函數
—— 封裝的一個公式:sin、cos、tan
—— 函數為腳本的別名
—— 函數就是一個功能模塊,在函數中寫執行的命令即可;使用函數可以避免代碼重復,增加可讀性,簡化腳本,使用函數可以將大的工程分割為若干小的功能模塊,代碼的可讀性更強
—— 函數由函數名和函數體組成
—— 函數一定要先定義,才能使用
—— 幫助:help function
函數的用法
注:一定要先給函數定義,才能執行函數
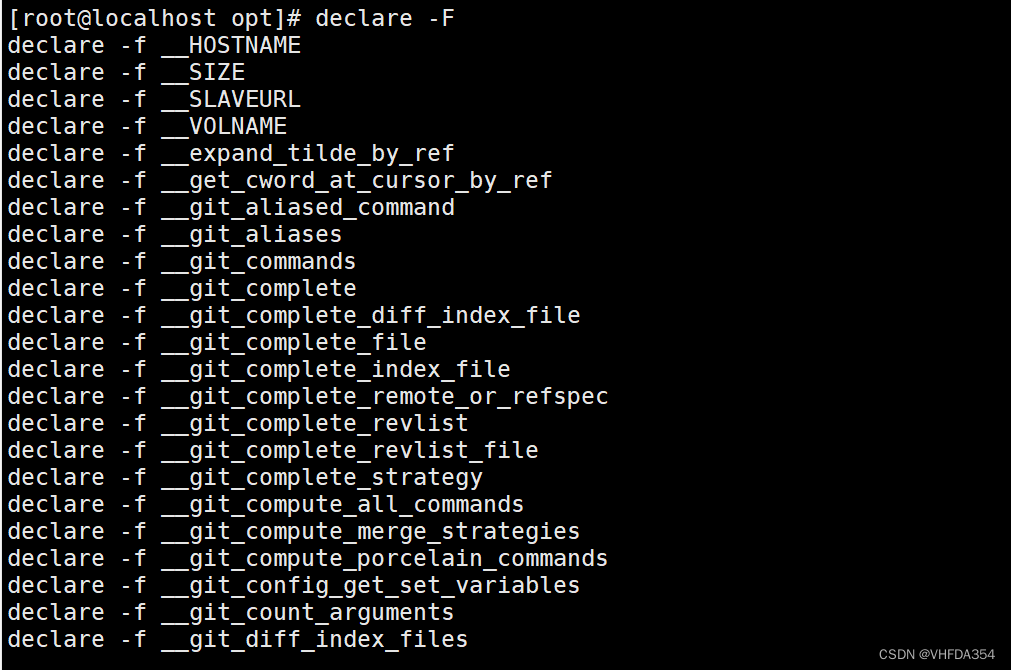
查看函數
declare 命令
—— declare -F :查看函數列表
—— declare -f __函數名 :查找指定函數名;兩個下劃線
函數的定義
—— 格式1:自定義函數名 () {
腳本;命令序列
}
—— 格式2:function 自定義函數名 {
腳本;命令序列
}
—— 格式3:function 自定義函數名 (){
腳本;命令序列
}
例
格式1 #一般用此格式
[root@localhost opt]# han () { echo "hello"; }
#定義一個函數 han 為標準輸出 hello
[root@localhost opt]# han
hello #執行此函數,顯示結果格式2
[root@localhost opt]# function han { echo "hello"; }
[root@localhost opt]# han
hello格式3
[root@localhost opt]# function han () { echo "hello"; }
[root@localhost opt]# han
hello刪除函數
unset 命令
—— unset 函數名
例
#先定義一個函數,并驗證是否能使用
[root@localhost opt]# han () { echo "hello"; }
[root@localhost opt]# han
hello[root@localhost opt]# unset han #刪除函數
[root@localhost opt]# han
bash: han: 未找到命令...
