本篇是對文章《一文徹底讀懂一致性哈希算法》的重寫,圖文并茂,篇幅較長,歡迎閱讀完提供寶貴的建議,一起提升文章質量。如果感覺不錯不要忘記點贊、關注、轉發哦。
原文鏈接:
《一文徹底讀懂一致性Hash 算法》
通過閱讀本文你可以獲得如下內容:
背景
? 我們的場景就是大數據量的圖片(或者緩存請求)能夠在多個服務器之間進行負載均衡,實現在某個服務器發生故障時最小的影響系統,盡量的減少圖片無法查看的請求。
? 那么我們為什么要提到一致性 Hash 算法呢,簡單的Hash 算法不能滿足我們的需求嗎?下面跟我一起來學習下一致性 Hash 算法是如何解決我們的問題的。
為什么要用一致性 Hash 算法?
? 為什么要用一致性 Hash 算法,那肯定是因為它有優點,優點就是可以盡可能小的改變已存在的服務請求與處理請求服務器之間的映射關系,從而提高系統的可伸縮性和容錯性。
-
負載均衡: 一致性哈希算法能夠在節點的增加或減少時最小化數據遷移的數量。在傳統的哈希算法中,當節點發生變化時,幾乎所有的數據都需要重新分配,導致大量的數據遷移。而一致性哈希只需要遷移一小部分數據,使得負載更加均衡。
-
容錯性: 當系統中的節點發生故障或需要擴展時,一致性哈希算法能夠最小化數據的丟失或遷移。新節點加入或舊節點離開時,只有部分數據需要重新映射,而不是整個數據集。
-
可伸縮性: 一致性哈希算法支持動態地添加或刪除節點,而不需要重新計算大部分數據的映射關系。這使得系統更容易擴展,同時減少了系統維護的復雜性。
-
簡化路由表: 在一致性哈希中,每個節點僅負責一小部分數據,因此路由表的大小相對較小。這降低了路由表的存儲和維護成本。
-
分布式存儲: 一致性哈希常被用于分布式存儲系統,如分布式緩存、分布式文件系統等。它能夠有效地處理大規模數據集的分片和分布,提高系統的性能和可擴展性。
總的來說,一致性哈希算法通過減小數據遷移的范圍,提高了分布式系統的可伸縮性、容錯性和負載均衡性,使得系統更具彈性和效率。
普通 Hash 算法有什么缺點?
? 通過一個例子來看一下簡單 Hash 算法有什么缺點。
? 假設我們有三臺緩存服務器A、B、C用于緩存圖片,現在需要對請求過來的圖片均勻的緩存在這三臺服務器上,以便它們均攤緩存圖片的請求。
? 假設有三萬張圖片需要緩存,也就是每臺服務器平均緩存一萬張左右。如果我們以沒有任何規律的方式把三萬張圖片平均的緩存在三臺服務器上,也能滿足我們的需求,但是如果這樣做的話,會有什么問題呢?想想看?
問題就是:
? 當我們訪問某一張圖片時,最差的情況是需要遍歷三臺服務器,從三萬個緩存中找到我們所需要的緩存,這樣的話其實也就失去了緩存的意義,并沒有改善用戶的體驗。那么我們可以怎么做呢,原始的做法就是對圖片名稱進行 Hash 運算(假設圖片名稱是唯一的),將 Hash 后的結果與服務器數量進行取模操作,通過取模后的結果來決定緩存該存在哪個服務器上,那么我們可以使用如下公式來決定圖片應該存在哪臺服務器上?
