參考文獻:
[1] Vocoder (由助教許博竣同學講授)嗶哩嗶哩bilibili
[2] Oord A, Dieleman S, Zen H, et al. Wavenet: A generative model for raw audio[J]. arXiv preprint arXiv:1609.03499, 2016.
[3] https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
[4] Review: DilatedNet — Dilated Convolution (Semantic Segmentation) | by Sik-Ho Tsang | Towards Data Science
[5] Jin Z, Finkelstein A, Mysore G J, et al. FFTNet: A real-time speaker-dependent neural vocoder[C]//2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018: 2251-2255.
[6] Kalchbrenner N, Elsen E, Simonyan K, et al. Efficient neural audio synthesis[C]//International Conference on Machine Learning. PMLR, 2018: 2410-2419.
[7] Prenger R, Valle R, Catanzaro B. Waveglow: A flow-based generative network for speech synthesis[C]//ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 3617-3621.
[8] Flow-based Deep Generative Models | Lil'Log (lilianweng.github.io)
[9] 細水長flow之NICE:流模型的基本概念與實現 - 科學空間|Scientific Spaces (kexue.fm)
目錄
一、Introduction
Spectrogram 與 phase
Waveform Synthesis Methods
Vocoder 為什么獨立研究
二、Neural Vocoder——WaveNet
WaveNet 思路
WaveNet 架構
WaveNet Softmax Distribution
WaveNet Dilated Causal Convolution
WaveNet Residual and Skip Connections
Conditional WaveNet
WaveNet 總結
三、Neural Vocoder——FFTNet
FFTNet 架構
FFTNet 小技巧
FFTNet 總結
四、Neural Vocoder——WaveRNN
WaveRNN Dual Softmax Layer
WaveRNN 架構
WaveRNN 加速小技巧
WaveRNN 總結
五、Neural Vocoder——WaveGlow
Flow-Based Model
WaveGlow 架構
WaveGlow 總結
六、Vocoder Conclusion
一、Introduction
Vocoder:當涉及語音合成時,vocoder是一個重要的組成部分,它負責將數字化的語音信號轉換回可聽的聲音。Vocoder是“Voice Coder”的縮寫,它是一種處理語音信號的算法或設備,用于分析和合成聲音。它接收數字信號(通常是通過語音識別等手段得到的),并對其進行處理,使之變成人耳能夠理解的聲音信號。
