什么是RDMA
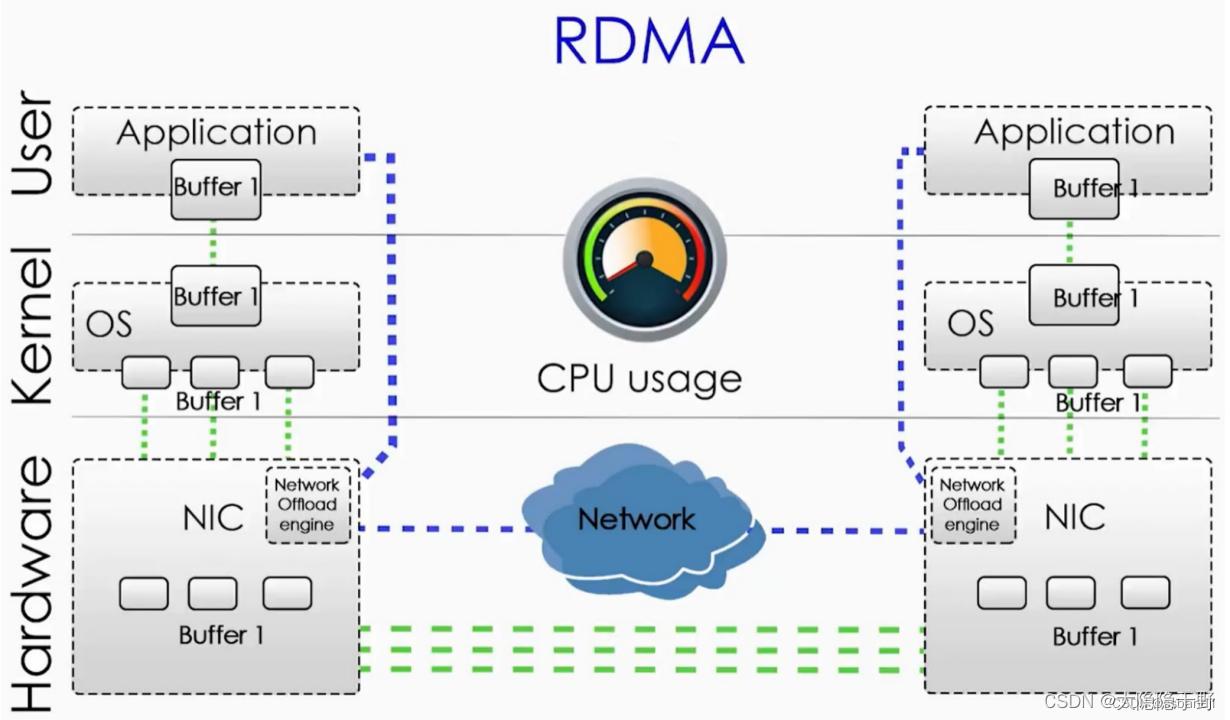
RDMA(Remote Direct Memory Access)遠程直接內存訪問是一種技術,它使兩臺聯網的計算機能夠在主內存中交換數據,而無需依賴任何一臺計算機的處理器、緩存或操作系統。與基于本地的直接內存訪問 ( DMA ) 一樣,RDMA 提高了吞吐量和性能,因為它可以釋放資源(如cpu),從而加快數據傳輸速率并降低延遲。在大規模并行計算機集群中特別有用,比如分布式存儲,超算中心。
RDMA 通過網絡適配器能夠將數據從線路直接傳輸到應用程序內存或從應用程序內存直接傳輸到線路,支持零拷貝,無需在應用程序內存和操作系統中的數據緩沖區之間復制數據。 不需要 CPU、緩存或上下文切換完,并且數據傳輸與其他系統操作并行,減少了消息傳輸的延遲。
Remote Direct Memory Access遠程直接內存訪問是一種技術,它使兩臺聯網的計算機能夠在主內存中交換數據,而無需依賴任何一臺計算機的處理器、緩存或操作系統。與基于本地的直接內存訪問 ( DMA ) 一樣,RDMA 提高了吞吐量和性能,因為它可以釋放資源(如cpu),從而加快數據傳輸速率并降低延遲。RDMA 可以使網絡和存儲應用程序都受益
概念
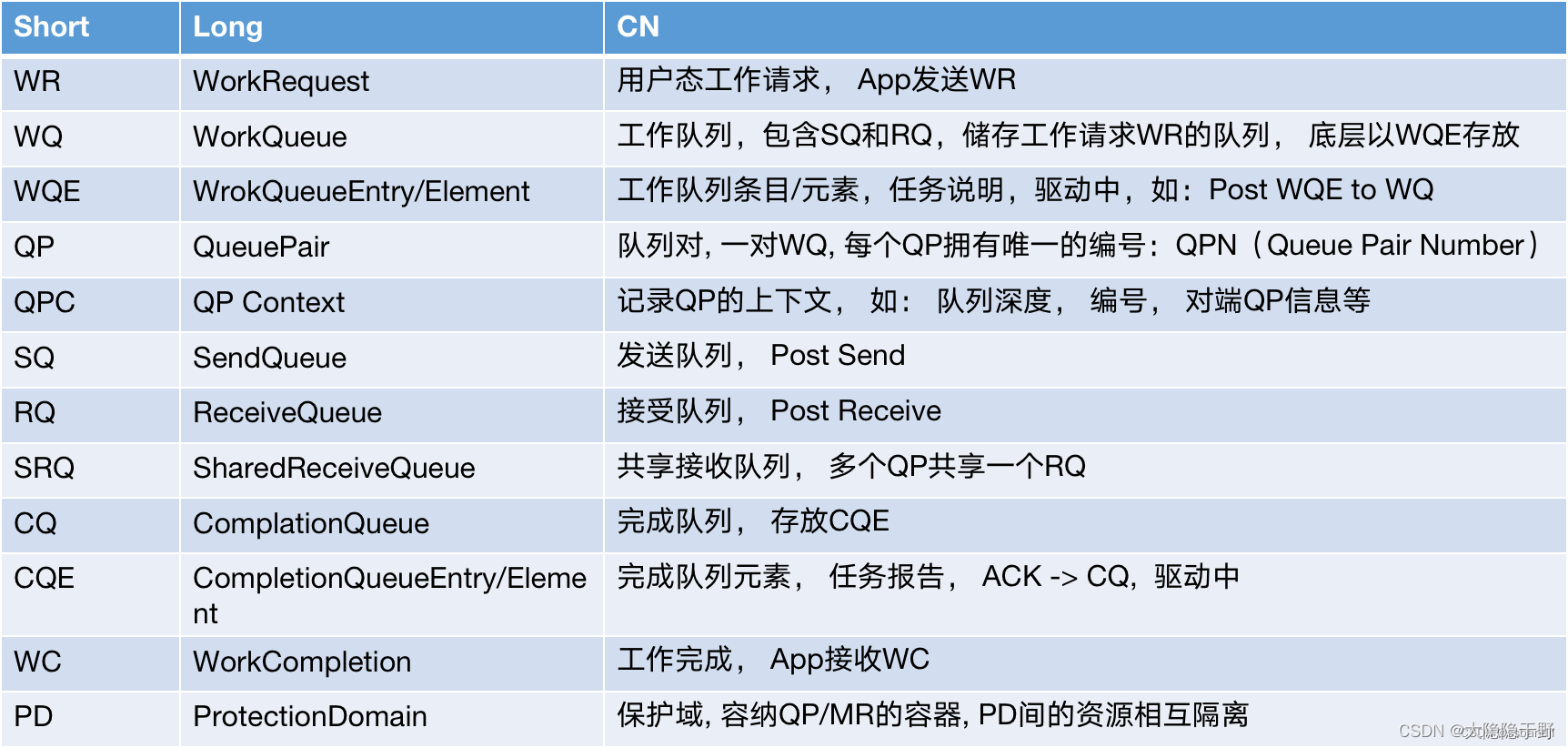
Fabric: 支持RDMA的局域網(LAN)
CA(Channel Adapter): 通道適配器, 將系統連接到Fabric的硬件組件, 本質是生產和消費包(packet)
HCA: Host Channel Adapter 主機通道適配器, 支持verbs接口的CA, 作用同上, ib協議對其定義為處理器和I/O單元中能夠產生和消耗數據包的IB設備
