
論文地址:https://arxiv.org/pdf/2211.12860.pdf
代碼地址:?GitHub - Sense-X/Co-DETR: [ICCV 2023] DETRs with Collaborative Hybrid Assignments Training
摘要
作者提出了一種新的協同混合任務訓練方案,即Co-DETR,以從多種標簽分配方式中學習更高效的基于detr的檢測器。這種新的訓練方案通過訓練ATSS和Faster RCNN等一對多標簽分配監督下的多個并行輔助頭部,可以很容易地提高編碼器在端到端檢測器中的學習能力。此外,作者通過從這些輔助頭部提取正坐標來進行額外的定制正查詢,以提高解碼器中正樣本的訓練效率。在推理中,這些輔助頭被丟棄,因此,作者的方法不給原始檢測器引入額外的參數和計算成本,同時不需要手工制作的非最大抑制(NMS)。
太長不看版:
本文也就是在DINO的基礎上,對DINO Deformable-transformer的encoder輸出的memory按每層特征圖尺寸展開(加一個最后一層的下采樣,共五層特征圖),在這五層特征圖上使用一對多標簽分配監督訓練即ATSS和faster-rcnn,除了特征圖的來源不同外,其余的訓練方式和ATSS以及faster-rcnn是一樣的。
如果還不是很了解DINO的可以看我的系列博文:
DINO代碼學習筆記(一)_athrunsunny的博客-CSDN博客
DINO代碼學習筆記(二)_athrunsunny的博客-CSDN博客
DINO代碼學習筆記(三)-CSDN博客
DINO代碼學習筆記(四)-CSDN博客
或者,DINO的原作者在知乎上也有對其文章的講解:DINO
以及可以通過Deformable-DETR代碼學習筆記_athrunsunny的博客-CSDN博客?加深對Deformable-transformer的理解
ATSS簡介:
ATSS(Adaptive Training Sample Selection)是一種目標檢測算法,用于在圖像中準確地檢測和定位目標物體。它是一種單階段目標檢測方法,旨在解決傳統單階段方法在處理密集目標和大尺度目標時的困難。
ATSS 的核心思想是根據目標與錨框之間的相似度(中心點距離)來選擇訓練樣本。傳統的單階段目標檢測方法使用固定的正負樣本采樣策略,但這種策略在處理密集目標和大尺度目標時可能會導致樣本不均衡的問題。ATSS 通過引入自適應樣本選擇機制,根據目標與錨框之間的相似度動態地選擇正負樣本,從而提高了模型的性能。
具體來說,ATSS 首先在每一層feature map上通過計算目標與每個錨框之間的相似度,得到每個錨框的iou。然后,根據iou對錨框進行排序,并選擇iou最高的一部分錨框作為正樣本。接下來,ATSS 使用一種自適應的方式選擇負樣本,即根據正樣本的分布情況來選擇與正樣本相似度較低的錨框作為負樣本。這樣可以有效地減少負樣本的數量,并提高模型對困難樣本的學習能力。
1. 介紹
????????在本文中,作者試圖使基于detr的檢測器優于傳統檢測器,同時保持其端到端優點。為了解決這一挑戰,作者將重點放在一對一集合匹配的直觀缺點上,即它探索的是不太積極的查詢。這將導致嚴重的訓練效率低下問題。作者從編碼器產生的潛在表征和解碼器的注意學習兩個方面詳細分析了這一點。作者首先比較了deform - detr和一對多標簽分配方法之間潛在特征的可判別性得分,其中作者簡單地將解碼器替換為ATSS頭部。利用每個空間坐標上的特征12范數表示可判別性得分。給定編碼器的輸出F∈RC×H×W,就可以得到可判別性評分圖S∈R1×H×W。目標在相應區域的得分越高,越容易被檢測到。如圖2所示,作者通過對判別性分數應用不同的閾值來演示IoF-IoB曲線(IoF:前景相交,IoB:背景相交)(詳情見第3.4節)。ATSS的IoF-IoB曲線越高,說明它更容易區分前景和背景。
