
?🔥博客主頁:小王又困了
📚系列專欄:C++
🌟人之為學,不日近則日退?
??感謝大家點贊👍收藏?評論??
目錄
一、函數重載
📒1.1函數重載的概念
📒1.2函數重載的種類
📒1.3 C++支持函數重載的原理
二、引用
📒2.1引用的概念
📒2.2引用的特性
📒2.3引用的使用場景
📒2.4傳值和引用性能比較
📒2.5常引用
📒2.6引用和指針的區別?
🗒?前言:
在上期的學習中,我們學習了命名空間和缺省參數,對C++有了初步的認識,本期我們將會學習函數重載和引用等新的概念。
一、函數重載
? ? ?自然語言中,一個詞可以有多重含義,人們可以通過上下文來判斷該詞真實的含義,即該詞被重載了。 比如:以前有一個笑話,國有兩個體育項目大家根本不用看,也不用擔心。一個是乒乓球,一個 是男足。前者是“誰也贏不了!”,后者是“誰也贏不了!”
📒1.1函數重載的概念
? ? ?函數重載是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數或類型或類型順序)不同,常用來處理實現功能類似數據類型不同的問題。
📒1.2函數重載的種類
- 參數類型不同
int Add(int left, int right) {cout << "int Add(int left, int right)" << endl;return left + right; }double Add(double left, double right) {cout << "double Add(double left, double right)" << endl;return left + right; }int main() {cout << Add(1, 2) << endl;cout << Add(1.0, 2.0) << endl; }? ? ?上面的代碼定義了兩個同名的Add函數,但是它們的參數類型不同,第一個函數的兩個參數都是int型,第二個函數的兩個參數都是double型,在調用Add函數的時候,編譯器會根據所傳實參的類型自動判斷調用哪個函數。
- 參數個數不同
void Fun() {cout << "f()" << endl; }void Fun(int a) {cout << "f(int a)" << endl; }int main() {Fun();Fun(1);return 0; }

