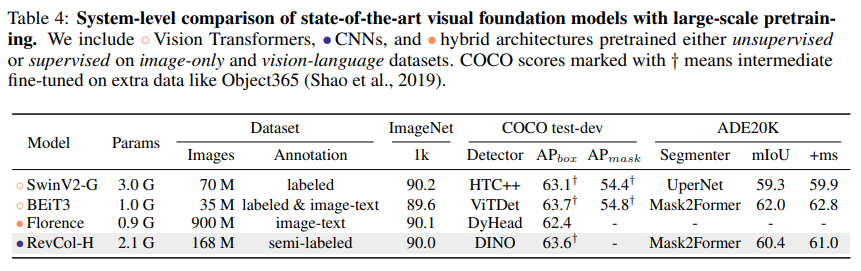
3.4、與SOTA基礎模型的系統級比較
基礎模型(Kolesnikov等人,2020;Radford等人,2021;Yuan等人,2021b)是通用目的的主干網絡,它們在大規模和多樣化數據源上進行預訓練,可以適應各種下游任務,只需使用有限的特定域數據。我們比較了各種公開的、最先進的(SOTA)基礎模型,包括視覺轉換器和視覺語言模型,即SwinV2(Liu等人,2022a)、BEiT3(Wang等人,2022)和Florence(Yuan等人,2021b)。如Tab. 4所示,盡管我們的RevCol-H是純粹基于卷積的,并且是在單一模態數據集上進行預訓練的,但它在不同任務上的結果都證明了RevCol具有出色的泛化能力,尤其是在具有大規模參數的情況下。
3.5、更多分析實驗
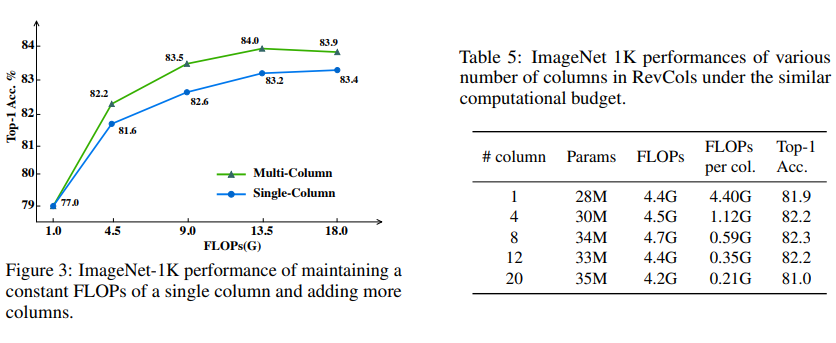
3.5.1、可逆列架構的性能提升
在本節中,我們評估使用可逆列的性能增益。在第一個實驗中,我們固定單個列的結構和FLOPs,然后簡單地添加更多列來擴展大型模型并測試性能。同時,我們繪制了具有相似模型大小的原始單列模型。如圖3所示,與單列模型相比,在相同的FLOPs約束下,使用多列可逆架構總是能獲得更好的性能。此外,在一定范圍內,與僅通過增加塊數(深度)和通道數(寬度)擴展單列模型相比,通過增加列數來擴展RevCol具有相似的增益。在第二個實驗中,我們將模型大小限制為約4.5G FLOPs,并測試了具有不同列數的模型變體。換句話說,我們逐漸添加更多列,同時逐漸減小單列的大小。結果如表5所示,我們注意到采用4到12之間的列數可以保持模型的性能,而進一步的更多列模型性能會下降。我們認為原因是單個列的寬度和深度過低,無法保持表示能力。
3.5.2、可逆網絡與非可逆網絡
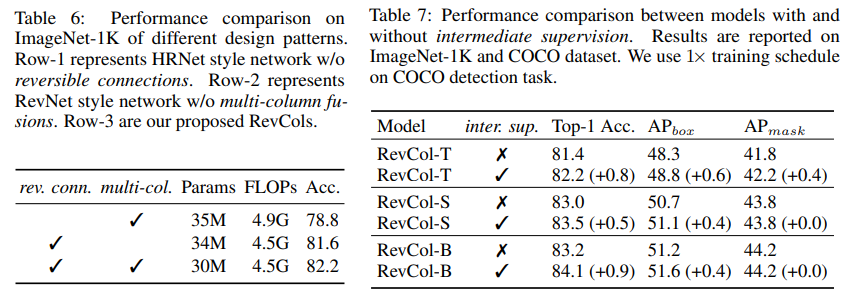