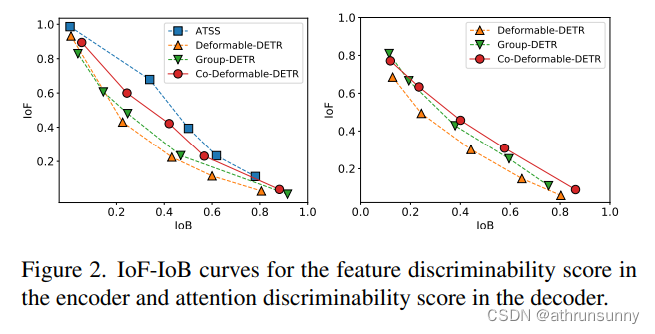
????????作者在圖3中進一步可視化可判別性評分圖S。很明顯,一對多標簽分配方法充分激活了一些顯著區域的特征,但在一對一集合匹配中卻沒有得到充分的探索。對于解碼器訓練的探索,作者還展示了基于deform - detr和Group-DETR的解碼器中交叉注意分數的IoF-IoB曲線,該曲線在解碼器中引入了更多的正向查詢。圖2中的插圖顯示,太少的積極查詢也會影響注意學習,而在解碼器中增加更多的積極查詢可以稍微緩解這種情況。

????????這一重要的觀察結果促使作者提出一種簡單而有效的方法——協同混合任務訓練方案(Co-DETR)。CoDETR的關鍵思想是使用通用的一對多標簽分配來提高編碼器和解碼器的訓練效率和有效性。更具體地說,作者將輔助頭與變壓器編碼器的輸出集成在一起。這些頭部可以通過多用途的一對多標簽分配來監督,如ATSS、FCOS和Faster RCNN。不同的標簽分配豐富了對編碼器輸出的監督,這迫使它具有足夠的判別性,以支持這些頭部的訓練收斂。為了進一步提高解碼器的訓練效率,作者在這些輔助頭部中對正樣本的坐標進行了精心編碼,包括正錨點和正提議。它們作為多組正查詢發送到原始解碼器,以預測預先分配的類別和邊界框。每個輔助頭部的正坐標作為一個獨立的組,與其他組隔離。多用途的一對多標簽分配可以引入大量(正查詢、真值)對來提高解碼器的訓練效率。注意,在推理過程中只使用原始解碼器,因此,所提出的訓練方案只在訓練過程中引入額外的開銷。
????????作者進行了大量的實驗來評估所提出方法的效率和有效性。如圖3所示,Co-DETR極大地緩解了一對一集合匹配中編碼器的特征學習問題。作為即插即用的方法,很容易將其與不同的DETR變體組合,包括DAB-DETR , DeformableDETR和DINO-Deformable-DETR。
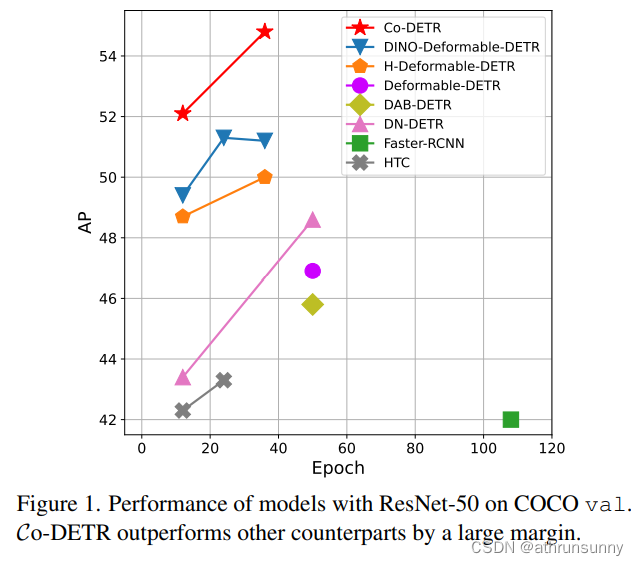
如圖1所示,Co-DETR實現了更快的訓練收斂,甚至更高的性能。具體來說,作者將基本的deform - detr在12 epoch訓練中提高了5.8% AP,在36 epoch訓練中提高了3.2% AP。使用Swin-L的最先進的DINO-Deformable-DETR在COCO val上的AP仍然可以從58.5%提高到59.5%。令人驚訝的是,結合vit -L主干,在COCO測試開發上實現了66.0%的AP,在LVIS val上實現了67.9%的AP,以更小的模型尺寸建立了新的最先進的檢測器。
2. 相關工作
One-to-many label assignment
對于目標檢測中的一對多標簽分配,可以在訓練階段將多個候選框作為正樣本分配到同一個ground-truth box中。在經典的基于錨點的檢測器中,如Faster-RCNN和RetinaNet,樣本選擇由預定義的IoU閾值和錨點與標注框之間的匹配IoU來指導。無錨點FCOS利用中心先驗,將每個邊界框中心附近的空間位置賦值為正。在一對多標簽分配中引入自適應機制,克服了固定標簽分配的局限性。ATSS通過最接近的k個錨的統計動態IoU值進行自適應錨選擇。PAA以概率方式自適應地將錨點分為陽性和陰性樣本。在本文中,作者提出了一種協作混合分配方案,通過一對多標簽分配的輔助頭來改進編碼器表示。
One-to-one set matching?