其中 N 為服務器的數量。
hash(圖片名稱)%N
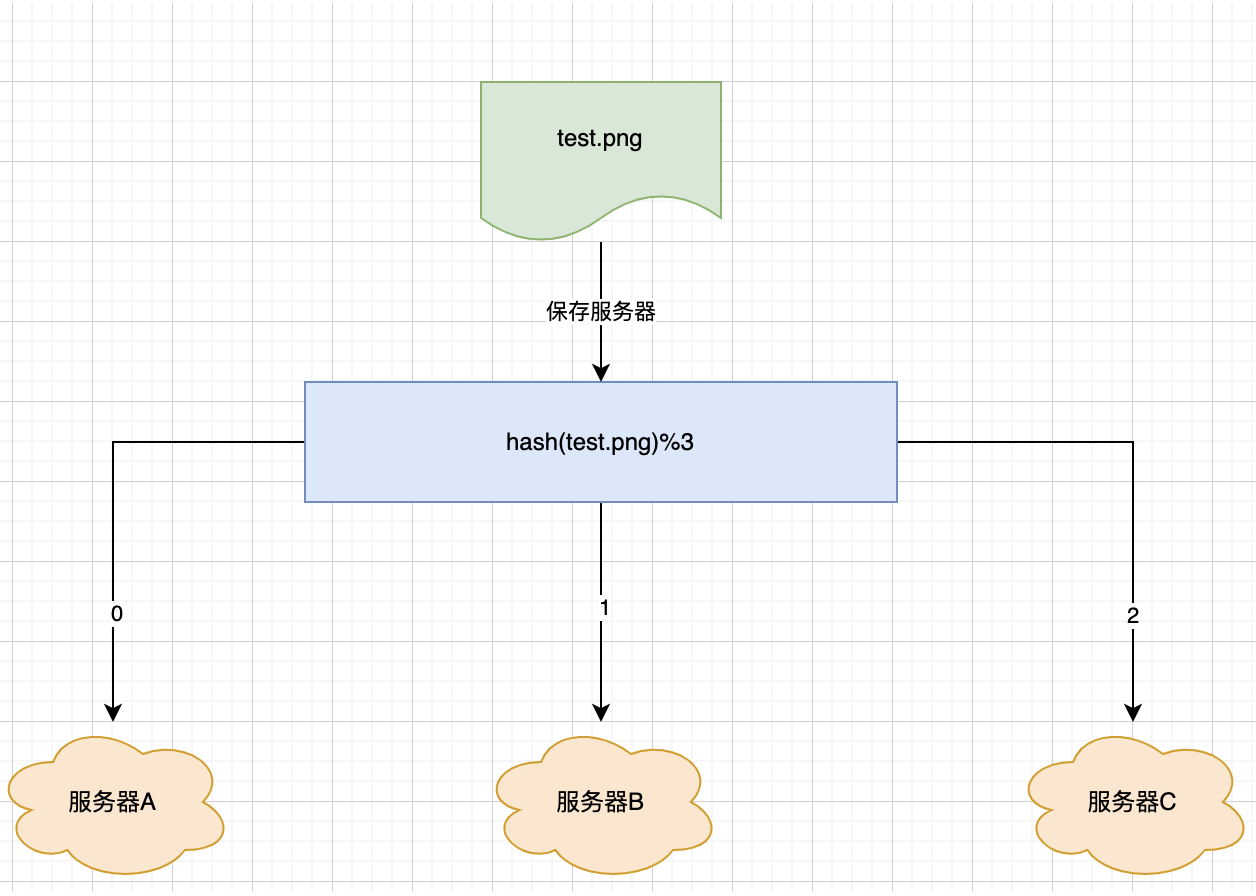
? 因為圖片的名稱是不重復的,所以當我們對一個圖片名稱做相同的 Hash 計算時,得到的結果應該是不變的。
如果我們有三臺服務器,使用哈希后的結果就是對3進行取余,那么余數一定是0、1、2三個中的一個,沒錯,正好對應我們的服務器A、B、C,所以如果求余的結果是0,那么我們就可以把圖片緩存在服務器A上,相反,如果取余的結果是1,那就是緩存在服務器B上。
那么當我們訪問任意一個圖片時,只需要對圖片名稱進行上述的操作即可知道圖片緩存在哪個服務器上。如果圖片在對應的服務器上不存在,則證明對應的圖片沒緩存,也就不需要再去其它的服務器上查詢了,通過這樣的方法,就可以平均的把三萬張圖片分散的放在三臺服務器上,而且當下次訪問某張圖片時,直接就能判斷出當前圖片所在的服務器,這樣就能滿足我們的需求了。
? 當使用了上面的哈希算法之后還會有什么問題呢,試想一下,如果三臺緩存服務器已經不能滿足我們的緩存需求,那么我們是不是要增加一臺,那么緩存服務器的數量就由3臺變成4臺了,此時如果仍然采用上述方法對同一張圖片進行緩存,那么這張圖片所在的服務器編號必定與原來三臺服務器時產生的結果不一致,這種情況帶來的后果就是當緩存服務器數量發生變動時,所有緩存的位置都要發生改變。
? 換句話說,當服務器數量發生改變時,所有緩存在一定時間內是失效的,當請求無法從緩存中讀取到數據時,則會向后端服務器發送請求,同理,假設三臺服務器其中有一臺服務器發生了故障,無法進行緩存,那么我們就需要將故障機器移除,此時響應的緩存服務器數量也是發生了變化,以前緩存的圖片也就失去了意義,此時大量圖片緩存失效,造成緩存雪崩,此時緩存無法在分擔壓力,后端服務器將承受壓力,整個系統也就有可能被壓垮,所以我們要想辦法不讓這種情況發生,但是由于上述哈希算法本身的緣故,使用取模算法進行緩存時,這種情況是不可避免的,為了解決這些問題,一致性 Hash 算法也就應運而生了。
所以我們來回顧下使用簡單 Hash 算法會產生的問題:
- 當緩存服務器數量發生變化時,引起緩存大量失效,緩存雪崩,可能會使后端服務器壓力變大而崩潰。
- 當緩存服務器數量發生變化時,幾乎所有的緩存位置都會發生變化,那我們怎樣才能減少受影響的緩存呢?
? 其實,這兩個問題都可以使用一致性 Hash 算法解決,現在我們繼續深入了解一下一致性 Hash 算法。
什么是一致性 Hash 算法?