在本節中,我們對可逆連接的不同設計模式進行消融實驗。首先,我們使用HRNet的融合模塊構建了一個非可逆的多列網絡。其次,我們使用RevNet的設計構建了另一個單列可逆的ConvNeXt,如圖2(a)所示。我們將這兩種設計與我們的RevCol進行比較,評估結果如表6所示。非可逆多列網絡在傳播過程中存在信息損失,可能導致精度下降。可逆單列網絡在傳播過程中保持信息,但缺乏多級融合的優勢。這個實驗進一步表明將可逆設計與多列網絡相結合的有效性。
3.5.3、使用中間監督的性能提升
在本節中,我們在ImageNet-1K上評估了使用和不使用中間監督的RevCol-T/S/B的性能。我們還評估了在MS-COCO數據集上使用1×訓練計劃的目標檢測任務性能。其他設置保持不變。從表7中的驗證結果可以看出,使用中間監督訓練的模型取得了0.5%至0.9%的更好的top-1準確率。此外,中間監督也有利于下游任務,這進一步證明了其有效性。
3.5.4、GPU內存消耗與模型大小
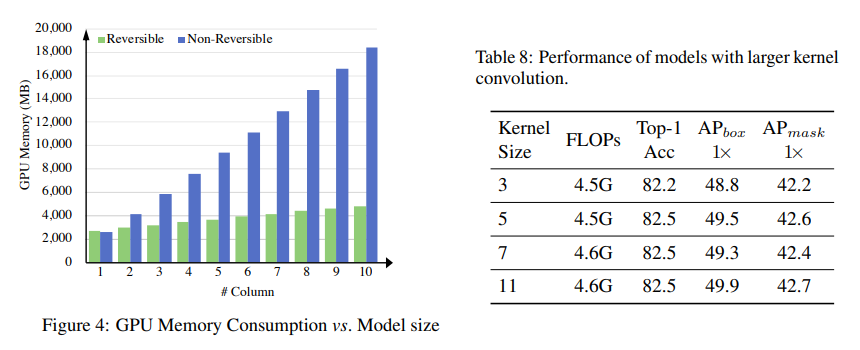
圖4繪制了GPU內存消耗與模型大小的關系。我們將單個列的計算復雜性固定為1G FLOPs,并增加列數。同時,我們測量了包括前向和后向傳播在內的訓練過程中的內存消耗。我們的實驗是在Nvidia Tesla V100 GPU上進行的,批量大小為64,FP16精度和PyTorch實現。隨著列數的增加,我們可以看到RevCol保持常數的GPU內存消耗,而非可逆架構的內存消耗隨著列數的增加而線性增加。請注意,我們的RevCol并不嚴格保持相同的GPU內存消耗,因為可逆網絡需要備份計算梯度所需的操作權重以及在反向傳播中進行特征圖的重建。
3.5.5、卷積中核大小的消融實驗
在原始ConvNeXt中,使用大核卷積可以獲得更好的性能。我們在RevCol-T中進行了實驗。如表8所示,對于4列模型,使用5×5卷積使ImageNet-1k Top-1準確率提高了0.3%,使COCO AP_{box}提高了0.7%。進一步增加核大小可以在下游任務中獲得更多準確度,但不會太多。我們認為RevCol設計已經擴大了有效感受野,這限制了使用大核卷積的準確度增益。另一方面,3×3卷積在(預)訓練中具有效率和穩定性的優點。因此,我們在所有RevCol模型中采用核3。
4、相關工作
4.1、分離表示學習和部分-整體層次