- 參數類型順序不同
void Text(int a, char b) {cout << "Text(int a,char b)" << endl; }void Text(char b, int a) {cout << "Text(char b, int a)" << endl; }int main() {Text(1, 'a');Text('a', 1);return 0; }
- 有缺省參數的情況
void Fun() {cout << "f()" << endl; }void Fun(int a = 10) {cout << "f(int a)" << endl; }int main() {Fun(); //無參調用會出現歧義Fun(1); //調用的是第二個return 0; }? ? ?上面代碼中的兩個Fun函數構成函數重載,編譯可以通過,因為第一個沒有參數,第二個有一個整型參數,屬于上面的參數個數不同的情況。但是Fun函數存在一個問題:在沒有參數調用的時候會產生歧義,因為有缺省參數,所以對兩個Fun函數來說,都可以不傳參。
注意:返回值的類型與函數是否構成重載無關。
📒1.3 C++支持函數重載的原理
? ? ?在C/C++中,一個程序要運行起來,需要經歷以下幾個階段:預處理、編譯、匯編、鏈接。
? ? ?我們想理解清楚函數重載,還要了解函數簽名的概念,函數簽名包含了一個函數的信息,包括函數名、它的參數類型、他所在的類和名稱空間以及其他信息。函數簽名用于識別不同的函數。?C++編譯器和鏈接器都使用符號來標識和處理函數和變量,所以對于不同函數簽名的函數,即使函數名相同,編譯器和鏈接器都認為他們是不同的函數。
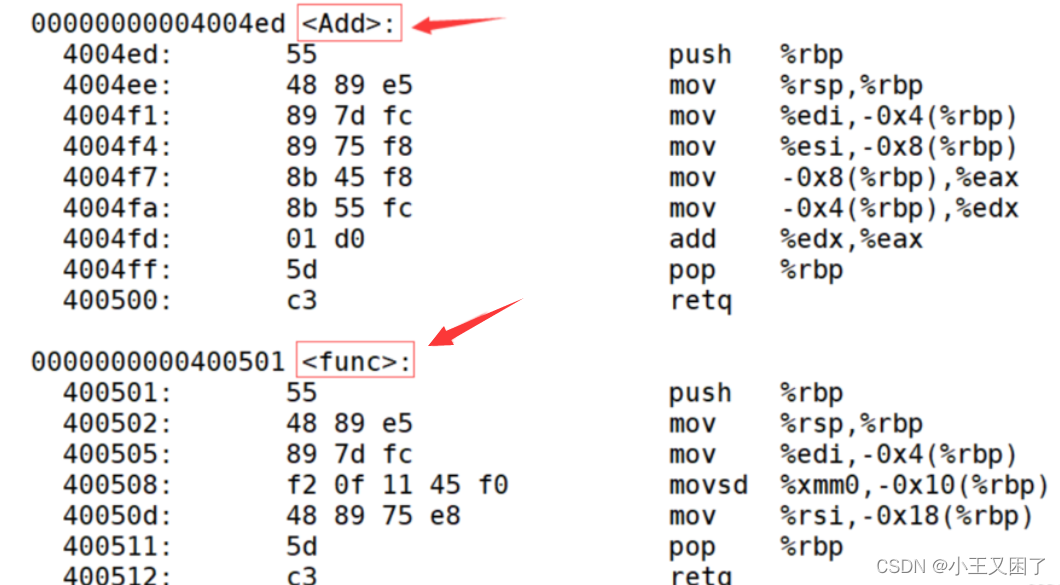
Linux環境下采用C語言編譯器編譯后結果
? ? ?可以看出經過gcc編譯后,函數名字的修飾沒有發生改變。這也就是為什么C語言不支持函數重
載,因為同名函數沒辦法區分。
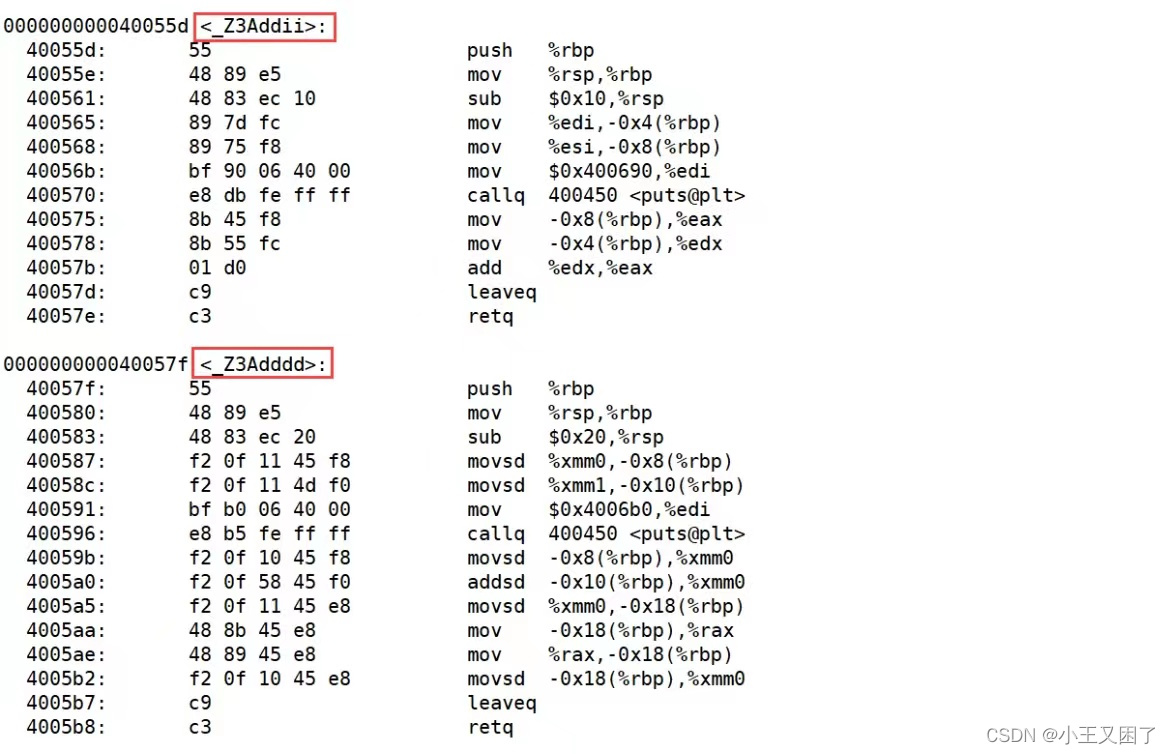
?采用C++編譯器編譯后結果
?其中_Z是固定的前綴;3表示函數名的長度;Add就是函數名;i是int的縮寫,兩個i表示兩個參數都是int類型,d是double的縮寫,兩個d表示兩個參數都是double類型。C++就是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。通過分析可以發現,修飾后的名稱中并不包含任何于函數返回值有關的信息,因此也驗證了上面說的返回值的類型與函數是否構成重載無關。
總結:
- C語言之所以沒辦法支持重載,是因為同名函數沒辦法區分。而C++是通過函數修飾規則來區分,只要參數不同,修飾出來的名字就不一樣,就支持了重載。
- 如果兩個函數函數名和參數是一樣的,返回值不同是不構成重載的,因為調用時編譯器沒辦法區分。
?
二、引用
📒2.1引用的概念
? ? ?引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空 間,它和它引用的變量共用同一塊內存空間。