#再次使用函數,驗證是否刪除;刪除成功
定義函數變量的作用范圍
local
—— 加此關鍵詞,可以固定函數的變量范圍,使其只能在函數內運行
export
—— 讓子shell 繼承變量
例
[root@localhost opt]# name=吳彥祖 #定義一個變量name為吳彥祖
[root@localhost opt]# echo $name #驗證
吳彥祖
[root@localhost opt]# id () { name=彭于晏;echo $name; }
#定義一個函數id,讓其中變量name輸出結果為彭于晏
[root@localhost opt]# id #驗證
彭于晏
[root@localhost opt]# echo $name
彭于晏#此時輸出變量name已經被函數id所影響
[root@localhost opt]# unset id
[root@localhost opt]# echo $name
彭于晏
#就算刪除函數id,變量name已經被更改
[root@localhost opt]# name=吳彥祖 #重新定義name
[root@localhost opt]# echo $name #驗證
吳彥祖
[root@localhost opt]# id () { local name=彭于晏;echo $name; }
#使用命令 local,限制變量參數,使其只能在函數中執行
[root@localhost opt]# id #驗證
彭于晏
[root@localhost opt]# echo $name #驗證,此時變量name不會被函數id影響
吳彥祖函數的返回值
return
—— 自定義 返回值 0 -- 255
—— 如果使用函數,那么 $? 那么使用就會受限,可以使用 return 自定義 $? 的返回值,來判斷函數中的命令是否成功
—— 函數一結束就取返回值,因為 $? 變量只返回執行的最后一條命令的退出返回碼
—— 退出碼必須是0-255,超出的值將為除以256取余
例
[root@localhost opt]# text () { echo "hello"; }
#定義一個函數
[root@localhost opt]# text
hello
[root@localhost opt]# echo $?
0
#此時返回值為0
[root@localhost opt]# text () { echo "hello";return 250; }
#更改返回值為250
[root@localhost opt]# text
hello
[root@localhost opt]# echo $?
250
#此時返回值已經被更改為250函數的傳遞參
腳本
#!/bin/bash
sum () {
echo " $1 " #識別第一個字符串
echo " $2 " #識別第二個字符串
#識別兩個字符串
}
sum $2 $1
#這后面的$2和$1,代表的是跟在腳本后面的字符串的順序;此處就是設定將第二個字符串放在第一位,將第一個字符串放在第二位顯示結果
[root@localhost opt]# bash j.sh 1 99 1 需要注意
—— 腳本的 $1 $2 和函數的 $1 $2 ,是沒有關系的
—— 函數的 $1 $2 是指跟在函數后面的值
遞歸函數
—— 函數的本質就是一個程序,每開一個進程都會消耗資源,無限的開自己死循環就會造成資源的無限占用形成病毒
—— 函數調用自己本身的函數
—— 必須要有結束函數的語句,防止死循環
階乘函數
—— 一個正整數的階乘(factorial)是所有小于及等于該數的正整數的積,并且0和1的階乘為1,自然數n的
—— 階乘寫作 n! =1×2×3×...×n
—— 階乘亦可以遞歸方式定義:0!=1,n!=(n-1)!×n n!=n(n-1)(n-2)...1 n(n-1)! = n(n-1)(n-2)!
