論文鏈接:https://arxiv.org/abs/2103.10504
代碼鏈接: https://monai.io/research/unetr
機構:Vanderbilt University,?NVIDIA
最近琢磨不出來怎么把3d體數據和文本在cnn中融合,因為確實存在在2d里面用的transformer用在3d里面會爆炸這回事,所以干脆去找個經典3d transformer+cnn的好了。要是有知道朋友也可以一起討論一下。因為是兩年前的文章,所以這篇博文主要集中寫方法了。
*媽耶,沒想到真的部分解決我的疑問了,好的洛陽鏟,愛來自中國
摘要
近十年來,具有收縮和擴展路徑的全卷積神經網絡(fcnn)在大多數醫學圖像分割應用中表現出突出的特點。在fcnn中,編碼器通過學習全局和局部特征以及上下文表示來發揮不可或缺的作用,這些特征和上下文表示可用于解碼器的語義輸出預測。盡管取得了成功,但fcnn中卷積層的局部性限制了學習遠程空間依賴關系的能力。受自然語言處理(NLP)在遠程序列學習中最近成功的啟發,我們將體積(3D)醫學圖像分割任務重新制定為序列到序列的預測問題。我們引入了一種新的架構,稱為UNEt-TRansformer(UNETR),它利用Transformer作為編碼器來學習輸入體積的序列表示并有效捕獲全局多尺度信息,同時也遵循編碼器和解碼器的成功“u形”網絡設計。Transformer 編碼器通過不同分辨率的跳過連接直接連接到解碼器,以計算最終的語義分割輸出。我們已經在用于多器官分割的多圖譜標記顱頂(BTCV)數據集和用于腦腫瘤和脾臟分割任務的醫學分割十項全能(MSD)數據集上驗證了我們的方法的性能。我們的基準測試在BTCV排行榜上展示了新的最先進的性能。
背景
fcnn不能有效捕捉全局信息,transformer難以有效捕捉局部信息