? 一致性哈希算法是1997年在論文《Consistent hashing and random trees》中被提出的,在分布式系統中應用非常廣泛。一致性Hash 是一種 Hash 算法,簡單的說就是在移除或者添加一個服務器時,此算法能夠盡可能小的改變已存在的服務請求與處理請求服務器之間的映射關系,盡可能滿足單調性的要求。
? 在普通分布式集群中,服務請求與處理請求服務器之間可以一一對應,也就是說固定服務請求與處理服務器之間的映射關系,某個請求由固定的服務器去處理。這種方式無法對整個系統進行負載均衡,可能會造成某些服務器過于繁忙一直無法處理新來的請求,而另一些服務器則過于空閑,整體系統的資源利用率低,并且當分布式集群中的某個服務器宕機,會直接導致某些服務請求無法處理。
? 進一步的改進可以利用 Hash 算法對服務請求進行處理服務器之間的關系進行映射,以達到動態分配的目的。通過 Hash 算法對服務請求進行轉換,轉換后的結果對服務器節點值進行取模計算,取模后的值就是服務請求對應的請求處理服務器。這種方法可以應對節點失效的情況,當某個分布式集群節點宕機,服務請求可以通過 Hash 算法重新分配到其他可用的服務器上。避免了無法處理請求的情況出現。
? 但這種方法的缺陷也很明顯,如果服務器中保存有服務請求對應的數據,那么如果重新計算請求的 Hash 值,會造成大量的請求被重定位到不同的服務器而造成請求所需要的數據無效,這種情況在分布式系統中是難以接受的。一個設計良好的分布式系統應該具有良好的單調性,即服務器的添加與移除不會造成大量的哈希重定位,而一致性哈希恰好可以解決這個問題。