Verbs: 訪問RDMA硬件的“一組標準動作”。 每一個Verb可以理解為一個Function
RoCE: RDMA over Converged Ethernet (RoCE) protocol: rdma融合以太網協議
zero-copy networking: 零拷貝網絡
bypass the kernel networking stack: 內核旁路(繞過內核)
high-performance computing (HPC): 高性能計算
Memory Registration(MR) : 內存注冊后, 操作系統不能對數據所在的內存進行頁置換(page out)操作 – 物理地址和虛擬地址的映射必須是固定不變的, 底層調用內核提供的函數pin住內存(防止換頁)
va -> pa
protect
pin: lock page(va<=>pa)
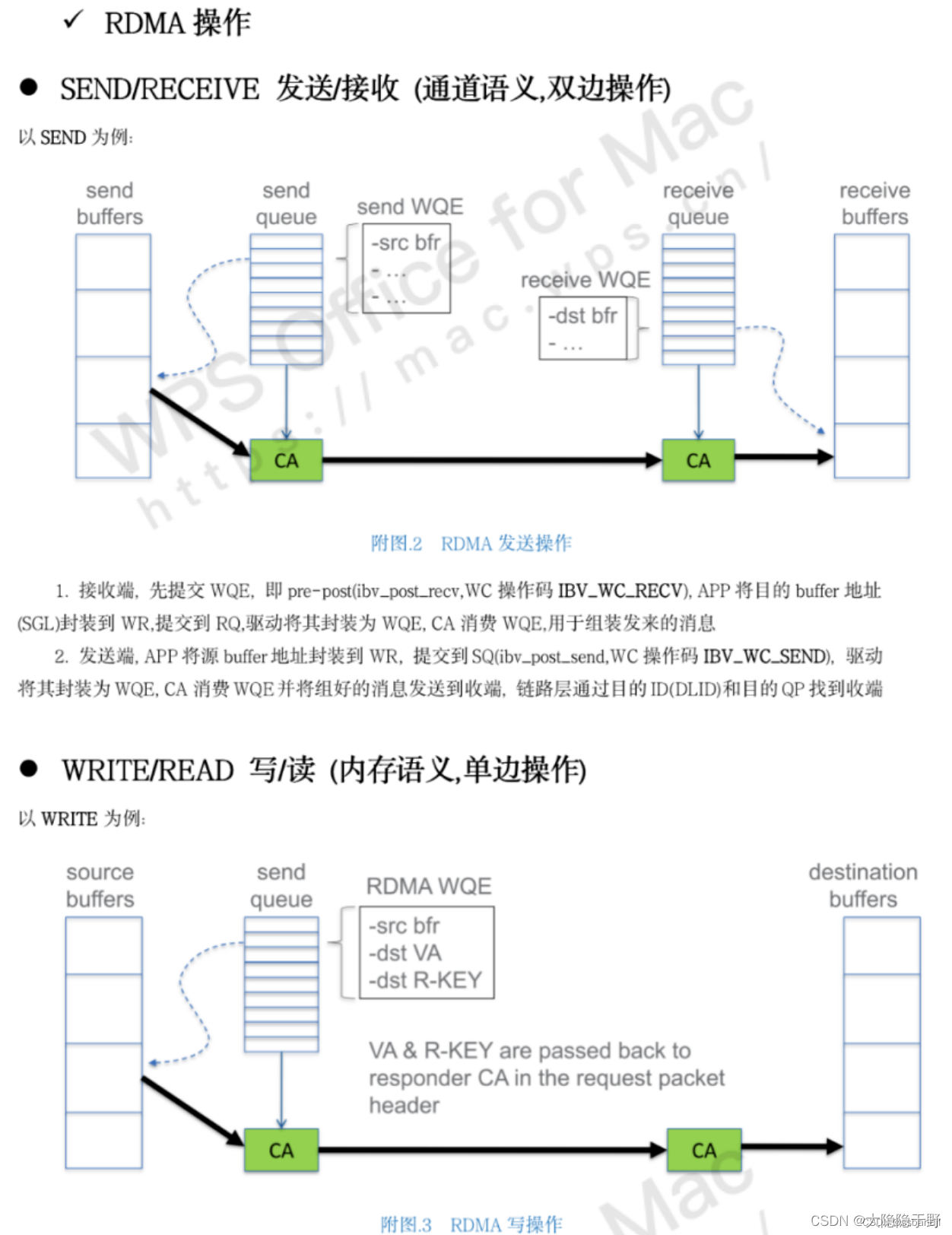
服務類型(隊列對qp類型):連接(可靠RC/不可靠UC), 數據報(可靠RD/不可靠UD)
RDMA術語

優點
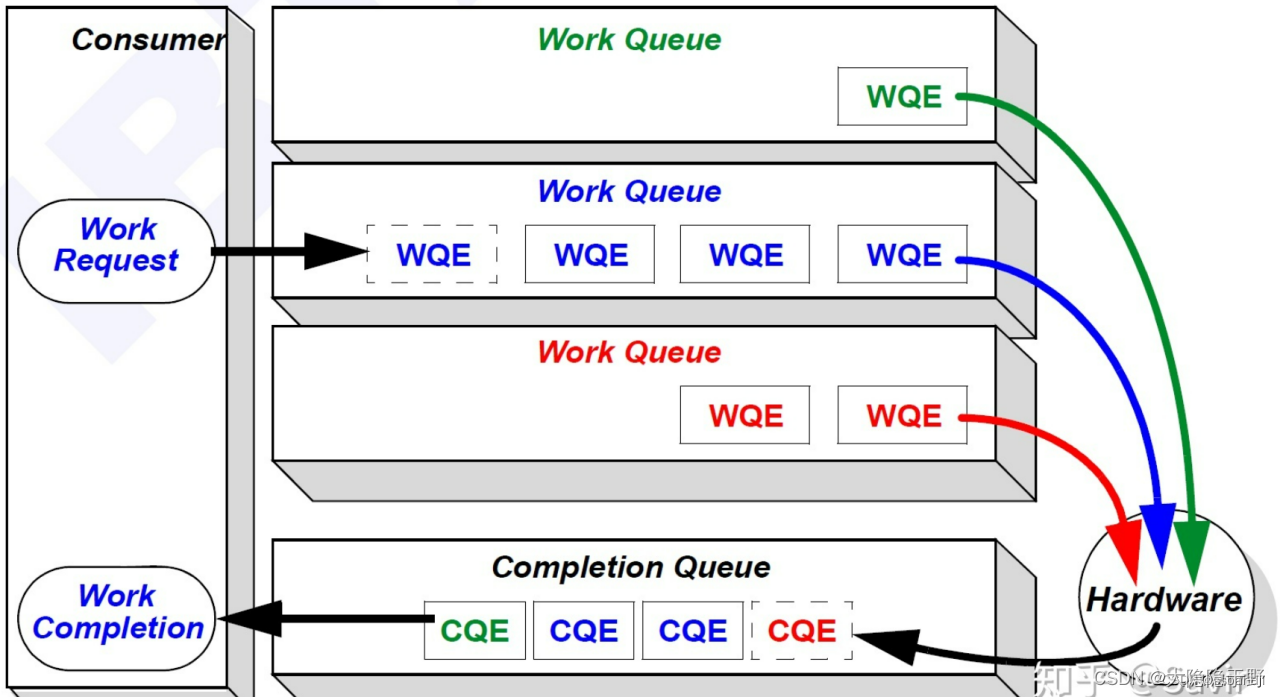
Zero-copy零拷貝-應用程序可以在不涉及網絡軟件堆棧的情況下執行數據傳輸,并且數據被直接發送到緩沖區,而無需在網絡層之間復制。
Kernel bypass繞過內核 - 應用程序可以直接從用戶空間執行數據傳輸,而無需執行上下文切換。
CPU Offload 卸載 - 應用程序可以訪問遠程內存而不消耗遠程機器中的任何 CPU。無需遠程進程(或處理器)的任何干預。遠程 CPU 中的緩存也不會被傳輸過程中的內存內容填充。
Message based transactions 基于事務的消息 - 數據作為離散消息而不是作為流處理,這消除了應用程序將流分離為不同消息/事務的需要。