分離表示通常被描述為一種將變化因素分離,明確表示數據的重要屬性的方法(Desjardins等人,2012年;Bengio等人,2013年)。Desjardins等人(2012年);Kulkarni等人(2015年);Higgins等人(2017年);Chen等人(2016年);Karras等人(2019年)通過生成模型尋求學習分離表示。Locatello等人(2019年)指出,沒有對所考慮的學習方法和數據集的歸納偏置,無監督學習分離表示從根本上來說是不可能的。最近的GLOM(Hinton,2021年)提議通過權重共享列來表示部分-整體層次。GLOM架構為深度神經網絡提供了解釋的部分-整體層次(Garau等人,2022年)。在RevCol中,我們采用了使用列的設計,但沒有對形成島嶼的過程進行建模。相反,我們的列迭代過程維護了低級和高級信息,并逐漸將它們分離。RevCol可以使用端到端的監督進行訓練,而不是使用自我監督的方法。
4.2、可逆網絡
Gomez等人(2017)首次提出了可逆網絡RevNet,可以在不保存中間激活的情況下進行反向傳播。可逆設計顯著節省了訓練成本,因為它在模型深度擴展時保持O(1)的GPU內存消耗。Jacobsen等人(2018)提出了一種完全可逆的網絡,可以在不損失任何信息的情況下返回到輸入。Chang等人(2018)開發了一個關于深度神經網絡穩定性和可逆性的理論框架,并推導出可以任意加深的可逆網絡。Mangalam等人(2022)將可逆網絡的范圍從CNN擴展到了Transformer。我們的RevCol在RevBiFPN中將信息保留在每個列內,而不是整個BiFPN網絡內。
5、結論
本文提出了一種基于可逆柱的基礎模型設計范式RevCol。在通過列進行無損傳播的過程中,學會了RevCol中的特征逐漸解糾纏,并且仍然保持總信息而不是壓縮。我們的實驗表明,RevCol可以在多個計算機視覺任務中獲得具有競爭力的性能。我們希望RevCol能夠在視覺和語言領域的各種任務中做出更好的貢獻。
A、MICRO 設計細節