? 一致性哈希算法將整個哈希值空間映射一個虛擬的圓環,整個哈希空間的取值范圍為 0~2 32 ^{32} 32-1 ,整個空間按順時針方向。0~2 32 ^{32} 32-1,在零點方向重合。接下來使用如下算法對請求進行映射,將服務請求使用 Hash 算法算出對應的 Hash值,然后根據 Hash 值的位置沿圓環順時針查找,遇到的第一個服務器就是所對應的處理請求服務器。當增加一臺新的服務器,受影響的數據僅僅是新添加的服務器到其環空間中前一臺的服務器(也就是順著逆時針方向遇到的第一臺服務器)之間的數據,其它都不會受到影響。綜上所述,一致性哈希算法對于節點的增減都只需重定位環空間中的一小部分數據,具有較好的容錯性和可擴展性。
? 首先,一致性哈希算法是采用取模的方法,只是,剛才的取模算法是對服務器數量進行取模,那么我們只要不對服務器數量進行取模,而對一個常量進行取模不就可以了嗎,所以一致性哈希算法是對2 32 ^{32} 32進行取模,我們把0-2 32 ^{32} 32次方想象成一個圓,就像鐘表一樣的圓,鐘表的圓可以想象是圓上有60個點,而我們的這個圓是由2 32 ^{32} 32個點組成的圓,示意圖如下:
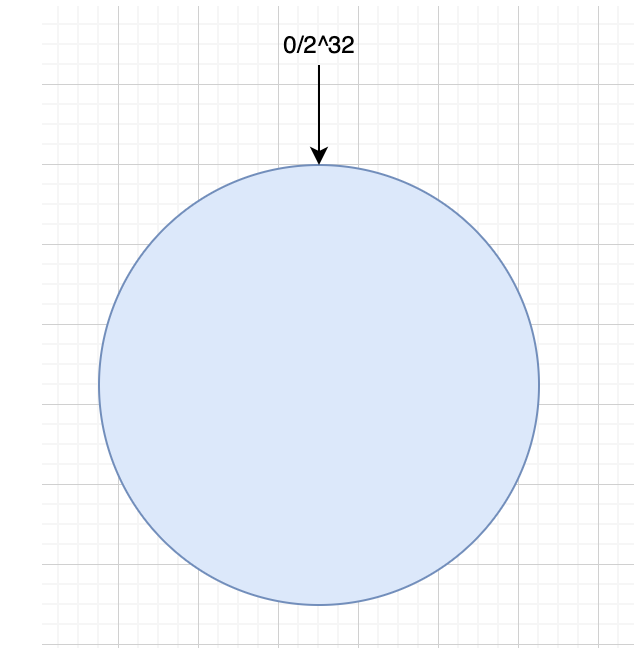
圓的正上方的點代表0,0點右側第一個點代表1,左側第一個點代表2 32 ^{32} 32-1,我們把0-2 32 ^{32} 32-1之間的圓環稱之為 Hash 環。
下面,跟我一起看下一致性 Hash 算法是怎么在這個圓上來體現的。
首先我們還是有三臺服務器,分別是服務器A,服務器B,服務器C,那么在我們的生產環境中,我們對這三臺服務器的 IP 地址進行 Hash,用 Hash 后的結果對2 32 ^{32} 32進行取模運算,得到的結果就是服務器的位置。
Hash(服務器IP地址)%2 32 ^{32} 32
通過這個公式計算的結果肯定是0-2 32 ^{32} 32-1之間的一個數,我們就用這個數代表服務器A。