Scatter/gather entries 分散/聚集條目支持 - RDMA 支持本地處理多個分散/聚集條目,即讀取多個內存緩沖區并將它們作為一個流發送或獲取一個流并將其寫入多個內存緩沖區
應用場景
低延遲 - 例如:HPC、金融服務、Web 2.0
高帶寬 - 例如:HPC、醫療設備、存儲和備份系統、云計算
CPU 占用空間小 - 例如:HPC、云計算
當今是云計算、大數據的時代,企業業務持續增長需要存儲系統的 IO 性能也持續增長。傳統的 TCP/IP 技術在數據包處理過程中,要經過操作系統及其他軟件層,數據在系統內存、處理器緩存和網絡控制器緩存之間來回進行復制,給服務器的 CPU 和內存造成了沉重負擔。尤其是網絡帶寬、處理器速度與內存帶寬三者的嚴重"不匹配性",更加劇了網絡延遲效應。為了降低數據中心內部網絡延遲,提高帶寬,RDMA 技術應運而生。RDMA 允許用戶態的應用程序直接讀取和寫入遠程內存,避免了數據拷貝和上下文切換;并將網絡協議棧從軟件實現 offload 到網卡硬件,實現了高吞吐量、超低時延和低 CPU 開銷的效果。
當前 RDMA 在以太網上的傳輸協議是 RoCEv2,RoCEv2 是基于無連接協議的 UDP 協議,相比面向連接的 TCP 協議,UDP 協議更加快速、占用 CPU 資源更少,但其傳輸是不可靠的,一旦出現丟包會導致 RDMA 的傳輸效率降低,這是由 RDMA 的 Go-back-N 重傳機制決定的。RDMA 接收方網卡發現丟包時,會丟棄后續接收到的數據包,發送方需要重發之后的所有數據包,這導致性能大幅下降。所以要想 RDMA 發揮出其性能,需要為其搭建一套不丟包的無損網絡環境。
編程
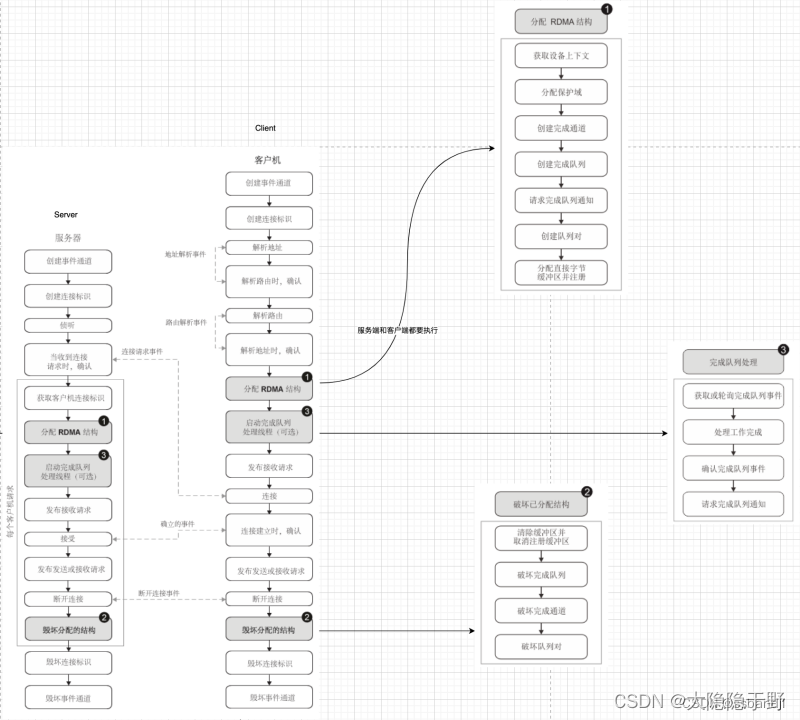
服務器流程