開創性的基于變壓器的檢測器DETR將一對一集合匹配方案融入到目標檢測中,實現完全的端到端目標檢測。一對一集合匹配策略首先通過匈牙利匹配計算全局匹配成本,并為每個真值盒只分配一個匹配成本最小的正樣本。DNDETR證明了由于一對一集合匹配的不穩定性導致的緩慢收斂,因此引入去噪訓練來消除這一問題。DINO繼承了DAB-DETR的高級查詢公式,并結合了改進的對比去噪技術,以實現最先進的性能。Group-DETR構造組明智的一對多標簽分配,利用多個正對象查詢,類似于H-DETR中的混合匹配方案。在上述后續工作的基礎上,本文提出了一對一集合匹配協同優化的新視角。
3.本文方法
????????根據標準的DETR協議,輸入圖像被送入主干和編碼器以生成潛在特征。多個預定義對象查詢在解碼器中通過交叉注意與它們交互。作者引入Co-DETR,通過協同混合任務訓練方案和自定義正查詢生成來改善編碼器的特征學習和解碼器的注意學習。作者將詳細描述這些模塊,并給出它們為什么可以很好地工作的見解。
3.2. Collaborative Hybrid Assignments Training
????????為了減輕由于解碼器中較少的正查詢而導致的編碼器輸出的稀疏監督,我們結合了具有不同多標簽分配范例的多功能輔助頭,例如ATSS和Faster R-CNN。不同的標簽分配豐富了對編碼器輸出的監督,這迫使它具有足夠的判別性,以支持這些頭部的訓練收斂。具體來說,給定編碼器的潛在特征F,我們首先通過多尺度適配器將其轉換為特征金字塔{F1,···,FJ},其中J表示下采樣步幅為的特征映射。與ViT-Det類似,特征金字塔是由單尺度編碼器中的單個特征映射構建的,而我們使用雙線性插值和3 × 3卷積進行上采樣。例如,對于來自編碼器的單尺度特征,我們依次應用下采樣(3×3與stride 2卷積)或上采樣操作來產生特征金字塔。對于多尺度編碼器,我們只對多尺度編碼器特征F中最粗的特征進行下采樣,構建特征金字塔。定義了K個協作頭,并以相應的標簽分配方式Ak,對于第i個協作頭,將{F1,···,FJ}發送給它,以獲得預測值^Pi在第i個頭部,Ai用于計算Pi中正樣本和負樣本的監督目標。記為G為GT,此過程可表示為:

其中{pos}和{neg}表示由Ai確定的(j, Fj中的正坐標或負坐標)的對集。j表示{F1,···,FJ}中的特征索引。B{pos}是空間正坐標的集合。P{pos} i和P{neg} i是相應坐標下的監督目標,包括類別和回歸偏移量。具體地說,我們在表1中描述了每個變量的詳細信息。
損失函數可定義為:

?注意,對于負樣本,回歸損失被丟棄。K個輔助頭部優化的訓練目標為:
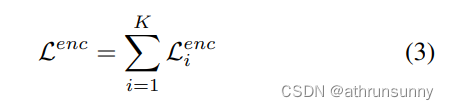
3.3. Customized Positive Queries Generation
????????在一對一集匹配范式中,每個GT框將只被分配給一個特定的查詢作為監督目標。正查詢太少會導致轉換器解碼器中的交叉注意學習效率低下,如圖2所示。為了緩解這種情況,我們根據每個輔助頭中的標簽分配Ai精心生成足夠的自定義正查詢。具體來說,給定第i個輔助頭部的正坐標集B{pos} i∈RMi×4,其中Mi為正樣本個數,則額外定制的正查詢Qi∈RMi×C可以通過以下方式生成:
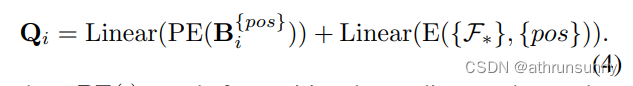
其中PE(·)表示位置編碼,根據索引對(j, Fj中的正坐標或負坐標)從E(·)中選擇相應的特征。
????????因此,在訓練期間,有K + 1組查詢有助于單個一對一集匹配分支和K個具有一對多標簽分配的分支。輔助的一對多標簽分配分支與原始主分支中的L個解碼器層共享相同的參數。輔助分支中的所有查詢都被視為正查詢,因此放棄匹配過程。具體來說,是第1解碼器層的損失在第i輔助分支中可表示為:

Pi,l為第i輔助支路第l解碼器層的輸出預測值。最后,Co-DETR的訓練目標為:
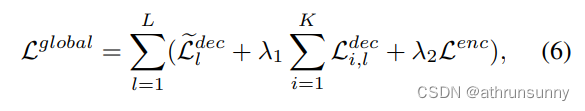
?其中,~Ldecl表示原一對一集匹配分支中的損失,λ1和λ2為平衡損失的系數。
3.4. Why Co-DETR works
????????Co-DETR使基于detr的檢測器有了明顯的改進。接下來,我們嘗試定性和定量地考察其有效性。我們基于Deformable-DETR與ResNet50主干使用36epoch設置進行了詳細的分析。
Enrich the encoder’s supervisions?