-
首先我們大概講一下 Vocoder 是干什么的。之前說過,一般在模型中操作的都是聲譜 spectrogram,而 Vocoder 就是將 spectrogram 轉為我們可以聽的聲音信號的。
Spectrogram 與 phase
-
要搞懂 Vocoder,首先我們需要知道 Spectrogram 是怎么來的。已知我們有一段聲音信號 x,則有以下過程
-
STFT:“Short-Time Fourier Transform”(短時傅立葉變換)。它是一種信號處理技術,用于將信號從時域轉換到頻域。STFT 通過在時域上應用傅里葉變換的窗口,將信號分解為時間上局部化的頻譜信息。
-
t:時間
-
f:頻率
-
-
首先對聲音信號進行 STFT,得到一個關于時間和頻率的函數 X,由于完成傅里葉變換后得到的結果通常都是復數,因此可以表示為 Ae^iθ 的形式,其中 A 就是振幅(amplitude),θ 就是相位(phase)。不同時間,不同頻率都有自己的振幅和相位。而這里的 A 就是 Spectrogram。
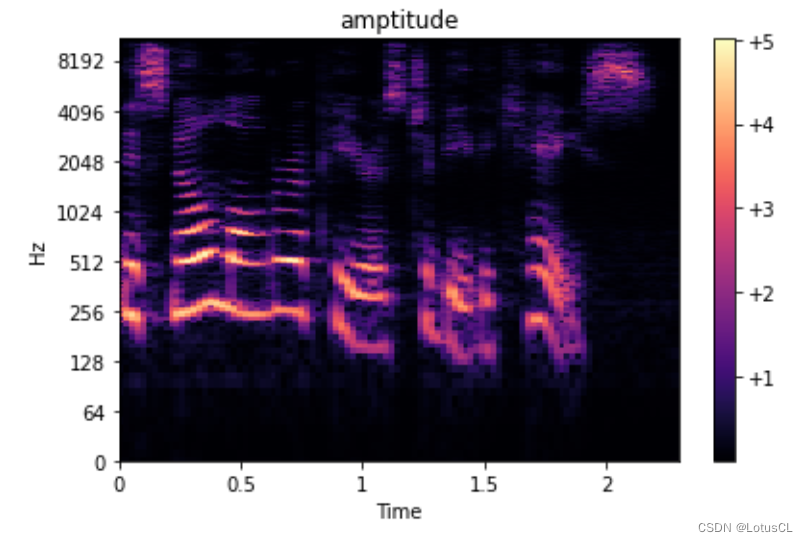
-
也就是說,Spectrogram 距離聲音信號還缺少相位的信息。奇怪了,那我們之前生成的時候為什么拋棄掉了相位的信息呢?我們將相位畫出,如圖,可以看出來,相位信息幾乎就相當于雜訊一般的存在。也就是說,無論是生成這個 phase,還是從 Spectrogram 中還原出 phase,都是非常困難的。
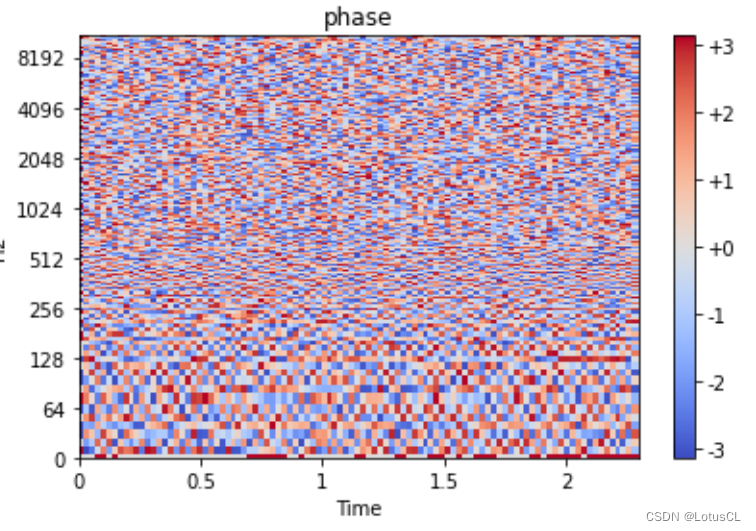
-
那問題就來了,phase 真的有這么重要嗎,是不是隨便給給就能合出比較好的聲音了呢?在視頻課程中,在隨便給了 phase 后,聲音就會變得非常奇怪,因此這個還是有點重要的,然而,phase 生成還是太難了。
Waveform Synthesis Methods
-
那不生成 phase,我們怎么合成出人類能聽的聲音信號,也就是波形(waveform)呢?我們決定使用模型生成出的聲音特征(acoustic features),由它通過 Vocoder 直接生成波形。
-
Traditional Methods:
-
Heuristic methods:Griffin-Lim algorithm
Griffin-Lim算法是一種啟發式方法,用于估計音頻信號的相位信息,從而實現從幅度譜(amplitude)重建時域波形(waveform)。這個算法特別適用于聲音合成或音頻重建的場景。這個算法的基本思想是:通過對幅度譜的估計和隨機初始化重建頻譜的相位,然后反轉這些估計的頻譜,再次應用STFT來獲得新的時域波形。然后重復這個過程,迭代多次,希望最終獲得合理的相位估計。不過它生成的語音聽起來還是不太自然。
-
-
Neural Vocoder:
-
Generative neural networks
遇事不決用神經網絡是這樣的(×),但是它生成出來的語音質量確實很好。
-
Directly generate waveform from acoustic features
-
Vocoder 為什么獨立研究
-
我們可能很好奇,為什么 Vocoder 要單獨拿來研究,而不是接在 TTS、VC 等模型后面直接做 End2End 訓練呢?因為 Vocoder 是將頻譜圖轉為波形的方式,只要生成的是頻譜圖,就可以使用 Vocoder,這使得其泛用性很高,而其他模型的生成目標就變成了生成頻譜圖,這會降低整個任務難度,使得它們能夠更加專注于聲音信號的處理。
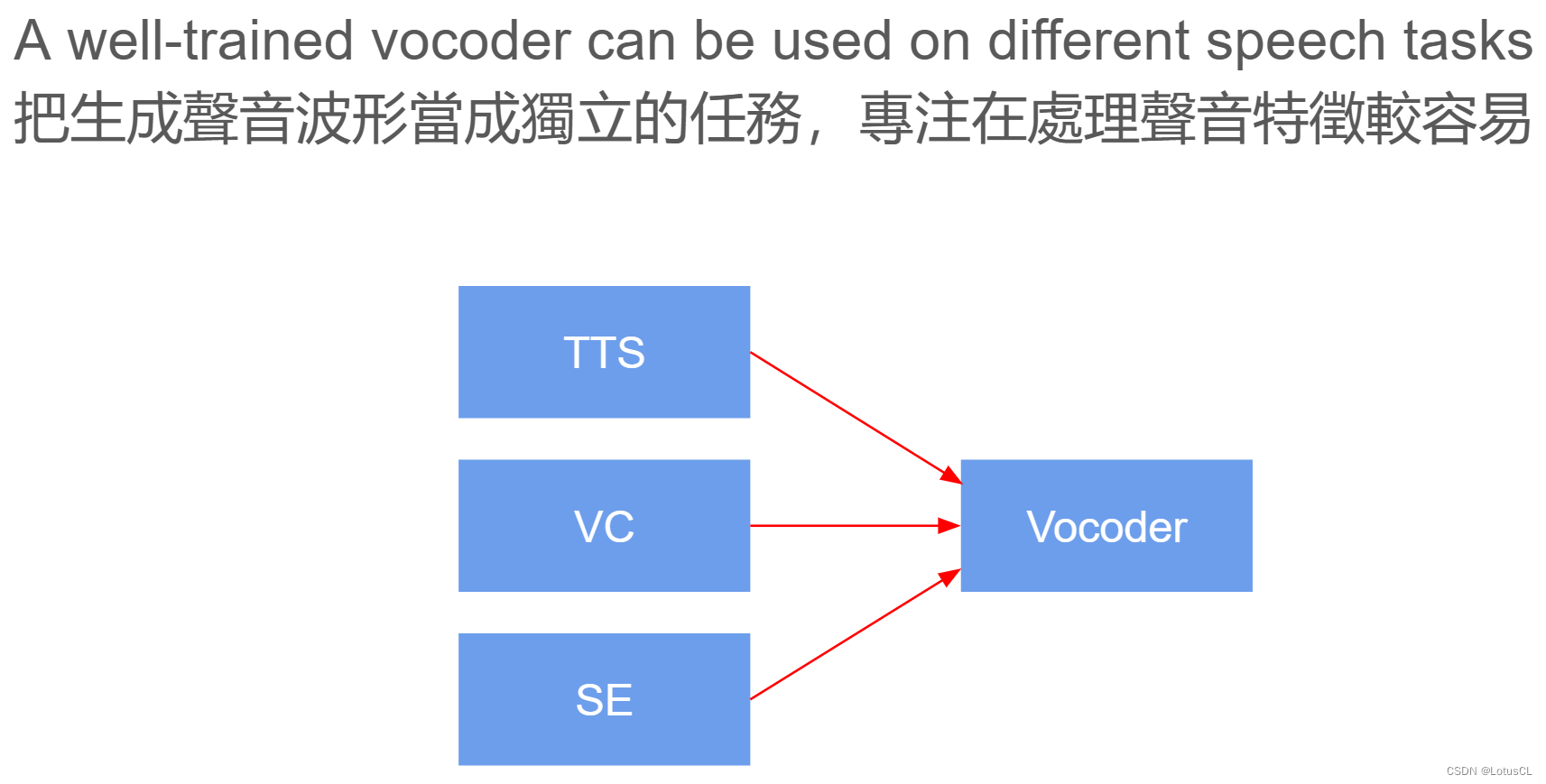
二、Neural Vocoder——WaveNet
WaveNet 思路