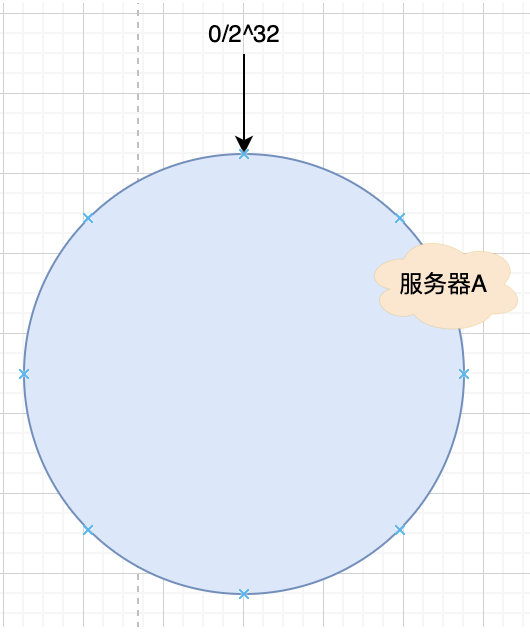
然后我們用同樣的方法,計算出服務器B,和服務器C的位置,表示如下。
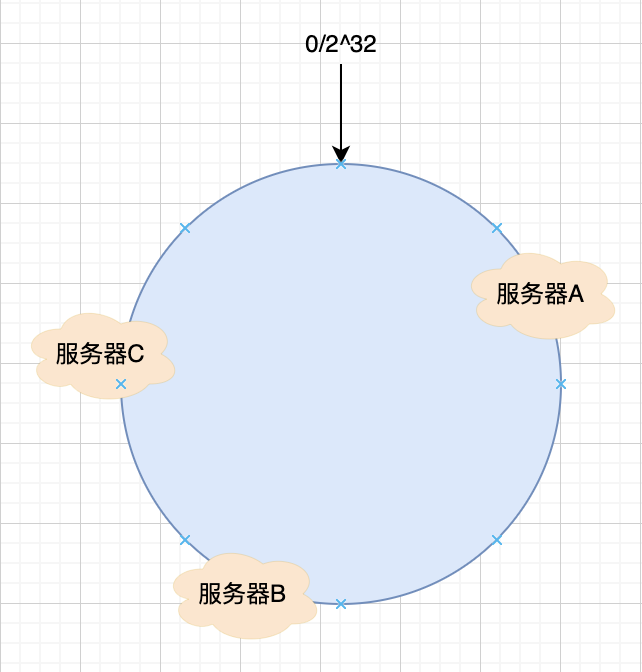
假設三臺服務器經過計算之后的位置如上圖所示(理想情況下是這個樣子,但是現實往往很無情)。
好了,到這里,我們已經把服務器與Hash環綁定到了一起,下面就是把數據綁定到 Hash環上,那么我們下面就用同樣的方法把需要緩存的對象放到Hash環上。
還是按照剛才的例子,對三萬張圖片進行緩存,此時我們還是使用如下公式。
Hash(圖片名稱)%2 32 ^{32} 32
第一張圖片映射的結果如下圖所示(假設)。
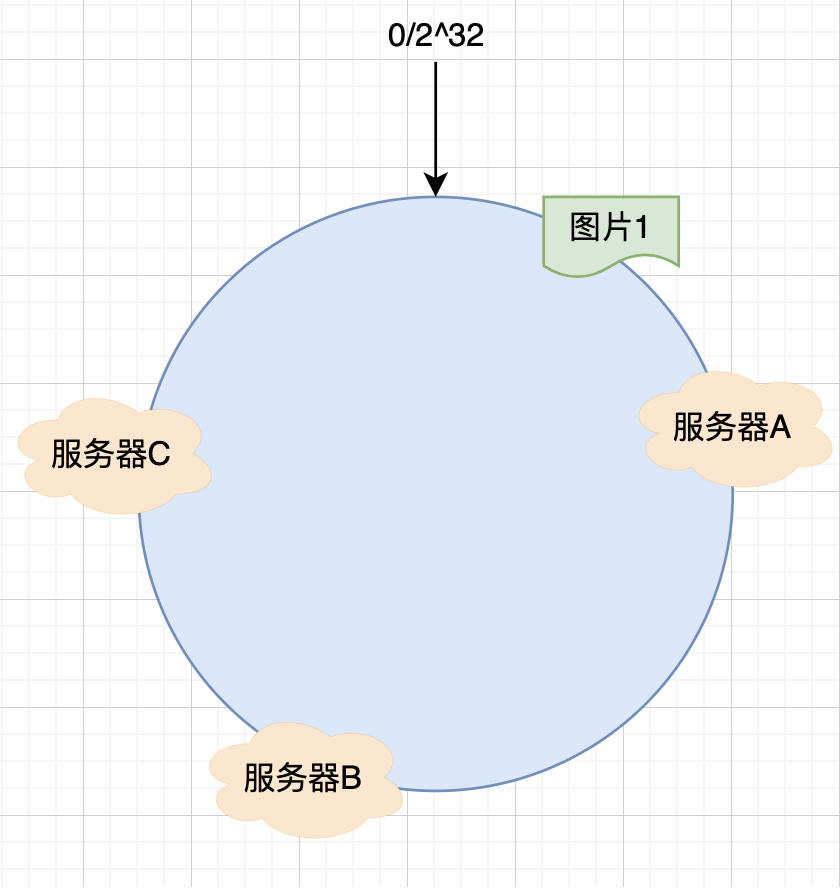
那么圖片1保存在哪臺服務器上去呢,上面的圖片會被緩存到服務器A上,為什么會這樣呢?因為從圖片1的位置開始,沿順時針方向遇到的第一個服務器就是服務器A,所以上圖會被緩存到服務器A上,如下圖所示:
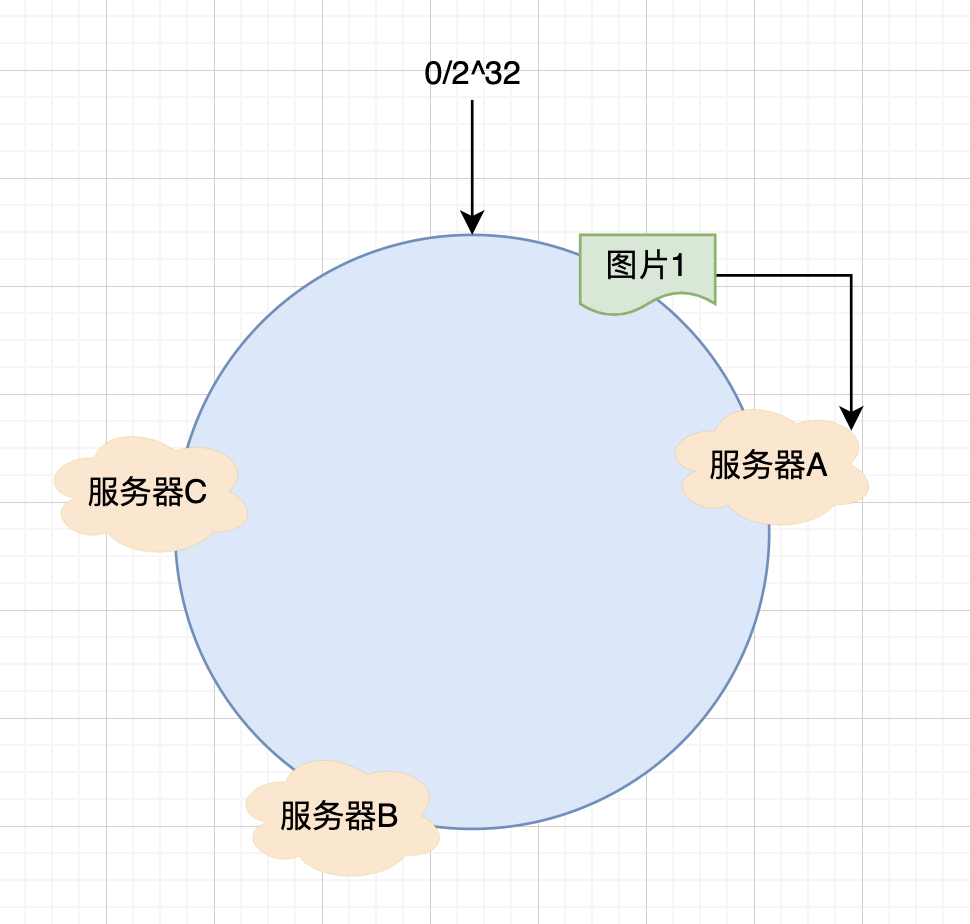
所以一致性 Hash 算法就是通過這種方法來判斷對象該存儲在哪臺服務器上的,也就是將緩存服務器與緩存對象綁定到 Hash 環上之后,從被緩存的對象開始,順時針方向遇到的第一臺服務器就是緩存對象要存儲的服務器,由于緩存對象對服務器 Hash 后的值是固定的,所以在服務器不變的情況下,一張圖片必定會緩存在固定的服務器上,所以當下次訪問該圖片時,只要再次使用同樣的哈希算法計算,即可獲取出該圖片在哪臺服務器上,然后直接去對應的服務器上獲取即可。
剛才的示例是一張圖片,下面演示一下多張圖片的位置。