在本節中,我們將提供RevCol的架構設計細節。如圖2和2.2節所示,我們的RevCol包含多個具有可逆連接的列。圖5 (a)顯示了ConvNeXt的架構。請注意,我們將ConvNeXt中的7 × 7深度卷積替換為3 × 3,如第2.2.2節所述。在圖5 (b)中,我們詳細展示了如何在ConvNeXt的基礎上擴展到我們的RevCol。首先,我們用融合塊替換下采樣塊,以融合當前列中的低級表示和前一列中的高級表示,圖5 ?顯示了融合塊的細節,其中包含上采樣和下采樣操作,以處理不同的分辨率。其次,對于每個級別,來自前一列的相同級別表示被添加到當前級別的輸出中,并準備作為一個整體傳播。由于這兩個修改,來自不同層次的特征映射聚合在一起形成中間表示。在圖5 ?中,我們使用Linear-LayerNorm,然后使用最接近的插值來上采樣低分辨率特征。一個步幅為2的2 × 2核Conv2d向下采樣高分辨率特征,然后是一個LayerNorm來平衡兩個輸入的貢獻。
B、概括Transformer
B.1、視覺Transformer模型
RevCol包含多個具有可逆連接的輕量級子網絡。在本文中,除了多列融合和較小的卷積核外,我們默認采用ConvNext微設計,如第2.2.2節所述。然而,我們的RevCol的微設計不僅限于卷積網絡,而且還與等變設計兼容,例如原始視覺Transformer(ViT)(Dosovitskiy等人,2020)。在本節中,我們展示了RevCol的微設計可以推廣到原始ViT,即RevCol-ViT,并取得了有希望的實驗結果。
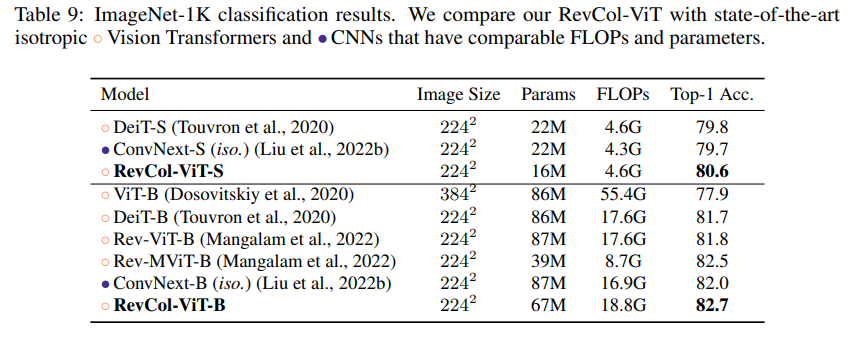
Net-ViT保持了可逆列中的特征分辨率。因此,融合模塊中的補丁合并塊和上采樣塊被一個簡單的線性投影和后LayerNorm所取代。我們使用的是原始的ViT構建塊,而不是ConvNext構建塊的變體。類似于Liu等人(2022a),在ViT塊中使用后LayerNorm和歸一化的點積注意力來穩定訓練收斂。由于具有各向同性的性質,我們均勻地排列每個列中的構建塊。RevCol-ViT的配置細節為:
- RevCol-ViT-S: C=(224,224,224,224), B=(2,2,2,2), H E A D=4, C O L=4
- RevCol-ViT-B: C=(384,384,384,384), B=(3,3,3,3), H E A D=6, C O L=4
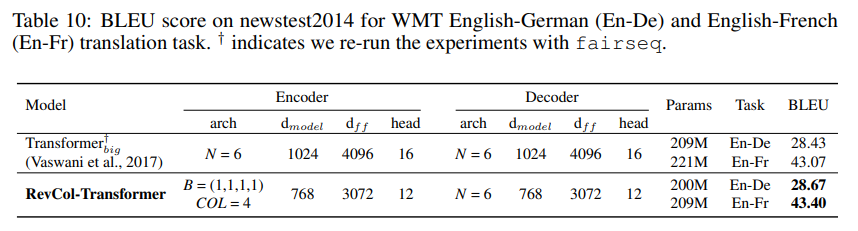