我們將3D分割任務重新制定為一維seq to seq 的預測問題,并使用Transformer作為編碼器從嵌入的輸入補丁中學習上下文信息。從Transformer編碼器中提取的表示通過多個分辨率的跳過連接與基于cnn的解碼器合并,以預測分割輸出。在解碼器中我們使用cnn,這是因為Transformer雖然具有學習全局信息的強大能力,但卻無法正確捕獲局部信息。
貢獻
1. 提出了一種新的基于變壓器的體積醫學圖像分割模型。
2. 為此,我們提出了一種新的架構,其中(1)Transformer編碼器直接利用嵌入式3D體來有效捕獲遠程依賴關系;(2)skip-connected decoder結合提取的不同分辨率的表示并預測分割輸出
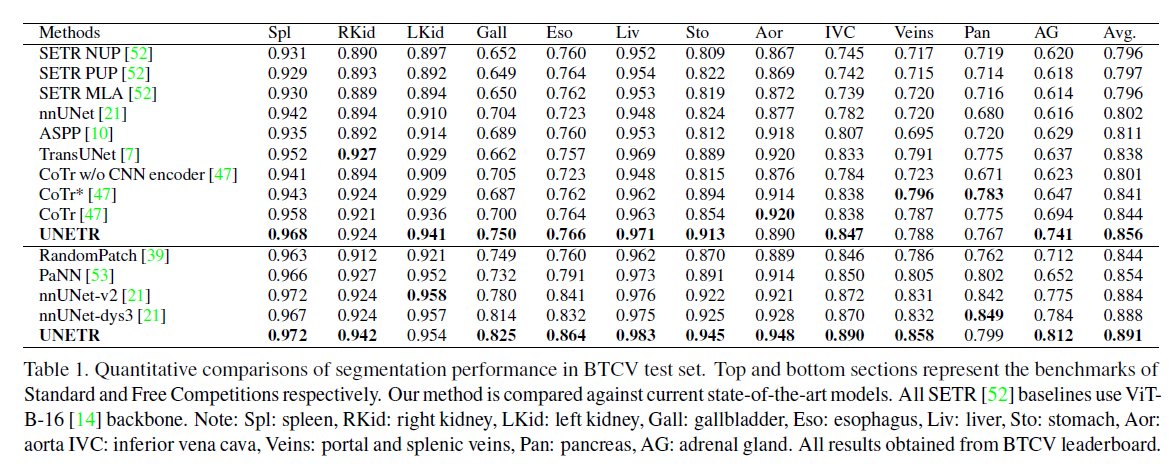
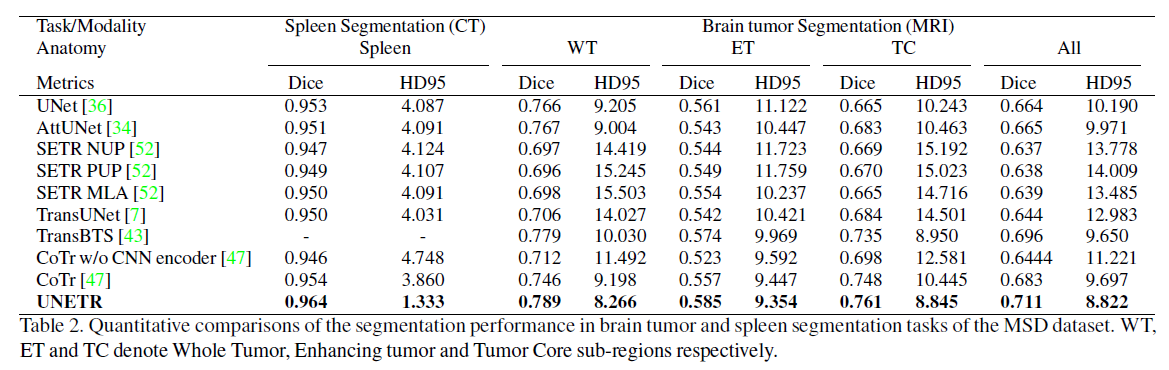
3.?我們在兩個公共數據集:BTCV[26]和MSD[38]上驗證了我們提出的模型在不同體積分割任務中的有效性。UNETR在BTCV數據集的排行榜上實現了新的最先進的性能,并且在MSD數據集上優于競爭方法。
相關工作
基于cnn的分割網絡
暫略
Vision Transformers
暫略
方法
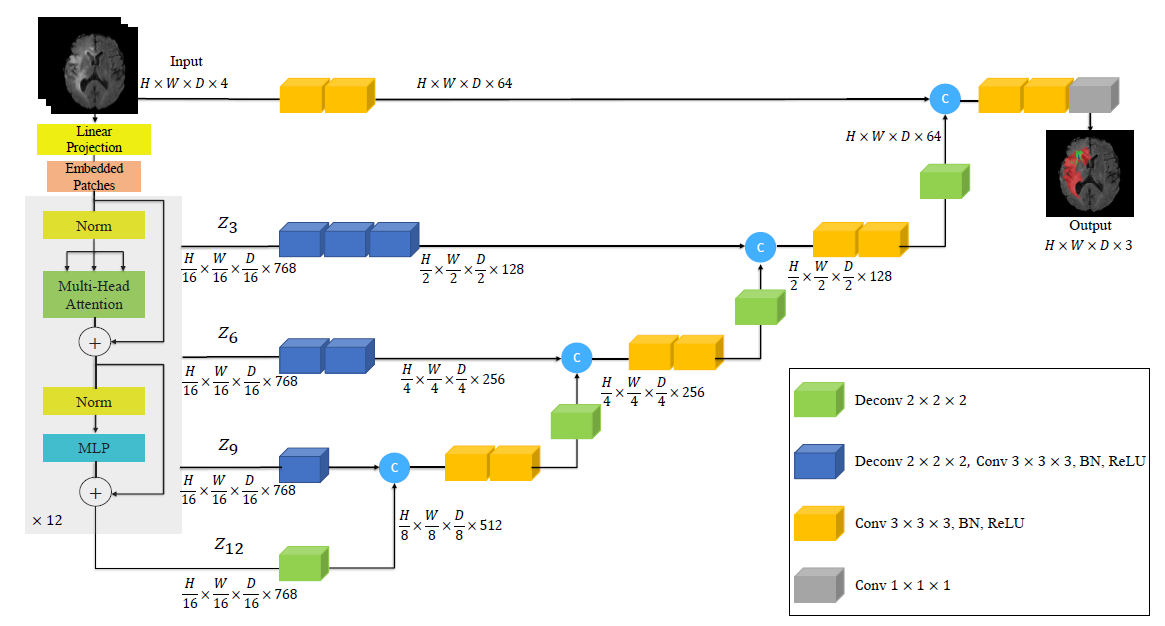
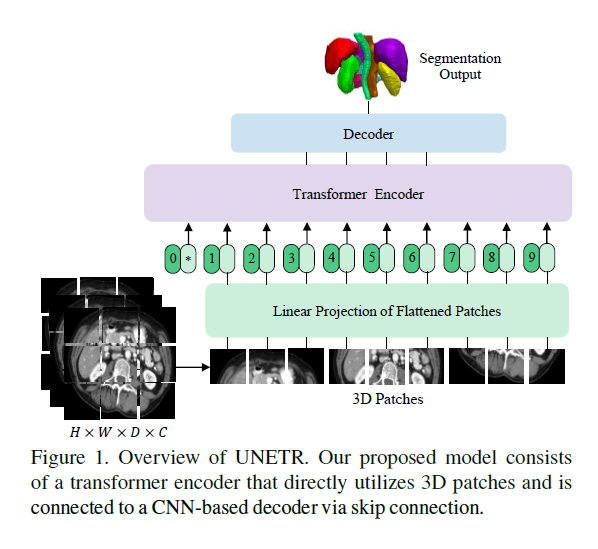
UNETR架構概述。3D輸入體數據(例如,MRI圖像的C=4通道)被劃分為一系列均勻且不重疊的patch,并使用線性層投影到嵌入空間中。該序列與位置嵌入一起添加,并用作變壓器模型的輸入。提取變壓器中不同層的編碼表示,并通過跳過連接與解碼器合并,以預測最終的分割。給出了補丁分辨率P =16和嵌入尺寸ek =768時的輸出大小。
網絡結構
我們在上圖中概述了所提出的模型。UNETR采用由一堆Transformer組成的收縮-擴展(contracting-expanding)模式作為編碼器,編碼器通過跳過連接連接到解碼器。與NLP中常用的一樣,Transformer在輸入嵌入的一維序列上運行。