在 RDMA 連接的服務器端建立了以下事件:
創建事件通道。server_cm_ec = rdma_create_event_channel();
創建連接標識并將其與事件通道關聯。可以將任何數量的連接標識與事件通道關聯。
struct rdma_cm_id* listener; rc = rdma_create_id(server_cm_ec, &listener, NULL, RDMA_PS_TCP);
綁定地址后, 服務器偵聽來自客戶機的連接請求。 rc = rdma_bind_addr(listener, (struct sockaddr *)&srv_addr); rc = rdma_listen(listener, BACKLOG); 啟動rdma服務器運行線程: rc = pthread_create(&tid, NULL, rserver_run, this);
當接收到客戶機連接請求時,將對請求進行應答。請求的事件類型為 RDMA_CM_EVENT_CONNECT_REQUEST。
對于從客戶機接收到的每個請求,將會執行以下步驟:
5.1 服務器獲取客戶機連接標識。
5.2 在建立服務器和客戶機之間的連接之前分配必要的 RDMA 結構。需要以下步驟來創建 RDMA 結構:
獲取設備的上下文,該上下文可用于查詢設備、端口或全局唯一標識 (GUID)。
分配保護域PD。
為發布完成事件創建完成通道。
創建完成隊列。
針對完成隊列通知發出工作請求。
創建隊列對。
為數據傳輸分配并注冊直接字節緩沖區。
5.3 (可選)可以啟動完成隊列處理線程。有關發生的事件的更多信息,請參閱完成隊列處理。
5.4 當 RDMA 結構就緒時,服務器會發布接收工作請求。
5.5 接受(accept)工作請求后,會向客戶機發送事件以確認連接已建立并準備就緒以接收 RDMA 發送或接收請求。事件類型為 RDMA_CM_EVENT_ESTABLISHED。