除了丟棄各向異性的RevCol中的中間監督以簡化模型,并將RevCol-B的隨機深度率設置為0.2,我們使用與第3.1節中所述相同的訓練設置。我們根據網絡深度縮放每個FFN中的最后一個線性投影層的值,與BEiT(Bao等人,2021)相同。在表9中,我們將RevCol-ViT與原始ViT和其他同時各向同性的設計進行比較。我們的RevCol-ViT優于原始視覺Transformer(ViT為77.9%,DeiT為81.7%)和具有可比較模型參數和計算開銷的卷積網絡ConvNeXt(82.0%),在ImageNet-1k分類中以頂級-1準確率衡量。
B.2、語言模型
考慮到將Transformer應用于計算機視覺的成功,即ViT(Dosovitskiy等人,2020),我們也進行了一些探索,以將RevCol泛化到自然語言處理(NLP)。基于附錄B.1中的設計,我們可以很容易地將各向同性的RevCol應用到語言模型中,只需進行少量修改。具體來說,我們用單詞嵌入和位置編碼替換了我們的RevCol中的stem模塊,然后,RevCol可以作為編碼器插入到原始的transformer中。RevCol中最后一個列的輸出將用作注意力層的記憶鍵和值,這與原始的transformer完全相同。
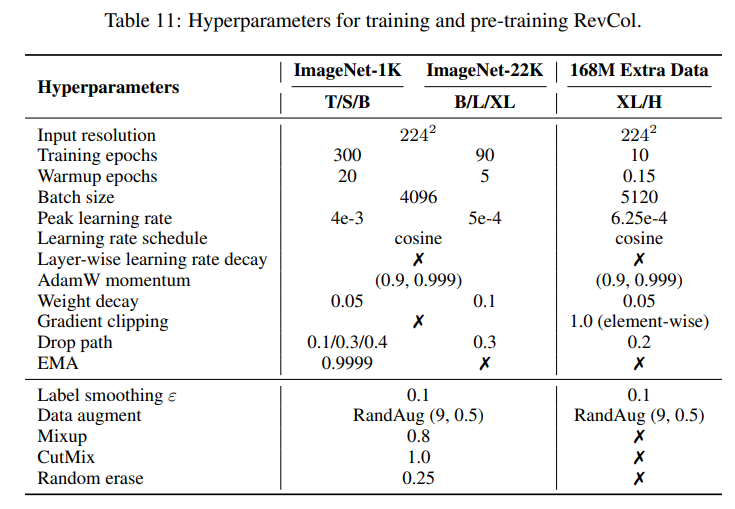
我們選擇翻譯任務來評估RevCol在NLP中的潛力。我們在WMT’16英語-德語(En-De)數據集上進行了實驗,該數據集包含450萬個句子,以及更大的WMT’14英語-法語數據集,包含3.6億個句子。每個句子都按照Sennrich等人(2016)的順序,使用聯合源編碼和目標字節對編碼進行編碼。模型架構的細節和BLEU分數在表10中列出。
所有數據集的準備和訓練配置都遵循Ott等人(2018)和開源項目fairseq。模型在En-De上訓練30萬步,批量大小為28672個令牌,在En-Fr上訓練20萬步,批量大小為86016個令牌。為簡單起見,我們丟棄了中間監督。如Tab. 10所示,我們的RevCol在En-De(28.67 vs. 28.43)和En-Fr(43.40 vs. 43.07)上優于原始的Transformer,具有可比較的參數,這表明了RevCol對NLP的適用性。