我本人就是在3D作為跟文本一樣維度的序列輸入tansformer之后會存在長寬高壓到一個維度上導致做交叉注意力的時候內存會爆掉,看看本文怎么解決的↓
1)img 輸入:x∈R? HxWxDxC,其中H,W是長寬,D是深度,C是channel
2)然后把它拍平成 xv∈R Nx(P^3 x C)? ?式中P^3表示每個patch的分辨率,N =(H*W*D)/P^3為序列長度。
3) 隨后,我們使用線性層將貼片投影到K維嵌入空間中,該嵌入空間在整個Transformer層中保持恒定。
4) 為了保留提取的patch的空間信息,我們添加了一維可學習的位置嵌入 Epos ∈ R NxK 到投影的 patch embedding?Epos ∈ R (P^3 x C)xK,根據公式↓
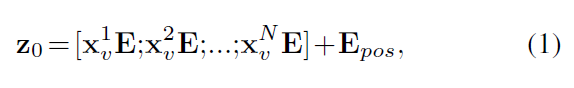
請注意,可學習的[class]令牌沒有添加到嵌入序列中,因為我們的變壓器主干是為語義分割而設計的。
5)在嵌入層后,我們利用由多頭自注意(MSA)和多層感知器(MLP)子層組成的Transformer塊堆,根據算式
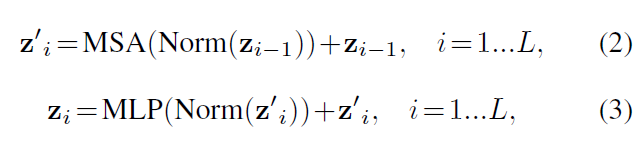
其中Norm()表示層歸一化[1],MLP由兩個具有GELU激活函數的線性層組成,i為中間塊標識符,L為變壓器層數。
MSA子層
由n個并行self-attention層(SA)組成。具體來說,SA塊是一個參數化函數,它學習查詢(q)與序列Z∈R N*K 中相應的鍵(k)和值(v)表示之間的映射
通過測量z中兩個元素及其鍵值對之間的相似性來計算注意權重(A)
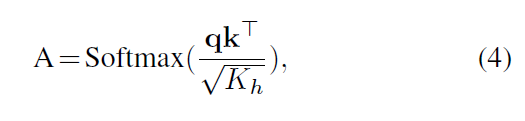
其中Kh = K=n是一個比例因子,用于將參數的數量保持在一個常數上,其中鍵K的值不同。
6)?使用計算的注意力權重,序列z中值v的SA輸出計算為

這里,v表示輸入序列和中的值 Kh = K/n是一個比例因子(scaling factor.)
