近日,微軟研究和清華大學的研究人員共同提出了一種名為“Skeleton-of-Thought(SoT)”的全新人工智能方法,旨在解決大型語言模型(LLMs)生成速度較慢的問題。
盡管像GPT-4和LLaMA等LLMs在技術領域產生了深遠影響,但其處理速度的不足一直是一個制約因素,特別是在對延遲敏感的應用中,如聊天機器人、協同駕駛和工業控制器。SoT方法與傳統的性能提升方法不同,它不對LLMs進行復雜的修改,而是將其視為黑匣子,并側重于優化輸出內容的組織結構。
項目地址:https://github.com/imagination-research/sot/
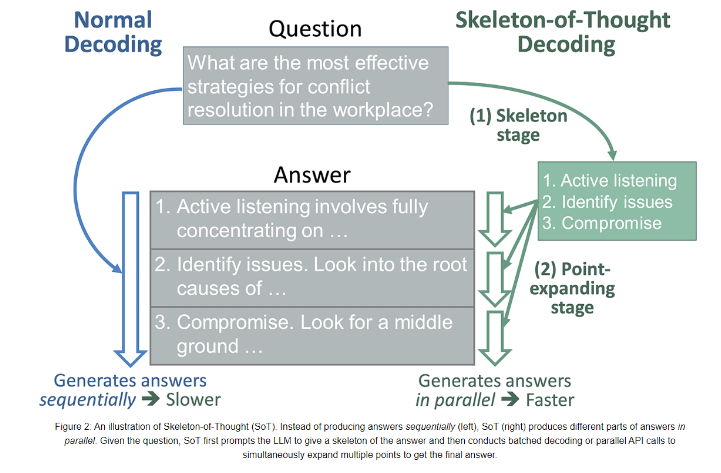
SoT引入了一個獨特的兩階段過程,首先引導LLM構建答案的骨架,然后在第二階段使LLM同時擴展骨架中的多個要點。這一方法不僅提高了LLMs的響應速度,還在不需要對模型架構進行復雜調整的情況下實現了這一目標。
為了評估SoT的有效性,研究團隊對12個不同領域的模型進行了廣泛測試,使用了Vicuna-80數據集,其中包含了來自編碼、數學、寫作和角色扮演等各個領域的問題。
通過使用FastChat和LLMZoo的度量標準,研究團隊觀察到SoT在八個模型上實現了1.13x到2.39x的速度提升,而且這些提升并沒有犧牲答案質量。這表明SoT不僅可以顯著提高響應速度,還能夠在各種問題類別中保持或提升答案質量。
因此,SoT方法為解決LLMs速度較慢的問題提供了一種有前景的解決方案。研究團隊的創新方法將LLMs視為黑匣子,并專注于數據級別的效率優化,為加速內容生成提供了新的視角。通過引導LLMs構建答案的骨架,然后進行并行擴展,SoT有效地提高了響應速度,為人工智能領域的動態思維過程開辟了新的探索方向,鼓勵向更高效、更多才多藝的語言模型發展。












)


![[Linux] 馮諾依曼體系結構 與 操作系統](http://pic.xiahunao.cn/[Linux] 馮諾依曼體系結構 與 操作系統)
)

)
真題解析#中國電子學會#全國青少年軟件編程等級考試)