5.6 發布發送或接收請求,該請求會在服務器和客戶機系統之間啟動數據傳輸。
5.7 當工作請求完成時,斷開連接。服務器會生成事件類型 RDMA_CM_EVENT_DISCONNECTED。
按照以下順序移除為數據傳輸創建的 RDMA 結構:
清除并注銷緩沖區。
移除完成隊列。
移除完成通道。
移除隊列對。
要斷開服務器與客戶機系統的連接以阻止進一步的 RDMA 操作,請移除連接標識。
移除事件通道。在接收到所有應答之前,無法移除事件通道。
客戶機流程
在 RDMA 連接的客戶端發生了以下事件:
8. 創建事件通道。struct rdma_event_channel* cm_ec; client_cm_context.cm_ec = rdma_create_event_channel();
9. 創建連接標識并將其與事件通道關聯。可以將任何數量的連接標識與事件通道關聯。 struct rdma_cm_id rdma_id; rdma_create_id(client_cm_context.cm_ec, &rdma_id, NULL, RDMA_PS_TCP)
10. 客戶機使用 ConnectionID.ResolveAddress() 方法查詢服務器系統的地址。當接收到事件類型 RDMA_CM_EVENT_ADDRESS_RESOLVED 時,客戶機發送應答。rdma_resolve_addr(rdma_id, NULL, (struct sockaddr)addr, RDMA_RESOLVE_ADDR_TIMEOUT_MS) case RDMA_CM_EVENT_ADDR_RESOLVED: 執行回調rc = on_addr_resolved(&evt_cpy); -> rdma_resolve_route(evt->id, RDMA_RESOLVE_ROUTE_TIMEOUT_MS)