-
最早被提出生成波形的模型。其本質上就是一個自回歸模型(autoregressive model)。這是怎么來的?
-
我們可以把波形放大,其實我們發現其本質上就是一個個數值連接起來的。
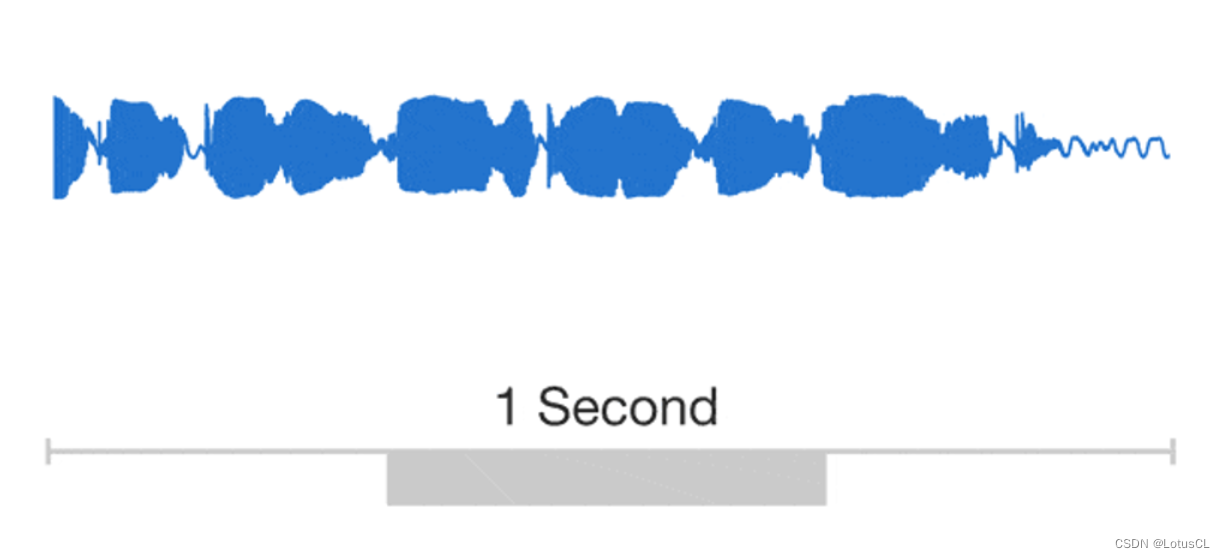
-
所以我們很自然的就能想到自回歸模型。想要知道 xt 的值,就需要將 x1~xt-1 的值拿出來當成輸入。而 WaveNet 就是這么做的。

-
一個值基于前面的值進行擴張卷積(Dilated Convolution),最終生成下一個值,然后生成的值又作為輸出,去生成下下個值。
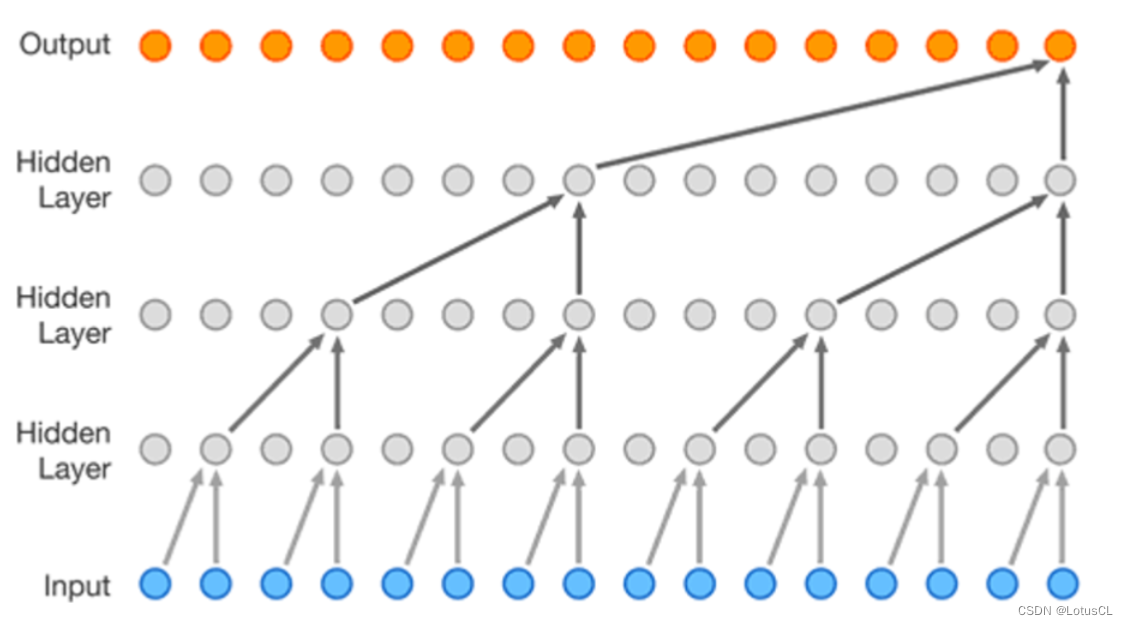
-
而 WaveNet 的主要構成成分就是因果卷積網絡(Causal Convolution Network)。馬上我們就細講。這里可以簡單了解一下。
Causal Convolution(因果卷積):是卷積神經網絡中的一種卷積操作,它具有一種“因果性”約束,即輸出中的每個元素只能依賴于輸入序列中其之前的元素。這種約束在處理時間序列數據時非常有用,因為它確保模型不會“未來”依賴于當前時間步之后的信息。
WaveNet 架構
Skip connections(跳躍連接):是指在神經網絡中將某一層的輸出直接連接到后續層的非相鄰層或更深層的輸入的技術。這種技術的主要目的是改善神經網絡的訓練效果、提高梯度傳播和模型學習能力。
-
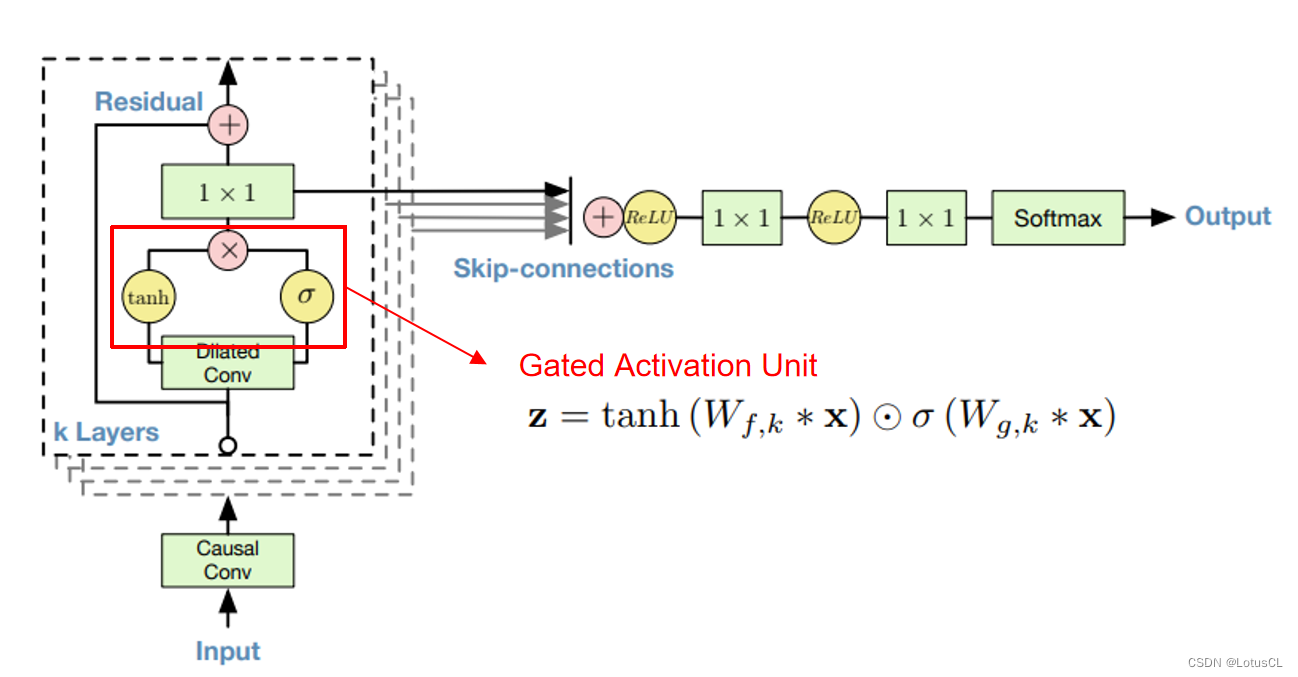
我們可以簡單了解一下 WaveNet 的主要架構。Input 就是所謂的 x1~xt-1,Output 就是 xt。輸入會率先進入因果卷積層(Casual Conv),然后進入擴張卷積層(Dilated Conv),經過不同的激活函數(activate function),將結果進行點乘,然后通過 1×1 的 CNN,之后和原來的結果相加(殘差學習,residual learning),這樣我們算作“一層”,這一層的輸出會傳到下一層中作為輸入,一共會有 k 層。
-
而每一層的 CNN 輸出又會被單獨拉出來相加(這樣的操作叫 Skip-connections),經過 ReLU、1×1 CNN、ReLU、1×1 CNN、Softmax,最終產生輸出。
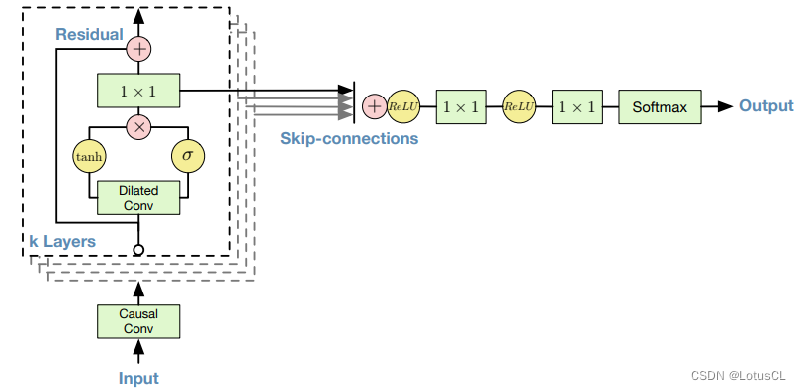
WaveNet Softmax Distribution
μ-law 編碼算法:主要用于音頻數據的壓縮和量化。μ-law(mu-law)是一種非線性編碼方式,通常用于將音頻信號進行壓縮,使其更適合于數字信號處理。它會將音頻信號進行非線性變換,將輸入信號的動態范圍縮小,并且使較小幅度的信號更容易表示,減少了對噪音的敏感程度。這種編碼方式能夠在保留音頻信號主要特征的同時,通過壓縮和量化來減小數據量。
-
對于 WaveNet,原來聲音信號是一系列數字的排列,這里會將其轉為獨熱向量(one-hot vector)后再作為輸入傳入網絡中。包括其輸出也將為 one-hot vector sequence。
-
而我們也可以將產生聲音信號的問題轉為以下式子:
?也即:給定 x1 到 xt-1,求取 xt 的概率分布。
-
而這也會導致一個問題。實際上,聲音信號在電腦中都是使用 16-bit 的整數來存儲的,這就意味著其范圍是 [-32768, 32767],如果使用這種格式來對模型進行訓練,那么問題就變成了一個有 65536 種類別的分類問題。類別太多,對模型來講學習過于困難,所以我們希望把這 65536 個類別壓縮成 256 個類別,也就是使用 8-bit 整數來表示聲音信號的數據。那我們可以直接使用 Linear Mapping 進行轉換嗎?
