往期快速傳送門:
Java核心知識點整理大全-筆記_希斯奎的博客-CSDN博客文章瀏覽閱讀9w次,點贊7次,收藏7次。Java核心知識點整理大全https://blog.csdn.net/lzy302810/article/details/132202699?spm=1001.2014.3001.5501
Java核心知識點整理大全2-筆記_希斯奎的博客-CSDN博客
Java核心知識點整理大全3-筆記_希斯奎的博客-CSDN博客
Java核心知識點整理大全4-筆記-CSDN博客
Java核心知識點整理大全5-筆記-CSDN博客
Java核心知識點整理大全6-筆記-CSDN博客
Java核心知識點整理大全7-筆記-CSDN博客
Java核心知識點整理大全8-筆記-CSDN博客
Java核心知識點整理大全9-筆記-CSDN博客
目錄
4.1.17. 如何在兩個線程之間共享數據
將數據抽象成一個類,并將數據的操作作為這個類的方法
Runnable 對象作為一個類的內部類
4.1.18. ThreadLocal 作用(線程本地存儲)
ThreadLocalMap(線程的一個屬性)
使用場景
4.1.19. synchronized 和 ReentrantLock 的區別
4.1.19.1. 兩者的共同點:
4.1.19.2. 兩者的不同點:
4.1.20. ConcurrentHashMap 并發
4.1.20.1. 減小鎖粒度
4.1.20.2. ConcurrentHashMap 分段鎖
ConcurrentHashMap 是由 Segment 數組結構和 HashEntry 數組結構組成
4.1.21. Java 中用到的線程調度
4.1.21.1. 搶占式調度:
4.1.21.2. 協同式調度:
4.1.21.3. JVM 的線程調度實現(搶占式調度)
4.1.21.4. 線程讓出 cpu 的情況:
4.1.22. 進程調度算法
4.1.22.1. 優先調度算法
4.1.22.2. 高優先權優先調度算法
1. 非搶占式優先權算法
2. 搶占式優先權調度算法
3.高響應比優先調度算法
4.1.22.3. 基于時間片的輪轉調度算法
1. 時間片輪轉法
2. 多級反饋隊列調度算法
4.1.23.1. 概念及特性
4.1.23.2. 原子包 java.util.concurrent.atomic(鎖自旋) JDK1.5 的原子包:
4.1.23.3. ABA 問題
4.1.17. 如何在兩個線程之間共享數據
Java 里面進行多線程通信的主要方式就是共享內存的方式,共享內存主要的關注點有兩個:可見 性和有序性原子性。Java 內存模型(JMM)解決了可見性和有序性的問題,而鎖解決了原子性的 問題,理想情況下我們希望做到“同步”和“互斥”。有以下常規實現方法:
將數據抽象成一個類,并將數據的操作作為這個類的方法
1. 將數據抽象成一個類,并將對這個數據的操作作為這個類的方法,這么設計可以和容易做到 同步,只要在方法上加”synchronized“
public class MyData {private int j=0;public synchronized void add(){j++;System.out.println("線程"+Thread.currentThread().getName()+"j 為:"+j);}public synchronized void dec(){j--;System.out.println("線程"+Thread.currentThread().getName()+"j 為:"+j);}public int getData(){return j;}}
public class AddRunnable implements Runnable{MyData data;public AddRunnable(MyData data){this.data= data;} public void run() {data.add();}}