????????直觀地說,太少的正查詢會導致稀疏的監督,因為對于每個GT只有一個查詢是由回歸損失監督的。一對多標簽分配方式下的正樣本得到更多的定位監督,有助于增強潛在特征學習。為了進一步探索稀疏監督如何阻礙模型訓練,作者詳細研究了編碼器產生的潛在特征。引入了IoF-IoB曲線來量化編碼器輸出的可判別性分數。具體來說,給定編碼器的潛在特征F,受圖3中特征可視化的啟發,作者計算IoF(前景相交)和IoB(背景相交)。給定j層編碼器的特征Fj∈RC×Hj×Wj,首先計算l2范數bFj∈R1×Hj×Wj,并將其大小調整為圖像大小H ×W。判別性評分D(F)由各等級得分平均計算得出:
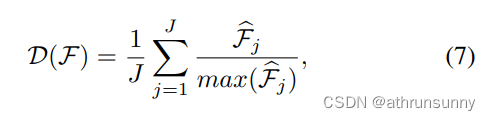
其中省略了調整大小操作。我們在圖3中可視化了ATSS、deform - detr和co - deform - detr的判別分數。與Deformable-DETR相比,ATSS和Co-Deformable-DETR都具有更強的關鍵目標區域識別能力,而Deformable-DETR幾乎不受背景干擾。因此,我們將前景和背景的指標分別定義為1(D(F) > S)∈RH×W和1(D(F) < S)∈RH×W。S是預定義的分數閾值,如果x為真,則1(x)為1,否則為0。對于前景Mf g∈RH×W的掩碼,如果(h, w)點在前景內,則元素Mf g h為1,否則為0。前景交點面積(IoF)如果g可以計算為:
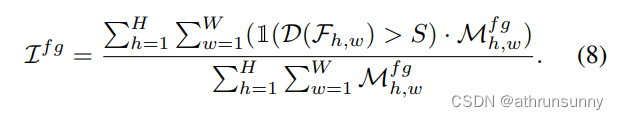
具體來說,我們以類似的方式計算背景區域的交點面積(IoB),并在圖2中通過改變S繪制出IoF和IoB曲線。顯然,在相同的IoB值下,ATSS和co - deform - detr比deform - detr和Group-DETR獲得更高的IoF值,這表明編碼器表示從一對多標簽分配中受益。?
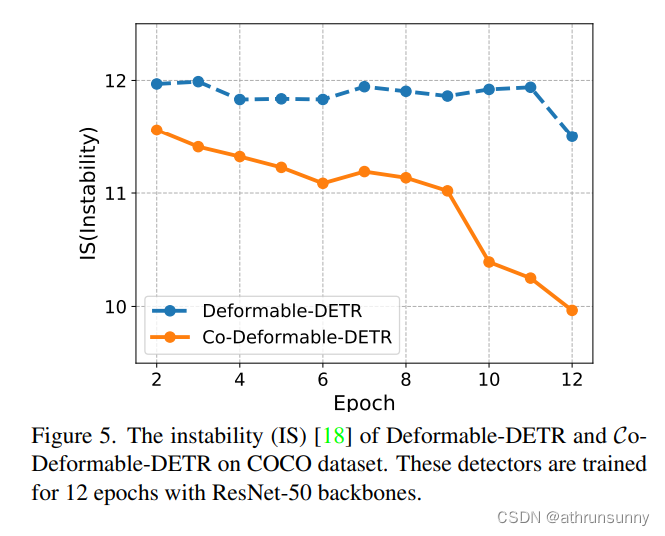
Improve the cross-attention learning by reducing the instability of Hungarian matching????????
