文章目錄
- CUDA與GPU編程
- 1. 并行處理與GPU體系架構
- 1.1 并行處理簡介
- 1.1.1 串行處理與并行處理的區別
- 1.1.2 并行處理的概念
- 1.1.3 常見的并行處理
- 1.2 GPU并行處理
- 1.2.1 GPU與CPU并行處理的異同
- 1.2.2 CPU的優化方式
- 1.2.3 GPU的特點
- 1.3 環境搭建
CUDA與GPU編程
1. 并行處理與GPU體系架構
1.1 并行處理簡介
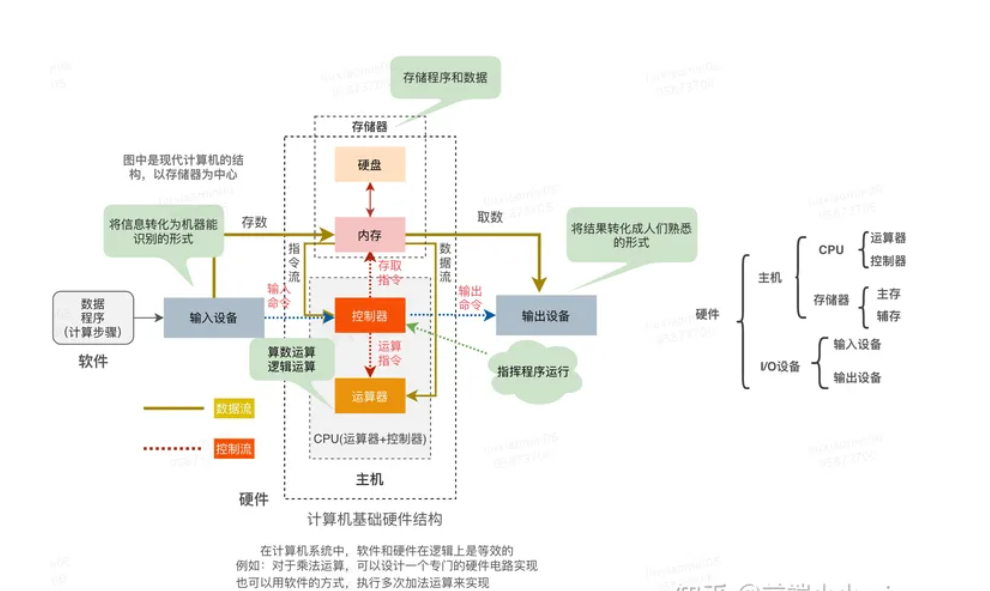
計算機基本硬件組成
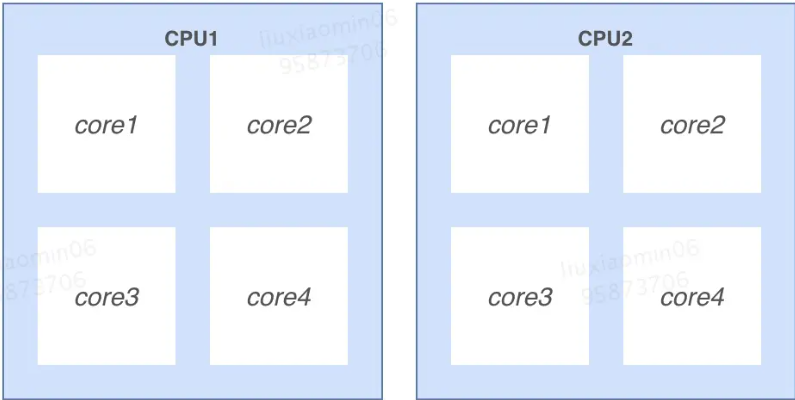
多CPU: 是指簡單的多個CPU工作在同一個系統上,多個CPU之間的通訊是通過主板上的總線進行的
多核 :是指一個CPU有多個核心處理器,處理器之間通過CPU內部總線進行通訊。
進程和線程
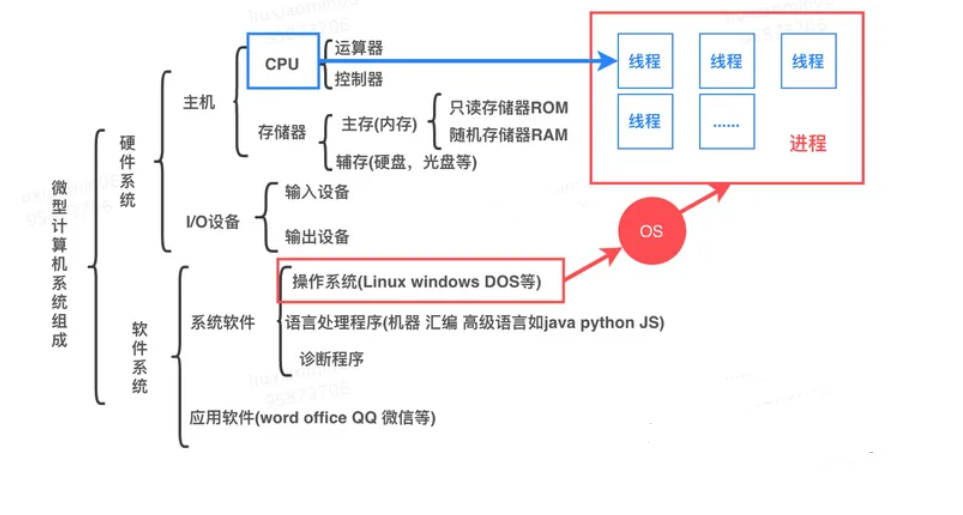
進程:是操作系統(OS)進行資源(CPU、內存、磁盤、IO、帶寬等)分配的最小單位。一個進程就是一個程序的運行實例
啟動一個程序的時候,操作系統會為該程序創建一塊內存,用來存放代碼、運行中的數據和一個執行任務的主線程,我們把這樣的一個運行環境叫進程,例如:打開一個瀏覽器、一個聊天窗口分別是一個進程。進程可以有多個子任務,如聊天工具接收消息、發送消息,這些子任務成為線程。
線程: 是CPU調度和分配的基本單位。操作系統會根據進程的優先級和線程的優先級去調度CPU。
線程數: 是一種邏輯概念,是模擬出的CPU核心數 。
進程和線程的關系描述如下:
- 進程可以簡單理解為一個容器有自己獨立的地址空間。一個進程可由多個線程的執行單元組成,每個線程都運行在同一進程的上下文中,共享進程該地址空間以及其內的代碼和全局數據等資源即線程之間共享進程中的數據
- 每個進程至少有一個主線程,它無需由用戶主動創建,一般由系統自動創建。系統創建好進程后,實際上就啟動了執行該進程的執行主線程,執行主線程以函數地址形式,即程序入口函數(如 main函數),將程序的啟動點提供給操作系統。主執行線程終止或關閉,進程也就隨之終止,操作系統會回收改進程所占用的資源
- 進程中的任意一線程執行出錯,都會導致整個進程的崩潰。
- 進程之間的內容相互隔離。進程隔離是為保護操作系統中進程互不干擾的技術,每一個進程只能訪問自己占有的數據,也就避免出現進程 A 寫入數據到進程 B 的情況。正是因為進程之間的數據是嚴格隔離的,所以一個進程如果崩潰了,或者掛起了,是不會影響到其他進程的。如果進程之間需要進行數據的通信,這時候,就需要使用用于進程間通信(IPC)的機制了。
- 嚴格講應該是線程能夠獲得CPU資源,進程對CPU資源的獲取也是體現在線程上的。CPU內核數,和進程線程沒直接關系。操作系統(OS)可以把某個進程部署在某個CPU核上,但這取決于系統設計。
- 進程、線程都是由操作系統調度的,線程只是由進程創建,但是進程本身不會負責調度線程。在操作系統看來,線程和進程其實差不多,不同點是線程是迷你的進程,并且進程可以包含多個線程
