線程其實對于操作系統來說是寶貴的資源,java層面的線程其實本質還是依賴于操作系統內核的線程進行處理任務,如果頻繁的創建、使用、銷毀線程,那么勢必會非常浪費資源以及性能不高,所以池化技術(數據庫連接池、線程池)在性能優化的時候是重中之重。
我們來猜想以下線程池的功能,因為如果是一個線程一個線程執行任務,那么我們需要進行對線程的管理、以及對于任務的分配,在執行過程中,本質還是利用多個線程通過從任務隊列中獲取任務,進行執行。通過這種方式,當任務來臨時可以直接使用線程,達到復用。
demo
ThreadPoolExecutor pool = new ThreadPoolExecutor(5, 10, 1000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>(15),new ThreadFactory() {private final AtomicInteger atomicInteger = new AtomicInteger(1);@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "pool-" + atomicInteger.getAndIncrement());}}, new ThreadPoolExecutor.DiscardPolicy());//執行pool.execute(new Runnable() {@Overridepublic void run() {System.out.println("qxlxi");}});//關閉pool.shutdown();boolean terminated = false;while (!terminated) {pool.awaitTermination(100,TimeUnit.SECONDS);}System.out.println("pool is shutdowm.");線程池的創建
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
corePoolSize :線程池中的常駐核心線程數 < core: >core : 緩沖隊列,超過緩沖隊列,就直接新建。核心線程不回銷毀,而非核心線程超過一定時間沒有使用,就會銷毀。
maxmumPoolSize : 整個線程池的核心線程和非核心線程數, maxmumPoolSize - corePoolSize 就是非核心線程數。
keepAliveTime & unit : 非核心線程數銷毀的時間,可以自定義
workQueue :當有新的任務請求線程時,超過核心線程數,那么就會將任務先存儲到任務隊列中,等待線程處理。是一個阻塞隊列。
有Array、Linked、Priority、Synchron等。
handler : 當沒有空閑線程進行處理任務的時候,超過來最大線程數,那么就需要執行線程池的拒絕策略。可以通過hanlder進行設置。只針對有屆阻塞隊列 可以看到通過一個抽象的接口,然后實現不同的策略來進行執行拒絕策略,當然我們也可以實現自己的策略拒絕類。
public interface RejectedExecutionHandler {void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
DiscardPolicy 什么也不做。
public static class DiscardPolicy implements RejectedExecutionHandler {public DiscardPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}}
AbortPolicy 直接返回異常。不執行
public static class AbortPolicy implements RejectedExecutionHandler {public AbortPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());}}
CallerRunsPolicy 策略是 任務提交者來執行這個任務。
public static class CallerRunsPolicy implements RejectedExecutionHandler {public CallerRunsPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}}}
DiscardOldestPolicy 策略是:判斷線程是否關閉狀態,沒有關閉的化,直接刪除workQueue中的一個任務,然后將其加入其中。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {public DiscardOldestPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}}}
threadFactory
線程創建ThreadPoolExecutor對象時,傳入ThreadFactory工廠類對象,那么線程池中的對象均會通過工廠類的new Thread()方法來實現。可以通過定義new Thread()對象來創建,添加一些信息。當然,我們還可以通過 newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor等方式。
線程池的執行
線程池執行任務的時候,只需要將執行的任務封裝成Runnable對象,然后將Runnable對象傳遞給execute()函數,線程池在創建的時候,并不會提前創建,而是當有任務的時候才會創建。
1.核心線程是否已滿,沒有滿 直接創建
2.核心線程已滿,則檢查等待隊列是否已滿,未滿,將任務放入隊列中
3.等待隊列已滿,檢查非核心線程,非核心線程未滿,常見非核心線程
4.核心線程、等待隊列、非核心線程都滿了,執行對應的拒絕策略
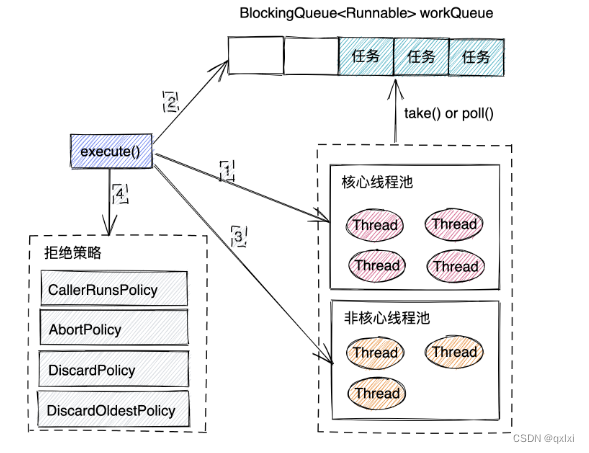