public class DecRunnable implements Runnable {MyData data;public DecRunnable(MyData data){this.data = data;}public void run() {data.dec();}}
public static void main(String[] args) {MyData data = new MyData();Runnable add = new AddRunnable(data);Runnable dec = new DecRunnable(data);for(int i=0;i<2;i++){new Thread(add).start();new Thread(dec).start();}Runnable 對象作為一個類的內部類
2. 將 Runnable 對象作為一個類的內部類,共享數據作為這個類的成員變量,每個線程對共享數 據的操作方法也封裝在外部類,以便實現對數據的各個操作的同步和互斥,作為內部類的各 個 Runnable 對象調用外部類的這些方法。
public class MyData {private int j=0;public synchronized void add(){j++;System.out.println("線程"+Thread.currentThread().getName()+"j 為:"+j);}public synchronized void dec(){j--;System.out.println("線程"+Thread.currentThread().getName()+"j 為:"+j);}public int getData(){return j;}}
public class TestThread {public static void main(String[] args) {final MyData data = new MyData();for(int i=0;i<2;i++){new Thread(new Runnable(){public void run() {data.add();}}).start();new Thread(new Runnable(){public void run() {data.dec();}}).start();}}
}
4.1.18. ThreadLocal 作用(線程本地存儲)
ThreadLocal,很多地方叫做線程本地變量,也有些地方叫做線程本地存儲,ThreadLocal 的作用 是提供線程內的局部變量,這種變量在線程的生命周期內起作用,減少同一個線程內多個函數或 者組件之間一些公共變量的傳遞的復雜度。
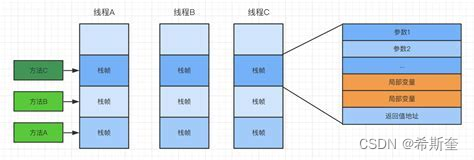
ThreadLocalMap(線程的一個屬性)
1. 每個線程中都有一個自己的 ThreadLocalMap 類對象,可以將線程自己的對象保持到其中, 各管各的,線程可以正確的訪問到自己的對象
。 2. 將一個共用的 ThreadLocal 靜態實例作為 key,將不同對象的引用保存到不同線程的 ThreadLocalMap 中,然后在線程執行的各處通過這個靜態 ThreadLocal 實例的 get()方法取 得自己線程保存的那個對象,避免了將這個對象作為參數傳遞的麻煩。
3. ThreadLocalMap 其實就是線程里面的一個屬性,它在 Thread 類中定義ThreadLocal.ThreadLocalMap threadLocals = null;
使用場景
最常見的 ThreadLocal 使用場景為 用來解決 數據庫連接、Session 管理等。