- 對于內存堆內存、代碼區一般屬于一個進程,但是棧(執行棧)卻是屬于一個線程的,且每個線程擁有一個獨立的棧。
1.1.1 串行處理與并行處理的區別
-
串行處理(Serial Processing):
-
指令/代碼塊依次執行任務按順序依次執行,一個任務完成后才會開始下一個任務。
-
串行處理是指在一個特定的時間點上,只有一個任務在執行。
-
這意味著任務之間相互等待,執行時間較長的任務會影響整體性能。一般來說,當程序有數據依賴or分支等這些情況下需要串行
-
-
并行處理(Parallel Processing):
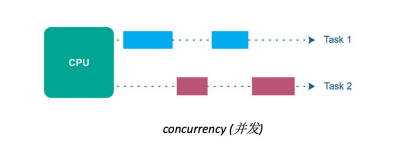
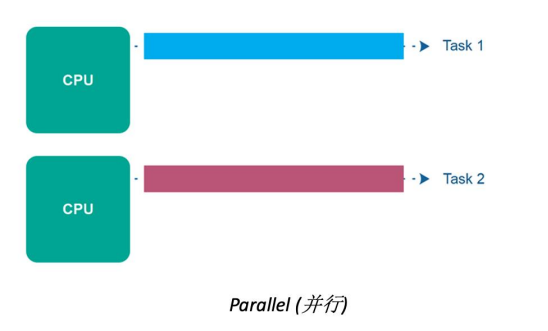
- 并行處理是指在同一時刻多個任務可以同時執行。
- 任務被分成多個子任務,這些子任務可以在多個處理單元(例如多核處理器或分布式系統中的多臺計算機)上并行執行。
- 并行處理可以顯著提高任務的執行速度和系統的性能。
- 指令/代碼塊同時執行
- 充分利用multi-core(多核)的特性,多個core一起去完成一個或多個任務
- 使用場景:科學計算,圖像處理,深度學習等等
在并行處理中,任務之間可以是相互獨立的,也可以是相互依賴的。并行處理通常需要額外的硬件支持和編程技巧來管理任務之間的同步和數據共享。
總之:
- 串行處理是按順序執行任務,而并行處理是同時執行多個任務。
- 并行處理通常用于加速計算和提高系統性能,特別是在需要處理大量數據或計算密集型任務時。
1.1.2 并行處理的概念
? 在計算機科學中,“并行處理” 是指同時執行多個任務或操作的技術。它利用多個處理單元或線程來并發執行任務,從而提高程序的執行速度。在 Python 中,我們可以利用多線程、多進程或異步編程等技術來實現并行處理。
1.1.3 常見的并行處理
- 多核處理器(Multi-Core Processors):
- 多核處理器包含多個CPU核心,每個核心可以獨立執行指令。這意味著多個任務可以在不同核心上并行執行。
- 多核處理器常見于現代計算機和移動設備,使多線程應用程序可以更有效地運行。
- 并行計算集群(Parallel Computing Clusters):
- 并行計算集群是由多臺計算機組成的網絡,它們可以協同工作來解決大規模計算問題。
- 每臺計算機都可以處理一部分任務,通過網絡通信和協作,實現任務的并行執行。
- GPU并行處理(GPU Parallel Processing):
- 圖形處理單元(GPU)在圖形渲染之外也可用于一般計算任務。它們具有大量的小型處理單元,適合并行計算。
- GPU計算用于加速科學計算、深度學習、機器學習等領域。
- 分布式計算(Distributed Computing):
- 分布式計算是將任務分發給多臺計算機,這些計算機可能位于不同地理位置。
- 通過分布式系統,可以同時處理大規模數據集或執行計算密集型任務。
- SIMD(Single Instruction, Multiple Data)并行性:
- SIMD是一種并行處理技術,其中一條指令同時作用于多個數據元素。
- SIMD通常用于多媒體處理和向量計算,如圖像處理和音頻處理。
- 多線程并發(Multithreading):
- 多線程技術允許在同一程序中創建多個線程,每個線程可以執行不同的任務。
- 多線程并發可用于處理并行性較低的任務,如GUI應用程序和服務器。
- 數據流并行性(Dataflow Parallelism):
- 數據流并行性是一種并行處理模型,其中任務的執行取決于數據的可用性。
- 當數據可用時,相關任務可以并行執行,而無需嚴格的同步。
并行化處理是將一個任務分解成多個子任務,每個子任務可以獨立地進行處理。這樣可以提高處理速度和效率。
- 分治法:將大問題分解成若干小問題,并且這些小問題可以獨立地進行計算,最后將結果合并得到答案。
- 數據劃分法:將數據劃分成多份,每份數據可以獨立地進行計算,最后將結果合并得到答案。
- 流水線法:將一個任務分為若干階段,每個階段可以獨立地進行計算,并且不同階段之間的數據傳輸要盡可能快。
- 線程池技術:在程序啟動時創建一定數量的線程,并放入線程池中,當需要執行某個任務時從線程池中取出一個線程來執行,執行完畢后再歸還給線程池。
- OpenMP庫:OpenMP是一個針對共享內存架構的并行編程API標準。它支持C、C++和Fortran等語言,在代碼中使用預處理器指令就能夠實現多線程編寫。
- MPI庫:MPI(Message Passing Interface)是一種消息傳遞編程模型,在分布式系統上實現進程間通信。MPI庫適用于各種形式的并行計算,包括集群、超級計算機和網格計算等。
Python 提供了多個并行處理庫,其中一些常用的庫包括:
- multiprocessing:這個內置庫提供了跨平臺的多進程支持,可以使用多個進程并行執行任務。
- threading:這個內置庫提供了多線程支持,可以在同一進程內使用多個線程并行執行任務。
- concurrent.futures:這個標準庫提供了高級的并行處理接口,可以使用線程池或進程池來管理并發任務的執行。
- joblib:這是一個流行的第三方庫,提供了簡單的接口來并行執行 for 循環,尤其適用于科學計算和機器學習任務。
- dask:這是一個靈活的第三方庫,提供了并行處理和分布式計算的功能,適用于處理大規模數據集。
1.2 GPU并行處理
1.2.1 GPU與CPU并行處理的異同
相同點:
- 并行性支持: GPU和CPU都支持并行處理,但它們的并行性方式有所不同。
- 計算能力: GPU和CPU都可以執行計算任務,但GPU在某些特定類型的計算任務上表現更出色。
不同點:
- 體系結構: GPU和CPU具有不同的體系結構。CPU通常具有較少的核心(一般為幾個到幾十個),而GPU具有大量的小型核心(通常為數百到數千個)。這使得GPU在同時處理大規模數據時更具優勢。
- 用途: CPU通常用于一般計算任務,如操作系統管理、文件處理和串行計算。而GPU主要設計用于圖形渲染,但也在科學計算、深度學習和機器學習等需要大規模并行計算的領域中得到廣泛應用。