-
不,我們不這么做。我們會先將 [-32768, 32767] 的范圍線性壓縮成 [-1, 1],然后再通過一個名為 μ-law 的算法,算法公式如下:
? -
通過 μ-law 后范圍還是 [-1, 1],然后再將其拉回 [0, 255] 范圍中。整體的過程如下:
[-32768, 32767] (16-bit int) -> [-1, 1] -> [-1, 1] (μ-law) -> [0, 255] (8-bit int)
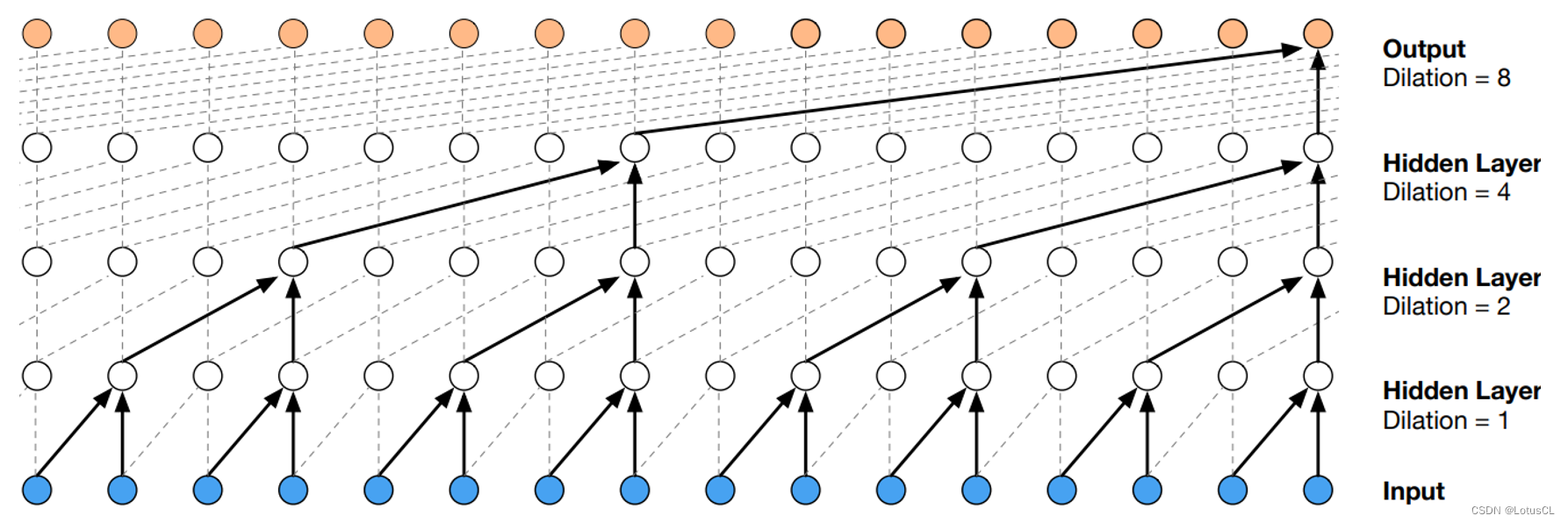
WaveNet Dilated Causal Convolution
-
我們之前說,WaveNet 主要組成成分是因果卷積網絡(Causal Convolution),具體是一個值基于前面的值進行擴張卷積(Dilated Convolution)。那么這些網絡名詞是什么意思呢?
-
因果卷積網絡,即具有一種“因果性”約束的卷積網絡,它的輸出 yt 只會看到輸入序列 xt 及之前的信息,而不會看到未來的信息。我們將其畫出,其最典型的特征就如下面的“直角三角形”圖案。
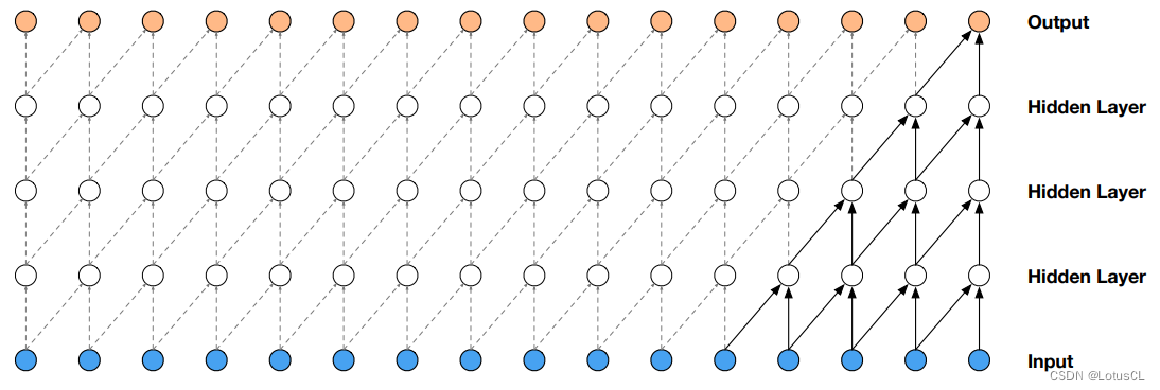
-
擴張卷積,它相對于普通的卷積有所不同。如下圖,普通卷積的卷積核是緊挨在一起的,而 Dilated Convolution 的卷積核則是分開布置的,因此做到了卷積視野的 “dilate”。
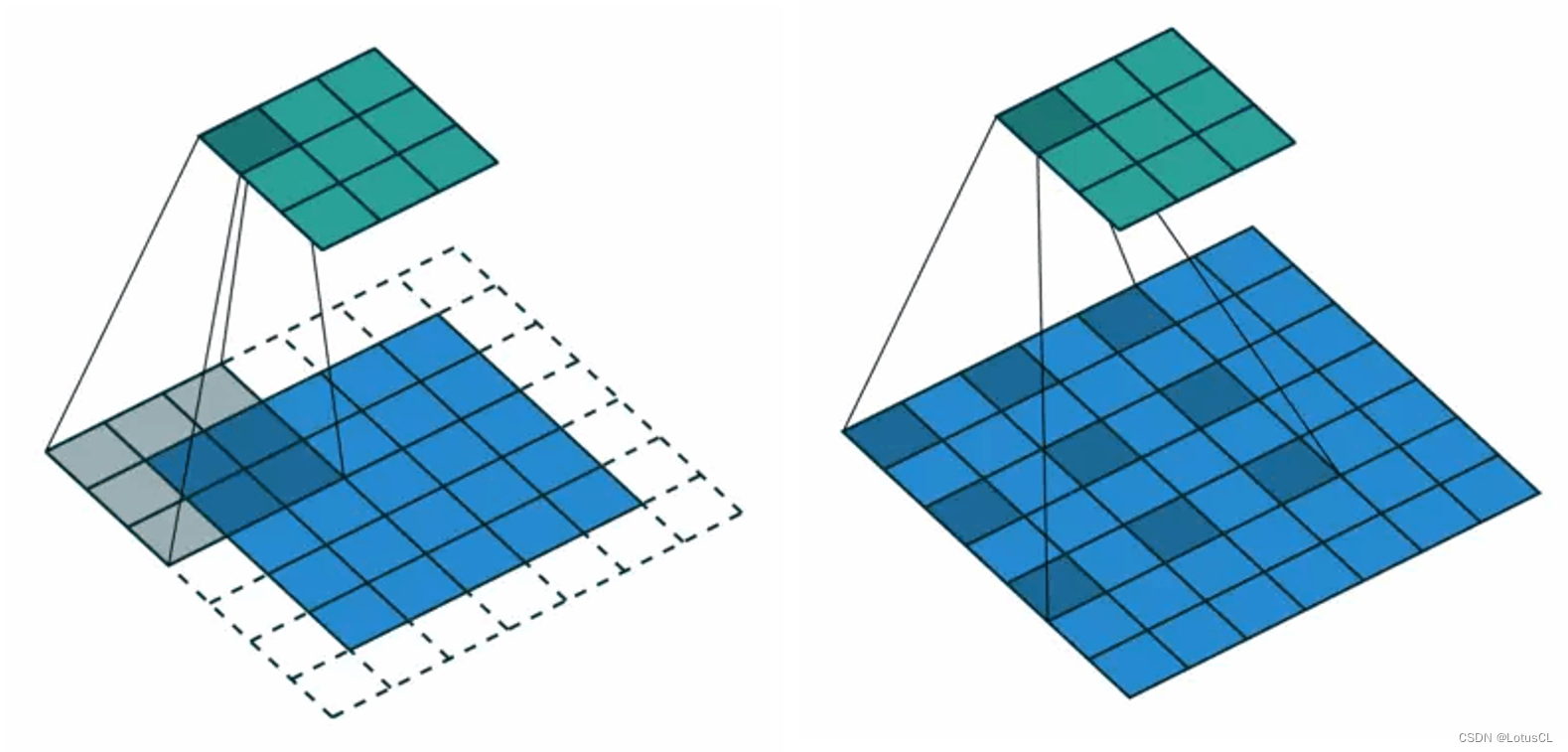
-
將這兩者的特性結合,我們就得到了 WaveNet 的 Dilated Causal Convolution。
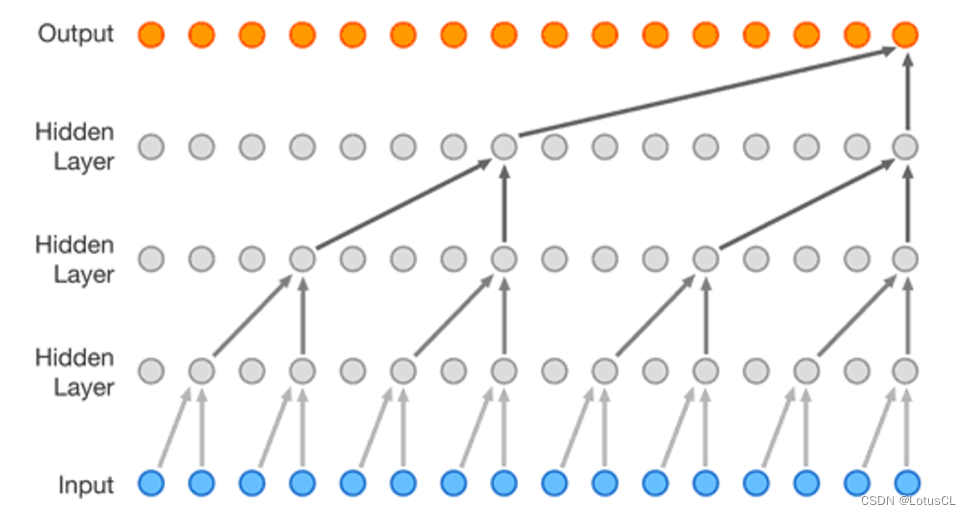
-
而擴張卷積最大的好處就是能夠指數級增加輸出的每一個值所能看到的視野。圖如下,如果采用的是普通的因果卷積,經過4層卷積后,輸出的一個值所能看到的只有輸入的5個值。但如果采用的是擴張因果卷積,同樣的深度下,輸出的一個值就能看到足足16個值,這極大提高了視野范圍。

WaveNet Residual and Skip Connections
-
剛剛我們講完了 WaveNet Softmax 操作以及 Dilated Causal Convolution,剩下還有一個結構,它是在每層中,將卷積后的結果通過不同的激活函數,然后再將各自的結果進行點乘。這樣的操作我們叫做 Gated Activation Unit。
-
其可以表達為以下公式:
?意思是通過了卷積后,經過 tanh 和 sigmoid 兩個激活函數,兩個結果再做點乘,變成最終的結果。
Conditional WaveNet
-
講到這里,我們好像還是沒有說到 Spectrogram?畢竟剛剛講述的 WaveNet 的輸入是前幾個 timesteps 的 輸出(x1, ... , xt-1),輸出則是 xt,那么 Spectrogram 是什么時候使用呢?其實就是放在了 Gated Activation Unit 那里。
-
我們將塞進來的隨時間變化的 Spectrogram 稱為 Local Condition,公式如下,使用 y 來表示 Spectrogram。還是和 x 一樣通過一個 CNN,和 x 加起來,再通過兩個激活函數,最終結果點乘。
? -