????????匈牙利匹配是一對一集合匹配的核心方案。交叉注意是幫助正查詢編碼豐富對象信息的重要操作。要做到這一點,需要充分的訓練。作者觀察到匈牙利匹配引入了不可控的不穩定性,因為在訓練過程中,分配給同一圖像中特定正查詢的真值是變化的。接下來,作者在圖5中給出了不穩定性的比較,作者發現他們的方法有助于更穩定的匹配過程。此外,為了量化交叉注意力的優化程度,還計算了注意力得分的IoF-IoB曲線。與特征可判別性分數計算類似,作者對注意力分數設置不同的閾值,得到多個IoF-IoB對。Deformable-DETR、Group-DETR和CoDeformable-DETR之間的比較如圖2所示。作者發現,具有更多正查詢的detr的IoF-IoB曲線一般都在deform - detr之上,這與他們的動機是一致的。
3.5. Comparison with other methods
Differences between our method and other counterparts
????????Group-DETR、H-DETR和SQR[2]通過與重復組和重復的ground-truth box進行一對一匹配來實現一對多賦值。Co-DETR明確地為每個基礎真值分配多個空間坐標作為正數。因此,將這些密集的監督信號直接應用到潛在特征映射中,使其具有更強的判別能力。相比之下,Group-DETR、HDETR和SQR缺乏這種機制。雖然在這些對應物中引入了更多的正查詢,但匈牙利匹配實現的一對多分配仍然存在一對一匹配的不穩定性問題。作者的方法受益于現成的一對多分配的穩定性,并繼承了它們在正查詢和真值框之間的特定匹配方式。Group-DETR和H-DETR無法揭示一對一匹配與傳統一對多分配之間的互補性。據作者所知,作者是第一個用傳統的一對多分配和一對一匹配對檢測器進行定量和定性分析的人。這有助于更好地理解它們的差異和互補性,這樣就可以通過利用現成的一對多任務設計來自然地提高DETR的學習能力,而不需要額外的專門的一對多設計經驗。
No negative queries are introduced in the decoder????????
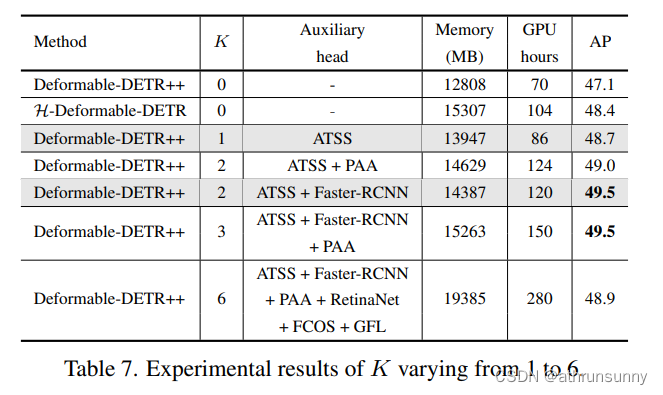
????????重復的對象查詢不可避免地會給解碼器帶來大量的負面查詢,并顯著增加GPU內存。但是,作者的方法只處理解碼器中的正坐標,因此消耗的內存較少,如表7所示。
4. 實驗
實現細節?
????????將Co-DETR合并到當前的類似detr的管道中,并保持訓練設置與基線一致。K = 2時,采用ATSS和Faster-RCNN作為輔助頭,K = 1時只保留ATSS。關于輔助頭的更多細節可以在補充材料中找到。作者選擇可學習對象查詢的數量為300,默認設置{λ1, λ2}為{1.0,2.0}。對于Co-DINODeformable-DETR++,作者使用了帶有大規模抖動的copypaste。
4.2. Main Results
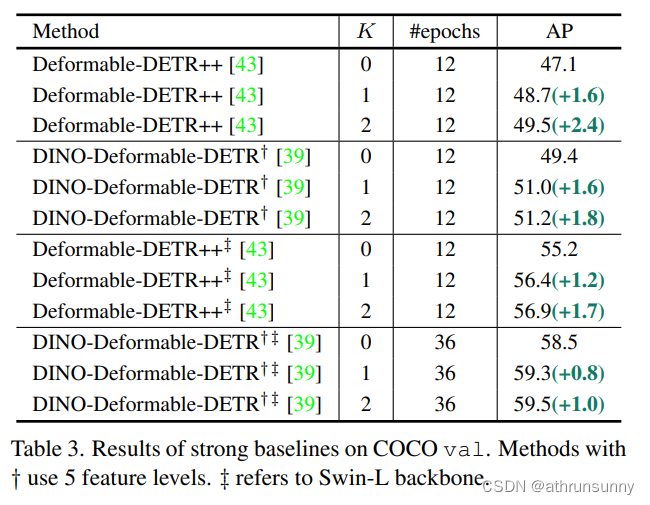
????????在本節中,在表2和表3中實證分析了Co-DETR對不同DETR變量的有效性和泛化能力。所有結果均使用mmdetection重現。首先將協作混合任務訓練應用于具有C5特征的單尺度detr。令人驚訝的是,Conditional-detr和DAB-DETR在較長的訓練計劃下比基線分別獲得2.4%和2.3%的AP增益。對于具有多尺度特征的Deformable-DETR,檢測性能從37.1%顯著提高到42.9%。當訓練時間增加到36次時,整體的改進(+3.2% AP)仍然有效。此外,我們在[16]之后對改進的Deformable-DETR(記為Deformable-DETR++)進行了實驗,觀察到+2.4%的AP增益。采用本方法的最先進的DINO-Deformable-DETR可達到51.2%的AP,比競爭基準高+1.8%。