11. 客戶機使用 ConnectionID.ResolveRoute() 方法查詢服務器系統的路由。當接收到事件類型 RDMA_CM_EVENT_ROUTE_RESOLVED 時,客戶機發送應答。收到事件: case RDMA_CM_EVENT_ROUTE_RESOLVED: -> rc = on_client_route_resolved(&evt_cpy);
12. 在建立客戶機和服務器之間的連接之前分配必要的 RDMA 結構。需要以下步驟來創建 RDMA 結構:
獲取設備的上下文,該上下文可用于查詢設備、端口或全局唯一標識 (GUID)。struct rdma_cm_id id = evt->id; struct rdma_device_context dev_ctx = get_dev_context(evt->id->verbs, rdma_name);
分配保護域。struct rdma_connection_priv priv_data;
為發布完成事件創建完成通道。struct ibv_qp_init_attr qp_attr;
創建完成隊列。poller_ctx->cq = ibv_create_cq(rdma_ctx, 8192, NULL, poller_ctx->comp_ec, 0)
針對完成隊列通知發出工作請求。rc = ibv_req_notify_cq(poller_ctx->cq, 0);
創建隊列對。 rdma_create_qp(evt->id, dev_ctx->pd, &qp_attr)
為數據傳輸分配并注冊直接字節緩沖區。
發送對列: qp_attr.send_cq = dev_ctx->poller_ctx[conn->rdma_poller_index].cq;