有 “Local Condition” 自然也就有 Global Condition。 這里指的就是我們對聲音添加的額外條件,比如使用誰的聲音,帶有怎樣的情緒,用什么樣子的說話方式等。這些條件將會作用于整個語音生成。條件可能是一個值,也可能是一個獨熱向量。不管怎樣,它們添加的方式都和上面是一樣的。公式表示如下:
?
WaveNet 總結
-
WaveNet 合成出來的音質還是非常好的,但由于是自回歸模型,而聲音信號中,一秒就有16000個值,也就是說使用 WaveNet 產生一秒的聲音就需要運算 16000 次,因此在生成時就會非常慢。而下面提到的模型其主要目的就是為了解決生成速度很慢的問題。
三、Neural Vocoder——FFTNet
FFTNet 和 WaveNet 一樣也是自回歸模型。不一樣的是,它將其中的深度 CNN 改成比較簡單的計算方式,這樣每次計算時的耗時就會少一些。此外,FFTNet 中還有一些訓練和合成上的技巧,只要是使用自回歸模型來生成語音的,這些技巧都可以加以應用來提高生成的語音質量。
FFTNet 架構
-
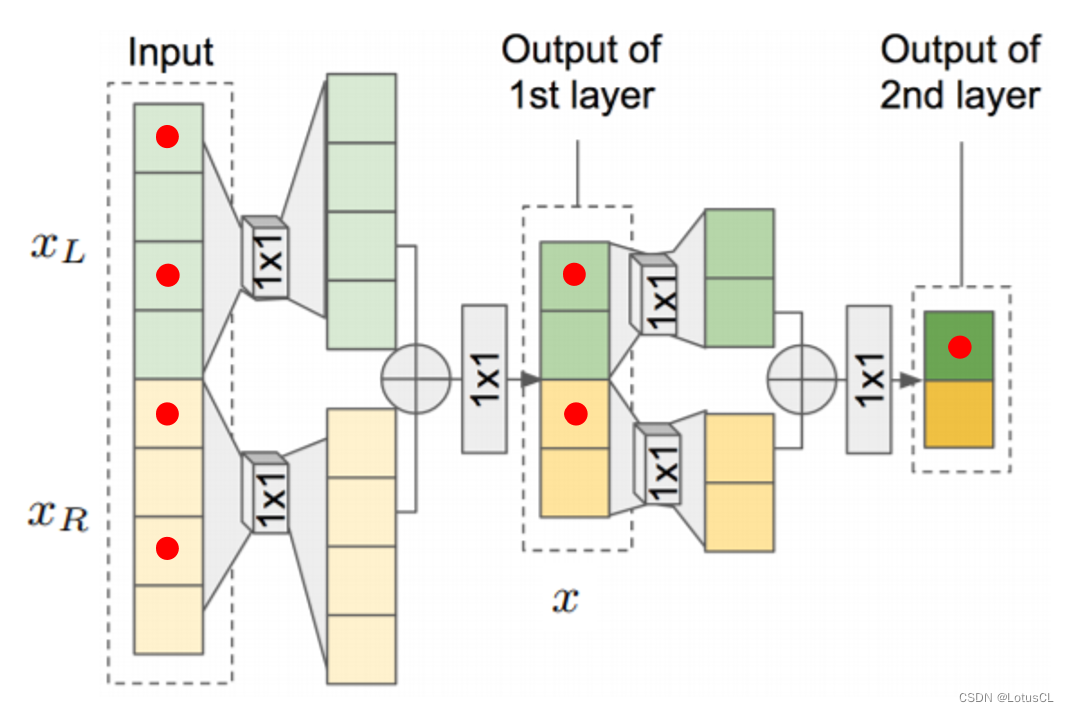
FFTNet 的輸入和輸出與 WaveNet 一樣,輸入就是所謂的 x1~xt-1,輸出就是 xt。輸入的數據首先會被切成兩段,分別為 xl 和 xr,通過不同的 CNN 再加起來得到 z,然后通過一個 ReLU,一個1×1 CNN,一個ReLU,得到新的 x,然后再進行和上面一樣的操作。因為相加的操作,每通過一層,輸入的數據大小就會減半,最后大小變成1的時候,這就是最終的輸出。

-
使用公式表達上面的過程就是:
? -
而 Spectrogram 加入也是和 WaveNet 類似的方式,是在生成 z 的步驟中加入的,我們用 h 代表 Spectrogram,使用公式表示加入的方式如下:
? -
這就是 FFTNet,架構非常簡單,而效果卻和 WaveNet 效果相似。為什么能達到如此優秀的效果?我們可以看下面的示意圖,生成最右邊的1個紅點,是需要往左推,知道上一層的2個紅點,再上一層是需要知道4個紅點,通過多層疊加,我們不難得知,最終輸出的視野將會非常大。
FFTNet 小技巧
-
Zero padding:
-
在輸入的聲音信號前加上一些0,會讓訓練變得更穩定。
-
-
Conditional sampling:
-
我們說過,WaveNet 的最終輸出實際上是一個分類問題,也就是說是從最后的分布(distribution)中選取概率最大的類別作為最終的輸出。而根據不同的情況,有時我們并不需要找概率最大的那個,而是根據分布去進行隨機采樣出最終的輸出。
-
-
Injected noise:
-
WaveNet 和 FFTNet 都是自回歸模型(autoregressive model),在訓練時都采用了 teacher forcing,使用真實的 x1-xt-1,希望輸出和答案的 xt 越接近越好。然而,在實際使用中,我們是使用模型上一步的輸出當成輸入的,也就意味著,如果上一步產生的答案并不是很好,這樣的誤差就會傳遞到下一步,最終導致整個模型垮掉。
-
所以我們可以在訓練的過程中,給輸入 x 增加一些高斯噪聲。這樣訓練出來的模型在推理生成聲音時會更加穩定。
-
-
Post-synthesis denoising