腳本舉例:此腳本作用是計算任意數值的階乘
#!/bin/bash
fact () {
if [ $1 -eq 0 -o $1 -eq 1 ]
thenecho 1
elseecho $[$1* $(fact $[$1-1])]
#這里將 $[$1-1] 的值再次使用函數 fact 進行執行
#此處 * 為乘
fi
}
fact $1結果展示
[root@localhost opt]# bash digui.sh 5
120
#5的階乘為120函數的文件
—— 專門存放函數的文件
—— . 絕對路徑的文件名 函數名:從存放函數的文件中,提取使用指定函數(. 可以用 source 代替)
數組
—— 數據的集合稱為數組
-
普通數組,普通數組可以不事先聲明,直接使用;下標只能是數值
-
關聯數組,關聯數組必須先聲明,再使用;下標可以自定義任意字符串
-
變量:存儲單個元素的內存空間
-
數組:存儲多個元素的連續的內存空間,相當于多個變量的集合
—— 數組名和索引
-
索引的編號從0開始,屬于數值索引
-
索引可支持使用自定義的格式,而不僅是數值格式,即為關聯索引,bash 4.0版本之后開始支持
-
bash的數組支持稀疏格式(索引不連續)
數組的使用
—— 一定要先聲明數組
daclare -a 普通數組(不需要手動聲明,系統幫你聲明了)
—— 關聯數組一定要手動聲明
declare -A 數組名
定義數組
—— 自定義數組名=(數組值中間用空格隔開)
例
![]()
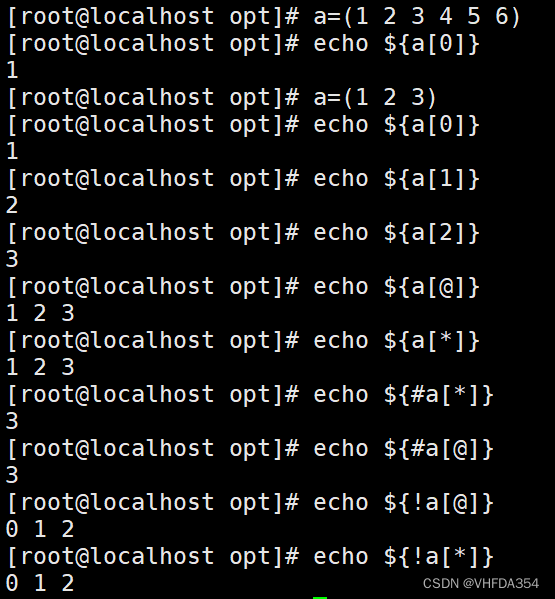
單個調用
| echo | 作用 |
|---|---|
| ${a[0]} | 調用第一個值 |
| ${a[1]} | 調用第二個值 |
| ${a[2]} | 調用第三個值 |
| …… | …… |
| ${a[n]} | 調用第n個值 |
全部調用
| echo | 作用 |
|---|---|
| ${a[@]} 或者 ${a[*]} | 顯示所有結果 |
| ${#a[@]} 或者 ${#a[*]} | 統計個數 |
| ${!a[@]} 或者 ${!a[*]} | 顯示所有下標 |
例
數組切片
—— 格式:echo ${自定義數組名[@或*]:自定義數字:自定義數字}
—— 注意:以 “:” 為分隔符
例
[root@localhost opt]# a=(1 2 3 4 5)
[root@localhost opt]# echo ${a[@]:1:3}
2 3 4
#從第一個開始并跳過第一個,到后三個結束數組替換
—— 格式:echo ${自定義數組名[@或*]/查找的目標字符/替換的字符}
—— 注意:以 “/” 為分隔符
例
[root@localhost opt]# a=(1 2 3 4 5)
[root@localhost opt]# echo ${a[@]/2/hi}
1 hi 3 4 5
#查找a數組中第二個字符串,并替換成hi數組刪除
—— 格式:unset 數組名 //刪除該數組
—— 格式:unset 數組名[n] //選擇數組中的第 n 個刪除;從0開始,0代表第一個字符
例
[root@localhost opt]# a=(1 2 3 4 5)
[root@localhost opt]# echo ${a[*]}
1 2 3 4 5
[root@localhost opt]# unset a[2] #刪除該數組中第三個字符