圖片1,圖片4會緩存在服務器A上,圖片2緩存在服務器B上,圖片3緩存在服務器C上。
? 經過上面的描述,我想同學們應該能夠知道一致性 Hash 的原理了,所以同學們考慮一下,一致性 Hash 可以解決上面的兩個問題嗎?首先還是第一個問題,當服務器數量發生變動時,緩存會同一時間大量失效造成緩存雪崩,從而有可能引發系統的崩潰,那么使用一致性Hash 算法能夠避免這個問題嗎,下面我們來看一下。
假設服務器B出現故障,現在我們需要把服務器B移除掉,那么我們從 Hash 環上移除服務器B之后如下所示:
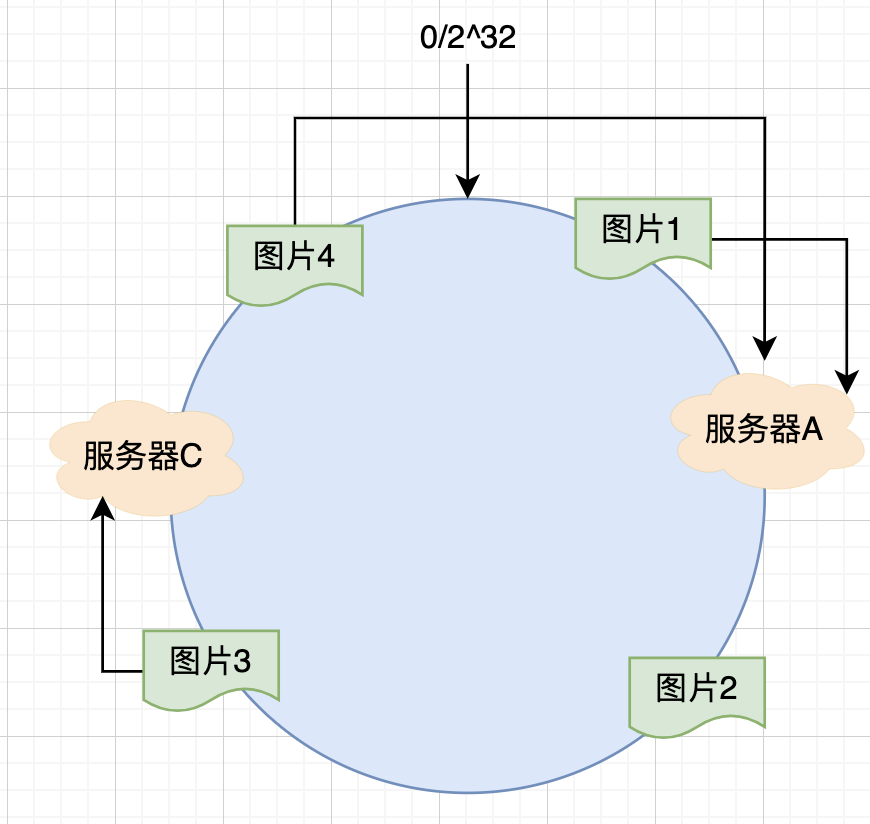
? 在服務器B沒有故障未被移除時,圖片2應該是緩存在服務器B上,可是當服務器B有了故障被移除后,圖片2按照順時針方向遇到的第一個服務器就變成了服務器C,所以此時圖片2就被緩存在服務器C中,也就是說,如果服務器B出現故障,圖片2的緩存位置會發生變化。

? 此時,圖片3仍然會被緩存中服務器C中,圖片1與圖片4緩存在服務器A中,這與服務器B移除前后并不會有影響,這也就是 Hash 算法的優點,如果使用之前的 Hash 算法,服務器數量發生變化時,所有的緩存對象都會發生變化,而使用一致性哈希算法之后,服務器的數量如果發生變化,并不是所有的緩存都會失效,而只有部分緩存才會失效,所以這種情況下不至于所有的緩存失效,都在同一時間集中到后端服務器上。
思考一下:通過上面的學習,可以知道了一致性 Hash 算法帶來的優點了,那么有什么缺點呢或者說有什么需要注意的點呢?這塊你可以想到嗎?
一致性 Hash 算法有什么缺點?
在這里也是給同學們舉例說明。
在介紹一致性哈希時,我們是非常理想化的假設3臺服務器均勻的分布在 Hash 環上,如下圖所示:
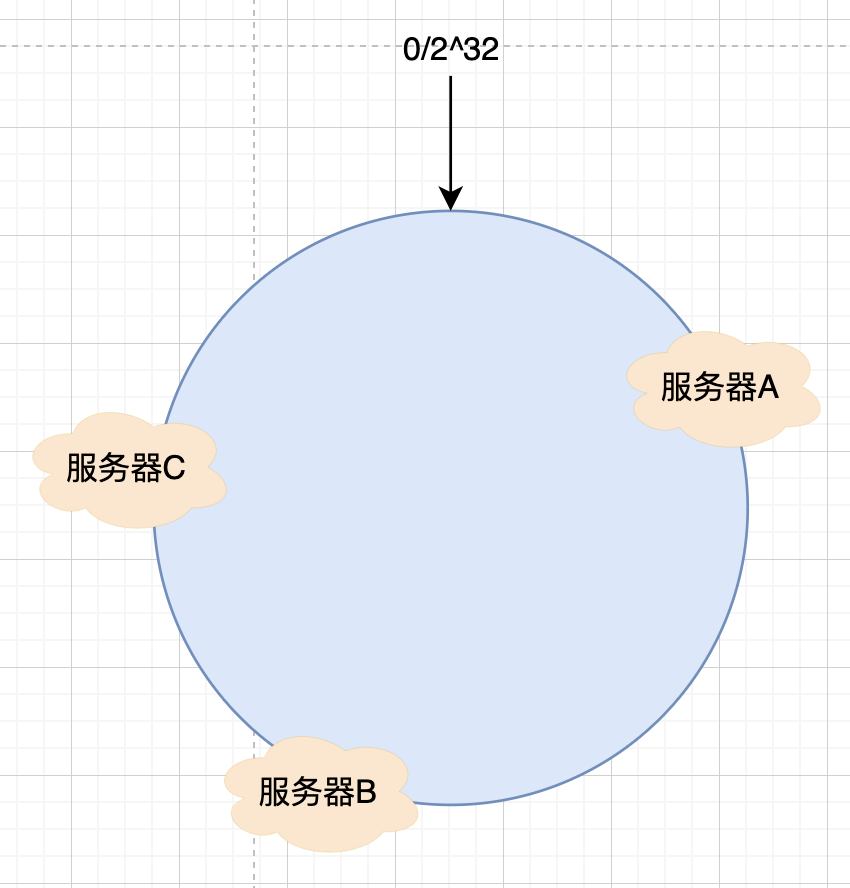
