向量數據庫選擇哪種近似搜索算法,選擇合適的集群規模以及集群設置調優對于知識庫的讀寫性能也十分關鍵,主要需要考慮以下幾個方面:
向量數據庫算法選擇
在 OpenSearch 里,提供了兩種 k-NN 的算法:HNSW (Hierarchical Navigable Small World) 和 IVF ?(Inverted File) 。
在選擇 k-NN 搜索算法時,需要考慮多個因素。如果內存不是限制因素,建議優先考慮使用 HNSW 算法,因為 HNSW 算法可以同時保證 latency 和 recall。如果內存使用量需要控制,可以考慮使用 IVF 算法,它可以在保持類似 HNSW 的查詢速度和質量的同時,減少內存使用量。但是,如果內存是較大的限制因素,可以考慮為 HNSW 或 IVF 算法添加 PQ 編碼,以進一步減少內存使用量。需要注意的是,添加 PQ 編碼可能會降低準確率。因此,在選擇算法和優化方法時,需要綜合考慮多個因素,以滿足具體的應用需求。
向量數據庫集群規模預估
選定了算法后,我們就可以根據公式,計算所需的內存進而推導出 k-NN 集群大小, 以 HNSW 算法為例:
占用內存 = ?1.1 * (4*d + 8*m) * num_vectors * (number_of_replicas + 1)
其中 d:vector 的維度,比如 768;m:控制層每個節點的連接數;num_vectors:索引中的向量 doc 數
向量數據庫批量注入優化
在向知識向量數據庫中注入大量數據時,我們需要關注一些關鍵的性能優化,以下是一些主要的優化策略:
Disable refresh interval
在首次攝入大量數據時,為了避免生成較多的小型 segment,我們可以增大刷新的間隔,或者直接在攝入階段關閉 refresh_interval(設置成 -1)。等到數據加載結束后,再重新啟用 refresh_interval。

Disable Replicas
同樣,在向量數據庫首次加載大量數據時,我們可以暫時禁用 replica 以提升攝入速度。需要注意的是,這樣做可能會帶來向量數據庫丟失數據的風險,因此,在向量數據庫數據加載結束后,我們需要再次啟用 replica。

增加 indexing 線程
處理 knn 的線程由 knn.algo_param.index_thread_qty 指定,默認為 1。如果你的設備有足夠的 CPU 資源,可以嘗試調高這個參數,會加快 k-NN 索引的構建速度。但是,這可能會增加 CPU 的壓力,因此,建議先按節點 vcore 的一半進行配置,并觀察 cpu 負載情況。

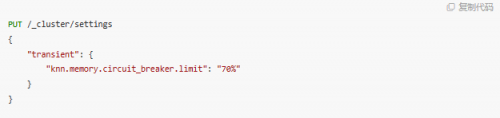
增加 knn 內存占比
knn.memory.circuit_breaker.limit 是一個關于內存使用的參數,默認值為 50%。如果需要,我們可以將其改成 70%。以這個默認值為例,如果一臺機器有 100GB 的內存,由于程序尋址的限制,一般最多分配 JVM 的堆內存為 32GB,則 k-NN 插件會使用剩余的 68GB 中的一半,即 34GB 作為 k-NN 的索引緩存。如果內存使用超過這個值,k-NN 將會刪除最近使用最少的向量。該參數在集群規模不變的情況下,提高 k-NN 的緩存命中率,有助于降低成本并提高檢索效率。
本文對于向量數據庫知識庫構建部分展開了初步的討論,基于實踐經驗對于知識庫構建中的一些文檔拆分方法,向量模型選擇,向量數據庫調優等一些主要步驟分享了一些心得,但相對來說比較抽象,如果你對此感興趣,可以期待下一篇。
設計_升級版)








簡單隊列)