private static final ThreadLocal threadSession = new ThreadLocal();public static Session getSession() throws InfrastructureException {Session s = (Session) threadSession.get();try {if (s == null) {s = getSessionFactory().openSession();threadSession.set(s);}} catch (HibernateException ex) {throw new InfrastructureException(ex);}return s;}4.1.19. synchronized 和 ReentrantLock 的區別
4.1.19.1. 兩者的共同點:
1. 都是用來協調多線程對共享對象、變量的訪問
2. 都是可重入鎖,同一線程可以多次獲得同一個鎖 3. 都保證了可見性和互斥性
4.1.19.2. 兩者的不同點:
1. ReentrantLock 顯示的獲得、釋放鎖,synchronized 隱式獲得釋放鎖
2. ReentrantLock 可響應中斷、可輪回,synchronized 是不可以響應中斷的,為處理鎖的 不可用性提供了更高的靈活性
3. ReentrantLock 是 API 級別的,synchronized 是 JVM 級別的
4. ReentrantLock 可以實現公平鎖
5. ReentrantLock 通過 Condition 可以綁定多個條件
6. 底層實現不一樣, synchronized 是同步阻塞,使用的是悲觀并發策略,lock 是同步非阻 塞,采用的是樂觀并發策略
7. Lock 是一個接口,而 synchronized 是 Java 中的關鍵字,synchronized 是內置的語言 實現。
8. synchronized 在發生異常時,會自動釋放線程占有的鎖,因此不會導致死鎖現象發生; 而 Lock 在發生異常時,如果沒有主動通過 unLock()去釋放鎖,則很可能造成死鎖現象, 因此使用 Lock 時需要在 finally 塊中釋放鎖。
9. Lock 可以讓等待鎖的線程響應中斷,而 synchronized 卻不行,使用 synchronized 時, 等待的線程會一直等待下去,不能夠響應中斷。
10. 通過 Lock 可以知道有沒有成功獲取鎖,而 synchronized 卻無法辦到。
11. Lock 可以提高多個線程進行讀操作的效率,既就是實現讀寫鎖等。
4.1.20. ConcurrentHashMap 并發
4.1.20.1. 減小鎖粒度
減小鎖粒度是指縮小鎖定對象的范圍,從而減小鎖沖突的可能性,從而提高系統的并發能力。減 小鎖粒度是一種削弱多線程鎖競爭的有效手段,這種技術典型的應用是 ConcurrentHashMap(高 性能的 HashMap)類的實現。對于 HashMap 而言,最重要的兩個方法是 get 與 set 方法,如果我 們對整個 HashMap 加鎖,可以得到線程安全的對象,但是加鎖粒度太大。Segment 的大小也被 稱為 ConcurrentHashMap 的并發度。
4.1.20.2. ConcurrentHashMap 分段鎖
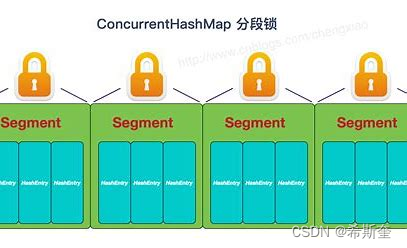
ConcurrentHashMap,它內部細分了若干個小的 HashMap,稱之為段(Segment)。默認情況下 一個 ConcurrentHashMap 被進一步細分為 16 個段,既就是鎖的并發度。 如果需要在 ConcurrentHashMap 中添加一個新的表項,并不是將整個 HashMap 加鎖,而是首 先根據 hashcode 得到該表項應該存放在哪個段中,然后對該段加鎖,并完成 put 操作。在多線程 環境中,如果多個線程同時進行 put操作,只要被加入的表項不存放在同一個段中,則線程間可以 做到真正的并行。
ConcurrentHashMap 是由 Segment 數組結構和 HashEntry 數組結構組成