- 指令集: CPU具有復雜的通用指令集,適用于各種計算任務。GPU的指令集通常較簡單,適用于執行相同操作的大量數據。
- 內存層次結構: CPU通常具有更大、更快速的高速緩存,適用于較小的數據集。GPU通常具有大量的全局內存,適用于處理大規模數據集。
- 編程模型: 編寫針對GPU的并行代碼通常需要使用特定的編程模型,如CUDA(用于NVIDIA GPU)或OpenCL。而CPU上的并行編程通常使用多線程和多進程來實現。
- 功耗和散熱: GPU通常在相對較高的功耗下運行,因為它們的設計重點是性能。相比之下,CPU通常更注重功耗效率和散熱控制。
綜上所述,GPU和CPU都支持并行處理,但它們在體系結構、用途、指令集、內存層次結構和編程模型等方面存在顯著差異。選擇使用哪種處理器取決于具體的計算任務和性能需求。在一些情況下,GPU可以顯著加速大規模并行計算,而CPU則更適用于通用計算和較小規模的任務。
1.2.2 CPU的優化方式
- 多核利用: 如果計算機使用多核CPU,確保充分利用所有核心。編寫多線程應用程序或使用并行編程框架來將任務分發到多個核心上,以提高性能。
- 高性能編程語言: 選擇使用高性能編程語言,如C++或Rust,以編寫計算密集型應用程序。這些語言通常具有更好的性能優化支持。
- 編譯器優化: 使用優化的編譯器選項來生成高效的機器碼。編譯器可以進行各種優化,包括內聯函數、循環展開和代碼重排。
- CPU指令級優化: 利用CPU的特定指令集擴展,如SSE(Streaming SIMD Extensions)或AVX(Advanced Vector Extensions),以加速特定類型的計算任務。
- 緩存優化: 編寫代碼時考慮緩存的層次結構,盡量減少緩存未命中。這包括循環訪問數組時考慮局部性,并使用緩存友好的數據結構。
- 減少分支: 避免過多的條件分支,因為分支可能導致流水線停滯。優化代碼以減少分支預測錯誤的可能性。
- 循環優化: 對于性能關鍵的循環,進行循環展開、循環重排和循環剝離等優化,以提高指令級并行性。
- 數據并行性: 使用SIMD指令和向量化編程,以在單個指令中處理多個數據元素,從而提高并行性。
- 內存優化: 減少內存訪問次數,使用局部變量和緩存數據以減少內存延遲。
- 多線程并發: 利用多線程來并行執行任務,特別是在多核CPU上。使用線程池或并發框架來管理線程。
- 性能分析工具: 使用性能分析工具(如Profiling工具)來識別性能瓶頸,并根據分析結果進行優化。
- 硬件加速: 對于某些計算密集型任務,可以考慮使用GPU或專用硬件加速器來提高性能。
- 避免不必要的同步: 減少線程之間的同步操作,以避免競態條件和鎖競爭,從而提高性能。
- 優化算法: 選擇適當的算法和數據結構,以減少計算復雜度,從而提高性能。
- 定時和調度: 了解操作系統的定時和調度機制,以便優化任務的調度和響應時間。
1.2.3 GPU的特點
1.3 環境搭建
lspci| grep

lsb_release -a
nvidia-smi
1.全面掌握「進程與線程、并發并行與串行、同步與異步、阻塞與非阻塞」的區別















 介紹與使用)


 - 簡介及Cargo使用)