-
使用上面添加噪聲的方法進行訓練,最終生成的模型在投入使用時,產生的聲音信號會有點噪音,所以就采用了信號處理的方式來對生成的聲音信號進行去噪(后合成去噪)
-
FFTNet 總結
-
FFTNet 采用了更簡單的架構,可以以更快的速度生成和 WaveNet 幾乎一樣好的聲音信號。作者甚至在論文里說模型可以做到使用 CPU 的實時轉換(real time using CPU),也就是產生 1s 的聲音信號花不到 1s。
-
然而,大家實際上在使用的時候速度沒有辦法達到如作者所說的那么快的速度,但是還是比 WaveNet 快上不少。并且,在 FFTNet 中采用的那些小技巧對于自回歸模型來說都是非常有用的。
-
最后我們來看看各個模型的效果。這里采用的 MOS 就是我們之前提到的 mean opinion score,即通過找一群人,讓他們聽聲音,給分數一個 1-5 的分數,最終計算平均得分。帶 ”+“ 的就是訓練時采用小技巧的模型。可以看到 FFT 的評分還是沒有 WaveNet 高,不過兩個模型在采用小技巧后其頻分都突飛猛進了。

四、Neural Vocoder——WaveRNN
還是由谷歌提出的,一句話總結這個模型就是,之前都是使用 CNN 來處理時間序列的,這回我們使用 RNN。
WaveRNN Dual Softmax Layer
門控循環單元(Gated Recurrent Unit,GRU):GRU 是一種循環神經網絡(RNN)的變體,用于處理和建模時間序列數據,如語音信號。GRU 包含更新門(Update Gate)和重置門(Reset Gate),這兩個門的作用類似于 LSTM 中的輸入門和遺忘門,用于控制信息的流動和傳遞。
-
在談 WaveRNN 架構前,我們先了解一下 WaveRNN 的 Softmax 層。之前我們說,WaveNet 的 Softmax 層將 16-bit 的數據壓縮成 8-bit 數據再進行處理。而在 WaveRNN 中, Softmax 是將 16-bit 的數據拆成兩個 8-bit 的數據,兩個數據做兩次預測來達到 16-bit 的效果。
-
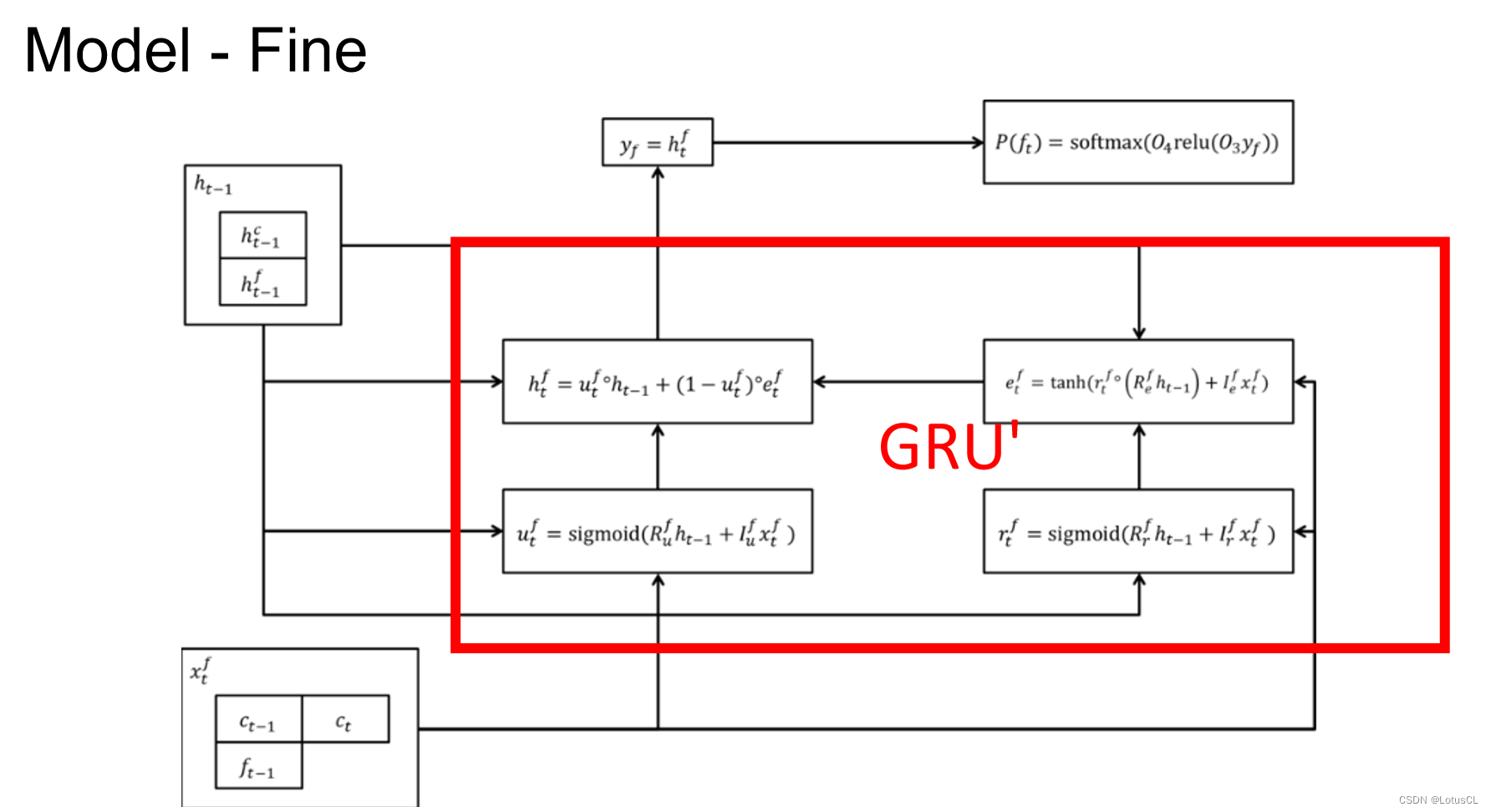
分成的兩個數據一個叫 Coarse,寫作 c_t,還有一個叫 Fine,寫作 f_t。

WaveRNN 架構
-
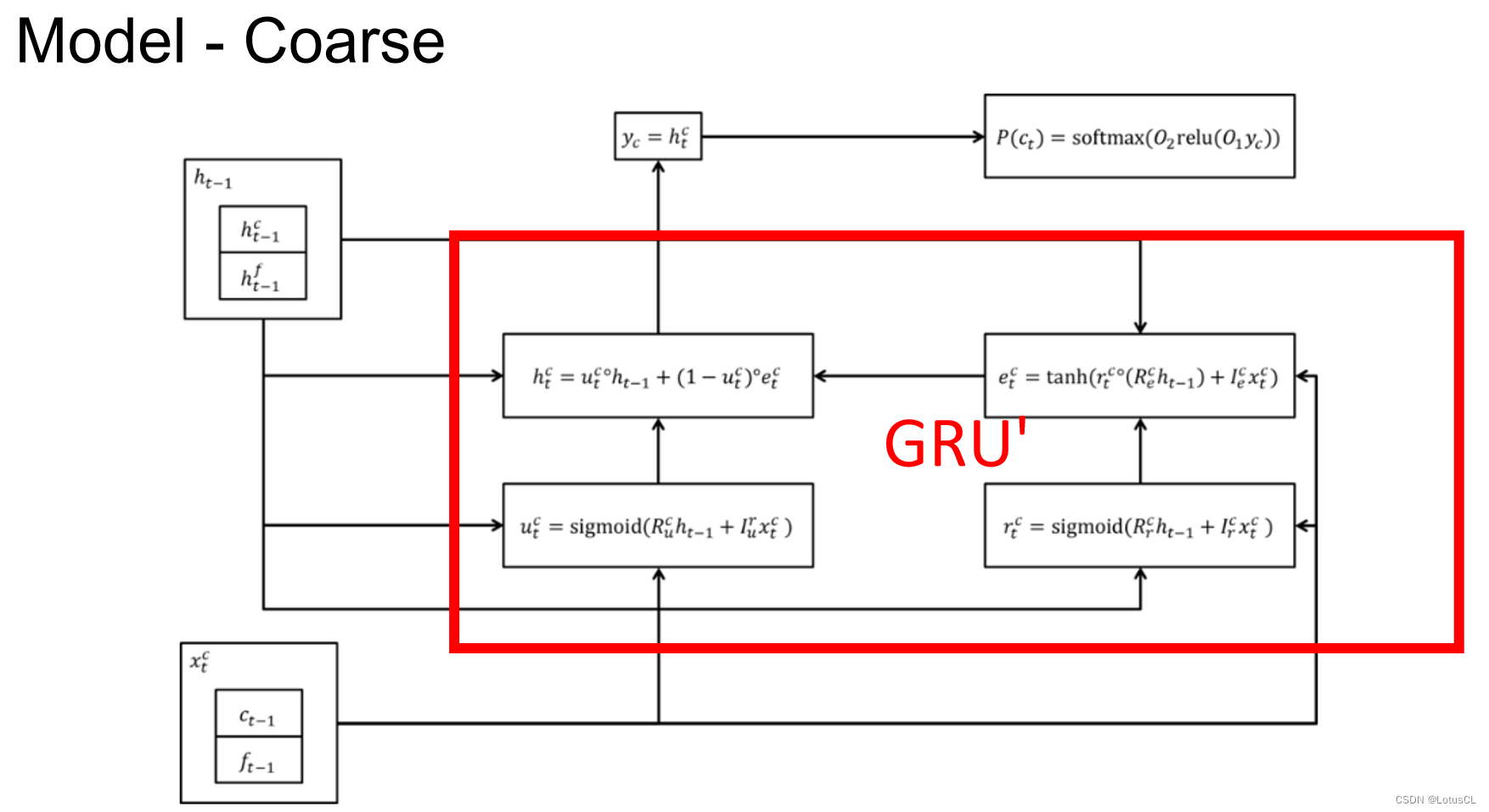
對于 Coarse 8-bit 的運算的結構圖如下,紅色方框里的四個單元可以理解為 GRU 運算。左下角 x_t^c 表示上一個時間的 16-bit 數據,即 x_t-1 的結果,左上角則是上一個時間的 hidden stat,輸出則是當前時間的 hidden state y_c,通過兩層的 linear transform,然后再進行 softmax 就可以得到 Coarse 8-bit,也就是最終的結果。
-
Fine 8-bit 和 Coarse 8-bit 其實差不多,用了另一個 GRU 來處理,唯一不同的就是我們不僅會將上一個 16-bit 數據拿來做 Input,同時也會將這一次產生的 Coarse 8-bit c_t 拿來做 Input。
-
遺憾的是,原論文中也只有上面這些圖,沒有詳細說明模型部署方式。網上關于 WaveRNN 的部署方式有很多,可以自己查詢了解,這里不再贅述。