- 類型& 引用變量名(對象名) = 引用實體
int main()
{int a = 0;int& b = a;//定義引用類型,b是a的引用return 0;
}注意:引用類型必須和引用實體是同種類型的
📒2.2引用的特性
- 引用在定義時必須初始化
int main() {int a = 10;int& b; //錯誤的return 0; }
在使用引用時,我們必須對變量進行初始化。int& b = a;,這樣的代碼才是被允許的。

- 一個變量可以有多個引用
int main() {int a = 10;int& b = a;int& c = a;return 0; }上面代碼中,b和c都是a的別名。就像孫悟空一樣,孫行者、悟空也都是他的名字,所以一個變量也可以同時有多個引用。
- 引用不能改變指向
int main() {int a = 10;int b = 20;int& c = a;c = b;return 0; }
? ? ?我們可以看到b和c的地址不同,所以c = b表示的不是c是b引用,而是是把b變量的值賦值給c引用的實體,c依舊是a的引用,所以引用一旦引用一個實體,再不能引用其他實體,也就是引用不能改變指向。

📒2.3引用的使用場景
🎀做參數
引用做參數的意義:
- 做輸出型參數,即要求形參的改變可以影響實參
- 提高效率,自定義類型傳參,用引用可以避免拷貝構造,尤其是大對象和深拷貝對象
交換兩個整型變量:?
void Swap(int& num1, int& num2) {int tmp = num1;num1 = num2;num2 = tmp; }int main() {int a = 5;int b = 10;Swap(a,b);return 0; }? ? ? 如上代碼,我們可以使用引用做參數實現了兩個數的交換,num1是 a 的引用,和?a?在同一塊空間,對num1的修改也就是對?a 修改,?b 同理,所以在函數體內交換num1和num2實際上就是交換?a 和 b 。以前交換兩個數的值,我們需要傳遞地址,還要進行解引用,相對繁瑣。
交換兩個指針變量:
void Swap(int*& p1, int*& p2) {int* tmp = p1;p1 = p2;p2 = tmp; }int main() {int a = 5;int b = 10;int* pa = &a;int* pb = &b;Swap(pa,pb);return 0; }? ? ?如果用C語言來實現交換兩個指針變量,實參需要傳遞指針變量的地址,那形參就需要用二級指針來接收,這顯然十分容易出錯。有了引用之后,實參直接傳遞指針變量即可,形參用指針類型的引用。
🎀做返回值
引用做返回值的意義:
- 減少拷貝,提高效率。
- 可以同時讀取和修改返回對象
int& add(int x, int y)
{int sum = x + y;return sum;
}int main()
{int a = 5;int b = 10;int ret = add(a, b);cout << ret << endl;return 0;
}
? ? ?如上代碼,我們使用傳值返回,調用函數要創建棧幀,sum是add函數中的一個局部變量,存儲在當前函數的棧幀中,函數調用結束棧幀銷毀,sum也會隨之銷毀,對于這種傳值返回,會生成一個臨時的中間變量,用來存儲返回值,在返回值比較小的情況下,這個臨時的中間變量一般就是寄存器。
? ? ?如上代碼,傳引用就是給sum起了一個別名,返回的值就是sum的別名,但是這里會出現問題,函數調用結束棧幀銷毀,sum也會隨之銷毀,返回它的值再進行調用就是越界訪問,打印出的值為隨機值。