[root@localhost opt]# echo ${a[*]} #驗證
1 2 4 5
[root@localhost opt]# unset a #刪除該數組
[root@localhost opt]# echo ${a[*]}
#不會顯示任何東西冒泡排序
—— 一種數組排序算法
—— 類似氣泡上涌的動作,會將數據在數組中從小到大或者從大到小不斷的向前移動
—— 基本思想:冒泡排序的基本思想是對比相鄰的兩個元素值,如果滿足條件就交換元素值,把較小的元素移動到數組前面,把大的元素移動到數組后面(也就是交換兩個元素的位置),這樣較小的元素就像氣泡一樣從底部上升到頂部
—— 算法思路:冒泡算法由雙層循環實現,其中外部循環用于控制排序輪數,一般為要排序的數組長度減1次,因為最后一次循環只剩下一個數組元素,不需要對比,同時數組已經完成排序了,而內部循環主要用于對比數組中每個相鄰元素的大小,以確定是否交換位置,對比和交換次數隨排序輪數而減少
腳本舉例:此腳本是隨機生成十個不同的數字并進行從小到大排序
#!/bin/bash
for i in {0..9}
do
a[$i]=$RANDOM
done
#生成一個擁有十個隨機數的數組
echo "原始數組: ${a[@]}"l=${#a[@]}
#定義變量l 等同于數組的總個數;此處 l=10
for((i=1;i<$l;i++))
#需要進行比較的次數
dofor ((j=0;j<$l-$i;j++))#相鄰的數字,需要比較的次數dofirst=${a[$j]}#數組的第 n個數k=$[$j+1]#數組的 n+1大小的下標second=${a[$k]}#數組的第 n+1個數if [ $first -gt $second ]thentemp=$firsta[$j]=$seconda[$k]=$temp#該三行是將兩個數字進行更換位置fidone
doneecho "從小到大: ${a[@]}"
腳本舉例
比較隨機數字的數組大小
#!/bin/bash
for a in {0..9}
dob[$a]=$RANDOM[ $a -eq 0 ] && min=${b[0]} && max=${b[0]}[ ${b[$a]} -gt $max ] && max=${b[$a]}[ ${b[$a]} -lt $min ] && min=${b[$a]}
doneecho "數組: ${b[*]}"
echo "最大值: $max"
echo "最小值: $min"補充命令
scp 腳本名 目標ip
—— 將腳本發送給指定虛擬機
declare 命令補充
—— declare +/- 選項 變量名
| 選項 | 作用 |
|---|---|
| - | 賦予變量類型屬性 |
| + | 取消變量的類型屬性 |
| -a | 將變量聲明為數組型 |
| -i | 將變量聲明為整數型 |
| -x | 將變量聲明為環境變量 |
| -r | 將變量聲明為只讀變量 |
| -p | 查看變量的被聲明的類型 |
eval 命令
—— 格式:eval()
—— 注釋:將任意字符串當成有效的表達式來求值并返回計算結果;如果參數不是字符串類型,則直接返回參數;需要注意的是,使用 eval() 函數時需要謹慎,因為它可以執行任意代碼,存在一定的安全風險
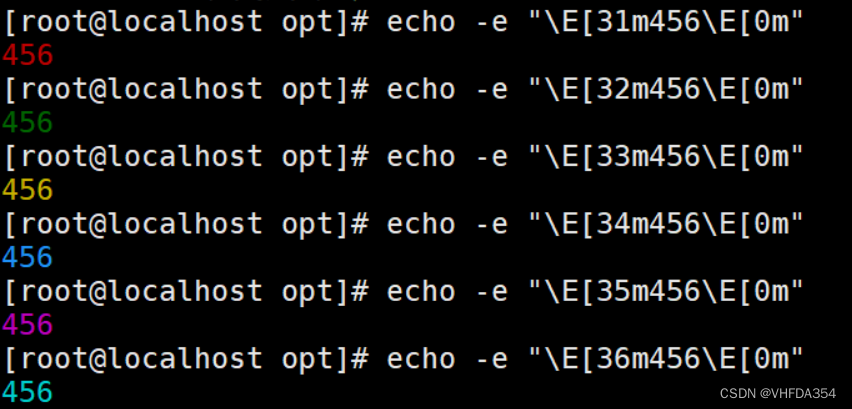
顯示顏色的命令









)




)
)


)
初識 Python)