WaveRNN 加速小技巧
在 WaveRNN 中還提到了一些能夠讓模型再加速的方法。論文中說,采用了下面技巧的 WaveRNN,就可以在手機的 CPU 上實現 Real-time 的運算。
-
Sparse WaveRNN
-
即 Weight Pruning(權重修剪),將一些比較小的權重值設為0,減少運算時候的消耗。
-
-
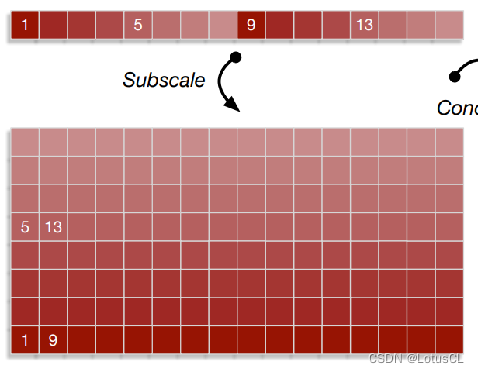
Subscale WaveRNN
-
原來我們是從1、2、3、……這樣生成下去的,而在此變種中,我們將生成的序列進行折疊,依次生成 1、9、17、……,其他部分也是如此,如依次生成5、13、21、……,這樣8個部分可以同時進行運算,那么整體速度就可以快8倍。
-
WaveRNN 總結
-
很簡單,但是很強大。
五、Neural Vocoder——WaveGlow
實際上,語音生成速度之所以慢,本質上還是因為采用的是自回歸模型。有人就想,如果不用自回歸模型來生成語音信號會怎么樣?WaveGlow 隨之誕生。
Flow-Based Model
-
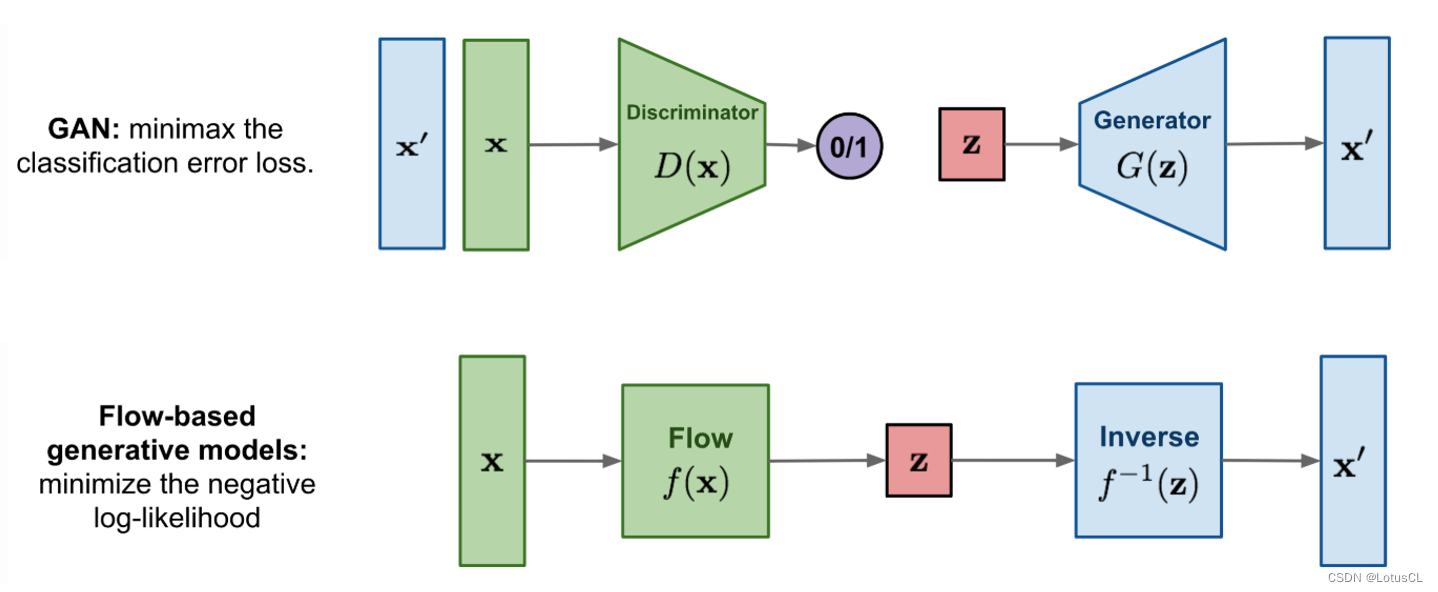
在了解 WaveGlow 模型前,我們先來了解一下 Flow-Based Model。相比于 GAN 中有兩個模型,生成器需要去騙過判別器,Flow-Based Model 只有一個模型 Flow,也就是圖中的 f(x)。模型將會接收真實數據的輸入,將數據映射到高緯度類噪聲 z 中,這相當于一個概率分布。與此同時,作為 transform 的 f(x) 還是可逆的,也就是可以使用 z 作為輸入,從中采樣出我們所需要的聲音信號。
-
從數學的角度來解釋就是下面這樣:
? -
這里的 z 就是平均值為 0,標準差為 1 的高斯分布。 因此我們可以寫出它的概率密度函數(Probability Density Function,PDF)q。其實就是高斯分布的 PDF,將某一個 z 丟到其中,就可以告訴我們其出現的概率有多大。公式如下:
? -
在訓練中,因為是將 x 映射到高斯分布上,所以如果變換函數 f 訓練得很好的話,那么它就可以將原始數據 x 映射到一個空間,在這個空間中數據點更符合高斯分布的特性。放到數學中就是 x 丟到高斯分布 PDF 中,得到的數值應該會很大。那么 q(x) 應該如何計算呢?我們將上面兩個公式結合起來,就得到了下面的式子:
? -
這里對 z 進行了一次變量替換,在概率中我們學過(悲,沒學過),變量替換不能簡單換了就行了,后面還需要加上雅可比行列式(Jacobian Determinant)的絕對值。
彈幕解釋:一個是以z的元素為坐標的空間,一個是在以x的元素為坐標的空間,所以要有jacobian
-
對 q(x) 取 log,這就是我們訓練的目標函數:數值越大越好。公式如下。此外,我們設計的變換函數 f 需要滿足兩個條件:很容易可逆、其雅可比行列式很容易計算。
? -
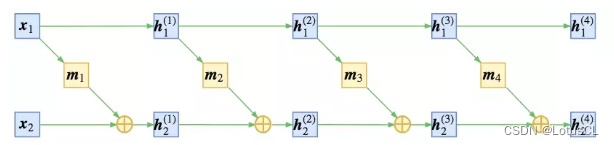
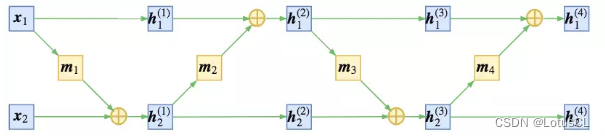