????????基于兩個最先進的基線,我們進一步將骨干容量從ResNet50擴展到swin-L。如表3所示,Co-DETR達到56.9% AP,并大大超過了deformation - detr ++基線(+1.7% AP)。使用swin-L的DINO-Deformable-DETR的性能仍然可以從58.5%的AP提高到59.5% AP。
4.3. Comparisons with the state-of-the-art
????????作者將K = 2的方法應用于deformable-detr++和DINO。此外,我們的Co-DINO-Deformable-DETR采用了quality focal loss和NMS。在表4中報告了COCO值的比較。與其他競爭對手相比,我們的方法收斂速度快得多。例如,Co-DINO-DeformableDETR在使用ResNet-50骨干網時僅使用12次epoch即可輕松實現52.1%的AP。我們使用SwinL的方法可以在1x調度器上獲得58.9%的AP,甚至超過了其他最先進的3x調度器框架。更重要的是,我們的最佳模型Co-DINO-DeformableDETR++在36 epoch訓練下,使用ResNet-50實現了54.8%的AP,使用swin-L實現了60.7%的AP,明顯優于所有具有相同主干的現有檢測器。

????????為了進一步探索該方法的可擴展性,作者將骨干容量擴展到3.04億個參數。這種大規模主干ViT-L使用自監督學習方法(EVA-02)進行預訓練。我們首先在Objects365上使用ViT-L預訓練Co-DINO-Deformable-DETR 26個epoch,然后在COCO數據集上進行12個epoch的微調。在微調階段,輸入分辨率在480×2400和1536×2400之間隨機選擇。詳細設置請參見補充資料。我們的結果是用測試時間增量來評估的。表5給出了最新的比較COCO測試開發基準。在更小的模型尺寸(304M個參數)下,Co-DETR在COCO測試開發上創造了66.0% AP的新記錄,比之前的最佳模型InternImage-G高出+0.5% AP。

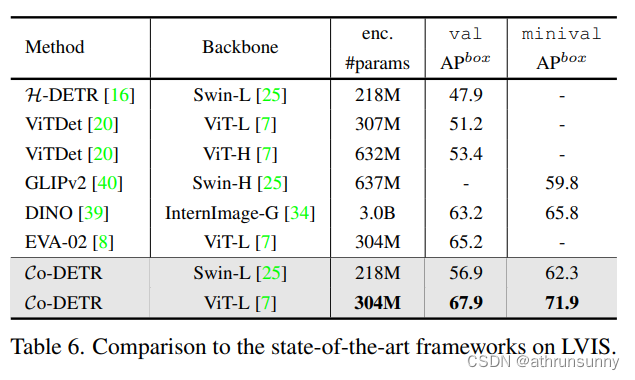
????????作者還證明了Co-DETR在長尾LVIS檢測數據集上的最佳效果。特別地,我們在COCO上使用相同的Co-DINO-Deformable-DETR++模型,但選擇FedLoss作為分類損失,以彌補數據分布不平衡的影響。在這里,我們只應用邊界框監督,并報告目標檢測結果。表6給出了比較結果。Co-DETR Swin-L以56.9%和62.3% AP LVIS val和minival超過ViT-Det與MAE-pretrained ViT-H和GLIPv2的方法骨干AP分別上漲3.5%和2.5%。作者進一步在此數據集上微調Objects365預訓練的Co-DETR。在不增加測試時間的情況下,作者的方法在LVIS val和minival上分別達到67.9%和71.9%的最佳檢測性能。與具有測試時間增強的30億個參數的InternImage-G相比,作者將模型大小減小到1/10的同時,在LVIS val和minival上獲得了+4.7%和+6.1%的AP增益。
4.4. Ablation Studies
????????除非另有說明,所有消融實驗都是在帶ResNet-50骨干網的deform - detr上進行的。默認情況下,作者選擇輔助頭的數量K到1,并將總批大小設置為32。更多的消融和分析可以在補充材料中找到。

Criteria for choosing auxiliary heads?