接收隊列: qp_attr.recv_cq = dev_ctx->poller_ctx[conn->rdma_poller_index].cq;
6.(可選)可以啟動完成隊列處理線程。有關發生的事件的更多信息,請參閱完成隊列處理。
13. 向服務器發出發布接收請求。
14. 向服務器發出連接請求。這會生成事件類型 RDMA_CM_CONNECT_REQUEST 并將其發送到服務器。rdma_connect(evt->id, &cm_params)
15. 客戶機等待直至從服務器接收到事件類型 RDMA_CM_EVENT_ESTABLISHED。此事件指示已建立連接且可以進行數據傳輸。
16. 發布發送或接收工作請求,該請求會在服務器和客戶機系統之間啟動數據傳輸。
17. 當工作請求完成時,斷開連接。客戶機會生成事件類型 RDMA_CM_EVENT_DISCONNECTED。
18. 按照以下順序移除為數據傳輸創建的 RDMA 結構:
清除并注銷緩沖區。
移除完成隊列。
移除完成通道。
移除隊列對。
19. 要斷開客戶機與服務器的連接以阻止進一步的 RDMA 操作,請移除連接標識。
20. 移除事件通道。
完成隊列處理
下圖擴展在選擇處理完成隊列時所需的編程步驟。此過程在第一張圖中顯示為以“完成隊列處理”標示的單個步驟,該步驟使用編號 3 進行標記。
圖中顯示了以下步驟:
21. 客戶機或服務器使用 getCQEvent() 和 pollCQEvent() 方法來從觸發處理的事件隊列通道檢索類型為 RDMA_CM_EVENT ESTABLISHED 的事件。
22. 處理工作完成。
23. 向完成隊列發送應答以確認工作完成。
24. 針對完成隊列通知發出請求以確保完成隊列接收到應答。