那么我們應該如何設計函數 f 呢?我們可以將 x 拆成 x_1 和 x_2,中間結果我們定義為 h,同時我們也將 h 拆成兩類結果,為 h_1 和 h_2,則第一層的兩個結果我們就寫作 h_1^(1) 和 h_2^(1),則有:
? -
其中,m 表示某種運算。所以以第一層舉例,當我們有中間結果h_1^(1) 和 h_2^(1) 時,如果想進行反推,則有:
? -
所以原始數據 x 經過上面這些變換后,最終生成的數據就是 z。而中間所有的變換加起來,就是我們的 f。

-
將上述過程繪制成圖更方便理解,大概是下面這個樣子:
-
當然,你也可以稍微改一下順序,變成這樣:
-
無論是上面的,還是下面的,整體運算都是可逆的。
WaveGlow 架構
-
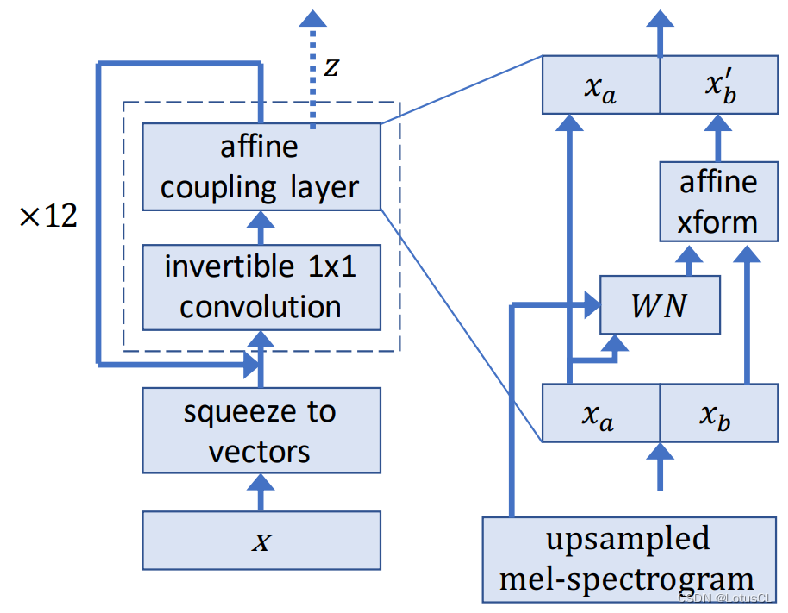
下圖是 WaveGlow 的架構圖。中間使用虛線框起來的模塊就是變換函數 f。我們可以給定 x 輸出結果 z,我們也可以提供 z 來生成語音 x。
-
從輸入開始講,x 首先通過 squeeze to vectors 變為向量,然后再進入一個 1×1 Conv,然后再進入 affine coupling layer,這就是我們之前提過的那一堆運算,這樣的操作在 WaveGlow 中一共會進行12次,每次都被視為一層。
-
我們將 affine coupling layer 放大來看(圖在右側),輸入首先被切割為 x_a 和 x_b,左邊的會直接保留作為輸出,并且還會丟給一個模塊 WN 做運算,算出來的結果會和 x_b 相加變成輸出 x_b‘。 值得一提的是,對 x_a 進行運算的模塊就是 WaveNet(WN),這也是 WaveGlow 的名字來源。所以同樣的,Spectrogram 自然也可以通過 WN 來接入模型中。
-
而對于 squeeze to vectors 操作,假設我們輸入的是 1s 的數據,也就是 16000 個點,我們會將其變換成形狀為 (8, 2000) 的向量。其中原因是如果我們不進行形狀的變換,在拆分輸入數據時,我們就會拆成兩個 8000 的,這樣對于運算來說很不方便,左右兩邊的計算時間會相差非常大。而在變換后,我們就可以將其拆分為兩個 (4, 2000) 的。

WaveGlow 總結
-
在使用 WaveGlow 時,我們的輸入是一整段聲音,所以它的生成速度要比自回歸模型要快得很多很多。
-
然而,這樣的模型也有一個很大的缺點,那就是非常難訓練。當初論文中說用了 8 張 Nvidia GV100 GPU 來進行訓練,這個在當時一張要賣 35w。
六、Vocoder Conclusion
-
質量方面:WaveNet > others
-
訓練時間方面:WaveRNN >= WaveNet >= FFTNet >> WaveGlow
-
生成速度方面:
-
實時標準:16kHz,即每秒需能運算 16000 次。
-
WaveGlow (520kHz) >> Real-time > WaveRNN >= FFTNet >> WaveNet (0.11kHz)
-
傳統高度優化的 Griffin-Lim 算法:507kHz
-
-
而 Neural Vocoders 的現狀就是要么生成速度很慢,要么很難訓練。而且還需要高度的優化才能有非常好的結果。
-
因此目前的研究目標就是做一個生成速度快、質量高,并且容易訓練的 Vocoder。








)


)

)
設計_升級版)