但是往往現實不會如此,在實際的使用過程中,服務器有可能會被映射為如下圖所示的情況:
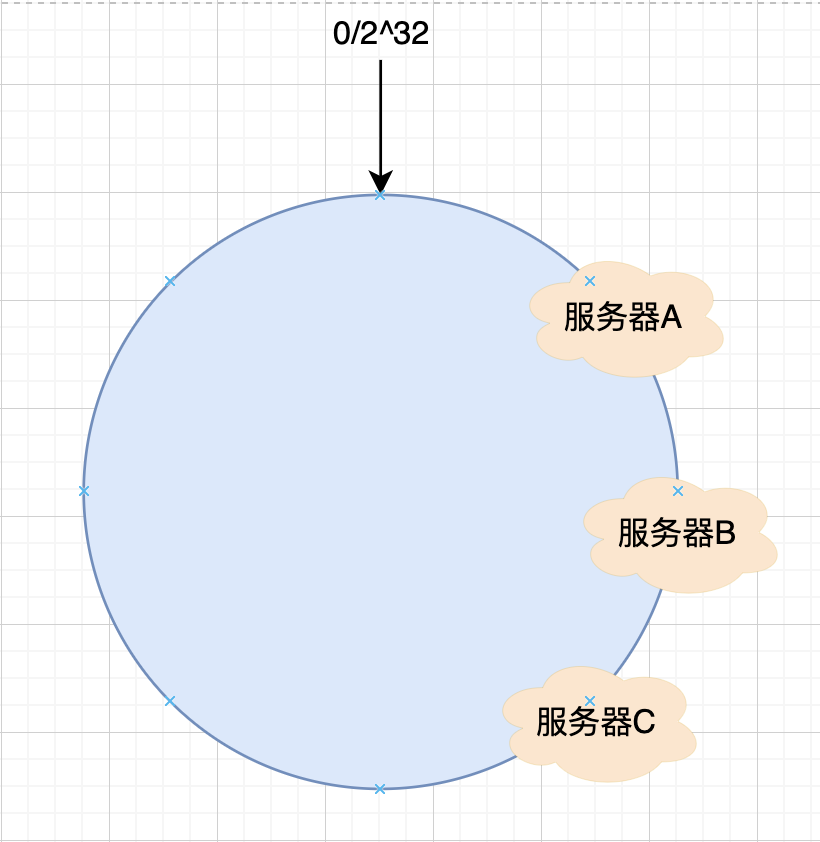
聰明的你肯定想到如果發生了這種情況,那么緩存的對象可能會集中的緩存在一臺服務器上,這也就是 Hash 環的傾斜,如下圖所示:
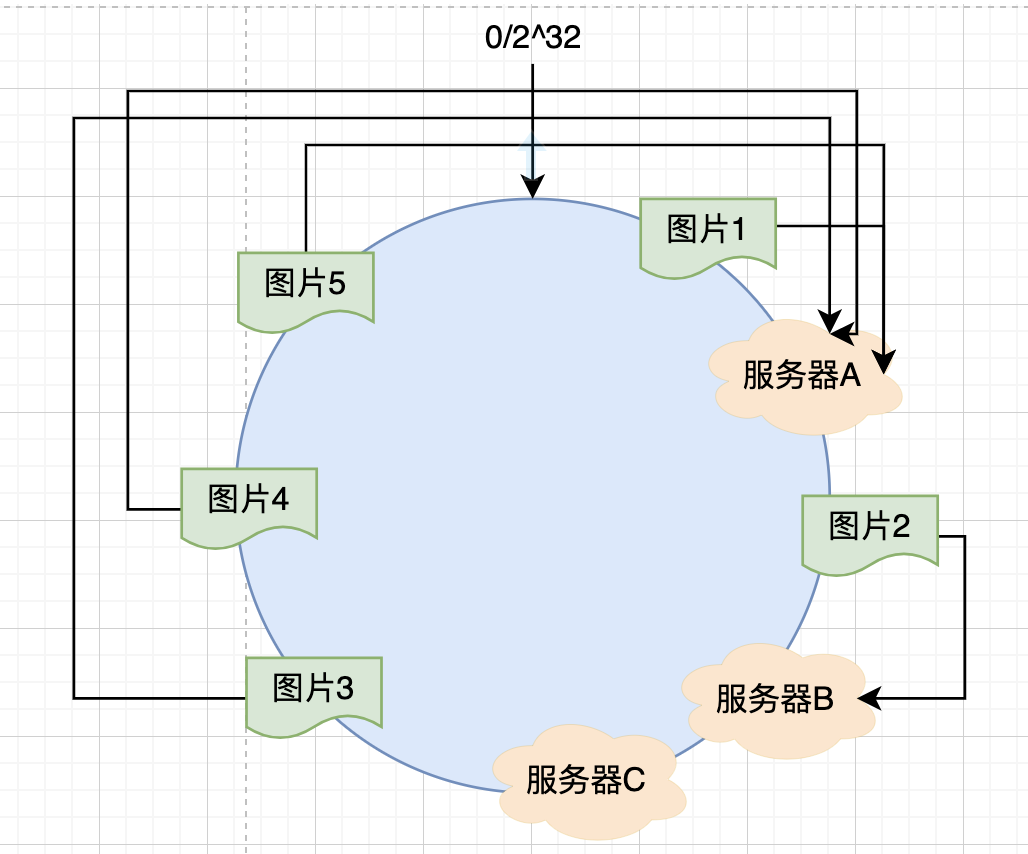
? 此時,如圖所示,圖片1,圖片3,圖片4,圖片5都會緩存到服務器A上,圖片2緩存中服務器B上,服務器C上沒有圖片,也就是說,服務器資源并沒有理想化平均的被使用。最壞的情況下,如果此時服務器A發生故障,那緩存失效的對象也就達到了最大值,極端情況下也有可能造成后端服務器的崩潰。此時這種情況稱之為 Hash 環的傾斜,那么怎么防止 Hash 環的傾斜呢,一致性hash算法使用虛擬節點來解決了這個問題,下面我們來看看。
如何最小化一致性 Hash算法帶來的影響?
? 還是按照我們說的,假設我們只有三臺服務器,當我們把服務器映射到 Hash 環上的時候,很有可能發生 Hash 環偏斜的情況,當 Hash環偏斜以后,緩存往往會極度不平衡的分布在各個服務器上,聰明的你肯定想到了,要想均衡的將緩存分布在三臺服務器上,那么只要這三臺服務器盡可能多的均勻的分布在H ash 環不就行了嗎,但是真實的服務器資源只有3臺,我們怎么憑空讓它多起來呢,沒錯,就是憑空讓服務器的節點多起來,既然沒有多余的真正的物理服務器節點,我們只能將現有的物理節點虛擬出來,這些由實際節點虛擬復制出來的節點被稱為“虛擬節點”,加入虛擬節點之后的 Hash 環如下圖所示:

虛擬節點是實際節點在 Hash 環上的復制品,一個實際節點可以復制多個虛擬節點。