DAOS與RDMA

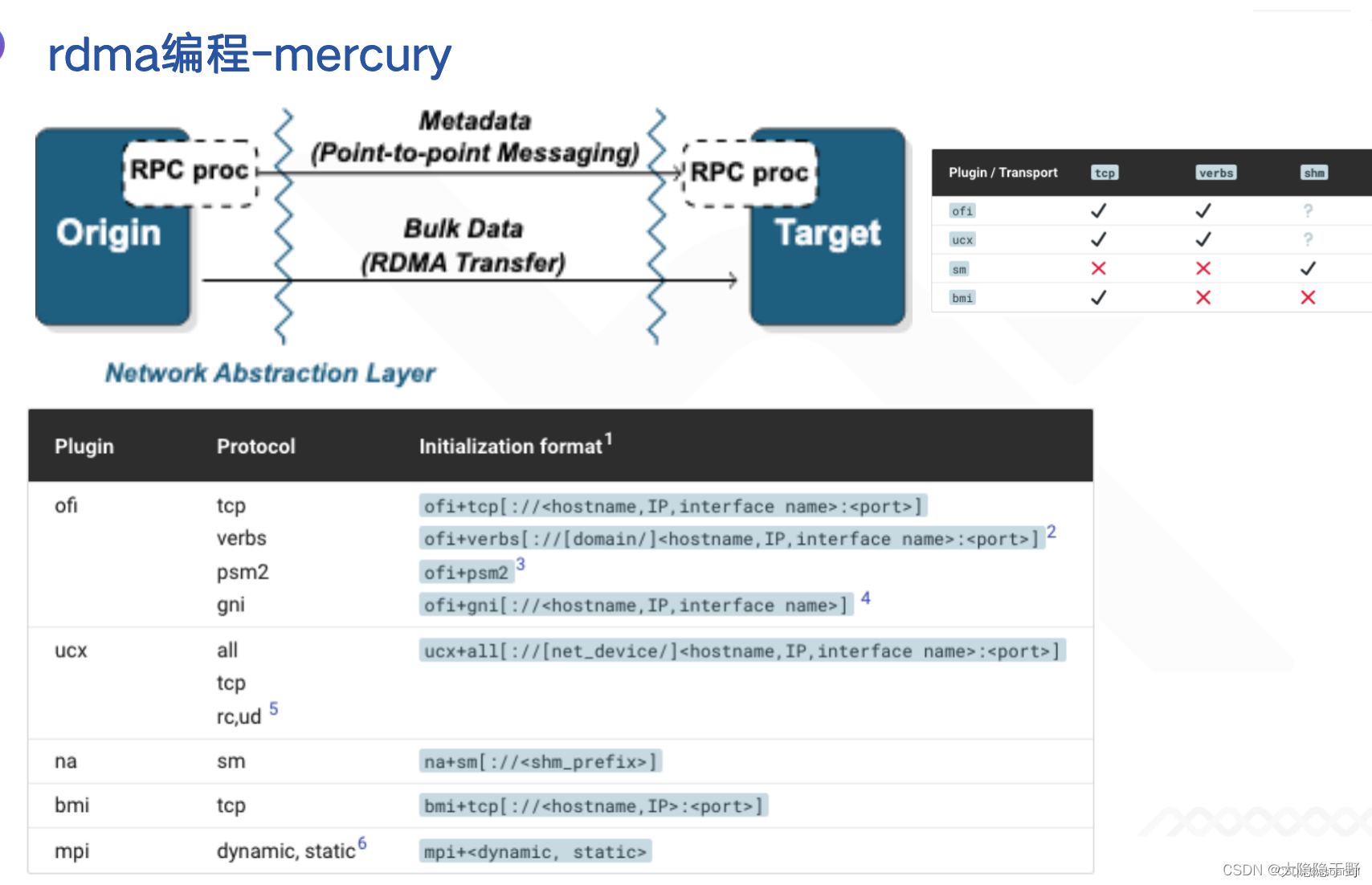
Libfabric與RDMA
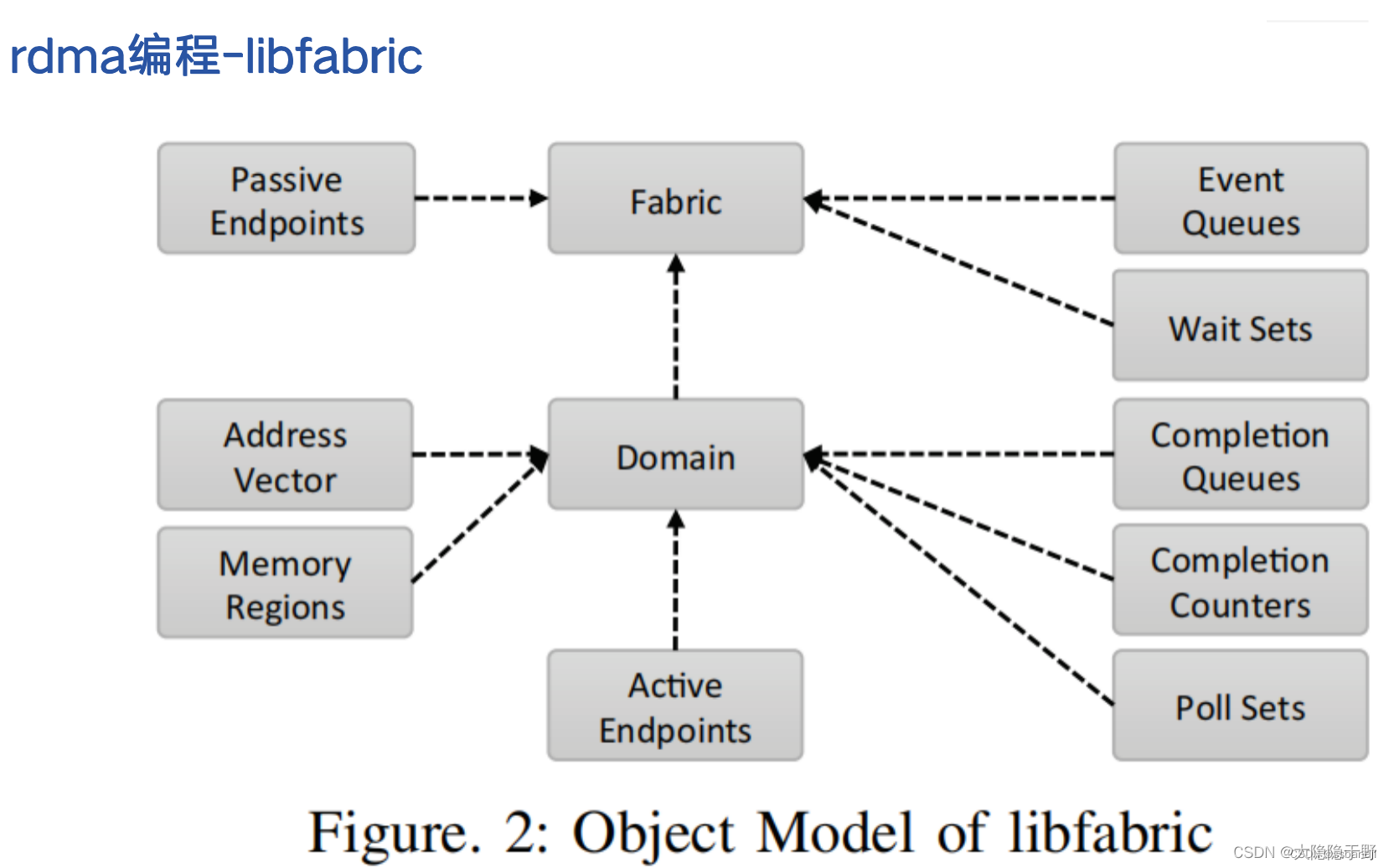
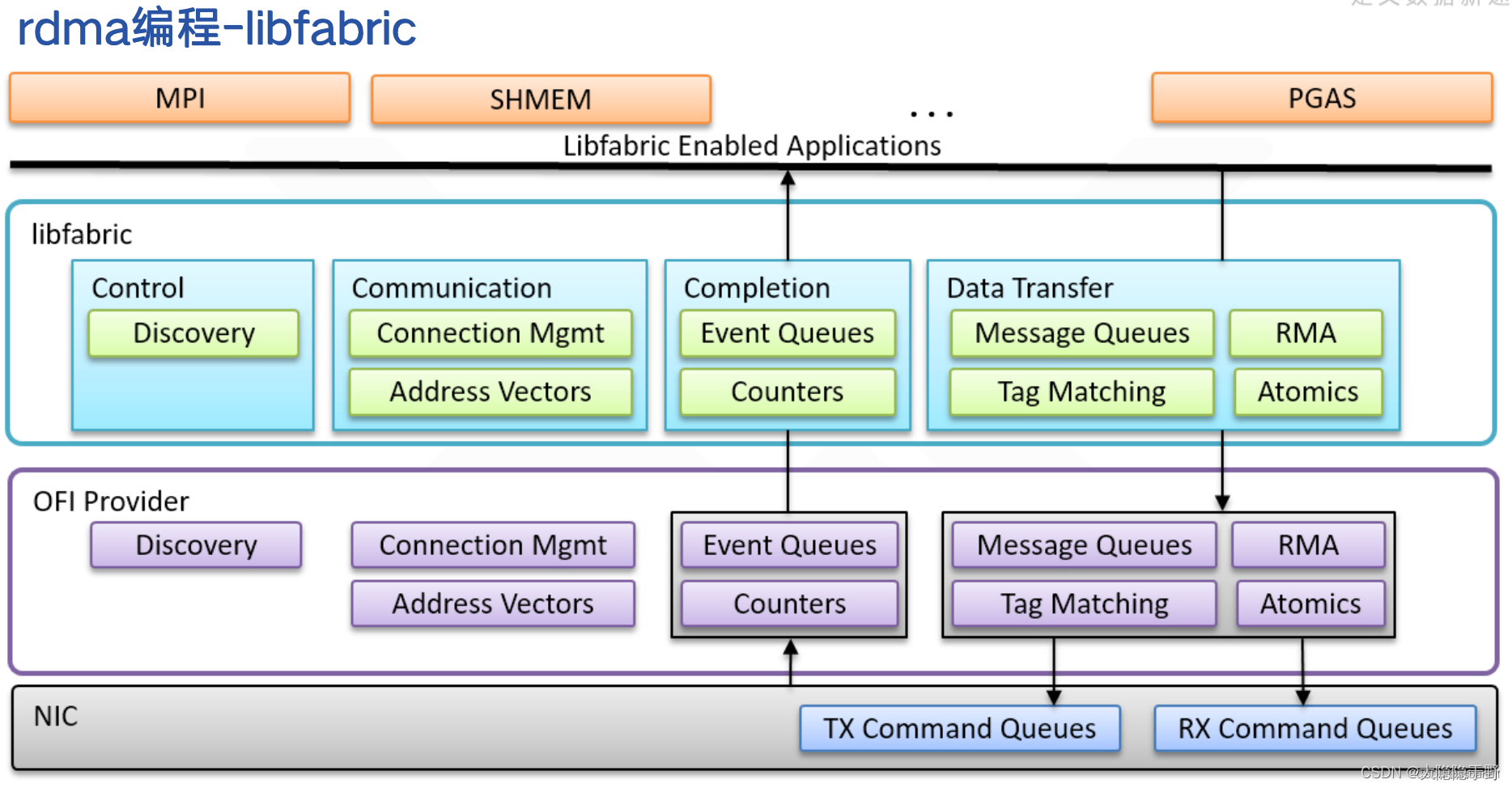
操作

OFI與Mercury(水銀HG)
Mercury 是 Mochi(麻糬)微服務生態系統的核心組件,是 R&D 100 獲獎項目,對libfabric封裝,提供網絡抽象NA,點對點RPC(對應RDMA的send/recv),大塊Bulk數據傳輸(如將RDMA的write/read封裝為put/get), 提供了靈活的RPC注冊, 回調, RPC飛行隊列/等待隊列擁塞控制, 單個RPC超時時間設置和跟蹤,重試機制, 存儲池等,充分利用底層網絡性能
CaRT(集體和 RPC 傳輸)與Mercury
CaRT 是用于大數據和 百億級 HPC 的開源 RPC 傳輸層。它支持傳統的 P2P RPC 和集體 RPC,后者通過可擴展的基于樹的消息傳播在一組目標服務器上調用 RPC。Cart將Mercury封裝,對應用程序提供初始化上下文,創建請求,發送請求,請求回調等數據通道接口,典型的上層應用如心跳swim,rank管理, 持久內存和Nvme讀寫io。


、源碼安裝nginx、系統服務、進程管理)



怎么調用另一個文件(B.py)中定義的類AA詳解和示例)

:013桉樹、米櫧、栲類)



)


![Banana Pi [BPi-R3-Mini] 回顧和主線 ImmortalWrt 固件支持](http://pic.xiahunao.cn/Banana Pi [BPi-R3-Mini] 回顧和主線 ImmortalWrt 固件支持)

:安裝Minio)

)