此外,MSA的輸出被定義為

其中Wmsa ∈?R n.Kh x K表示多頭可訓練參數權重。
7) 受類似于U-Net[36]的架構的啟發,其中編碼器的多個分辨率的特征與解碼器合并。我們從transformer提取了大小為 (HxWxD)/P^3 x K?的序列表示zi(i∈{3,6,9,12}),并把他們變形成一個 H/P x W/P xD/P x K的tensor
我們定義中的表示在嵌入空間中被重塑為特征大小為K的Transformer 的輸出(即變壓器的嵌入大小)。此外,如圖2所示,在每個分辨率下,我們利用連續3x3x3的卷積層,然后是規范化層,將嵌入空間中的重塑張量投影到輸入空間中。
8)在我們encoder的bottleneck(即變壓器最后一層的輸出)中,我們將反卷積層應用于變換后的特征映射,將其分辨率提高2倍。
9) 然后,我們將調整大小的特征圖與先前變壓器輸出(例如z9)的特征圖連接起來,并將它們饋送到連續的3x3x3的卷積層中,并使用反卷積層對輸出進行上采樣。這個過程在所有其他后續層中重復,直到原始輸入分辨率,其中最終輸出被送入帶有softmax激活函數的1x1x1卷積層,以生成體素語義預測。
損失函數
soft dice loss
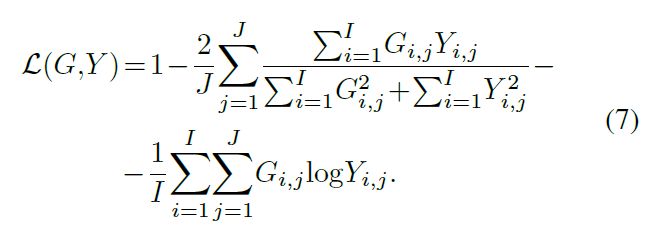
實驗
數據集
BTCV (CT):多器官分割
MSD (MRI/CT):腦腫瘤分割
實現細節
框架:pytorch 和 monai(monai聽說作為醫學深度學習的框架還挺方便的,也是基于pytorch的,有機會學學)
硬件:NVIDIADGX-1服務器
所有模型都以6個批大小進行訓練,使用AdamW優化器[31],初始學習率為0.0001,迭代20000次。
Transformer 模型 :VIT-B16,L=12層,嵌入尺寸k =768
結果
BTCV
MSD
評估指標
Dice(Dice score)
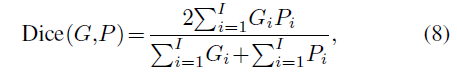
HD (Hausdorff Distance)
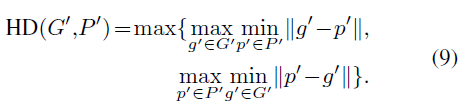
總結
本文介紹了一種新的基于Transformer的結構,稱為UNETR,通過將該任務重新表述為一維序列到序列預測問題,用于體醫學圖像的語義分割。我們建議使用轉換器編碼器來增加模型學習遠程依賴關系和在多個尺度上有效捕獲全局上下文表示的能力。我們驗證了UNETR在CT和MRI模式下不同體積分割任務中的有效性。UNETR在BTCV排行榜上的多器官分割的標準和自由競賽中都取得了新的最先進的表現,并且在MSD數據集上優于腦腫瘤和脾臟分割的競爭方法。最后,UNETR已顯示出有效學習醫學圖像中所表示的關鍵解剖關系的潛力。該方法為醫學圖像分析中一類新的基于變壓器的分割模型奠定了基礎。


)






)
 - 變量與作用域)