可是這里的值為什么是正確的呢?這是取決于編譯器的,看編譯器是否會對這塊空間進行清理。
📒2.4傳值和引用性能比較
? ? ?以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直 接返回,而是傳遞實參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效 率是非常低下的,尤其是當參數或者返回值類型非常大時,效率就更低。
struct A
{int a[100000];
};void TestFunc1(A a)
{;
}void TestFunc2(A& a)
{;
}void TestFunc3(A* a)
{;
}//引用傳參————可以提高效率(大對象或者深拷貝的類對象)
void TestRefAndValue()
{A a;// 以值作為函數參數size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)//就是單純的調用一萬次這個函數傳一萬次參TestFunc1(a);size_t end1 = clock();// 以引用作為函數參數size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);//這里直接傳的是變量名size_t end2 = clock();//以指針作為函數參數size_t begin3 = clock();for (int i = 0; i < 10000; i++){TestFunc3(&a);}size_t end3 = clock();// 分別計算兩個函數運行結束后的時間cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;cout << "TestFunc3(A*)-time:" << end3 - begin3 << endl;
}
????
值和引用的作為返回值類型的性能比較:
struct A
{int a[100000];
};
A a;//全局的,函數棧幀銷毀后還在// 值返回
A TestFunc1()
{return a;
}// 引用返回
A& TestFunc2()
{return a;
}
void TestReturnByRefOrValue()
{// 以值作為函數的返回值類型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();//就讓他返回不接收size_t end1 = clock();// 以引用作為函數的返回值類型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 計算兩個函數運算完成之后的時間cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}int main()
{TestReturnByRefOrValue();return 0;
}

📒2.5常引用
🎀?權限放大
int main()
{const int a = 10;int& b = a;return 0;
}
![]()
? ? ?上面代碼中,用const定義了一個常變量?a?,然后給a取一個別名?b?,這段代碼在編譯過程中出現了錯誤,這是為什么呢?
? ? ??a?是一個常變量,是不可以被修改的,給?a?取別名為變量 b?,變量b沒有用const修飾,所以不具有常屬性,是可以被修改的,相當于權限的放大,這種情況是不允許的。正確的做法是:
int main()
{const int a = 10;const int& b = a;return 0;
}
🎀?權限縮小
int main()
{int a = 10;const int& b = a;return 0;
}
? ? ?上面代碼中,給一個普通的變量a取了一個別名b,這個b是一個常引用。這意味著,可以通過a變量去對內存中存儲的數據進行修改,但是不能通過b去修改內存中存儲的數據,但是b會跟著變。
📒2.6引用和指針的區別?
- 引用在概念上定義一個變量的別名,指針存儲一個變量的地址。
- 引用在定義時必須初始化,指針沒有要求。
- 引用在初始化時引用一個一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實體。
- 沒有NULL引用,但有NULL空指針。
- 在sizeof中的含義不同,引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位機下占四個字節,64位機下占八個字節)。
- 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小。
- 有多級指針,但是沒多級引用。
- 訪問實體方式不同。指針顯式解引用,引用編譯器自己做處理。
- 引用比指針使用起來相對更安全。
本次的內容到這里就結束啦。希望大家閱讀完可以有所收獲,同時也感謝各位讀者三連支持。文章有問題可以在評論區留言,博主一定認真認真修改,以后寫出更好的文章。你們的支持就是博主最大的動力。
)



·循環語句(for循環、while 語句、do‐while 語句))
)





![批量插入SQL 錯誤 [933] [42000]: ORA-00933: SQL 命令未正確結束](http://pic.xiahunao.cn/批量插入SQL 錯誤 [933] [42000]: ORA-00933: SQL 命令未正確結束)







)