ConcurrentHashMap 是由 Segment 數組結構和 HashEntry 數組結構組成。Segment 是一種可 重入鎖 ReentrantLock,在 ConcurrentHashMap 里扮演鎖的角色,HashEntry 則用于存儲鍵值 對數據。一個 ConcurrentHashMap 里包含一個 Segment 數組,Segment 的結構和 HashMap 類似,是一種數組和鏈表結構, 一個 Segment 里包含一個 HashEntry 數組,每個 HashEntry 是 一個鏈表結構的元素, 每個 Segment 守護一個 HashEntry 數組里的元素,當對 HashEntry 數組的 數據進行修改時,必須首先獲得它對應的 Segment 鎖。

4.1.21. Java 中用到的線程調度
4.1.21.1. 搶占式調度:
搶占式調度指的是每條線程執行的時間、線程的切換都由系統控制,系統控制指的是在系統某種 運行機制下,可能每條線程都分同樣的執行時間片,也可能是某些線程執行的時間片較長,甚至 某些線程得不到執行的時間片。在這種機制下,一個線程的堵塞不會導致整個進程堵塞。

4.1.21.2. 協同式調度:
協同式調度指某一線程執行完后主動通知系統切換到另一線程上執行,這種模式就像接力賽一樣, 一個人跑完自己的路程就把接力棒交接給下一個人,下個人繼續往下跑。線程的執行時間由線程 本身控制,線程切換可以預知,不存在多線程同步問題,但它有一個致命弱點:如果一個線程編 寫有問題,運行到一半就一直堵塞,那么可能導致整個系統崩潰。
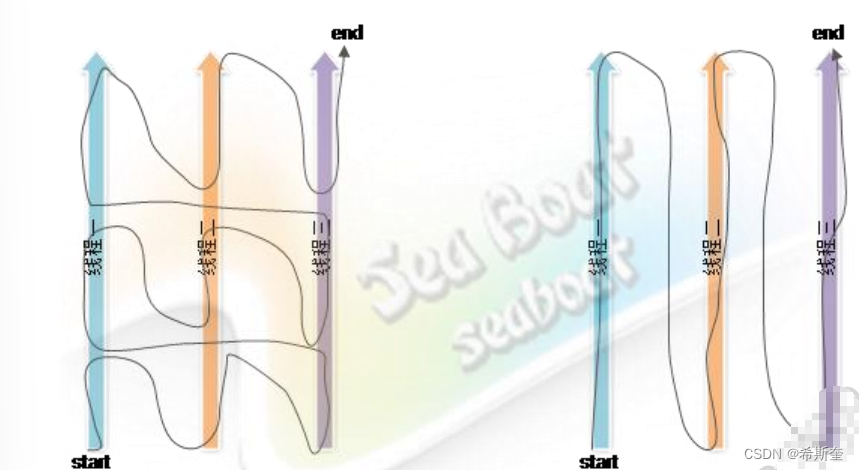
搶占式調度👆? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 協同式調度👆
4.1.21.3. JVM 的線程調度實現(搶占式調度)
java 使用的線程調使用搶占式調度,Java 中線程會按優先級分配 CPU 時間片運行,且優先級越高 越優先執行,但優先級高并不代表能獨自占用執行時間片,可能是優先級高得到越多的執行時間 片,反之,優先級低的分到的執行時間少但不會分配不到執行時間。
4.1.21.4. 線程讓出 cpu 的情況:
1. 當前運行線程主動放棄 CPU,JVM 暫時放棄 CPU 操作(基于時間片輪轉調度的 JVM 操作系 統不會讓線程永久放棄 CPU,或者說放棄本次時間片的執行權),例如調用 yield()方法。
2. 當前運行線程因為某些原因進入阻塞狀態,例如阻塞在 I/O 上。
3. 當前運行線程結束,即運行完 run()方法里面的任務。
4.1.22. 進程調度算法
4.1.22.1. 優先調度算法
1. 先來先服務調度算法(FCFS) 當在作業調度中采用該算法時,每次調度都是從后備作業隊列中選擇一個或多個最先進入該隊 列的作業,將它們調入內存,為它們分配資源、創建進程,然后放入就緒隊列。在進程調度中采 用 FCFS 算法時,則每次調度是從就緒隊列中選擇一個最先進入該隊列的進程,為之分配處理機,使之投入運行。該進程一直運行到完成或發生某事件而阻塞后才放棄處理機,特點是:算法比較 簡單,可以實現基本上的公平。
2. 短作業(進程)優先調度算法 短作業優先(SJF)的調度算法是從后備隊列中選擇一個或若干個估計運行時間最短的作業,將它們 調入內存運行。而短進程優先(SPF)調度算法則是從就緒隊列中選出一個估計運行時間最短的進程, 將處理機分配給它,使它立即執行并一直執行到完成,或發生某事件而被阻塞放棄處理機時再重 新調度。該算法未照顧緊迫型作業。
4.1.22.2. 高優先權優先調度算法
為了照顧緊迫型作業,使之在進入系統后便獲得優先處理,引入了最高優先權優先(FPF)調度 算法。當把該算法用于作業調度時,系統將從后備隊列中選擇若干個優先權最高的作業裝入內存。 當用于進程調度時,該算法是把處理機分配給就緒隊列中優先權最高的進程。
1. 非搶占式優先權算法