整體的流程,其實是創建核心線程之后,就會從wrokQueue中獲取任務通過take()函數進行執行,如果沒有任務的化就會阻塞等待,非核心線程創建之后,會調用workQueue()的poll(),不同從workQueue()獲取任務,poll()函數是阻塞函數,根take()函數不同的時,poll()函數可以設置阻塞的超時時間,poll()的超時時間超過非核心線程的等待時間,那么就會超時返回,執行線程銷毀。
關閉
public void shutdown() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();advanceRunState(SHUTDOWN);interruptIdleWorkers();onShutdown(); // hook for ScheduledThreadPoolExecutor} finally {mainLock.unlock();}tryTerminate();}
public List<Runnable> shutdownNow() {List<Runnable> tasks;final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();advanceRunState(STOP);interruptWorkers();tasks = drainQueue();} finally {mainLock.unlock();}tryTerminate();return tasks;}
線程池關閉有兩個方法,一種是shutdown() 以及shutdownNow()。前者是通過優雅的方式,會執行完正在執行以及等待隊列中的任務,后者則是通過直接將處理中,以及清空等待隊列,并向所有線程發送中斷請求。shutdownNow的返回值是等得隊列中未被執行的任務。需要注意的是返回時,有可能線程池內還有線程在執行任務,需要等所有線程都執行完畢之后,調用awaitTermination函數阻塞等待。
配置
在實際的應用開發中,我們如何進行合理配置線程池的大小呢,一般通俗來說的化,IO密集型和計算密集型,計算密集型設置未CPU核心相當就可以,IO密集型因為大部分時間都在IO阻塞上,所以將線程池適當開大點。除此之外就是IO+計算相結合的方式。
具體的方式其實就需要統計花在IO和計算上的占比,pool_size * 核數 = (cpu_time + io_time) / cpu_time。
比如cpu_time 占用 1/3 io占用 2/3 那么就是3.
當然在實際的層面來說,還需要考慮別的地方有沒有瓶頸,比如數據庫連接池,文件句柄等。也就是木桶效應。根據最短的進行合理評估,在實際中,就遇到DB 連接池配置失效,當時吞吐量上不去,最后發現后才解決。
小結
參數說明:
corePoolSize:指定了線程池中的線程數量。
maximumPoolSize:指定了線程池中的最大線程數量。
keepAliveTime:當前線程池數量超過corePoolSize時,多余的空閑線程的存活時間,即多次時間內會被銷毀。CachedThreadPool是60秒。
unit: keepAliveTime的單位。
workQueue:
blockQueue的配置。新加入任務的時候,當線程池中的可用線程小于第一個參數core線程數量,那么直接new一個線程或者用空閑的可用線程來執行任務。不用進行排隊。當線程池中core線程數量都處于執行中,那么就把任務加入到blockqueue中進行排隊等待。當排隊隊列滿了,那么新new一個線程,執行最新加入到queue中的任務。如果線程池中的線程數量超過了最大線程數量,那么這個時候將拒絕新加入的任務。如果最大線程數都滿了,隊列中也滿了,這個時候,還有新任務請求進來,那么會報錯,默認是拋出RejectedException。
blockqueue有三種策略,
第一種是配置一個SynchronousQueue,這種queue其實不是真正的queue,他根本就不會進行排隊,如果core線程數量滿了,那么新來一個任務,會直接new一個線程,而不是進入排隊!直到池中的線程數量超過最大線程數,開始拒絕新加入的任務,JDK的CacheThreadLocal就是使用的這個工作隊列,配置的最大線程數是Integer.MAXVALUE。
第二種是配置一個LinkedBlockingQueue,這種queue本身是沒有大小的,也就是說,這種queue永遠也滿不了,可以無限排,這個時候最大線程數就沒有意義了,因為queue永遠不滿,所以,這種配置就相當于是一個固定的大小為core線程數的線程池,JDK的FixedThreadPool就是采用的這個
第三種策略是用ArrayBlockingQueue,我們可以給這個queue指定大小。比如200啊,300啊,那么,只要queue大小滿了,就會產生新的線程來處理queue的頭部任務。如果池中超過了最大線程數,那么會拒絕任務的加入。
threadFactory:線程工廠,用于創建線程,一般用默認的即可。如果默認的不能滿足我們的要求,我們可以使用自定義的線程工廠。
RejectedExceptionHandler:拒絕策略,當BlockQueue都滿了無法接收新的任務了,就會觸發RejectedExceptionHandler的方法了,這是一個策略模式的很好的例子。JDK提供了幾種現成的拒絕策略,默認的拒絕策略是AbortPolicy,拋出RejectedException,這是一個運行時的異常,但是線程池執行器依舊可以繼續工作,再次提交新的任務的時候,可能又會拋出RejectedException。CallerRunsPolicy,這個策略是在調用者的線程中運行被拋棄的任務,相當于在線程池submit任務的時候,在調用者線程中執行runnable,顯然,這個策略很糟糕;DiscardoldestPolicy,這個策略是將隊列中最老的擠出去拋棄掉,然后再次提交該任務;DiscardPolicy,直接丟棄無法處理的任務,不做任何處理。一般來說,默認的拒絕策略是最好的,但是如果我們還想要自定義的拒絕策略,我們可以自己實現一個RejectedExceptionHandler策略。




)



之Plist文件、Preference(NSUserDefaults類))