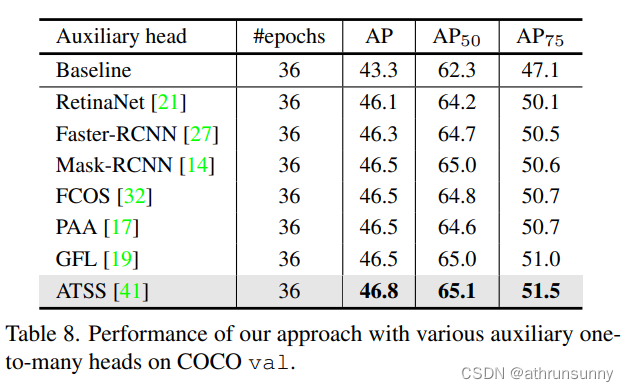
????????作者在表7和表8中進一步研究了選擇輔助頭像的標準。表8中的結果顯示,任何具有一對多標簽分配的輔助頭部都可以持續提高基線,并且ATSS可以達到最佳性能。我們發現,當選擇K小于3時,隨著K的增加,準確率繼續提高。值得注意的是,當K = 6時,性能會出現下降,我們推測這是由于輔助頭之間的嚴重沖突造成的。如果輔助頭部之間的特征學習不一致,則隨著K持續變大改進將被破壞。并在后續和補充資料中分析了多頭的優化一致性。綜上所述,我們可以選擇任意頭部作為輔助頭部,為了在K≤2時達到最佳性能,我們通常選擇ATSS和Faster-RCNN作為輔助頭部。我們不會使用太多不同的heads,例如6個不同的heads,以避免優化沖突。
Conflicts analysis
????????當將相同的空間坐標分配給不同的前景框或在不同的輔助頭部中作為背景時,會產生沖突,從而混淆檢測器的訓練。我們首先定義頭部Hi與頭部Hj之間的距離,以及Hi的平均距離來衡量優化沖突為:

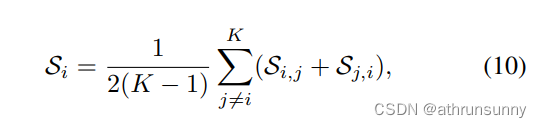
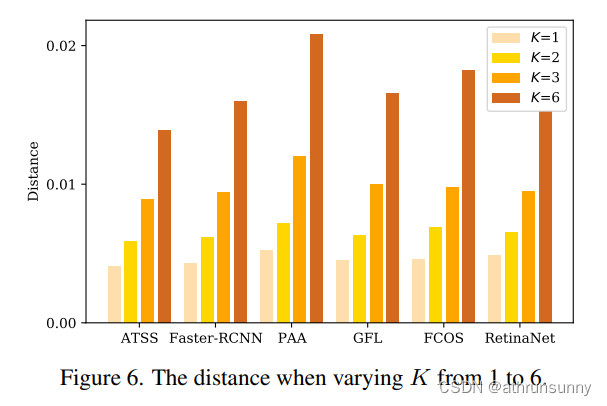
????????其中KL, D, I, C分別為KL散度、數據集、輸入圖像和class activation maps(CAM)。如圖6所示,當K > 1時,我們計算輔助頭之間的平均距離,當K = 1時,計算DETR head與單個輔助頭之間的距離。我們發現,當K = 1時,每個輔助頭的距離度量是不顯著的,這一觀察結果與我們在表8中的結果一致:當K = 1時,DETR head可以與任何頭協同改進。當K增加到2時,距離指標略有增加,我們的方法達到了最佳性能,如表7所示。當K從3到6增加時,距離激增,說明這些輔助頭之間存在嚴重的優化沖突導致性能下降。然而,6個不同頭部的ATSS基線達到49.5% AP,用6個不同頭部替代ATSS可降低到48.9% AP。因此,我們推測過多的不同的輔助頭像,例如超過3個不同的頭像,會加劇沖突。綜上所述,優化沖突受各種輔助頭的數量以及這些頭之間的關系的影響。
Should the added heads be different?