在這種方式下,系統一旦把處理機分配給就緒隊列中優先權最高的進程后,該進程便一直執行下 去,直至完成;或因發生某事件使該進程放棄處理機時。這種調度算法主要用于批處理系統中; 也可用于某些對實時性要求不嚴的實時系統中。
2. 搶占式優先權調度算法
在這種方式下,系統同樣是把處理機分配給優先權最高的進程,使之執行。但在其執行期間,只 要又出現了另一個其優先權更高的進程,進程調度程序就立即停止當前進程(原優先權最高的進程) 的執行,重新將處理機分配給新到的優先權最高的進程。顯然,這種搶占式的優先權調度算法能 更好地滿足緊迫作業的要求,故而常用于要求比較嚴格的實時系統中,以及對性能要求較高的批 處理和分時系統中。
3.高響應比優先調度算法
在批處理系統中,短作業優先算法是一種比較好的算法,其主要的不足之處是長作業的運行 得不到保證。如果我們能為每個作業引入前面所述的動態優先權,并使作業的優先級隨著等待時 間的增加而以速率 a 提高,則長作業在等待一定的時間后,必然有機會分配到處理機。該優先權的 變化規律可描述為:

(1) 如果作業的等待時間相同,則要求服務的時間愈短,其優先權愈高,因而該算法有利于 短作業。
(2) 當要求服務的時間相同時,作業的優先權決定于其等待時間,等待時間愈長,其優先權 愈高,因而它實現的是先來先服務。
(3) 對于長作業,作業的優先級可以隨等待時間的增加而提高,當其等待時間足夠長時,其 優先級便可升到很高,從而也可獲得處理機。簡言之,該算法既照顧了短作業,又考慮了作業到 達的先后次序,不會使長作業長期得不到服務。因此,該算法實現了一種較好的折衷。當然,在 利用該算法時,每要進行調度之前,都須先做響應比的計算,這會增加系統開銷。
4.1.22.3. 基于時間片的輪轉調度算法
1. 時間片輪轉法
在早期的時間片輪轉法中,系統將所有的就緒進程按先來先服務的原則排成一個隊列,每次調度 時,把 CPU 分配給隊首進程,并令其執行一個時間片。時間片的大小從幾 ms 到幾百 ms。當執行 的時間片用完時,由一個計時器發出時鐘中斷請求,調度程序便據此信號來停止該進程的執行, 并將它送往就緒隊列的末尾;然后,再把處理機分配給就緒隊列中新的隊首進程,同時也讓它執 行一個時間片。這樣就可以保證就緒隊列中的所有進程在一給定的時間內均能獲得一時間片的處 理機執行時間。
2. 多級反饋隊列調度算法
(1) 應設置多個就緒隊列,并為各個隊列賦予不同的優先級。第一個隊列的優先級最高,第二 個隊列次之,其余各隊列的優先權逐個降低。該算法賦予各個隊列中進程執行時間片的大小也各 不相同,在優先權愈高的隊列中,為每個進程所規定的執行時間片就愈小。例如,第二個隊列的 時間片要比第一個隊列的時間片長一倍,……,第 i+1 個隊列的時間片要比第 i 個隊列的時間片長 一倍。
(2) 當一個新進程進入內存后,首先將它放入第一隊列的末尾,按 FCFS 原則排隊等待調度。當 輪到該進程執行時,如它能在該時間片內完成,便可準備撤離系統;如果它在一個時間片結束時 尚未完成,調度程序便將該進程轉入第二隊列的末尾,再同樣地按 FCFS 原則等待調度執行;如果 它在第二隊列中運行一個時間片后仍未完成,再依次將它放入第三隊列,……,如此下去,當一個 長作業(進程)從第一隊列依次降到第 n 隊列后,在第 n 隊列便采取按時間片輪轉的方式運行。
(3) 僅當第一隊列空閑時,調度程序才調度第二隊列中的進程運行;僅當第 1~(i-1)隊列均空時, 才會調度第 i 隊列中的進程運行。如果處理機正在第 i 隊列中為某進程服務時,又有新進程進入優 先權較高的隊列(第 1~(i-1)中的任何一個隊列),則此時新進程將搶占正在運行進程的處理機,即 由調度程序把正在運行的進程放回到第 i 隊列的末尾,把處理機分配給新到的高優先權進程。 在多級反饋隊列調度算法中,如果規定第一個隊列的時間片略大于多數人機交互所需之處理時間 時,便能夠較好的滿足各種類型用戶的需要。
4.1.23.1. 概念及特性