B.3 列數量的魯棒性
在論文的消融分析中,我們發現當總浮點運算次數保持不變并增加更多列的RevCol時,性能首先增加然后趨于飽和。當列的數量非常大時,例如20列,由于單個列的表示能力有限,性能會下降。當列的數量通常為4列或12列時,性能類似,這驗證了列數量的設置魯棒性。
為了進一步分析列數量的魯棒性,本節構建了一些RevColViT-B變體(更多細節請參見附錄B)。每個變體具有相同數量的殘差塊和相同的通道維度,但列的數量不同。換句話說,這些變體具有相同的通道維度,但每列的深度和列的數量不同。總共使用32個殘差塊并保持浮點運算次數約為18G。圖6顯示了不同變體在ImageNet-1K上的性能。列的數量為1、2、4和8,因此每列的深度分別為32、16、8和4。單列變體的性能較低(類似于DeiT-B(Touvron等人,2020)),因為單列ViT無法像多列可逆那樣維護信息。當列的數量增加時,性能下降,因為每列的深度不夠。這種現象表明,給定目標浮點運算次數,除非每列的深度或通道維度過小,否則列數量的設置是魯棒的。
C. 半標注私人收集的大型模型數據集
C.1 數據收集和偽標簽系統
該數據集包含約1.68億(M)張圖片,其中50M張帶有標簽,其余1.18億張為未標記。大多數帶標簽的圖片來自公共數據集,例如ImageNet、Places365(Zhou等人,2017a)和Bamboo(Zhang等人,2022b)。其他的是由內部員工標注的網絡爬蟲圖片。未標記的圖片來自弱注釋的圖像文本數據集,如YFCC-100M(Thomee等人,2016)。我們不使用文本注釋。
為了利用不同標簽域的圖像和大量未標記的圖像,我們采用了類似于Ding等人(2022a)和Ghiasi等人(2021)的多目標標簽系統。我們采用了基于ViTs的半監督學習策略,從而生成質量不斷提高的偽標簽。我們只存儲置信度高于1%的軟預測結果以節省存儲空間。我們使用的最終版本偽標簽是由一個準確率為89.0%的Multi-head ViT-Huge教師模型生成的。
C.2 圖像去重