????????在作者的分析中,兩個ATSS頭(49.2% AP)的協同訓練仍然改善了一個ATSS頭(48.7% AP)的模型,因為ATSS是DETR頭的補充。此外,還引入了多種互補的輔助頭而不是與原始head相同,如Faster-RCNN,可以帶來更好的增益(49.5% AP)。請注意,這與上述結論并不矛盾;相反,由于沖突不顯著,我們可以在較少的不同heads(K≤2)下獲得最佳性能,但當使用許多不同heads(K > 3)時,將面臨嚴重的沖突。
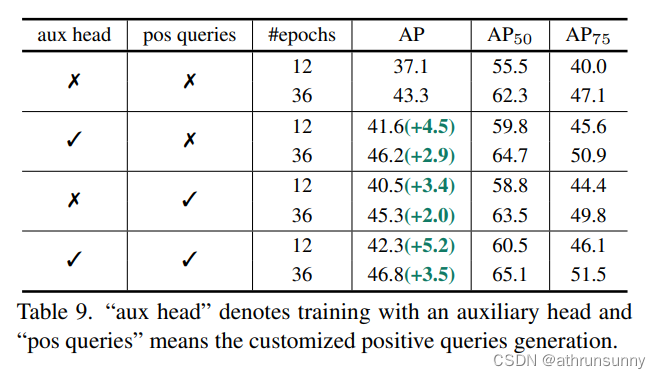
The effect of each component.
????????作者進行了成分消融,以徹底分析表9中每個成分的影響。由于密集的空間監督使編碼器特征更具鑒別力,因此結合輔助head產生顯著的增益。或者,引入自定義的正查詢也對最終結果有顯著貢獻,同時提高了一對一集合匹配的訓練效率。這兩種技術都可以加速收斂并提高性能。總之,作者觀察到整體改進源于編碼器更具鑒別性的特征和解碼器更有效的注意力學習。
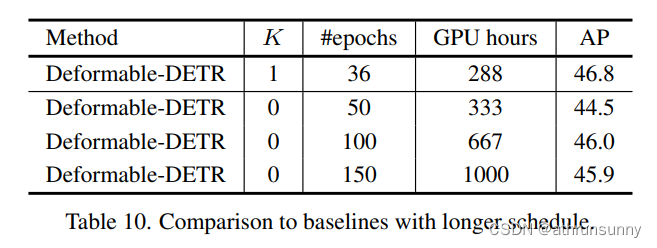
Comparisons to the longer training schedule
????????如表10所示,作者發現隨著性能飽和,長時間的訓練不能使deform - detr受益。相反,Co-DETR大大加快了收斂速度,提高了峰值性能。
Performance of auxiliary branches
????????令人驚訝的是,作者觀察到Co-DETR也為表11中的輔助頭帶來了一致的收益。這意味著我們的訓練范式有助于更多的判別編碼器表示,這提高了解碼器和輔助頭的性能。

Difference in distribution of original and customized positive queries
????????作者在圖7a中可視化了原始正查詢和自定義正查詢的位置。每張圖像只顯示一個對象(綠色框)。匈牙利匹配在解碼器中分配的正查詢用紅色標記。我們分別用藍色和橙色標記從Faster-RCNN和ATSS中提取的正查詢。這些自定義查詢分布在實例的中心區域,為檢測器提供足夠的監督信號。
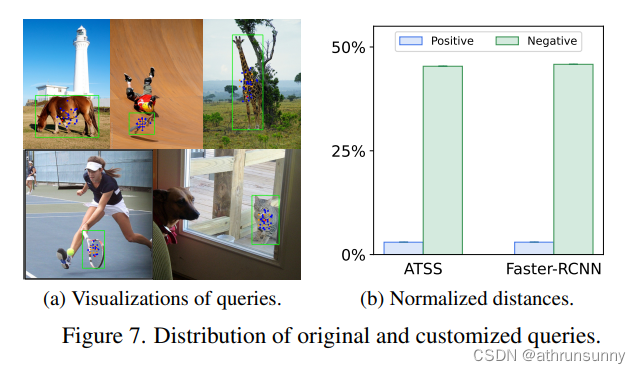
Does distribution difference lead to instability?
????????作者在圖7b中計算原始查詢和自定義查詢之間的平均距離。原始負查詢和自定義正查詢之間的平均距離明顯大于原始和自定義肯定查詢之間的距離。由于原始查詢和自定義查詢之間的分布差距很小,因此在訓練期間不會遇到不穩定性。
代碼的訓練配置用的是projects\configs\co_deformable_detr\co_deformable_detr_r50_1x_coco.py默認使用k=2,即ATSS+Faster-rcnn頭。







)
ATF MMU轉換表)







不接顯示器無法輸出VNC圖像解決辦法以及vnc安裝記錄)

)