CAS(Compare And Swap/Set)比較并交換,CAS 算法的過程是這樣:它包含 3 個參數 CAS(V,E,N)。V 表示要更新的變量(內存值),E 表示預期值(舊的),N 表示新值。當且僅當 V 值等于 E 值時,才會將 V 的值設為 N,如果 V 值和 E 值不同,則說明已經有其他線程做了更新,則當 前線程什么都不做。最后,CAS 返回當前 V 的真實值。 CAS 操作是抱著樂觀的態度進行的(樂觀鎖),它總是認為自己可以成功完成操作。當多個線程同時 使用 CAS 操作一個變量時,只有一個會勝出,并成功更新,其余均會失敗。失敗的線程不會被掛 起,僅是被告知失敗,并且允許再次嘗試,當然也允許失敗的線程放棄操作。基于這樣的原理, CAS 操作即使沒有鎖,也可以發現其他線程對當前線程的干擾,并進行恰當的處理。
4.1.23.2. 原子包 java.util.concurrent.atomic(鎖自旋) JDK1.5 的原子包:
java.util.concurrent.atomic 這個包里面提供了一組原子類。其基本的特性就 是在多線程環境下,當有多個線程同時執行這些類的實例包含的方法時,具有排他性,即當某個 線程進入方法,執行其中的指令時,不會被其他線程打斷,而別的線程就像自旋鎖一樣,一直等 到該方法執行完成,才由 JVM 從等待隊列中選擇一個另一個線程進入,這只是一種邏輯上的理解。 相對于對于 synchronized 這種阻塞算法,CAS 是非阻塞算法的一種常見實現。由于一般 CPU 切 換時間比 CPU 指令集操作更加長, 所以 J.U.C 在性能上有了很大的提升。如下代碼:
public class AtomicInteger extends Number implements java.io.Serializable {private volatile int value;public final int get() {return value;}public final int getAndIncrement() {for (;;) { //CAS 自旋,一直嘗試,直達成功int current = get();int next = current + 1;if (compareAndSet(current, next))return current;}}public final boolean compareAndSet(int expect, int update) {return unsafe.compareAndSwapInt(this, valueOffset, expect, update);}
}getAndIncrement 采用了 CAS 操作,每次從內存中讀取數據然后將此數據和+1 后的結果進行 CAS 操作,如果成功就返回結果,否則重試直到成功為止。而 compareAndSet 利用 JNI 來完成 CPU 指令的操作。


4.1.23.3. ABA 問題
CAS 會導致“ABA 問題”。CAS 算法實現一個重要前提需要取出內存中某時刻的數據,而在下時 刻比較并替換,那么在這個時間差類會導致數據的變化。
比如說一個線程 one 從內存位置 V 中取出 A,這時候另一個線程 two 也從內存中取出 A,并且 two 進行了一些操作變成了 B,然后 two 又將 V 位置的數據變成 A,這時候線程 one 進行 CAS 操 作發現內存中仍然是 A,然后 one 操作成功。盡管線程 one 的 CAS 操作成功,但是不代表這個過 程就是沒有問題的。
部分樂觀鎖的實現是通過版本號(version)的方式來解決 ABA 問題,樂觀鎖每次在執行數據的修 改操作時,都會帶上一個版本號,一旦版本號和數據的版本號一致就可以執行修改操作并對版本 號執行+1 操作,否則就執行失敗。因為每次操作的版本號都會隨之增加,所以不會出現 ABA 問 題,因為版本號只會增加不會減少。

![web:[WUSTCTF2020]樸實無華](http://pic.xiahunao.cn/web:[WUSTCTF2020]樸實無華)



)
)





)