由于數據集包含大量未經核實的網絡爬蟲圖像,因此我們的訓練數據集中可能混入了驗證或測試圖像。Mahajan等人(2018)和Yalniz等人(2019)的工作都認為圖像去重對于公平的實驗來說是一項重要的過程。
我們首先遍歷整個數據集,根據它們的偽標簽距離過濾出可疑的重復項以及相應的測試圖像。這帶來了超過10,000張具有高度可疑性的圖像。我們查看這些圖像對,并最終找到約1,200個完全重復和近似重復的圖像。圖7顯示了一些近似的重復例子,這些是難以檢測到的。然而,在我們的實驗中,不刪除這些重復項訓練模型在ImageNet-1k上的準確率提高了不到0.1%。我們將這歸因于這些重復項缺少真實標簽。

D. 更多訓練細節
本節提供了有關ImageNet分類、COCO檢測和ADE20K分割的更多訓練細節。
D.1 中間監督設置
我們在ImageNet-1k訓練、ImageNet-22k和額外數據預訓練中添加了中間監督。我們在ImageNet-1k訓練中使用了3個塊的解碼器,特征圖逐漸上采樣。與第2.2節一樣,塊設置保持不變。在ImageNet-22k和額外數據預訓練中,我們使用單層解碼器。對于所有RevCol變體,我們將復合損失數n設置為3(例如,對于8列RevCol,中間監督添加到第2、4和6列,同時原始分類CE損失也添加到第8列)。 α i α_i αi?設置為3、2、1、0, β i β_i βi?設置為0.18、0.35、0.53、1。
D.2 用于訓練和預訓練的超參數
本節介紹了主要實驗的訓練細節,即在ImageNet和額外數據上進行的有監督訓練。我們將在表11中展示此設置。除附加說明外,所有實驗中的 ablation studies 都是在 ImageNet-1K 上進行有監督訓練的,并且遵循本節中描述的設置。
D.3 用于微調的超參數
本節介紹了用于在ImageNet-1K進行微調的下流COCO目標檢測和實例分割、ADE20K語義分割任務的超參數,如表12、表13和表14所示。
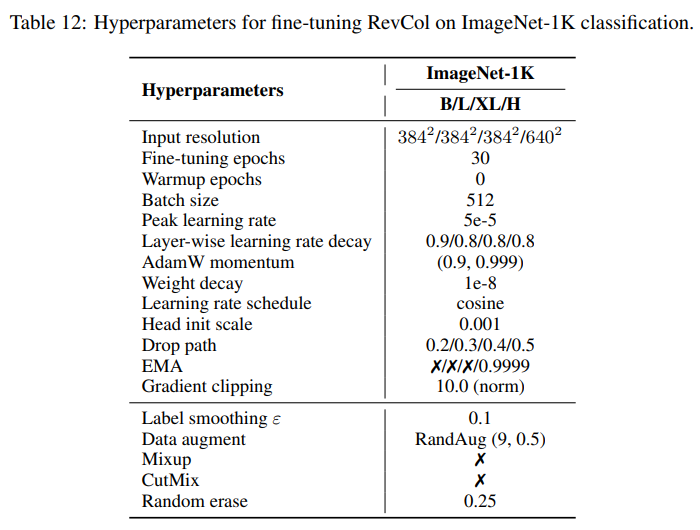
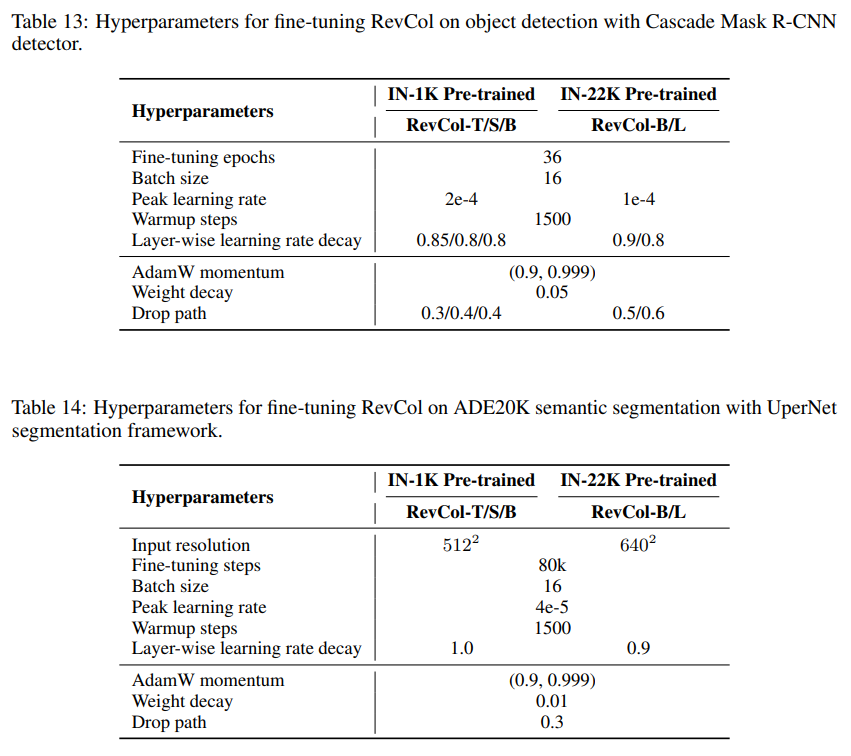
D.3.1、下游任務中的卷積核填充技巧