? 從上圖可以看出,ABC三臺服務器分別虛擬出來一個虛擬節點,當然,如果你需要的話也可以虛擬出更多的節點,此時為了畫圖演示,我們各只虛擬出一個節點。
增加了虛擬節點的概念后,緩存的分布就均勻了很多,上圖中,圖片1,圖片3緩存在服務器A,圖片2,圖片4緩存在服務器B,圖片5緩存在服務器C,如果你還不放心的話,可以虛擬出更多的虛擬節點,以便減少 Hash環傾斜帶來的影響,虛擬節點越多,Hash環的節點越多,緩存被均勻分布的可能就越大。
? 所以,此時緩存對象已經均衡的分布在 Hash環上,如果在發生服務器故障,那么受影響的緩存對象就是發生故障的服務器逆時針方向到遇到的第一臺服務器之間的數據,受影響的緩存對象大大減少。
總結
讀到這了,不知道同學們收獲了多少,如果沒有記住,沒關系,下面我來給大家總結一下開頭的幾個問題。
-
為什么要用一致性 Hash 算法
能夠在服務器發生故障時最小化因為故障造成的影響,并且可以提升系統的可伸縮性。
-
普通 Hash 算法有什么缺點
其中一臺服務器故障,或者新增服務器時,大量緩存同時失效造成緩存雪崩。
-
什么是一致性 Hash 算法
一致性 Hash 算法就是可以盡可能小的影響已經存在的請求與服務器的映射關系。
-
一致性 Hash 算法有什么缺點
Hash 環偏移。
-
如何最小化一致性 Hash 算法帶來的影響?
使用虛擬節點。
好了,一致性哈希算法的原理就總結了這里,如果錯誤,歡迎賜教。如果感覺對你有幫助,歡迎點贊、評論、轉發。
參考鏈接
- 百度百科
- 維基百科
- 參考博客1
- 參考博客2
- 參考鏈接3

?





:014槭樹、梧桐、鵝掌楸、檫木、梓木、油桐、泡桐、川楝、麻楝)



)



·循環語句(for循環、while 語句、do‐while 語句))
)