根據第3.5.5節的結果,較大的卷積核在下游任務中表現更好。為了節省預訓練成本并獲得更好的性能,我們將預訓練模型權重中的3x3卷積核填充為較大的尺寸,然后在檢測和分割任務中進行微調。受Net2net(Chen等人,2015)方法啟發,我們在卷積層中用高斯初始化的值填充預訓練的3x3核。為了保護預訓練的核免受新填充值的影響,我們用0均值和極小的標準差(1e-7)初始化填充的值。我們只在最大的模型RevCol-H上使用此技巧。在COCO檢測任務中,我們將預訓練模型中的3x3核填充為7x7的核大小,在ADE20k語義分割任務中填充為13x13,然后在相應的數據集上進行微調以獲得最終結果。一般來說,對于RevCol-H模型,核填充技巧可以使AP_box提高0.5~0.8個單位,mIoU提高 0.7 1.0 0.7~1.0 0.7?1.0個單位。
E、功能解耦的可視化
在本節中,我們將展示我們的RevCol如何使用堆疊列來解耦特征,這與傳統的順序網絡不同。我們使用在ImageNet-1K上預訓練的RevCol-S進行分析。首先,我們可視化每個級別最后一個層的輸出類激活映射(CAMs)。我們采用LayerCAM(Jiang等人,2021)技術生成具有預測類別的CAMs。圖8顯示了激活的熱力圖。隨著級別和列的深入,特征關注具有更多語義的區域。RevCol-S的輸出是最后一列的不同級別。這些具有高級語義的特征關注圖像的不同部分和對象的整個部分,實現了任務相關和任務無關的功能解耦。
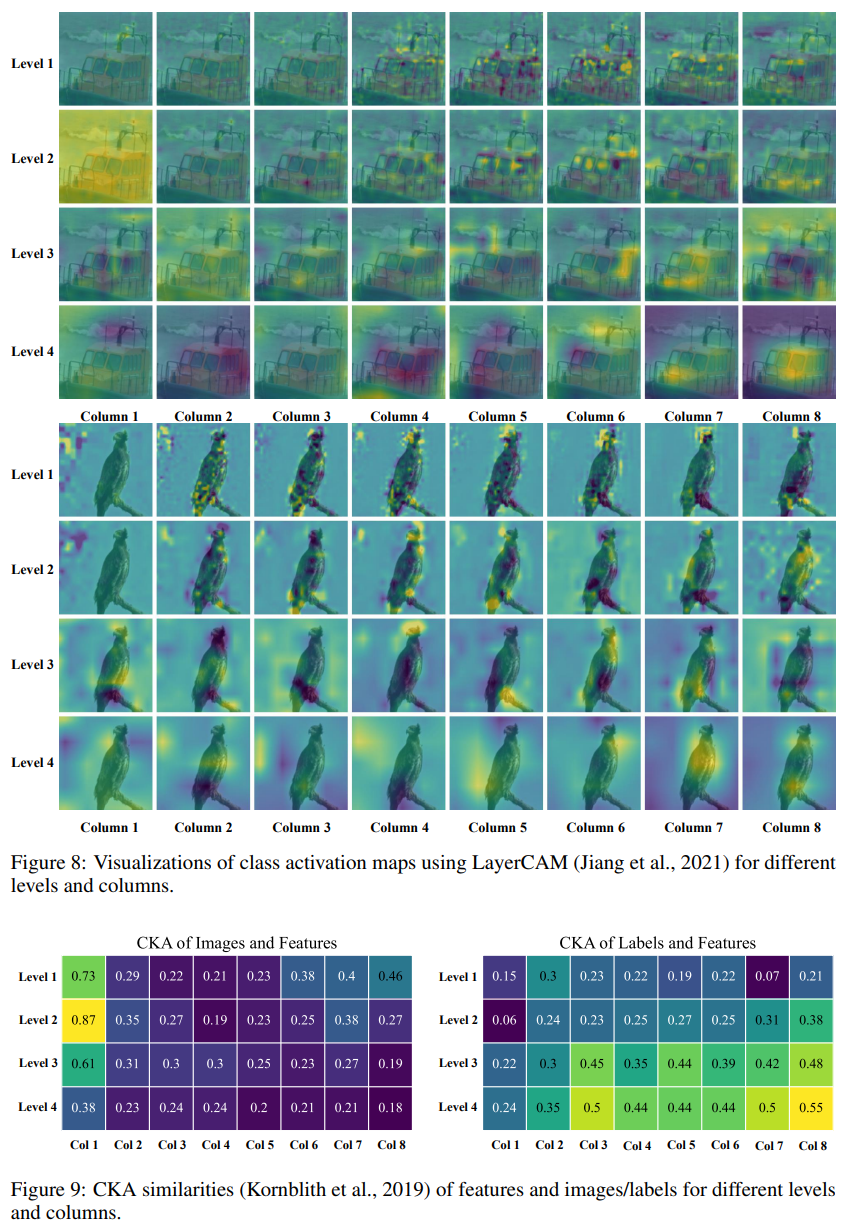
為了定量評估解耦程度,我們使用Centered Kernel Alignment (CKA)相似度度量(Kornblith等人,2019年)來衡量RevCol-S中表示之間的相似性。我們計算不同級別和列之間的中間特征與每個類別在ImageNet驗證集中的圖像或標簽之間的CKA相似性。然后,我們在圖9中繪制了具有最高標簽相似度的類別的相似性。如圖所示,在第2-5列中,圖像和中間特征之間的相似性在不同級別上沒有明顯區分,而第6-8列中具有較高級別的特征與圖像的相似度較低。標簽和中間特征之間的相似性在較高列中更為明顯。


|LeetCode1049. 最后一塊石頭的重量 II、LeetCode494. 目標和)



)











)
